Amazon Web Services ブログ
Amazon Redshift を使用したレイクハウスアーキテクチャの ETL および ELT 設計パターン: パート 1
このマルチポストシリーズのパート 1 では、プライマリおよび短期の Amazon Redshift クラスターの両方を使用して、スケーラブルな ETL (抽出、変換、ロード) と ELT (抽出、ロード、変換) データ処理パイプラインを構築するための設計のベストプラクティスについて説明します。また、Amazon Redshift Spectrum、Concurrency Scalingといった Amazon Redshift の主要な機能に関するユースケースや、最近開始したデータレイクエクスポートのサポートについても見ていきます。
このシリーズのパート 2、Amazon Redshift を使用したレイクハウスアーキテクチャの ETL および ELT 設計パターン: パート 2 では、ETL と ELT のユースケースで Amazon Redshift を使い始めるための手順を順を追って説明します。
ETL と ELT
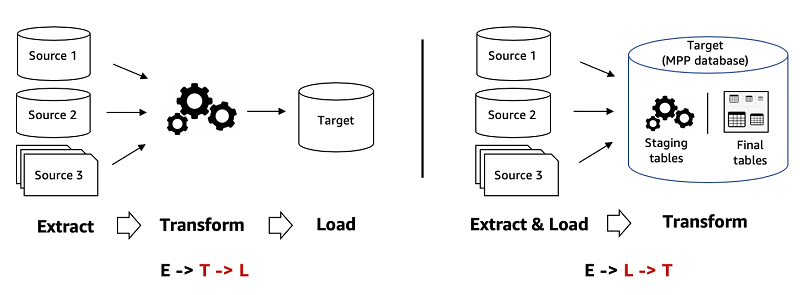
ソースシステムからデータウェアハウスにデータを移行する場合、一般的な設計パターンが 2 つあります。2 つのパターンの主な違いは、データ処理パイプライン内の変換が発生する点です。これにより、データの取り込みと変換に使用するツールのセット、データの分析に使用する基礎となるデータ構造、クエリ、最適化エンジンも決定されます。最初のパターンは ETL で、データをデータウェアハウスにロードする前に変換します。2 番目のパターンは ELT です。これは、データをデータウェアハウスにロードし、使い慣れた SQL セマンティクスと超並列処理 (MPP) アーキテクチャの能力を使用します。これにより、データウェアハウス内で変換を実行します。
次の最初の図は ETL です。この図では、Amazon EMR または AWS Glue で Apache Spark や Apache Hive などのツールを使用してデータウェアハウスの外部でデータ変換を実行しています。このパターンを使用すると、データ変換に適したツールを選択できます。2 番目の図は ELT です。この図では、リレーショナルおよび SQL ワークロード用のデータウェアハウスにデータ変換エンジンが組み込まれています。このパターンは、MPP アーキテクチャの高度に最適化されたスケーラブルなデータストレージとコンピューティング能力を使用するため、強力です。
Redshift Spectrum
Amazon Redshift は、AWS 上の完全マネージド型のデータウェアハウスサービスです。分散型、MPP、および何も共有しないアーキテクチャを使用します。Redshift Spectrum は Amazon Redshift のネイティブ機能です。これにより、データレイクにオープンファイル形式で保存されているすべてのデータに対して現在使用している BI アプリケーションと SQL クライアントツールを使用して、Amazon Redshift の使い慣れた SQL を実行できます (Amazon S3)。
フォローできる一般的なパターンは、外部テーブルにスキーマバインディングのないビューを使用して、Amazon Redshift にローカルに保存された頻繁にアクセスする「ホット」なデータと、Amazon S3 にコスト効率よく保存された「ウォーム」または「コールド」データの両方にまたがるクエリを実行することです。これにより、さまざまなユースケースに合わせて、クラスターおよび S3 全体でコンピューティングリソースとストレージを個別にスケーリングできます。
Redshift Spectrum は、Apache Parquet、Avro、CSV、ORC、JSON など、さまざまな構造化および非構造化ファイル形式をサポートしています。S3 に保存されているデータはオープンファイル形式であるため、同じデータが信頼できる唯一のソースとして機能し、Amazon Athena、Amazon EMR、Amazon SageMaker などの他のサービスが S3 データレイクから直接アクセスできます。
詳細については、「Amazon Redshift Spectrum がデータウェアハウジングをエクサバイトに拡張—読み込み不要」を参照してください。
