Amazon Web Services ブログ
Amazon SageMaker Ground Truthを利用した動画ラベリングとAmazon Rekognition Custom Labelsへのインポート
「Amazon Rekognition Custom Labelsを利用した動物の特徴的な行動検出」にて、行動検知モデル作成手順について紹介致しましたが、本ブログではモデル作成の重要なステップであるAmazon SageMaker Ground Truthを利用した動画のデータラベリングをご紹介します。合わせて、2021年1月時点ではAmazon SageMaker Ground Truthでラベリングした動画データをAmazon Rekognition Custom Labelsのデータセットとしてそのままインポートできません。そのため、ここではインポートするためのマニフェストファイルの記述方法をご紹介します。
ラベリングデータを利用した一般的な機械学習のワークフローは以下になります。このフローでモデルの精度向上に重要なのはラベリングデータの準備になります。もちろん、モデル開発やモデル学習に時間はかかると思います。しかし多くの場合、モデル開発に関しては既存もしくは機械学習のスペシャリストが作成したアルゴリズムやモデルを選定する事で開発の短縮化が行えますし、モデル学習についてもクラウドリソース(例えばGPUインスタンス)を利用することで学習時間の短縮化を行えます。そうすると、時間がかかるのがラベリングデータの準備であり、ラベリングの効率化・質の高いデータ数を増やす事が重要なポイントになります。このラベリングデータの準備を簡素化するツールとして、Amazon SageMaker Ground Truthがあります。

Amazon SageMaker Ground Truthは、フルマネージド型のデータラベル付きサービスで、数分でデータのラベル付を開始する事ができます。画像はもちろん、2020年7月より動画のラベル付をサポートしており、動画オブジェクトの検出・追跡、動画クリップの分類のワークフローを備えています。動画のラベル付で特筆すべき機能としてPrediction機能があり、バウンディングボックスでラベリングした物体を、次のフレームでも追跡して自動的にラベリングしてくれます。これにより、ラベリング時間の短縮化が期待できます。
Amazon SageMaker Ground Truthでの動画ラベリング
ここからは、Amazon SageMaker Ground Truthを利用した動画のラベリング手順を説明します。本手順ではオレゴン(us-west-2)リージョンを使用しています。事前にラベリングする動画はAmazon S3の所定のバケットに格納してください。ここではaws-hcls-demo-blogバケットのinputフォルダに動画を格納しています。
ラベリングジョブの作成
マネージメントコンソールからAmazon SageMakerを選択し、Ground Truthのラベリングジョブからラベリングジョブの作成をクリックします。

入力データのセットアップは自動化されたデータセットアップ、データタイプは動画ファイルを選択します(ジョブ名、入力データセットと出力データセットの場所は任意)。今回は動画ファイルからオブジェクト検出を行うため、「動画ファイルからフレームを抽出しますか?」は、はいを選択し、フレームの抽出はデフォルトの設定のままにします。フレームのサンプルレートを指定したい場合は、任意のレートを設定してください。

IAMロールは新たに作成し入力・出力データセットで指定したS3バケットへのアクセス権限を付与します。

完全なデータセットアップをクリックします。これによりデフォルト設定または指定したフレームレートで動画を画像分割してくれます。セットアップが完了するまでに数分かかります。

先程作成したIAMロールの最大セッション時間を変更します。マネージメントコンソールからIAM > ロールの画面に遷移し、作成したIAMロールを選択します。デフォルトでは1時間になっており、ラベリングツールでのタスク時間もこの最大セッション時間以内となります。今回は動画ラベリングが1時間以内におわらないことを想定して、12時間に設定して保存しています。

