Amazon Web Services ブログ
Amazon SageMaker RL – Amazon SageMakerを使ったマネージドな強化学習
この数年、機械学習はたくさんの興奮をもたらしました。実際、医療画像分析 から自動運転トラックまで、複雑なタスクを機械学習によって成功させ、成長を遂げてきました。それにしても、どうやってこれらの機械学習モデルは賢くなっているのでしょうか?
端的には、機械学習のモデルは、以下の3つのいずれかの方法で学習されています。
- 教師あり学習:ラベル付きのデータセット(サンプルと答えを含む)を使って学習を実行します。徐々にモデルは学習し、正しい解を予測をするようになります。回帰と分類などが、教師あり学習の例として挙げられます。
- 教師なし学習: ラベルのないデータセット(サンプルのみを含む)を使ってアルゴリズムを実行します。ここでは、モデルはデータ中のパターンを徐々に学習し、それに応じてサンプルを編集します。クラスタリングやトピックモデリングなどが、教師なし学習の例として挙げられます。
- 強化学習: これは上の二つとはとても異なっています。ここでは、コンピュータープログラム(エージェントを指す)は環境と相互作用し、ほとんどの場合、これはシミュレータの中で行われます。エージェントは行動に応じて正または負の報酬を得ますが、報酬は、その行動がどれぐらい良いのかを表す数値表現を出力するユーザー定義関数によって計算されます。生の報酬を最大化することで、エージェントは最適な意思決定の戦略を学ぶことができます。
2017年の re:Invent でローンチされてから、Amazon SageMaker はお客様が迅速に、機械学習モデルのビルド・学習・ デプロイが実行できるようお手伝いをしてきました。本日、 Amazon SageMaker の利点を残したまま、Amazon SageMaker RL をローンチできることをとても嬉しく思います。これにより、全ての開発者やデータサイエンティストが、機械学習の専門知識を使ってより簡単に強化学習を実行できるようになりました。
強化学習のクイック入門
強化学習 ( RL: Reinforcement Learning ) というと、はじめとても複雑なものに聞こえますね、まずは例を見てみましょう。迷路をナビゲートするエージェントの学習を想像してみます。シミュレータでは、ある方向に向かって動くことができますが、壁にぶつかるとそこを通過することはできません。強化学習を使ってポリシーを学習し、エージェントはすぐに、より関連した行動をとるように成長していきます。
RLモデルを理解する上で一つの重要なことは、事前に定義されたラベル付きの迷路の情報をもとに学習するわけではないということです(ラベル付けされたデータで学習する場合は教師あり学習)。その代わり、エージェントは1歩ずつ進みながらそれらの環境(この場合は迷路)を発見し、さらにステップを進めることで報酬を得ます。行き止まりに達したら、負の報酬を与え、出口に近づいたら正の報酬を与えます。 たくさんの異なる迷路が生成されたらすぐに、エージェントは行動・データ点における報酬を学習し、モデルを学習し、次の行動としてより良い行動を決定します。この探索や学習のサイクルはRLの中心であり、十分な迷路の情報と十分な学習時間があれば、どんな迷路でもどのように進めば良いかナビゲートできるようになります。
RL は特に、 複雑で予想できないが環境はシミュレーション可能な場合や、自動運転、ゲーム、ポートフォリオ最適化、在庫最適化、ロボティクスまたは産業用のコントロールシステムなど、以前のデータセットの再構築が不可能だったり非常に高価だったりする場合などに、特に向いています。例えば、研究者がRLベースでコントロールするHVACシステムでは、ルールベースに比べて、20% から 40% のコスト削減が可能になります [1]、エコロジカル・フットプリントの大幅な削減は言うまでもありません。
Amazon SageMaker RLの紹介
Amazon SageMaker RL は、Amazon SageMaker 上に構築され、事前にパッケージ化されたRLツールキットを加え、どんなシミュレーション環境も統合しやすくしました。ご期待どおり、学習、推論はフルマネージドで、お客様には、サーバー管理でなくRLの開発に集中していただけます。
本日より、Open AI Gym, Intel Coach, Berkeley Ray RLLib を含む、SageMaker の Apache MXNet と Tensorflow 版で提供されるコンテナをご利用いただけます。これまでのように、Amazon SageMaker では、TensorForce や StableBaseline などの RL ライブラリを使ったご自身のカスタム環境を作成いただけます。
シミュレーション環境として、Amazon SageMaker RL は、次のオプションをサポートしています。
- ファーストパーティシミュレータは、AWS RoboMaker と Amazon Sumerian。
- Roboschool や EnergyPlus など、Gym インターフェースを使用して開発されたOpen AI Gym 環境や、オープンソースのシミュレーション環境。
- Gym interface を使ってお客様が構築されたシミュレーション環境。
- MATLAB や Simulink など、市販のシミュレータ(ライセンスについてはお客様側で管理)。
Amazon SageMaker RL では、Amazon SageMaker のように、Jupyter notebook のコレクションが提供されます。これらは Github で入手可能で、簡単な examples (cartpole, simple corridor) から、より高度なロボティクス、オペレーションズリサーチ、金融など様々な業種のものまでを含みます。これらのノートブックを拡張し、お客様のビジネス課題に合わせてカスタマイズしていただくことができます。