同時実行スケーリング
同時実行スケーリングを使用して、Amazon Redshift はクエリ処理能力を自動的かつ柔軟にスケーリングし、数百の同時クエリに対して一貫して高速なパフォーマンスを提供します。同時実行性のスケーリングリソースは、同時実行性が増加するにつれて、数秒で透過的に Amazon Redshift クラスターに追加され、同時リクエストの突然のスパイクに待機時間なしで高速なパフォーマンスで対応します。ワークロードの需要が落ち着くと、Amazon Redshift は同時実行スケーリングリソースを自動的にシャットダウンして、コストを節約します。
次の図は、同時実行スケーリングが高レベルでどのように機能するかを示しています。

詳細については、「新機能 – Amazon Redshift の同時実行スケーリング – 常時ピーク時のパフォーマンス」を参照してください。
データレイクのエクスポート
Amazon Redshift は、Apache Parquet にある S3 のデータレイクへのクエリの結果のアンロードをサポートしています。Apache Parquet は、分析のための効率的なオープンなカラムナストレージ形式です。Parquet 形式は、テキスト形式と比較して、S3 でのアンロードが最大 2 倍速く、ストレージの消費量が最大 6 倍少なく済みます。また、1 つ以上のパーティション列を指定して、アンロードされたデータを S3 バケット内のフォルダに自動的にパーティション化されるようにもできます。これにより、クエリのパフォーマンスを改善し、アンロードされたデータのダウンストリーム消費のコストを下げられます。たとえば、マーケティングデータをアンロードして、年、月、および日の列でパーティション分割することができます。これにより、クエリでパーティションのプルーニングを利用し、パーティション分割された列でフィルタリングされた場合に無関係なパーティションのスキャンをスキップできます。これにより、クエリのパフォーマンスが向上し、コストが削減されます。詳細については、「UNLOAD」を参照してください。
ユースケース
データ管理およびデータ統合の必要上、Amazon Redshift を部分的または完全に使用されているかもしれません。MPP データベースの出現により、ワークロードが主にリレーショナルであるため、使い慣れた SQL 構文のため、MPP アーキテクチャの大規模なスケーラビリティのために、ETL アプローチから ELT アプローチに移行したかもしれません。
このセクションでは、Amazon Redshift を使用してデータ処理パイプラインを設計するための ELT および ETL の一般的なユースケースを示します。
ELT
適度な量のリレーショナルデータと構造化データで標準の SQL 結合と集計を必要とするバッチデータ処理ワークロードを考えてみましょう。SQL のニーズを満たすために、最初に Hadoop ベースのソリューションを選択しました。ただし、時間の経過とともに、データが増加し続けると、システムは適切に拡張できませんでした。必要なパフォーマンス SLA の目標を達成することは困難であることがわかり、増え続けるハードウェアとメンテナンスのコストに気をもむことになるでしょう。リレーショナル MPP データベースは、パフォーマンスとコストの点で利点をもたらし、使い慣れた SQL を使用してデータを処理するための技術的な障壁を下げます。
Amazon Redshift は、非常にスケーラブルで完全に管理されたコンピューティングの大きな利点があり、S3 のデータレイクから直接構造化および半構造化データを処理します。
次の図は、CTAS (Create Table As) コマンドを使用して、Redshift Spectrum によりデータ処理パイプラインを 4 段階から 1 段階のプロセスに簡素化および高速化する方法を示しています。

上記のアーキテクチャにより、Amazon Redshift データウェアハウスソリューションと、ERP、金融、サードパーティなどの他のエンタープライズデータセットをホストする S3 上の既存のデータレイクソリューションとの間でシームレスな相互運用が可能になり、さまざまなデータ統合ユースケースで利用できます。
次の図は、Amazon Redshift と S3 のデータレイク間のシームレスな相互運用性を示しています。

