Amazon Web Services ブログ
Amazon SageMaker Clarify を使用して Bundesliga Match Facts xGoals を説明する
この記事は、Nick McCarthy、Luuk Figdor、Gabriel Anzer による Explaining Bundesliga Match Facts xGoals using Amazon SageMaker Clarifyを翻訳したものです。
AWS re: Invent 2020 の発表の中で最もエキサイティングだったものの 1 つは、機械学習 (ML) モデルのバイアスを検出し、モデル予測を説明するために設計された Amazon SageMaker の新機能である Amazon SageMaker Clarify でした。大規模な機械学習アルゴリズムによって予測が行われる今日の世界では、テクノロジーの大手企業にとって、機械学習モデルの予測に基づいて特定の決定を下した理由を顧客に説明できることがますます重要になっています。これは、基礎となるモデルが、インプットとアウトプットを観察することはできても、内部構造を観察することはできないクローズドボックスであることからの直接的な脱却であると考えることができます。これにより、モデルの構成を反復してさらに改善するために、さらなる解析ができるようになるだけでなく、これまで以上のレベルのモデル予測解析をお客様に提供することができます。
Clarify の特に興味深いユースケースの 1 つは、ドイツサッカーリーグ (DFL) からのもので、xGoals モデルの予測に関する興味深いインサイトを明らかにすることを目的として、AWS による Bundesliga Match Facts です。AWS による Bundesliga Match Facts は、世界中のブンデスリーガファンに、サッカーの試合中のより魅力的なファンエクスペリエンスを提供します。視聴者にシュートの難易度、お気に入りの選手のパフォーマンスに関する情報を提供し、チームの攻撃と守備の傾向を説明することができます。
Clarify により、DFL は、機械学習モデルが特定の xGoals 値を予測するための要因を決定する際に動作する、主要で基本的な特徴のいくつかをインタラクティブに説明できるようになりました。xGoals (Expected Goals の略) とは、ピッチ上の任意の位置からシュートした選手がゴールを決める確率を計算したものです。それぞれの特徴の特性を把握し、結果を説明することにより、モデルのデバッグに役立ち、その結果、より質の高い予測が可能になります。何よりも、このような透明性のレベルを高めると、機械学習モデルに対する信頼性が高まり、今後の協力や革新のための無数の機会が広がります。解釈のしやすさは、採用のしやすさにつながります。それでは、さっそくご紹介しましょう!
Bundesliga Match Facts
AWS による Bundesliga Match Facts は、ブンデスリーガの試合について公式の試合データからライブで生成された、高度なリアルタイム統計情報と詳細なインサイトを提供します。これらの統計は、国内外の放送局、DFL のプラットフォーム、チャンネル、アプリを介して視聴者に配信されます。これにより、世界中の 5 億人以上のブンデスリーガファンが、選手、チーム、リーグに関するより高度なインサイトを得ており、よりパーソナライズされたエクスペリエンスと次世代の統計情報の提供を受けています。
