Amazon Web Services ブログ
AWS Lake Formation でデータレイクを構築、保護、管理
データレイクとは、複数の分析アプローチおよびグループによる分析向けの、多様なデータタイプの集中型ストアです。多くの組織がデータをデータレイクに移行させています。この記事では、AWS Lake Formation を使用してデータレイクを構築、保護、管理する方法を紹介します。
従来、組織は、オンプレミスデータウェアハウスアプライアンスといった柔軟性に欠ける単一目的用のシステムにデータを保持していました。同様に、事前定義済み BI レポートといった単一の方法でデータを分析してきました。データベース間でデータを移行する、または機械学習 (ML、machine learning) や即席の SQL クエリ実行といったさまざまなアプローチでの使用に向けてデータを移行する際には、分析に先んじて “抽出、変換、ロード” (ETL、extract, transform, load) 処理を行う必要がありました。こうした従来の手法は、うまくいったとしても非効率的で遅延がつきものでした。そして最悪の場合には、セキュリティが複雑化します。
対照的に、クラウドベースのデータレイクを利用すると、より柔軟な分析に構造化データおよび非構造化データを使用できるようになります。IT スタッフは、規模を問わずデータを前もって集計、整理、準備、保護できます。そして、アナリストおよびデータサイエンティストは、適切な使用ポリシーに準拠しながら、準備されたデータにお好みの分析ツールでアクセスできます。
データレイクを使用すると、複数の分析手法を組み合わせて、従来のデータストレージおよび分析では不可能だった価値あるインサイトの取得を実現できます。ある小売シナリオでは、ML を用いた手法によって、詳細な顧客プロフィールが検出されたほか、ウェブブラウジング操作、購入履歴、サポート記録、さらにはソーシャルメディアから収集された個人特定に繋がらないデータに基づくコホートが検出されました。これは、リアルタイムの、ストリーミングされる、インタラクティブな顧客データにデプロイされた ML モデルの実例です。
こうしたモデルは、買い物かごを分析して瞬時に “次のおすすめ商品” を提示したり、即座に販売促進策を実施したりといったことに成功しました。マーケティングとサポートのスタッフは、顧客の収益性と満足度をリアルタイムに調査し、新しい売上向上策を立案できました。データレイクを使用すると、このような分析手法の組み合わせにより多様なデータストリームを統合して、データサイロからは得られないインサイトを取得できます。
データレイク構築の課題
残念ながら、データレイクの構築、保護、管理の開始は、複雑で時間のかかるプロセスであり、しばしば数か月を要します。 クラウド上でのデータレイク構築にも、時間のかかる多くの手動の手順が必要です。
- ストレージのセットアップ。
- データの移行、クリーニング、準備、カタログ化。
- 各サービスのセキュリティポリシーの設定および適用。
- ユーザーに対するアクセス権限の手動での付与。
複数のサービスで処理および分析ができるよう、データをデータレイクで集中管理したいとお考えでしょう。しかし、環境の整備と保護には忍耐が必要です。