ELT パターンを使用する場合、オンプレミスのデータウェアハウスから Amazon Redshift に移行する際、既存の ELT 最適化 SQL ワークロードを使用することもできます。これにより、リレーショナルおよび複雑な SQL ワークロードを新しいコンピューティングフレームワークに一から書き直す必要がなくなります。Amazon Redshift により、使い慣れた SQL を使用して、データを効率的にロード、変換、および強化できます。これにより、高度で堅牢な SQL サポートが得られ、シンプルさ、既存の SQL ツールとのシームレスな統合を実現できます。また、クラスター用に Amazon Redshift が提供するモニタリング機能も必要です。
ETL
Amazon Redshift からデータレイク (S3) にデータのサブセットをアンロードして、分析に最適化されたオープンなカラムナーファイル形式 (Parquet) で戻す必要があります。次に、Redshift Spectrum と、アドホックおよびオンデマンド分析用の Athena、ETL 用の AWS Glue と Amazon EMR、機械学習用の Amazon SageMaker などの他の AWS のサービスを使用して、データレイクからアンロードされたデータセットをクエリします。
データレイクの複数のビジネスプロセス間で、キュレーションされたメトリクスセット (Amazon Redshift で計算) の単一バージョンを共有する必要があります。Amazon Redshift で ELT を使用してこれらのメトリクスを計算し、最適化されたファイル形式とパーティションでアンロード操作を行って、計算されたメトリクスをデータレイクにアンロードできます。
また、使い慣れた SQL を使用して、データレイク (S3) コールドストレージに格納された大規模なデータセットでエンドユーザーから一般的に要求される一連のメトリクスを事前に集計し、データレイクで集計されたメトリクスをアンロードすることで、ダウンストリームで消費できるようにする必要があります。言い換えれば、S3 に短時間保存されたかなり大量のリレーショナルデータと構造化されたコールドデータに対して標準 SQL の結合と集計を必要とするバッチワークロードを考えてみてください。1 つ以上の短命 Amazon Redshift クラスターをスピンアップすることにより、Redshift Spectrum の力を活かすことができます。これにより、S3 に保存されているデータに対して必要な SQL 変換を実行し、最適化されたファイル形式で変換結果を S3 にアンロードし、処理の最後に不要な Amazon Redshift クラスター終了できます。この方法では、Amazon Redshift クラスターがワークロードにサービスを提供している期間のみ料金を支払います。
次の図に示すように、変換された結果が S3 でアンロードされると、データレイクからアンロードされたデータをクエリします。その際、既存の Amazon Redshift クラスターがある場合は Redshift Spectrum、従量制およびサーバーレスのアドホックおよびオンデマンドクエリモデルを備えた Athena、アンロードされたデータで ETL 操作を実行し、データレイクに保存されている他のデータセット (ERP、財務、サードパーティデータなど) とのデータ統合を行うための AWS Glue と Amazon EMR、および機械学習を行うための Amazon SageMaker を使用します。

Amazon Redshift の同時実行スケーリング機能を使用して、アンロード操作をスケーリングすることもできます。これにより、使い慣れた SQL を使用して、オープンで分析に最適化されたファイル形式でデータを一括エクスポートする、スケーラブルでサーバーレスのオプションが得られます。
ベストプラクティス
次の推奨プラクティスは、Amazon Redshift を使用して ELT および ETL ワークロードを最適化するのに役立ちます。
要件を分析して、ELT と ETL を決定する
Amazon Redshift の MPP アーキテクチャとその Spectrum 機能は効率的であり、大規模なリレーショナルおよび SQL ベースの ELT ワークロード (結合、集約) 用に設計されています。Amazon Redshift を使用して効率的な ELT ソリューションを設計する際、次の分析に十分な時間を費やすのが一般的です。