Bundesliga Match Facts xGoals を使用すると、DFL は選手がフィールド上のどの位置からシュートを打っても、ゴールを決める確率を評価することができます。ゴール成功率はシュートごとにリアルタイムで計算され、視聴者はシュートの難易度とゴールの可能性を知ることができます。xGoals 値が高いほど (値は 0~1 の間)、ゴールの可能性が高くなります。この投稿では、xGoals メトリクスを詳しく見て、基礎となる機械学習モデルの内部動作を調べ、個々のシュートとサッカーシーズンのデータ全体の両方において、xGoals が特定の予測を行う理由について明らかにしていきます。
トレーニングデータの準備と調査
Bundesliga xGoals の機械学習モデルは、これまでの xGoals モデルとは異なり、ゴールへのシュートのイベントデータと、25Hz のフレームレートを持つ高度なトラッキング技術から取得した高精度のデータを組み合わせています。ボールと選手のリアルタイムの位置情報に基づいて、ゴールへの角度、選手とゴールの距離、選手のスピード、シュートライン上のディフェンダーの数、ゴールキーパーの守備範囲など、さまざまな特徴を把握することができます。ROC 曲線の下の領域 (AUC) をトレーニングジョブの客観的メトリクスとして使用し、Amazon SageMaker XGBoost アルゴリズムを使用して、2017 年以降ブンデスリーガのゴールで放たれた 40,000 本以上のシュートで xGoals モデルをトレーニングしました。Amazon SageMaker Python SDK および XGBoost ハイパーパラメータの最適化を使用した xGoals トレーニングプロセスの詳細については、The tech behind the Bundesliga Match Facts xGoals: How machine learning is driving data-driven insights in soccer を参照してください。
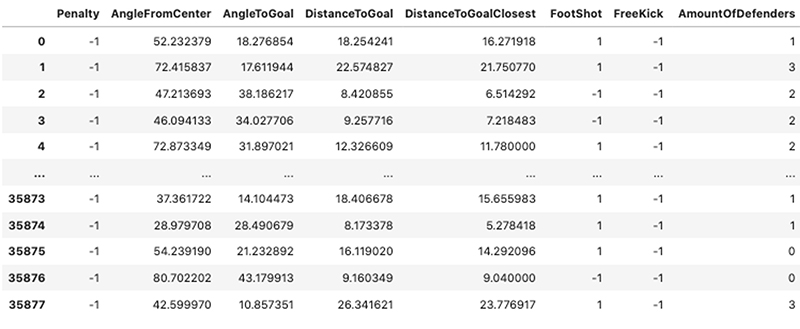
元のトレーニングデータセットのいくつかの行を見ると、処理している特徴の種類、つまり、ゴールへ試みられたシュートの大規模なデータセット全体にわたるバイナリ値、カテゴリ値、連続値の組み合わせを理解することができます。次のスクリーンショットは、モデルトレーニングと説明可能性の処理の両方に使用される 17 個の特徴のうちの 8 つを示しています。
SageMaker Clarify
SageMaker は、初心者のデータサイエンティストから熟練した機械学習の研究者までが、データセットの準備、カスタムモデルの構築とトレーニングを行い、その後、ヘルスケア、メディア、エンターテインメント、金融などの幅広い業界に展開できるように支援してきました。
しかし、ほとんどの機械学習ツールと同様に、より深く掘り下げてそのモデルの結果を説明したり、潜在的なバイアスについてトレーニングデータセットを調査する方法が欠けていました。これはすべて Clarify の発表で変わりました。Clarify は、バイアスを検出し、再現可能かつスケーラブルな方法で、モデルの説明可能性を実装する機能を提供します。