現在、IT スタッフおよびアーキテクトは、データレイクの作成、セキュリティの設定、データリクエストへの応答に、膨大すぎる時間を費やしています。これらの人員が、データリソースのキュレーターとして、またはアナリストとデータサイエンティストのアドバイザーとしてこの時間を使えるようになるでしょう。アナリストおよびデータサイエンティストは、必要なデータへのアクセスを、このセットアップが終わるまで待たなければなりません。
次の図はデータレイクのセットアッププロセスを示しています。
 ストレージのセットアップ
ストレージのセットアップ
データレイクには膨大な量のデータが保持されます。何よりもまず、その全データを保持するストレージをセットアップする必要があります。AWS を利用中の場合、Amazon S3 バケットとパーティションを設定します。オンプレミスでデータレイクを構築する場合、ハードウェアを調達して、全データを保存するための大規模ディスクアレイをセットアップします。
データの移行
オンプレミスおよびクラウド上のさまざまなデータソースに接続し、IoT デバイス上のデータを収集します。次に、それらのソースから関連データセットを収集して整理し、データをクロールしてスキーマを抽出し、カタログにメタデータタグを付加します。次のような一連のファイル転送ツールや ETL ツールを使用できます。
- AWS Glue
- AWS Database Migration Service (AWS DMS)
- Amazon Kinesis
- Amazon Managed Streaming for Apache Kafka (Amazon MSK) (新規)
- AWS Transfer for SFTP サービス (新規)
- AWS Snowball
データのクリーニングおよび準備
次に、収集したデータのパーティション分割、インデックス作成、列指向形式への変換を慎重に行い、パフォーマンスとコストを最適化する必要があります。関連レコードのクリーニング、重複削除、一致を行う必要があります。
現在、組織はこうしたタスクを柔軟性に欠ける複雑な SQL ステートメントを使用して完了させています。こうしたステートメントの動作は信頼性にかけるうえ、管理が困難です。受信データを収集、クリーニング、変換するというこの複雑なプロセスは、エラーを回避するために手動でのモニタリングを必要とします。多くのお客様がこのタスクに AWS Glue を使用しています。
ポリシーの設定および適用
お客様および規制当局は、組織が機密性の高いデータを保護することを要求します。コンプライアンスは、データアクセスポリシー、保護ポリシー、コンプライアンスポリシーの作成および適用に関わります。たとえば、個人特定に繋がる情報 (PII、personally identifiable information) へのアクセスをテーブル、列、または行レベルで制限したり、全データを暗号化したり、誰がデータにアクセスしているかの監査ログを保持したりといったことが行われています。
現在、S3 バケットのアクセスコントロールリストまたはサードパーティーの暗号化ソフトウェアおよびアクセスコントロールソフトウェアを使用してデータを保護することができます。データへのアクセスが必要な各分析サービス用に、データアクセスポリシー、保護ポリシー、コンプライアンスポリシーを作成および管理します。たとえば、Amazon Redshift と Amazon Athena を使用してデータレイクに対して分析を実行している場合、これらの各サービス用にアクセスコントロールルールをセットアップする必要があります。