データのセットアップが完了したら、タスクのタイプの選択画面で動画オブジェクトの検出にある境界ボックスを選択し、次へをクリックします。

次にワーカを選択します。今回はプライベートチームを選択し、タスクのタイムアウトとタスクの有効期限が先ほど指定した最大セッション時間内の値を入力します。プライベートワーカが未作成の場合は、ラベリングワークフォースより作成してください。
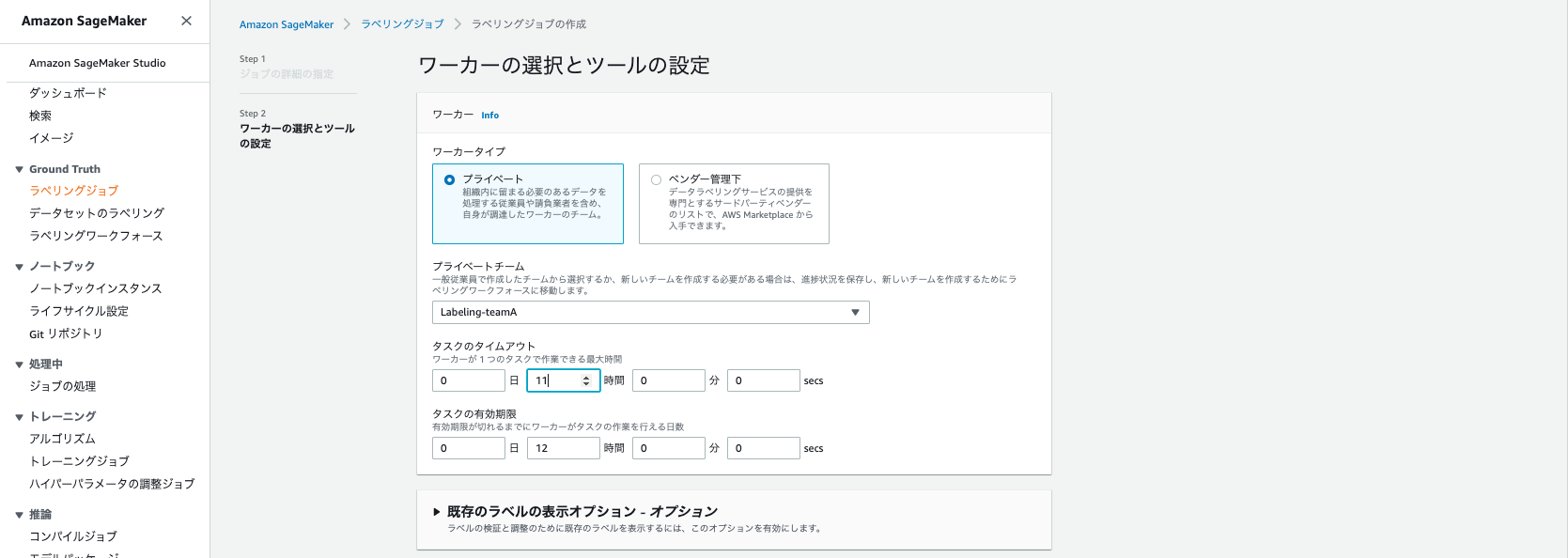
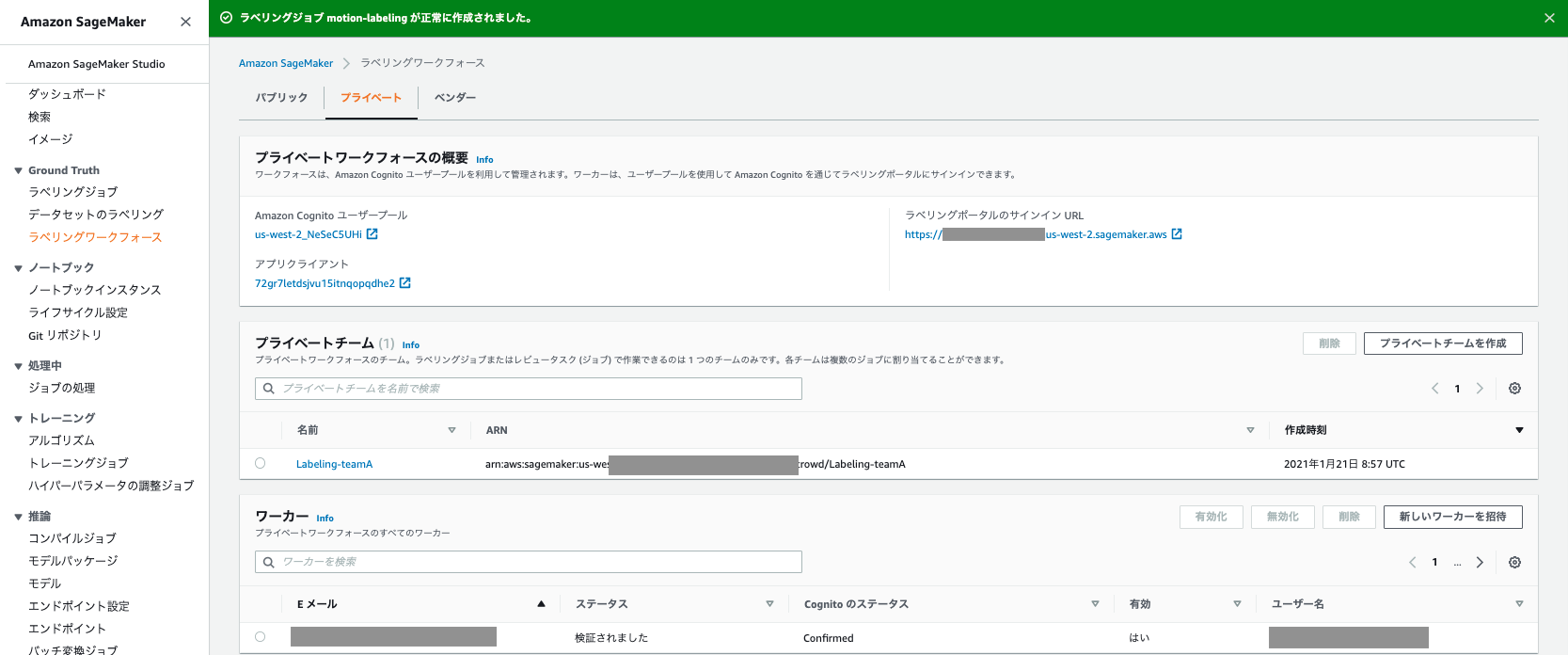
最後に今回検出するオブジェクトのタスクの説明、ラベルを入力します。今回はNormalとCleaningのラベルを登録しています。設定内容を確認し作成をクリックすると、ラベリングジョブが作成され、指定したプライベートチームに今回のタスクがアサインされます。