説明可能性の欠如は、多くの場合、組織が機械学習を導入する障壁となります。このモデルの説明可能性の欠如を克服するための理論的アプローチは、近年明らかに成熟しており、傑出したフレームワークである SHAP (SHapley Additive Explainations) が説明可能な AI の分野で重要なツールになっています。この方法の詳細な説明についてはこの記事では割愛しますが、SHAP は、「モデルから特定の特徴を削除すると、予測はどのように変化するか」という質問を提起して、モデルの説明を構築します。 SHAP 値は、この問いに対する答えであり、ある特徴が予測に与える影響の大きさと方向性を直接計算するものです。連立ゲーム理論に基づいて、SHAP 値は、データインスタンスの特徴量を連立の選手として特徴付けることを目的としており、その後、さまざまな特徴量の間で配当 (予測) を公平に分配する方法を示します。SHAP フレームワークの優れた特徴は、モデルにとらわれず、単純な線形モデルから、数百層からなる深くて複雑なニューラルネットワークまで対応できる、高いスケーラビリティです。
Clarify で Bundesliga xGoals モデルの動作を説明する
データセットと ML の説明可能性が導入されたので、目的の SHAP 値を計算する Clarify プロセッサの初期化を開始できます。このプロセッサのすべての引数は汎用的で、現在の本番環境と自由に使える AWS リソースにのみ関連しています。
まず、次のコードを使用して、SageMaker セッション、AWS Identity and Access Management (IAM) 実行ロール、 Amazon Simple Storage Service (Amazon S3) バケットとともに、Clarify 処理ジョブを定義しましょう。
CSV トレーニングファイルを Amazon S3 に保存し、Clarify ジョブのトレーニングデータと結果のパスを次のように指定します。
Clarify プロセッサをインスタンス化し、説明可能性のトレーニングデータセットを定義したので、問題に特化した実験構成を指定し始めることができます。
次は、前述の関連コードスニペットに示したように、注意すべき重要な入力パラメータです。
- ベースライン – これらのベースラインは、モデルの説明を計算するために重要です。各特徴にはベースライン値があります。実験では、連続的な数値特徴には平均を使用し、カテゴリ別の特徴にはモードを使用します。詳細については、説明可能性のための SHAP ベースラインを参照してください。
- NBR_SAMPLES – SHAP アルゴリズムで使用されるサンプルの数。
- AGG_METHOD – グローバルな SHAP 値の算出するための集計方法。この例では、すべてのインスタンスの SHAP 絶対値の平均です。
- TARGET_NAME – 基盤となる XGBoost モデルが予測しようとしているターゲットの特徴の名前。
- MODEL_NAME – (以前の) トレーニングを受けた SageMaker XGBoost モデルのエンドポイント名。
重要なパラメータを clarify.ModelConfig、clarify.SHAPConfig、および clarify.DataConfig インスタンスに直接渡します。次のコードを実行すると、処理ジョブの動作が設定されます。
グローバル説明
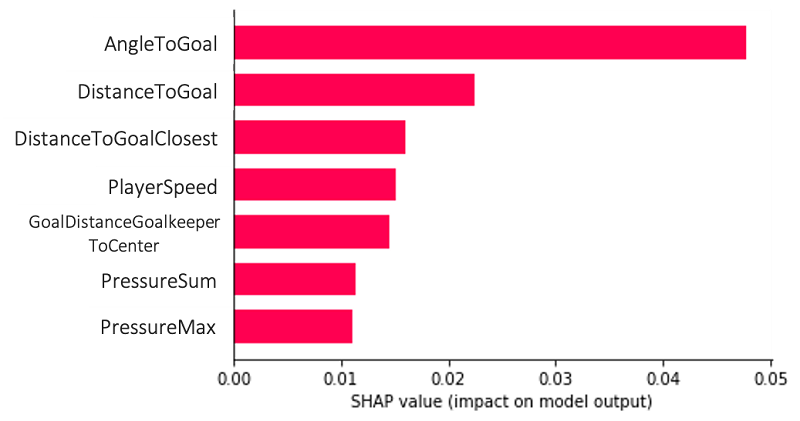
xGoals トレーニングセット全体を対象に Clarify の説明可能性解析を実行すると、各特徴のグローバルな SHAP 値とその分布をすばやく簡単に表示できます。これにより、ある特徴の値が正または負に変化した場合、最終的な予測にどのような影響を与えるかをマッピングできます。オープンソースの SHAP ライブラリを使用して、処理ジョブ内で計算される SHAP 値をプロットします。