多くのお客様が AWS Glue データカタログリソースポリシーを使用してデータへのメタデータアクセスを設定および制御しています。Apache Ranger が使用されるケースもあります。しかしこうしたアプローチは困難で限定的な可能性があります。S3 ポリシーで提供されるのはせいぜいテーブルレベルのアクセスです。また、データおよびメタデータのポリシーは別々に管理しなければなりません。Apache Ranger を使用すると、メタデータアクセスを一度に 1 つのクラスターだけに設定することができます。また、ポリシーは、組織内でデータレイクにアクセスするユーザーやチームの数が増えるにつれて冗漫になることが考えられます。
データ検出の簡素化
アナリストやデータサイエンティストといったさまざまなニーズを持つユーザーは、データレイクの関連データセットを検出および信頼するのに苦労することがあります。ユーザーが簡単に関連する信頼済みデータを検出できるようにするには、データレイクカタログでデータに対して明確にラベル付けを行う必要があります。IT スタッフに要請することなく、ユーザーがこのデータに対するアクセスと分析を行えるようにします。
現在、これらの各手順には手動での作業が多く伴います。お客様が行う作業には、データアクセスおよび変換ワークフローの構築、セキュリティおよびポリシー設定のマッピングがあるほか、データ移行、ストレージ、カタログ化、セキュリティ、分析、ML 用のツールおよびサービスの設定が含まれます。こうした手順すべてを行う必要があるため、生産性に優れたデータレイクの実装には数か月かかる場合があります。
幅広い AWS のサービスが、ストレージ、コンピューティング、分析、セキュリティに関する多数の選択肢を含む、データレイクの構成要素すべてを提供しています。 AWS は 13 年近くにわたってエクサバイト規模のデータを保持する Amazon S3 を運営してきました。同サービスはデータレイクに最もおすすめの選択肢にもなっています。AWS Glue を使用すると、データカタログの使用およびサーバーレス変換が可能になります。Amazon EMR では、Apache Spark や Apache Hadoop といったマネージド型ビッグデータ処理フレームワークを利用できます。Amazon Redshift Spectrum では、Amazon S3 のデータに対して直接データウェアハウス機能を提供します。Athena ではサーバーレス SQL クエリを実行できます。
こうした利用可能なサービスすべてを使用して、長年にわたり数々のお客様が AWS でデータレイクを構築しています。AWS は S3 で 10,000 を超えるデータレイクを運用しています。その多くで、AWS Glue を使用した AWS Glue データカタログの共有や Apache Spark でのデータ処理が行われています。