動画のラベリング
ここからはAmazon SageMaker Ground Truthでのラベリングの手順を説明します。まず、ラベリングポータルのサインインURLからログインし、ジョブがアサインされていることを確認します。サインインURLはラベリングワークフォースの概要欄に記載されています。アサインされたジョブを選択し、Start workingをクリックするとラベリング画面に遷移します。ジョブがアサインされていない場合は、ラベリングジョブのアサインが完了していないため、数分後に再度ログインしてください。

ラベリングしたい動画がフレーム分割されているので、フレームごとに画面右のラベルを指定してラベリングを行います。
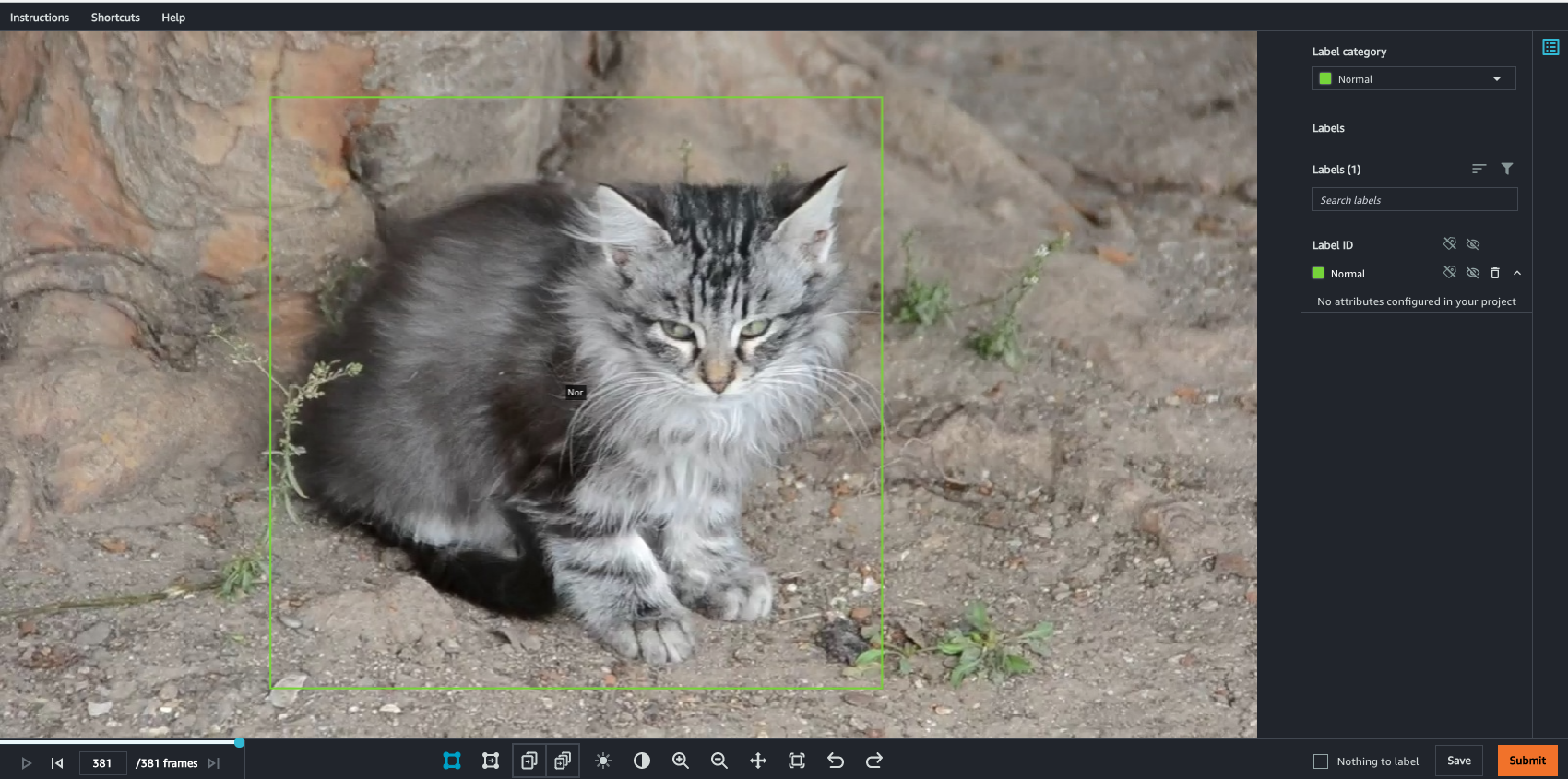
ただ、1フレーム毎に手動でラベリングを行うと時間がかかり非効率のため、Prediction機能を利用します。最初のフレームは手動でラベリングを行い、それ以降のフレームはPredict(Shift + P)を押すことでフレーム内のオブジェクトを追跡して自動ラベリングしてくれます。ラベルの位置がずれた、またはラベル対象のオブジェクトが変化した場合(今回だとNormal→Cleaningの行動が変わる)のみ手動で修正します。この機能によりラベリング時間の短縮と効率化ができます。最後に全てのラベリングが終了したらSubmitをクリックします。これでラベリング作業は終了です。