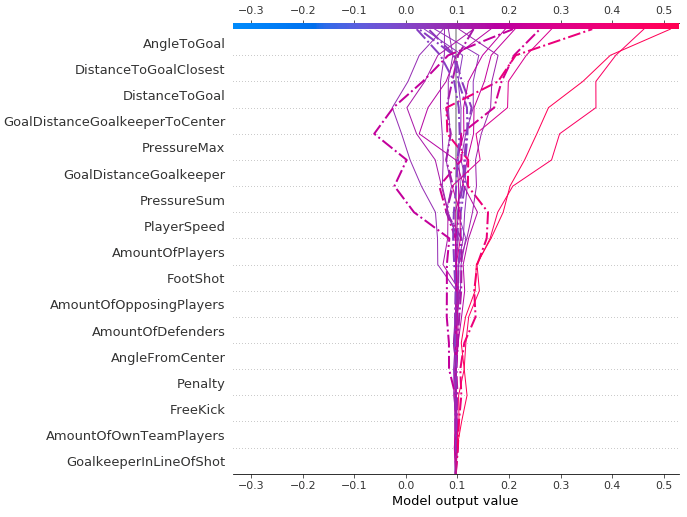
次のプロットは、グローバル説明の例で、複数のデータポイントにわたってモデルとその特徴の組み合わせを集約して理解することができます。AngleToGoal、DistanceToGoal、および DistanceToGoalClosest の特徴は、目標変数、つまりゴールが得点されているかどうかを予測する上で最も重要な役割を果たします。
このタイプのプロットはさらに進んで、棒グラフよりも多くのコンテキストを提供し、各特徴の SHAP 値の分布 (ある特徴の値の変化が最終的な予測にどのように影響するかをマッピングできる) に関するより高度なインサイトや、予測子とターゲット変数の正負の関係を示すことができます。次のプロットの各データポイントは、ゴールへの各シュートを表します。
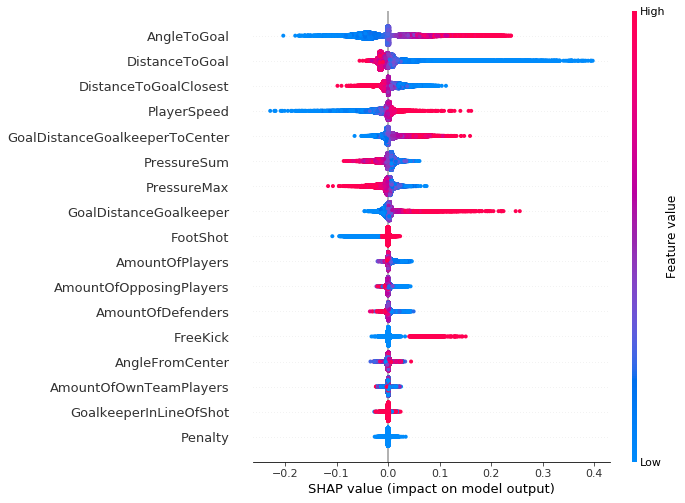
プロットの右側の縦軸に示されているように、赤いデータポイントは特徴の値が高いことを示し、青のデータポイントは低い値を示します。ゴール予測値に対する正負の影響は、SHAP 値から算出される X 軸に表示されます。このことから、例えば、ゴールに対する角度が大きくなると、予測の対数確率が高くなることが論理的に推測できます (これは、ゴールが決まるかどうかの True の予測と関連しています)。
注目すべき点として、結果の垂直分散が増加している領域では、重なり合っているデータポイントの濃度が単純に高くなるため、特徴ごとの Shapley 値の分布がわかります。
特徴は、重要度の順に上から下に並べられます。このプロットを 3 つのシーズン (2017~2018、2018~2019、2019~2020) で比較すると、特徴の重要度とそれに関連する SHAP 値の分布の両方にほとんどまたはまったく変化がないことがわかります。ブンデスリーガのリーグに参加する個々のクラブで同じことが言え、標準から逸脱しているクラブはほんの一握りしかありません。
調査した試合イベントにはペナルティ (すべて特徴値 =1) はありませんでしたが、元の XGBoost モデルトレーニングにも含まれていたため、Clarify 処理ジョブに含める必要があります。モデルトレーニングと Clarify 処理では、2 つの特徴セット間で一貫性を持たせる必要があります。
xGoals 特徴依存性
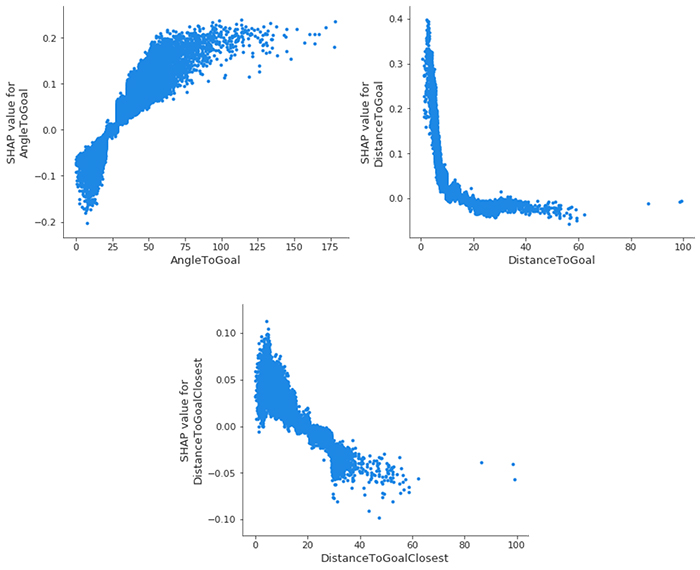
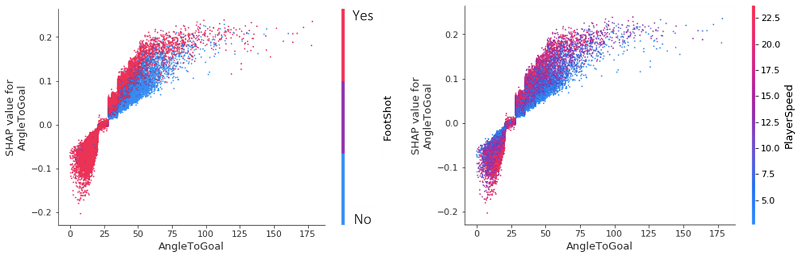
さらに深く掘り下げて、SHAP の特徴依存性プロットについて見ていきましょう。おそらく最も単純なグローバル解釈です。特徴を選択し、特徴値を X 軸に、対応する SHAP 値を Y 軸にプロットします。次のプロットは、最も重要な特徴との関係を示しています。
- AngleToGoal – 角度が小さい (< 25) とゴールの可能性が低くなりますが、角度が大きくなるとゴールの可能性は高くなります。
- DistanceToGoal – ゴールセンターから遠ざかるにつれてゴールが決まる可能性は、急降下 (対数的に減少する関数を模倣) します。一定の距離を超えると、SHAP 値には影響しません。他の条件が同じであれば、20 メートルからのシュートで入る可能性は、40 メートルからのシュートと同じ程度です。この観察は、おそらく、その範囲内の選手は、ゴールチャンスが高まる特別な理由 (キーパーがラインから外れているか、近くに選手を遮りシュートをブロックするディフェンダーがいない) がある場合にのみシュートを打つという事実によって説明できます。