AWS は、AWS で分析を実行する数千ものお客様から、分析を実行したいほとんどのお客様がデータレイクの構築も望んでいることを学びました。しかし、お客様の多くが、このプロセスを現在よりもさらに簡単かつ迅速に行えるようにしたいと望んでいます。
AWS Lake Formation (現在一般提供中)
AWS re:Invent 2018 で、AWS は Lake Formation を発表しました。Lake Formation は数日でセキュアなデータレイクを構築するための新しいマネージド型サービスです。見逃した方は、こちらから Andy Jassy による基調講演をご覧ください。Lake Formation にはいくつかの利点があります。
- データの特定、取り込み、クリーニング、変換: Lake Formation を使用すると、データをより迅速に移行、保存、カタログ化、クリーニングできます。
- 複数のサービスに対するセキュリティポリシーの適用: データソースがセットアップされたら、セキュリティ、ガバナンス、監査のポリシーを 1 か所で定義して、全ユーザーおよび全アプリケーションに適用できます。
- 新しいインサイトの取得および管理: Lake Formation を使用すると、利用可能なデータセットと適切なビジネスユースを記述したデータカタログを構築できます。このカタログにより、分析に適したデータセットの検出が支援され、ユーザーの生産性が高まります。
次のスクリーンショットは、Lake Formation とその機能を示しています。
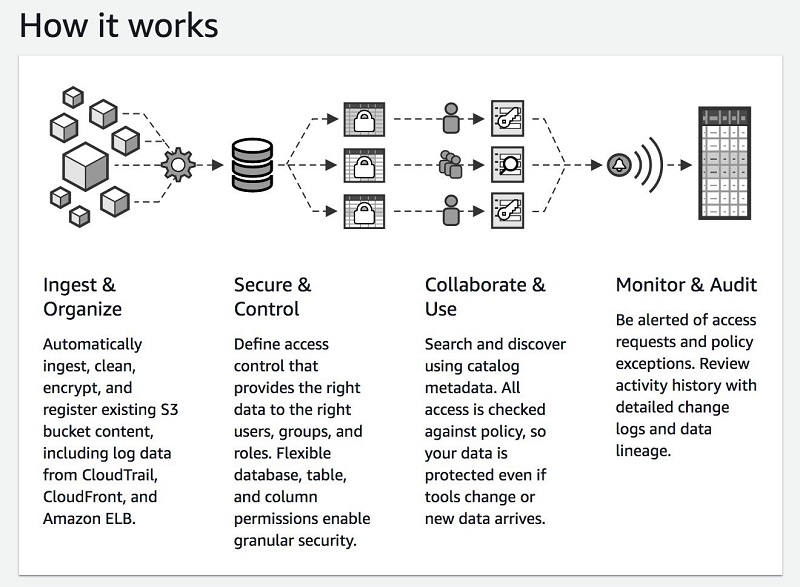
データレイクの作成方法
Lake Formation のストレージレイヤーは、S3 が形成します。S3 を既に使用中の場合、データを保持している既存の S3 バケットを登録するのが一般的な開始方法です。Lake Formation によってデータレイク用の新しいバケットが作成され、そのバケットにデータがインポートされます。AWS では常にお使いのアカウントにこのデータを保存します。このデータにはユーザーだけがダイレクトアクセスできます。
データが Lake Formation にロックインされることはありません。AWS では、CSV、ORC、または Parquet といった標準的な形式でデータが保存されるため、保存されたデータは AWS またはサードパーティーが提供するさまざまな分析ツールで使用可能です。
また、Lake Formation では S3 のデータのパーティション分割が最適化されるため、パフォーマンスが向上しコストが削減されます。お客様がロードする raw データは、小さすぎる (余分な読み取りが必要) または大きすぎる (必要以上のデータ読み取りが発生する) パーティションに存在する場合があります。Lake Formation では、サイズ、時間、または関連するキーを基準にデータを整理し、最も普及しているクエリ向けに高速スキャンおよび並列分散読み取りを実現します。
データのロードおよびメタデータのカタログ化方法
Lake Formation では、データのロードおよびカタログ化に設計図の概念を用いています。初回のロードに対して設計図を 1 回実行するか、または増分に対応できるよう設定し、新しいデータを追加して利用可能にすることができます。