Amazon Rekognition Custom Labelsへインポートするためのマニフェストファイルの記述方法
Amazon SageMaker Ground Truthでのラベリングが終了すると指定したS3バケットにラベリング情報を含むファイル群が出力されます。ここではaws-hcls-demo-blogバケットのOutputフォルダを指定したため、その配下にラベリングジョブ名(ここでは、motion-labeling)のフォルダが作成されています。その配下にmanifests/output/output.manifestがあり、このマニフェストファイルを指定することで、Amazon Rekognition Custom Labelsのデータセットとしてインポートする事ができます。しかしながら、2021/1月時点ではこのマニフェストを指定してインポートできないため、マニフェストファイルの書き換えが必要です。
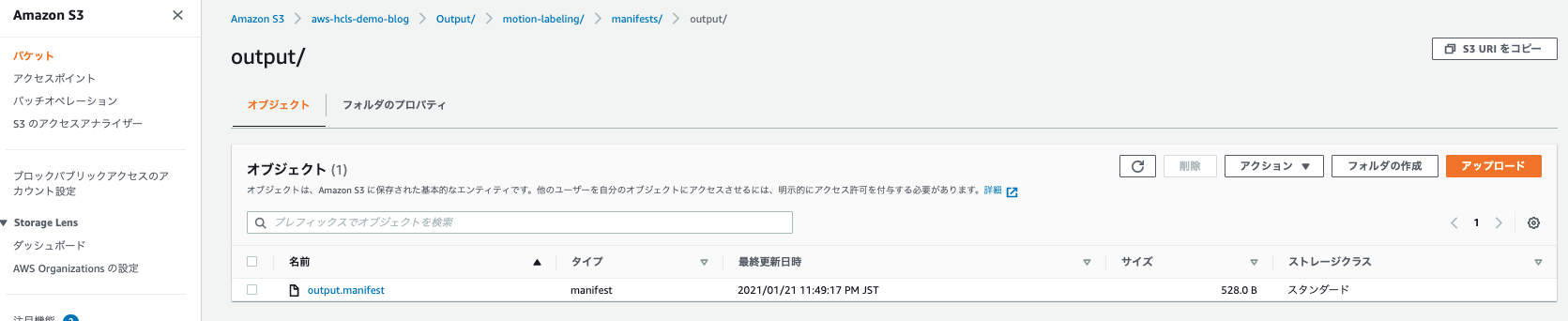
書き換えの方法として、アウトプットとして出力されているoutput.manifestとSeqLabel.jsonをダウンロードして利用します。SeqLabel.jsonは以下のようにannotations/consolidated-annotation/output/0に格納されており、参考情報として今回のラベリング作業だと各ファイルは以下のようなjsonが記載されています。

output.manifest
{"source-ref":"s3://aws-hcls-demo-blog/Input/mixkit-kitten-outside-cleaning-26382-medium.mp4/mixkit-kitten-outside-cleaning-26382-medium.mp4-sequence-1611238347.json","motion-labeling-ref-metadata":{"class-map":{"0":"Normal","1":"Cleaning"},"job-name":"labeling-job/motion-labeling","human-annotated":"yes","creation-date":"2021-01-21T14:48:51.110000","type":"groundtruth/video-object-detection"}}SeqLabel.json
{"detection-annotations":[{"annotations":[{"height":590,"width":623,"top":81,"left":265,"class-id":"1","label-category-attributes":{}}],"frame-no":"0","frame":"frame_0000.jpeg","frame-attributes":{}},
{"annotations":[{"height":590,"width":623,"top":81,"left":259,"class-id":"1","label-category-attributes":{}}],"frame-no":"1","frame":"frame_0001.jpeg","frame-attributes":{}},
....省略....
{"annotations":[{"height":602,"width":622,"top":66,"left":275,"class-id":"0","label-category-attributes":{}}],"frame-no":"380","frame":"frame_0380.jpeg","frame-attributes":{}}]}これらのファイルの情報をマージ及び修正を行い、output.manifestを以下のようなフォーマットにします。置換・修正に関してはVS Code、正規表現、pythonを利用する事で一括で行えます。特に各画像にimage_sizeの記載、class-mapの情報は降順に、typeをgroundtruth/object-detectionする点に注意してください。
output.manifest