- DistanceToGoalClosest – 当然ながら、
DistanceToGoalには大きな相関関係がありますが、DistanceToGoalClosest にははるかに線形な関係になっています。SHAP 値は、ゴールの最近接点までの距離が長くなるにつれて単調に減少します。
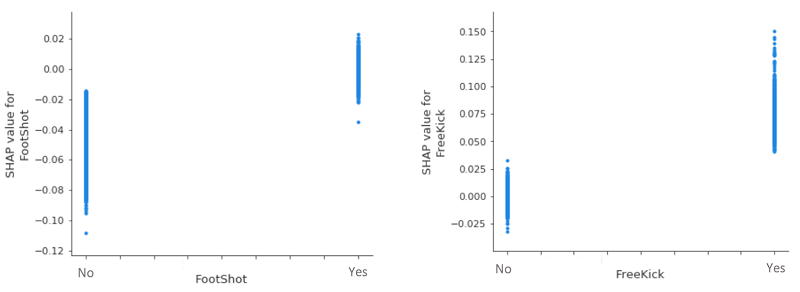
2つの (影響力の低い) カテゴリ変数を詳しく見てみると、他のすべての条件が同じであれば、ヘディングは常にゴールの可能性を下げ、フリーキックは可能性を上げます。FootShot=Yes および FreeKick=No の 0 SHAP 値付近の垂直方向の分散を考えると、ゴール予測への影響について結論づけることは何もありません。
xGoals 特徴の相互作用
個々の特徴の影響を考慮した後に、異なる特徴間の相互作用 (追加の影響) を強調表示することで、依存性プロットを改善することができます。ゲーム理論の Shapley 相互作用インデックスを使用して、すべての特徴の SHAP 相互作用値を計算し、次元 F X F のインスタンスごとに 1 つの行列を取得します。ここで、F は特徴の数です。この相互作用指数を使用して、最も強い相互作用を持つ SHAP 特徴依存性プロットを色付けできます。
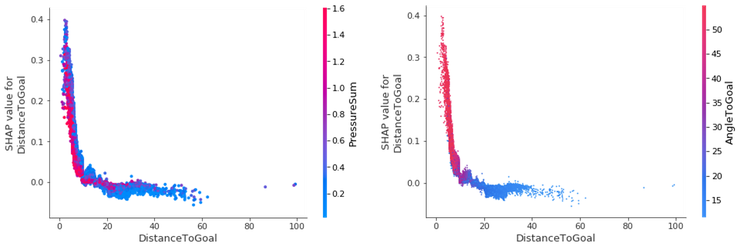
たとえば、変数 DistanceToGoal と PressureSum の相互作用と、それらが DistanceToGoal の SHAP 値に与える影響を知りたいとします。PressureSum は、シューターに対する相手選手からの個々のプレッシャーをすべて単純に合計することによって計算されます。DistanceToGoal とターゲット変数の間には負の関係があり、ゴールに近づくにつれてゴールの可能性が高くなります。当然ながら、ゴール予測が高い試合イベントでは、DistanceToGoal と PressureSum の間に強い逆相関が存在します。前者が減少すると、後者は上昇します。
ゴール近くで得点されたほとんどすべてのゴールは、45 度を超える角度で決められています。ゴールから遠ざかると、角度は小さくなります。これは理にかなっています。40 メートル離れた位置のサイドラインからゴールを決める頻度がどれほどあるでしょうか。
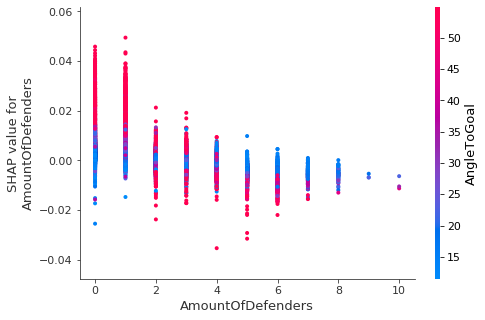
前述の結果に基づいて、ゴールに対する角度が高いとゴールを決める可能性が高くなることに留意しつつ、ディフェンダーの数の SHAP 値を見ると、これはアタッカーの近くに 1 人か 2 人のディフェンダーしかいない場合にのみ当てはまると判断できます。
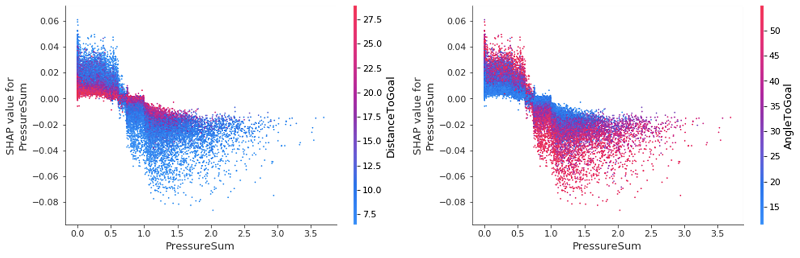
最初のグローバルサマリープロットをよく見直すと、PressureSum および PressureMax の特徴について、いくらかの不確実性 (ゼロの SHAP 値マークの周囲にある高密度な点の集合によって表される) があることがわかります。相互作用プロットを使用してこれらの値を深く掘り下げ、この原因を解明して特定することができます。