Lake Formation を使用すると、Amazon RDS で運用される、または Amazon EC2 でホストされる MySQL、Postgres、SQL Server、MariaDB、Oracle データベースからデータをインポートできます。Java Database Connectivity (JDBC) に接続して、オンプレミスデータベースからインポートすることもできます。
Lake Formation にデータソースを指定し、データレイクにロードするために場所を特定し、ロードする頻度を指定します。設計図によって、ソーステーブルスキーマが検出され、データが自動的にターゲットデータ形式に変換され、パーティション分割スキーマに基づいてデータがパーティション分割され、処理済みのデータが追跡されます。これらのアクションはすべてカスタマイズ可能です。
設計図はサポートサービスとして AWS Glue を利用します。AWS Glue クローラは、取り込む raw データに対して接続および検出を行います。AWS Glue のコード生成およびジョブにより取り込みコードが生成され、データがデータレイクに取り込まれます。Lake Formation ではメタデータの整理に同じデータカタログが使用されます。AWS Glue はクローラとジョブをまとめ、個々のワークフローのモニタリングを可能にします。このように、Lake Formation は本質的に AWS Glue の拡張機能のようなものです。
次の図は、設計図ワークフローとインポートの画面を示しています。
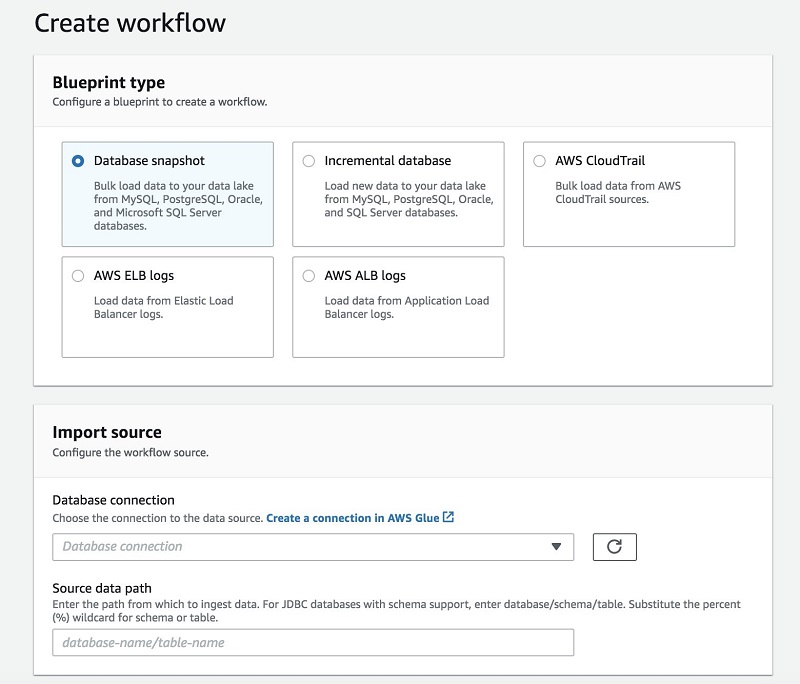
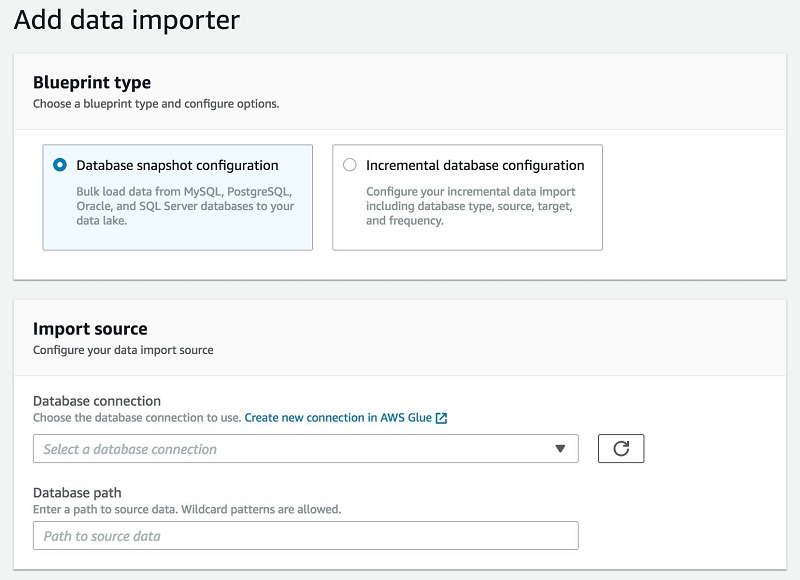
分析に向けてデータを変換および準備する方法
AWS Glue と同じ ETL 機能をサポートしているのに加え、Lake Formation には新しい Amazon ML 変換が導入されています。この機能には、4 億超のレコードの重複を 2 時間半未満で削除できるファジー論理ブロッキングアルゴリズムが含まれています。このアルゴリズムは、従来のものよりもはるかに優れたアプローチです。
Amazon ML 変換を使用してデータを一致させその重複を削除するにはまず、関連データセットをマージします。Amazon ML 変換によってこれらのセットはトレーニング用およびテスト用のサンプルに分割され、完全一致とあいまい一致を検出するためにスキャンされます。精度向上のためにデータとサンプルを増やし、これらを本稼働させて、新しいデータがデータレイクにやって来る際にそのデータを処理させることができます。パーティション分割アルゴリズムには最低限のチューニングしか必要ありません。信頼度レベルにはグループ化の品質が反映されています。より即席的な従来のアルゴリズムよりも改善されています。次の図は、この一致と重複削除のワークフローを示しています。
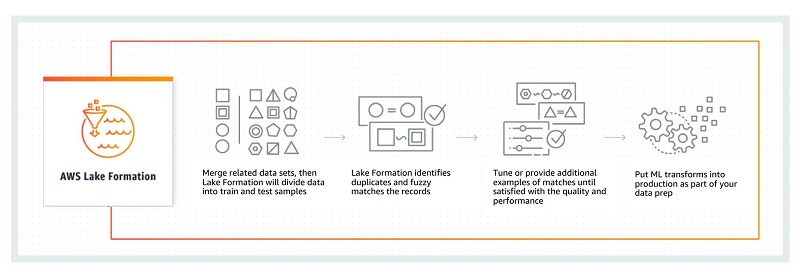
Amazon.com では現在、社内で大規模に小売ワークロードに関して Amazon ML 変換を使用、評価中です。Lake Formation ではこれらのアルゴリズムを公開しているため、複雑で脆弱な SQL ステートメントを作成してレコードの一致と重複削除を処理するストレスから解放されます。Amazon ML 変換を使用すると、分析前のデータの品質を向上させることができます。詳細については、Fuzzy Matching and Deduplicating Data with Amazon ML Transforms for AWS Lake Formation を参照してください。