{"source-ref":"s3://aws-hcls-demo-blog/Input/mixkit-kitten-outside-cleaning-26382-medium.mp4/frame_0000.jpeg","motion-labeling":{"annotations":[{"height":590,"width":623,"top":81,"left":265,"class_id":1,"label-category-attributes":{}}],"image_size":[{"width":1280,"depth":3,"height":720}],"frame-no":"0","frame":"frame_0000.jpeg","frame-attributes":{}},"motion-labeling-metadata":{"job-name":"labeling-job/motion-labeling","class-map":{"1":"Cleaning","0":"Normal"},"human-annotated":"yes","objects":[{"confidence":0.09}],"creation-date":"2021-01-21T14:48:51.110000","type":"groundtruth/object-detection"}}
{"source-ref":"s3://aws-hcls-demo-blog/Input/mixkit-kitten-outside-cleaning-26382-medium.mp4/frame_0001.jpeg","motion-labeling":{"annotations":[{"height":590,"width":623,"top":81,"left":259,"class_id":1,"label-category-attributes":{}}],"image_size":[{"width":1280,"depth":3,"height":720}],"frame-no":"1","frame":"frame_0001.jpeg","frame-attributes":{}},"motion-labeling-metadata":{"job-name":"labeling-job/motion-labeling","class-map":{"1":"Cleaning","0":"Normal"},"human-annotated":"yes","objects":[{"confidence":0.09}],"creation-date":"2021-01-21T14:48:51.110000","type":"groundtruth/object-detection"}}
....省略....
{"source-ref":"s3://aws-hcls-demo-blog/Input/mixkit-kitten-outside-cleaning-26382-medium.mp4/frame_0380.jpeg","motion-labeling":{"annotations":[{"height":602,"width":622,"top":66,"left":275,"class_id":0,"label-category-attributes":{}}],"image_size":[{"width":1280,"depth":3,"height":720}],"frame-no":"380","frame":"frame_0380.jpeg","frame-attributes":{}},"motion-labeling-metadata":{"job-name":"labeling-job/motion-labeling","class-map":{"1":"Cleaning","0":"Normal"},"human-annotated":"yes","objects":[{"confidence":0.09}],"creation-date":"2021-01-21T14:48:51.110000","type":"groundtruth/object-detection"}}このマニフェストファイルをダウンロードしたフォルダにアップロードします。これでマニフェストファイルの書き換えは完了です。