調査してみると、2 つの最も重要な特徴であっても、PressureSum の SHAP 値を変えるような影響がほとんどないことがわかります。ここで重要なポイントは、選手にプレッシャーがほとんど、またはまったくない場合、DistanceToGoal を低くするとゴールの可能性が高まりますが、ゴールに近くプレッシャーが多い場合には逆になり、選手は得点する可能性が低くなります。これらの影響は AngleToGoal では再び逆転します。プレッシャーが高まっても、AngleToGoal が大きくなると PressureSum の SHAP 値は減少します。特徴の相互作用プロットにより試合の予想を確認したり、プレー中のさまざまなパワーを定量化したりできるのは、心強いことです。
当然ながら、25 度未満の角度で得点したヘディングはほとんどありませんでした。たいへん興味深いことに、ヘディングと FootShot がゴールの可能性に与える影響を比較すると、25~75 度の範囲のどの角度でも、ヘディングがゴールの可能性を下げることがわかります。これを簡単に説明すると、お気に入りの選手がボールを足元に持ってゴールに対して広角に構えている場合、ボールが空中を舞い上がっている場合よりも得点する可能性が高くなるということです。
逆に、25 度を超える角度で、ゴールに向かってゆっくり移動している選手は、より速く移動している選手と比較して、ゴールの可能性が下がります。両方のプロットからわかるように、AngleToGoal < 25 と AngleTOGoal > 25 がゴール予測に与える影響の間には顕著な差があります。データに普遍的な傾向があることがすぐに特定できたため、SHAP 値を使用して 1 シーズン分のデータを分析する価値が見えてきました。
ローカル説明
これまでの分析では、データセット全体の説明可能性の結果 (グローバル説明) のみに焦点を当ててきました。ここでは特に興味深い試合とそのゴールイベントを調べ、ローカル説明と呼ばれるものを見ていきます。
2019~2020 シーズンで最も興味深い試合の 1 つである、2020 年 2 月 8 日に Bayer 04 Leverkusen が 4–3 で Borussia Dortmund を破ったスリリングな試合を振り返ると、各特徴が xGoals 値 (横軸に表示されるモデル出力値) に与えるさまざまな影響を見ることができます。下から始めて上に向かって、特徴が最終的な予測にだんだん影響を強める様子を見ていきますが、いくつかの極端なケースでは、AngleToGoal、DistanceToGoalClosest、およびDistanceToGoal が XGBoost モデルの確率予測に実際に最終的な影響を与えていることがわかります。破線は、ゴールが発生した試合イベントです。
モデルが比較的容易に予測した Leon Bailey が決めた試合の 6 点目のゴールを見ると、次のフォースプロットで比較的高い xGoals 値 0.36 に反映されているように、(主要な) 特徴量の多くが平均値を上回り、ゴールの可能性を高める方向に寄与していることがわかります。
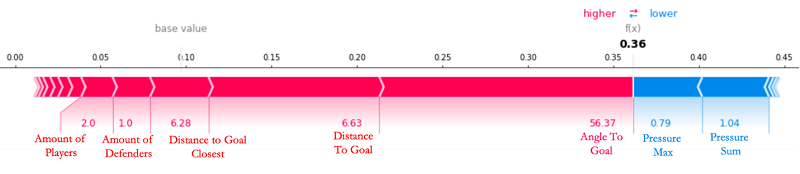
過去 3 シーズンのブンデスリーガで試みられたすべてのシュートの平均 XGoals 値は 0.0871 であり、これが基準値です。 XGBoost モデルは、このベースラインから予測を開始し、予測を増減させる正負の力が働きます。プロットでは、特徴の SHAP 値が、予測値を大きくする (正の値) または小さくする (負の値) 働きをする矢印として機能します。前のケースでは、どの特徴も、このゴールへのシュートで高い AngleToGoal (56.37)、低いAmountOfDefenders (1.0)、および低い DistanceToGoal (6.63) を打ち消すことができません。すべての定性的な記述 (小、低、大など) は、それぞれの特徴に関するデータセットの平均値に関連しています。