さらに、 均質 (homogeneous)、異種 (heterogeneous) スケーリングのいずれかを使って、RL をスケールさせる例を見てみましょう。この後者は 、シミュレーションはCPU、学習は GPU という使われ方をする多くの RL アプリケーションにおいて、特に重要です。シミュレーション環境はローカルでも、異なるネットワークにおけるリモートでもお使いいただくことができ、SageMaker が全てのセットアップを行います。
心配しないでください、見かけよりも優しいです。例を見てみましょう。
Amazon SageMakerを使った予測的なオートスケーリング
オートスケーリングは動的にサービス(例えば Amazon EC2 )を拡張させることができ、お客様が定義される条件に応じて、容量の増減を自動的に行います。閾値、アラーム、スケーリングポリシーなどの設定が、よくある定義条件としてあげられます。
ここで、RLモデルとカスタムシミュレータを使ったこのプロセスを、どのように最適化できるか、Amazon EC2 キャパシティをスケールさせるつもりで(もちろんこれは、ただのトイモデルです)、みてみましょう。簡単のために、最も重要なコードスニペットのみをハイライトします。完全なコードは Github で見ることができます。
ここで、ゲームの名前を、負荷プロファイルにインスタンスキャパシティに適応させること、とします。供給不足( アンダープロビジョンド によりトラフィックを失う) 、供給過多( オーバープロビジョンド によりお金を失う)のどちらも好まず、適切な量の見積もりをしたいと思っています。
RL用語でいうと、
- 環境は、負荷プロファイルとインスタンスの数を含む。
- それぞれのステップで、エージェントは、 インスタンスの増と減の二つの行動をとることができる。インスタンスを増やすと、より多くのトランザクションが可能となるが、金銭的なコストがかかり、オンライン状態になるのに数分かかることがある。インスタンスを削除すると金額的なコストは抑えられるが、全体として処理能力が減ってしまう。
- 報酬はインスタンスを実行するコストと、トランザクションの完走に成功する価値の組み合わせで与えられる。キャパシティが不足すると、大きなペナルティが課される。
シミュレーションのセットアップ
はじめに、高トラフィックの Web サーバーで見られるような負荷プロファイルを生成するシミュレータが必要となります。非常にシンプルな Python プログラムを作ってみましょう。ここに、三日分の周期における、毎分のトランザクションの例をプロットします。周期性を持った信号の中に、予測不可能なスパイクが含まれていることがわかります。

これが初期状態です。
config_defaults = {
"warmup_latency": 5, # It takes 5 minutes for a new machine
"tpm_per_machine": 300, # Each machine can process 300 transactions
"tpm_sigma": 30, # Machine's TPM capacity is variable
"machine_cost": 0.05, # Machines cost $0.05/min
"transaction_val": 0.90, # Successful transactions are worth
"downtime_cost": 200, # Downtime is assumed to cost the
"downtime_percent": 99.5, # Downtime is defined as availability
"initial_machines": 50, # How many machines are initially
"max_time_steps": 1000, # Maximum number of timesteps per
報酬の計算
これはとてもストレートなやり方です!現在の負荷を、現状のキャパシティと比較し、ロストしたトランザクションのコストを差し引き、0.5% を超える損失に対して大きなペナルティを適用します(ダウンタイムのかなり厳密な定義です!)。
def _react_to_load(self):
self.capacity = int(self.active_machines * np.random.normal
if self.current_load <= self.capacity:
# All transactions succeed
self.failed = 0
succeeded = self.current_load
else:
# Some transactions failed
self.failed = self.current_load - self.capacity
succeeded = self.capacity
reward = succeeded * self.transaction_val / 1000.0 # divide by percent_success = 100.0 * succeeded / (self.current_load +
if percent_success < self.downtime_percent:
self.is_down = 1
reward -= self.downtime_cost
else:
self.is_down = 0
reward -= self.active_machines * self.machine_cost
シミュレーションを進めていきましょう
ここでは、エージェントが RL フレームワークの各ステップをどのように進めるのかを示します。上記で説明してきたように、モデルは最初にランダムな行動を予測しますが、いくつかの学習ラウンドを繰り返していくと、より賢くなります。
def step(self, action):
# First, react to the actions and adjust the fleet
turn_on_machines = int(action[0])
turn_off_machines = int(action[1])
self.active_machines = max(0, self.active_machines - turn_off_machines