Amazon Rekognition Custom Labelsでのデータセットのインポート
Amazon Rekognition Custom Labelsでラベリングしたデータをインポートします。マネージメントコンソールからAmazon Rekognition Custom Labelsのページに遷移し、データセットを作成するをクリックします。

データセット名は任意の値を入力し、画像の場所はAmazon SageMaker Ground Truthでラベル付けされた画像をインポートする、manifestファイルの場所は先ほどアップロードしたファイルのパスを指定します。

ファイルパスを入力するとS3のバケットポリシーが表示されるので、別タブでAmazon S3のコンソール画面を開きこのポリシーをS3のバケットポリシーにコピーして変更の保存をクリックします。
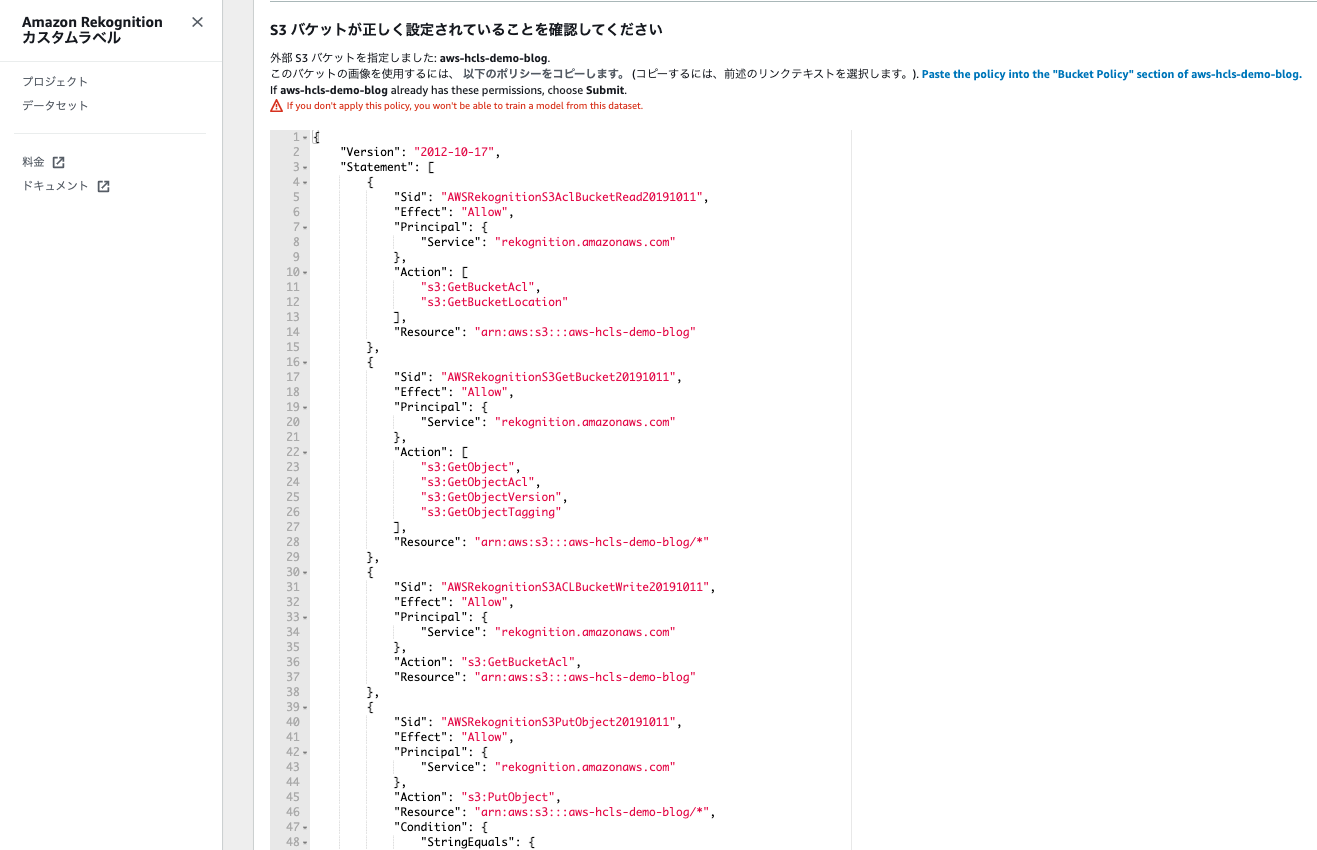

最後に画面右の提出をクリックするとAmazon SageMaker Ground Truthでラベリングしたデータが表示されます。表示されない場合はマニフェストファイルのフォーマットが不正の場合がありますので、修正してください。

インポートが正常にできたらモデルをトレーニングをクリックし、プロジェクトやテストセットの方法を指定してトレーニングを開始できます。トレーニングが途中でFailする場合は、マニフェストファイルのフォーマットが不正ですので、エラーログを確認して修正してください。

まとめ
本BlogではAmazon SageMaker Ground Truthを利用した動画のラベリングと、当該データセットのAmazon Rekognition Custom Labelsへのインポート方法を説明しました。このようにAmazon SageMaker Ground Truthを利用すると、簡単に動画のラベリングUIが作成でき、Prediction機能によりラベリングの効率化・短縮化が可能です。動画のラベリングデータを効率よく準備する事で、前回説明したAmazon Rekognition Custom Labelsを利用した行動検出やオブジェクトトラッキングモデルの精度向上につながれば幸いです。
著者について
 小泉 秀徳(Hidenori Koizumi)は、日本のヘルスケア・ライフサイエンスチームのソリューションアーキテクトです。理学のバックグラウンド(生物学、化学など)を活かした研究領域でのソリューション作成を得意としています。得意分野は機械学習で、最近ではAWS Amplifyを利用したアプリケーション作成も行っています。趣味は旅行と写真撮影です。
小泉 秀徳(Hidenori Koizumi)は、日本のヘルスケア・ライフサイエンスチームのソリューションアーキテクトです。理学のバックグラウンド(生物学、化学など)を活かした研究領域でのソリューション作成を得意としています。得意分野は機械学習で、最近ではAWS Amplifyを利用したアプリケーション作成も行っています。趣味は旅行と写真撮影です。