一方で、XGBoost モデルでは予測できず、SHAP 値では説明できないゴールもあります。ブンデスリーガの視聴者の 22% が2019~2020シーズンのベストゴールに選んだ Emre Can の驚きのシュートは、ゴールの確率はほぼゼロ (3%) とされました。ゴールからの遠い距離 (約 30 メートル) とかなりフラットな角度 (11.55 度) を考えると、それも頷けます。彼の得点の可能性を高めた唯一の特徴は、その時、ほとんどプレッシャーを与えるものがなく、彼を遮ることができるのは近くにいた 2 人の選手だけだったということでした。しかし、それだけでは明らかに Can を止めることはできませんでした。サッカーではいつもそうであるように、シュートのあらゆる側面が完璧であるために、人間はもちろんのこと、高度な機械学習モデルであっても結果を予測できないことがあります。

では、ゴール時の選手の位置追跡データを使用して、2D アニメーションで Can がゴールするプレーを見てみましょう。
結論:Bundesliga Match Facts にもたらす意味合い
今後の AWS による Bundesliga Match Facts にとっての主な意味は 2 つあります。この記事の実験結果は、次のことを示しています。
- 大規模なゴール予測データの探索と分析のプロセスを、新しい方法で自動化することに成功した
- 興味深く重要なシュートパターンをさらに取得するために改良可能な、モデルの説明可能性とバイアスのプラットフォームを提供した
サッカーの試合のように複雑な現実世界のシナリオでは、従来のまたはロジックに特化したルールベースのシステムでは、適用した時点で破綻し始め、あらゆる種類の試合イベントの予測はおろか、予測が行われた方法の詳細な説明も提供できません。Clarify を適用すると、ゴール予測モデルを強化し、サッカーの試合イベントをプレーごとにコンテキスト化することができます。
近年、サッカーのデータを取得する技術が飛躍的に進歩しているため、この増大するデータの山をモデル化するために使用できるモデルも進歩しています。Bundesliga Match Facts のデータセットの複雑さ、深さ、豊かさが増加し続ける中、チームはマッチファクトを追加するための新しいアイデアと、インサイトに満ちた説明可能性の結果に基づいて、実稼働モデルをどのように微調整するかを常に模索しています。これは、Clarify の必然的かつ継続的な更新や改善と並行して、xGoals と Bundesliga Match Facts の両方に今後のエキサイティングな道を開くものです。
「Amazon SageMaker Clarify は、最先端の説明可能な AI アルゴリズムのパワーをほんの数分でデベロッパーにもたらし、Bundesliga Match Facts のデジタルプラットフォームの残りの部分とシームレスに統合します。これは、Amazon SageMaker で機械学習ワークフローを標準化する長期戦略の重要な部分です」と、AWS による Bundesliga Match Facts の主要パートナー組織である Sportec Solutions (STS) のデータサイエンティストである Gabriel Anzer は報告しています。