アクセスコントロール許可を設定する方法
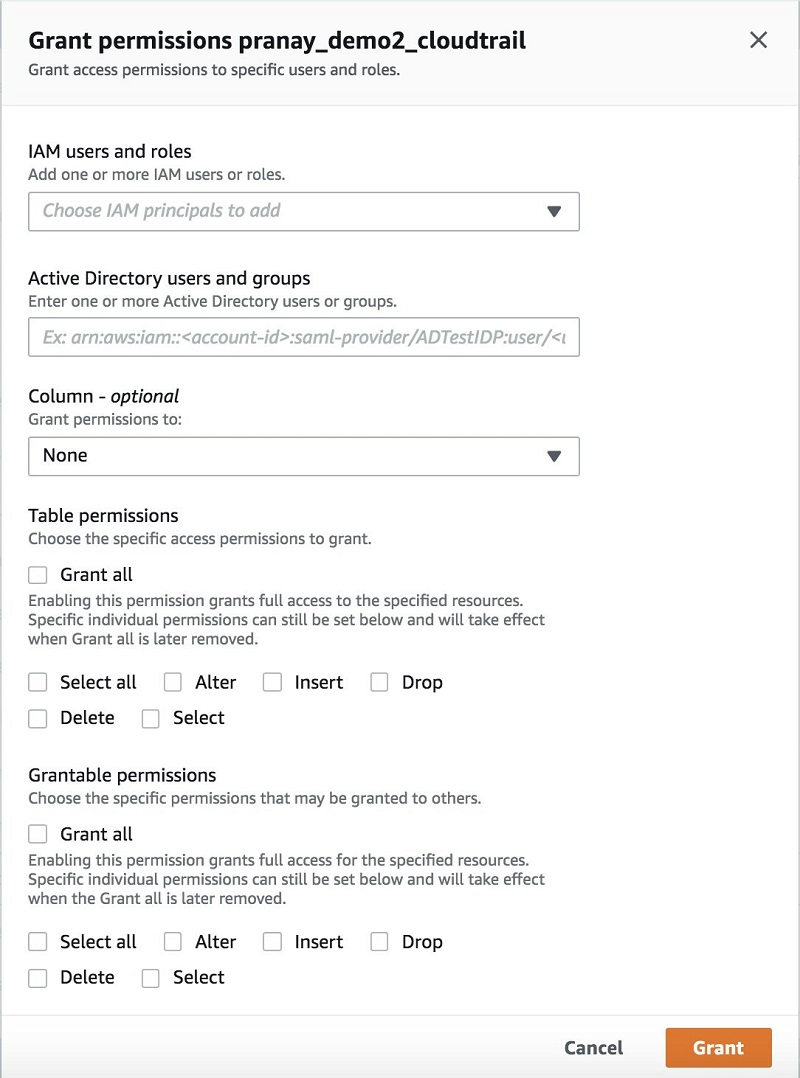
Lake Formation では、シンプルに “データ (セット) へのアクセス許可の付与と取り消し” を行うことで、ポリシーを定義してきめ細かくデータアクセスを制御することができます。 IAM ユーザー、ロール、グループ、およびフェデレーションを使用している Active Directory ユーザーにアクセス許可を割り当てることができます。バケットやオブジェクトではなく、カタログオブジェクト (テーブルや列など) に対するアクセス許可を指定します。
ユーザーに付与されたデータポリシーすべてを 1 か所で、簡単に確認および監査できます。ユーザー、ロール、またはグループに付与されたアクセス許可はダッシュボードで検索および確認できます。付与されたアクセス許可を検証して、必要な場合には簡単にポリシーを取り消すことが可能です。次のスクリーンショットは、アクセス許可の付与のコンソールを示しています。

データを分析に利用できる状態にする方法
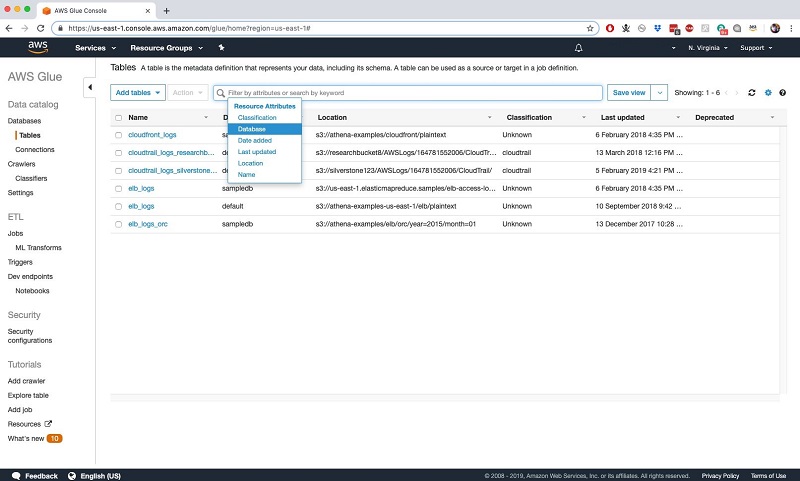
Lake Formation では、統合されたテキストベースのファセット検索を全メタデータに対して行えるため、分析に利用可能なデータセットのカタログにセルフサービスでアクセスできます。このカタログには検出されたスキーマ (前述) が含まれており、データの所有者、スチュワード、その他ビジネス固有の属性といった属性をテーブルプロパティとして追加できます。
よりきめ細かいレベルでは、データの機密性レベル、列定義、その他属性を列プロパティとして追加することもできます。こうしたあらゆるプロパティでデータを検索可能です。しかし、アクセスはユーザーのアクセス許可に依存します。次の AWS Glue [テーブル] タブのスクリーンショットを参照してください。
アクティビティをモニタリングする方法
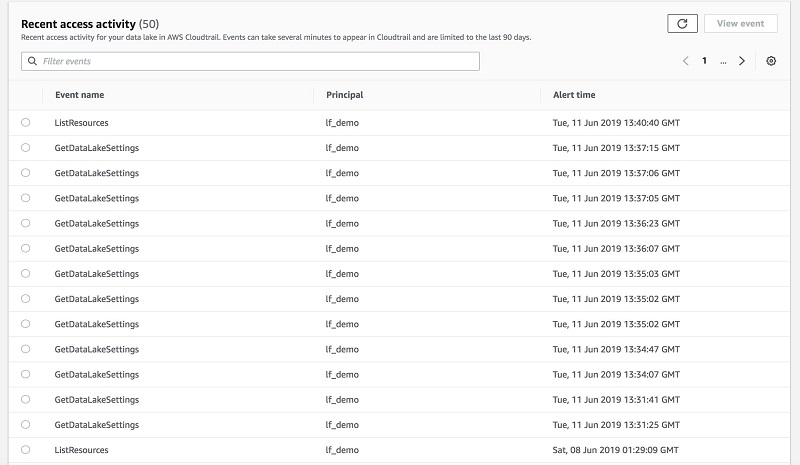
Lake Formation では、ダッシュボードで詳細なアラートを確認して、さらなる分析のために監査ログをダウンロードすることもできます。
Amazon CloudWatch により、すべてのデータ取り込みイベントおよびカタログ通知が発行されます。こうすることで、不審な行為の特定や、またはルールの順守の実証を行うことが可能です。
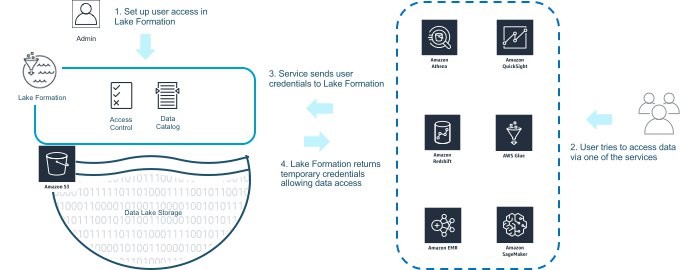
Lake Formation を使用してアクセスをモニタリングしたり制御したりするには、まず、前述のようにアクセスポリシーを定義します。データを分析したい場合は、Amazon EMR for Spark、Amazon Redshift、または Athena といった AWS の分析サービスから直接データにアクセスします。あるいは、Amazon QuickSight または Amazon SageMaker を使用して間接的にアクセスします。