- ソースシステムからのデータのタイプ (構造化、半構造化、および非構造化)
- 必要な変換の性質 (通常、クレンジング、濃縮、調和、変換、集約を含む)
- 行ごとのカーソルベースの処理ニーズとバッチ SQL
- 長期にわたるデータ量の増加を考慮したパフォーマンス SLA とスケーラビリティ要件
- ソリューションのコスト
これは、ワークロードがリレーショナルであり、MPP 規模の SQL に適しているかどうかを評価するのに役立ちます。
ELT の重要な考慮事項
ELT と ELT の両方について、適切なデータ型と分散方法を使用したステージングテーブルを含むすべてのテーブルのパフォーマンスを向上させるために、適切な物理データモデルを構築することが重要です。結合が少ないディメンションデータモデル (スタースキーマ) は、ELT ベースの SQL ワークロードを含む MPP アーキテクチャに最適です。書き込みパフォーマンスを向上させるために、ELT プロセスで実行可能な中間ステージングテーブルに TEMPORARY テーブルを使用することを検討してみてください。これは、一時テーブルは単一のコピーのみを書き込むためです。
ELT ワークロードの一般的な経験則は、行ごとのカーソルベースの処理は避けることです (ストアドプロシージャで発見が見落とされがちなため)。このような処理は、Amazon Redshift などの MPP データベースのリーダーノードで実行する必要があるため、次善の策です。代わりに、このようなワークロードの推奨事項は、Apache Spark などの代替の分散処理プログラミングフレームワークを探すことです。
MPP アーキテクチャを使用して、トランザクションが非常に必要な場合に数百から数千の単一レコードを挿入、更新、削除することは、効率的ではありません。MPP アーキテクチャを使用する代わりに、一括操作としてテーブルで一括 UPDATE または DELETE/INSERT のいずれかのレコードをステージングします。
Redshift Spectrum の外部テーブル機能を使用すると、ステージングテーブルのデータを Amazon Redshift ローカルストレージに最初にロードしてから、それらのステージングテーブルで変換を行うのではなく、単一の SQL を使用して変換ロジックを最適化できます。
データレイクのエクスポートに関する重要な考慮事項
S3 で Amazon Redshift からデータレイクにデータをアンロードする場合、Amazon Redshift テーブルのデータスキューまたは処理スキューに注意してください。UNLOAD コマンドは、クラスター内のスライスの並列処理を使用します。したがって、保存中のデータスキューまたは実行時の処理スキューがある場合、S3 にアンロードされたファイルのファイルサイズは異なる可能性があり、データレイク内のアンロードされたデータの UNLOAD コマンド応答時間とクエリ応答時間に影響します。
また、ダウンストリーム消費のパフォーマンスを向上させるために、UNLOAD コマンドで最大ファイルサイズを約 100 MB 以下に制御する必要があります。同様に、S3 パーティションの場合、UNLOAD コマンドで低カーディナリティパーティション列 (年、四半期、月、日が適切な選択) を選択することにより、S3 のテーブルごとのパーティション数を数百まで超えないようにするのが目安です。これにより、パーティションが過剰に作成されることで、AWS Glue カタログに大量のメタデータが作成され、Athena および Redshift Spectrum を介したクエリ時間が長くなることを防ぎます。
並行して実行される複数の UNLOAD コマンドの同時実行で最高のスループットとパフォーマンスを得るには、同時実行スケーリングをオンにして、アンロードクエリ用の個別のキューを作成します。これにより、Amazon Redshift は必要に応じて追加の同時実行性スケーリングクラスターをバーストできます。
ELT の Redshift Spectrum の主な考慮事項
Redshift Spectrum から最高のパフォーマンスを得るには、クエリプランで S3 スキャン、投影、フィルタリング、集計などの可能な最大プッシュダウン操作に注意して、パフォーマンスを向上させてください。これは、Redshift Spectrum をサポートする強力なインフラストラクチャを利用するためです。述語プッシュダウンを使用すると、Amazon Redshift クラスター内のリソースの消費も回避されます。