warmed_up_machines = self.warmup_queue[0]
self.active_machines = min(self.active_machines + warmed_up_machines
self.warmup_queue = self.warmup_queue[1:] + [turn_on_machines]
# Now react to the current load and calculate reward
self.current_load = self.load_simulator.time_step_load()
reward = self._react_to_load()
self.t += 1
done = self.t > self.max_time_steps
return self._observation(), reward, done, {}
Amazon SageMaker におけるトレーニング
さて、他の SageMaker モデルのように、私たちのモデルを学習できる準備ができました。イメージネーム(ここでは、TensorFlow や Intel Coach )、インスタンスタイプなどを入力しましょう。
rlestimator = RLEstimator(role=role,
framework=Framework.TENSORFLOW,
framework_version='1.11.0',
toolkit=Toolkit.COACH,
entry_point="train-autoscale.py",
train_instance_count=1,
train_instance_type=p3.2xlarge)
rlestimator.fit()学習ログを見ると、エージェントは最初は学習をせず、環境を探索していることがわかります。これはヒートアップフェーズと呼ばれ、学習のための初期データセットの生成しています。
## simple_rl_graph: Starting heatup
Heatup> Name=main_level/agent, Worker=0, Episode=1, Total reward=-39771.13
Heatup> Name=main_level/agent, Worker=0, Episode=2, Total reward=-3089.54
Heatup> Name=main_level/agent, Worker=0, Episode=3, Total reward=-43205.29
Heatup> Name=main_level/agent, Worker=0, Episode=4, Total reward=-24542.07
...ヒートアップフェーズが完了すると、モデルは学習の繰り返しサイクル(ポリシー学習)に入り、すでに学習済みの結果をもとに探索をします。
Policy training> Surrogate loss=-0.09095033258199692, KL divergence=
Policy training> Surrogate loss=-0.1263471096754074, KL divergence=0.00145535240881145
Policy training> Surrogate loss=-0.12835979461669922, KL divergence=
Policy training> Surrogate loss=-0.12992703914642334, KL divergence=
....
Training> Name=main_level/agent, Worker=0, Episode=152, Total reward
Training> Name=main_level/agent, Worker=0, Episode=153, Total reward
Training> Name=main_level/agent, Worker=0, Episode=154, Total rewardモデルが設定されたエポック数に達すると、学習が完了します。この場合、学習に18分かかりました。モデルがどのように学習されたかみてみましょう。

学習の可視化
可視化の1方法として、探索のイテレーションごとにエージェントが得た報酬をプロットしてみました。期待されたように、ヒートアップフェーズ(150イテレーション)では、エージェントは学習を行わないため、極端に負の値となっています。そこから学習が適用されていくうちに報酬はすぐに向上し始めます。
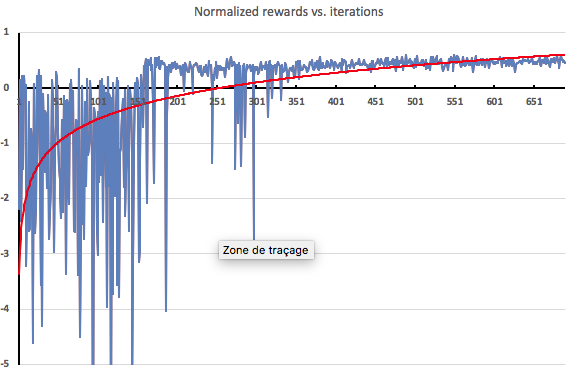
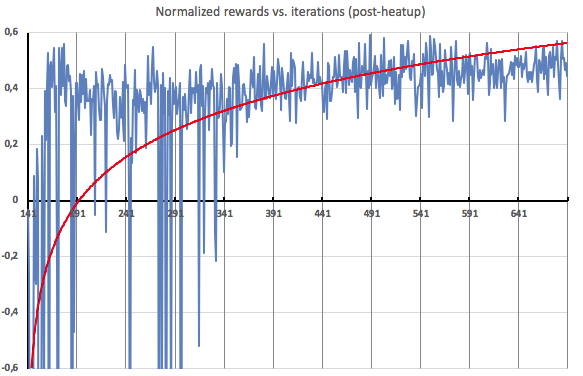
こちらは、ヒートアップ後のイテレーションの拡大図です。見てわかるように、約半分くらいのところから、エージェントがかなり定常的に正の報酬を受け取るようになります。これは、負荷プロファイルに対して、効果的なスケーリングが適用されていることを示しています。
モデルのデプロイ
学習モデルが満足なものになったら、これまでの SageMaker と同様にデプロイが可能で、新しく作成された推論用 HTTPS エンドポイントを使うことができます。
今すぐご利用可能です
この記事がお役に立てば幸いです。なんとか Amazon SageMaker RL でできること、のほんの触りをご紹介することができました。Amazon SageMaker が利用可能なすべてのリージョンで、本機能もお使いいただけます。ぜひ、試してみてください。そして、感想を教えてください。皆様がどんなモデルを実装されるのか、楽しみです!
— Julien
[1] “Deep Reinforcement Learning for Building HVAC Control”, T. Wei, Y. Wang and Q. Zhu, DAC’17, June 18-22, 2017, Austin, TX, USA.
翻訳は Machine Learning SA の宇都宮が担当しました。原文は、こちら。