使用するサービスによって Lake Formation にユーザー認証情報が転送され、アクセス許可が検証されます。その後、次の図に示されているように、Lake Formation は S3 のデータへのアクセス権限を付与する一時的な認証情報を返します。ユーザーがアクセス権限を取得すると、分析サービスと S3 の間で直接実際のデータの読み取りおよび書き込み操作が実行されます。このアプローチを用いると、重要なデータ処理パスにおける中継のニーズから解放されます。
次のスクリーンショットと図は、Lake Formation を使用してアクセスをモニタリングおよび制御する方法を示しています。
まとめ
ほんの数ステップで、S3 にデータレイクをセットアップし、すぐにクエリ可能な状態のデータの取り込みを開始することができます。開始するには、Lake Formation コンソールにアクセスして、データソースを追加します。Lake Formation はそれらのソースをクロールし、データを新しい S3 データレイクに移行させます。
Lake Formation では、S3 パーティションへのデータの配置、Apache Parquet や ORC といったより高速な分析が可能な形式へのデータの変換、機械学習を利用したレコードの一致および重複削除を介したデータ品質の向上が、自動で行われます。
データレイクのアクセス許可はすべて、単一のダッシュボードからセットアップ可能です。それらのアクセス許可は、データレイクのデータにアクセスする全サービスに対して実装されます。これには、分析サービスおよび ML サービス (Amazon Redshift、Athena、Apache Spark ワークロードを扱う Amazon EMR) などが含まれます。Lake Formation を使用すると、複数のサービスにわたってポリシーを再定義する苦労から解放され、それらのポリシーを一貫して適用および順守することができます。
こちらで AWS Lake Formation の開始方法を参照してください。
著者について
 Nikki Rouda は AWS でデータレイクおよびビッグデータのプリンシパルプロダクトマーケティングマネージャーを務めています。Nikki は 20 年以上にわたり 40 か国以上で、エンタープライズが分析と IT インフラストラクチャの課題に対するソリューションを開発、実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。
Nikki Rouda は AWS でデータレイクおよびビッグデータのプリンシパルプロダクトマーケティングマネージャーを務めています。Nikki は 20 年以上にわたり 40 か国以上で、エンタープライズが分析と IT インフラストラクチャの課題に対するソリューションを開発、実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。
 Prajakta Damle は、アマゾン ウェブ サービスのプリンシパルプロダクトマネージャーです。
Prajakta Damle は、アマゾン ウェブ サービスのプリンシパルプロダクトマネージャーです。