さらに、複数の列で DISTINCT や ORDER BY などの複雑な操作を避け、必要に応じて GROUP BY に置き換えます。Amazon Redshift は、単一列 DISTINCT を GROUP BY として、その下のクエリ書き換え機能を使用して Spectrum コンピューティングレイヤーにプッシュダウンできますが、複数列の DISTINCT または ORDER BY 操作は Amazon Redshift クラスター内で行う必要があります。
Amazon Redshift オプティマイザーは、外部テーブル統計を使用して、より最適な実行プランを生成できます。統計情報がない場合、S3 テーブルが比較的大きいと仮定して、ヒューリスティックに基づいて実行計画が生成されます。S3 外部テーブルのテーブル統計 (numRows) を手動で設定することをお勧めします。
Amazon Redshift Spectrum のベストプラクティスの詳細については、「Amazon Redshift Spectrum の 12 のベストプラクティス」 と「Amazon S3 で AWS KMS 暗号化データのクロスアカウント Amazon Redshift COPY および Redshift Spectrum クエリを有効にする方法」を参照してください。
まとめ
この記事では、Spectrum、Concurrency Scaling、および最近リリースされたパーティション化によるデータレイクエクスポートのサポートといった Amazon Redshift のいくつかの主要な機能を使用して、データレイクアーキテクチャ用の ELT および ETL データ処理パイプラインを構築するための一般的なユースケースと設計のベストプラクティスについて説明しました。
このシリーズのパート 2、Amazon Redshift を使用したレイクハウスアーキテクチャの ETL および ELT 設計パターン: パート 2 では、AWS サンプルデータセットから数例を使用して、ステップバイステップのチュートリアルで使用の開始方法を説明します。
いつものように、AWS では皆さんのフィードバックをお待ちしています。コメント欄よりご意見やご質問をお送りください。
著者について
 Asim Kumar Sasmal は、AWS プロフェッショナルサービスのグローバルスペシャリティプラクティスの IoT 担当シニアデータアーキテクトです。彼は、AWS プラットフォームで専門的な技術コンサルティング、ベストプラクティスに関するガイダンス、実装サービスを提供することによって、世界中の AWS 顧客がデータ駆動型ソリューションを設計および構築するのを支援しています。彼は、顧客の要望から逆向きに取り組み、大きな思考を手助けし、AWS プラットフォームの力を活用して現実のビジネスの問題を深く掘り下げて解決することに情熱を注いでいます。
Asim Kumar Sasmal は、AWS プロフェッショナルサービスのグローバルスペシャリティプラクティスの IoT 担当シニアデータアーキテクトです。彼は、AWS プラットフォームで専門的な技術コンサルティング、ベストプラクティスに関するガイダンス、実装サービスを提供することによって、世界中の AWS 顧客がデータ駆動型ソリューションを設計および構築するのを支援しています。彼は、顧客の要望から逆向きに取り組み、大きな思考を手助けし、AWS プラットフォームの力を活用して現実のビジネスの問題を深く掘り下げて解決することに情熱を注いでいます。
 Maor Kleider は、Amazon Redshift のプリンシパルプロダクトマネージャーです。Amazon Redshift は、高速、シンプルかつコスト効率のよいデータウェアハウスです。お客様やパートナーの皆様と協働し、彼ら特有のビッグデータユースケースについて学び、その利用体験をよりよくすることに情熱を傾けています。余暇は、家族とともに旅行やレストラン開拓を楽しんでいます。
Maor Kleider は、Amazon Redshift のプリンシパルプロダクトマネージャーです。Amazon Redshift は、高速、シンプルかつコスト効率のよいデータウェアハウスです。お客様やパートナーの皆様と協働し、彼ら特有のビッグデータユースケースについて学び、その利用体験をよりよくすることに情熱を傾けています。余暇は、家族とともに旅行やレストラン開拓を楽しんでいます。