このソリューションにより、ファンタジーフットボールの選手が地元リーグで優位に立つことができたり、マネージャーが選手の現在 (および将来の予測) のパフォーマンスについて客観的に評価できるようになったり、あるいは著名なサッカー専門家が特定の選手やチームについての攻撃および守備の傾向を見極めるための会話のきっかけになったりするなど、Bundesliga Match Facts に Clarify を適用することで、サッカーのエコシステムのあらゆる分野で具体的な価値が生み出されることがおわかりいただけたかと思います。
執筆者について
 Nick McCarthy は AWS Professional Services チームのデータサイエンティストです。同氏は、ヘルスケア、金融、スポーツ、メディアなど、さまざまな業界の AWS のお客様と協力し、AI や機械学習の活用によりビジネスの成果を加速させてきました。仕事以外では、旅行に出かけたり、新しい料理に挑戦したり、科学技術に関する本を読んだりするのが好きです。Nick のバックグラウンドは天体物理学と機械学習です。ブンデスリーガを時々観戦していますが、Manchester United については幼い頃かららのファンです。
Nick McCarthy は AWS Professional Services チームのデータサイエンティストです。同氏は、ヘルスケア、金融、スポーツ、メディアなど、さまざまな業界の AWS のお客様と協力し、AI や機械学習の活用によりビジネスの成果を加速させてきました。仕事以外では、旅行に出かけたり、新しい料理に挑戦したり、科学技術に関する本を読んだりするのが好きです。Nick のバックグラウンドは天体物理学と機械学習です。ブンデスリーガを時々観戦していますが、Manchester United については幼い頃かららのファンです。
 Luuk Figdor は、AWS Professional Services チームのデータサイエンティストです。彼はさまざまな業界のお客様と協力して、機械学習を使ってデータから知見を得るための支援を行っています。余暇には、心理学、経済学、AI の学際的分野を学ぶのが好きです。
Luuk Figdor は、AWS Professional Services チームのデータサイエンティストです。彼はさまざまな業界のお客様と協力して、機械学習を使ってデータから知見を得るための支援を行っています。余暇には、心理学、経済学、AI の学際的分野を学ぶのが好きです。
 Gabriel Anzer は、DFL の子会社である Sportec Solutions AG の主任データサイエンティストです。AI や機械学習を使用して、ファンとクラブ両方のためにサッカーのデータから興味深いインサイトを抽出する作業に取り組んでいます。Gabriel のバックグラウンドは数学と機械学習ですが、さらにテュービンゲン大学においてスポーツアナリティクスの博士号の取得、サッカーのコーチングライセンスの取得にも取り組んでいます。
Gabriel Anzer は、DFL の子会社である Sportec Solutions AG の主任データサイエンティストです。AI や機械学習を使用して、ファンとクラブ両方のためにサッカーのデータから興味深いインサイトを抽出する作業に取り組んでいます。Gabriel のバックグラウンドは数学と機械学習ですが、さらにテュービンゲン大学においてスポーツアナリティクスの博士号の取得、サッカーのコーチングライセンスの取得にも取り組んでいます。