Amazon Web Services ブログ
Human Longevity, Inc. – ゲノム研究で医療を変える ゲノム研究の先端をリードする
Human Longevity, Inc. (HLI) は予防衛生を支持する上で、ヒトゲノムおよび関連性を持つ表現型データや臨床データを蓄える世界最大のデータベースを構築したいと考えています。今回のゲスト投稿では、Yaron Turpaz 氏と Bryan Coon 氏、Ashley Van Zeeland 氏が医学に大きな変化をもたらす努力の一端として生成している大量のデータを保存するため、どのように AWS を使用しているのか語ります。
— Jeff;
2013 年に Human Longevity, Inc. を設立した当時から、前途に待ち受ける挑戦を認識していました。ゲノムには生命体を形成し維持する上で必要なすべての情報が詰まっています。ヒトにおいては、30 億もの DNA ベースのペアを含むゲノム全体のコピーが核を持つ全細胞に含まれています。我々の目的は 100 万のゲノムを配列し、その情報と関連付けた健康記録や疾病リスクを研究者や医師に提供することです。研究者や医師はデータを解釈して的を絞った個人の健康管理プランや、癌やその他の深刻な健康リスクにおいて最適な治療を従来より遥かにすばやく提供することができます。従来のように症状が出始めてから医師にかかり、病気を診断されてから治療を始めるモデルではなく、予防衛生やリスク予防を発展させることで医療を変えることが我々の目的です。大規模なコンピューティングを開発し適用、ゲノム研究に機械学習を使用するには Illumina のような企業が提供する DNA 配列技術による大量なデータの収集、分析、保存が必要になります。1 つのゲノムからの生データは約 100 ギガバイトを消耗します。注釈や表現型のソースや分析を含むゲノム情報を調整し、健康上の情報を分析するに伴ってこの数字は上昇します。我々が選ぶコンピューティングとストレージ技術が当社の成功に直接影響することは初めから理解していました。ですから、クラウドを使用することは明らかに最適な選択でした。当社はゲノミクスを専門としているので、IT インフラストラクチャの構築や維持にリソースを使用することは希望していません。そこで、プラットフォームの広さや当社が必要とする優れたスケーラビリティ、そしてビッグデータで展開した専門知識を備えている AWS を選ぶことにしました。また、AWS によるイノベーションのペースも考慮しました。利用者のために可能な限りコストを抑える AWS の手の込んだ策略も、当社のビジョンを実現する上で非常に大切なポイントだと考えました。
広範囲にわたる AWS サービスの活用
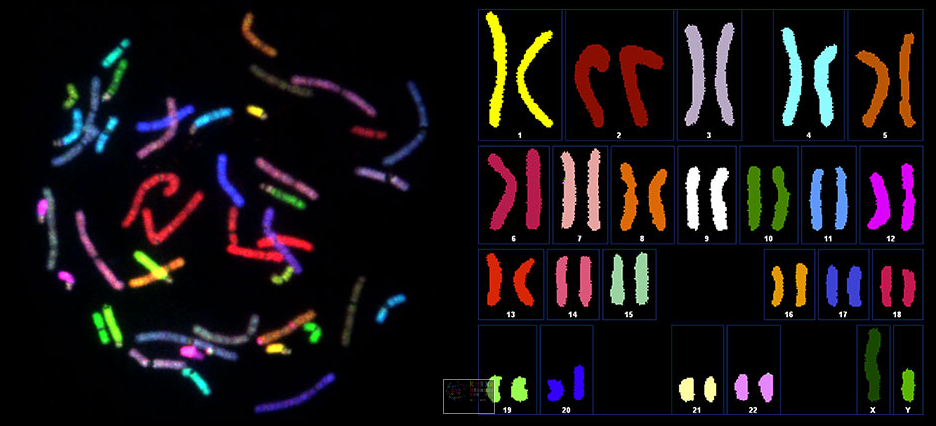
スペクトルの核型分析 / 画像提供: Human Longevity, Inc.
現在、当社では広範な AWS サービスを使用して様々な種類のコンピューティングタスクやストレージタスクを行っています。たとえば HLI のナレッジベースは Amazon S3 ストレージと多数の Amazon EC2 ノードで構成される分散システムインフラストラクチャを活用しています。これにより、当社がリソースの分離やスケーラビリティ、迅速なプロビジョニング、ペタバイトスケールのデータベースクエリや動的なコホートビルダーに対し、ほぼリアルタイムの応答時間を可能にすることができました。AWS サービスの柔軟性により、当社のカスタマイズした Amazon Machine Image や事前構築の BTRFS 分割した Amazon EBS ボリュームで起動時間を数分ではなく数秒にすることもできました。当社が必要とする規模でデータレイクに対し Spark クエリを実行する場合には Amazon EMR を使用しています。AWS 関数は Amazon S3 イベントに接続したり、アプリと連携したり、すでに対応済みのビジネスロジックを含むコードをドロップするのに優れたツールです。当社はデマンドベースの Auto Scaling を使用し、Docker パイプラインの管理には AWS OpsWorks を使用しています。We also leverage the cost controls provided by Amazon EC2 スポットやリザーブドインスタンスタイプが提供するコスト管理も使用しています。当初はオンデマンドインスタンスを使用していましたが、コスト面で負担が急増しました。スポットインスタンスやリザーブドインスタンスでは、特定のニーズやワークフローに基づいてコンピューティングリソースを割り当てることができます。AWS サービスの柔軟性により、Apache Mesos が提供するリソース管理サービスを介して Docker サイズのコンテナをフル活用することも可能です。永続的およびスポット抽象化レイヤーにある何百もの Amazon EC2 の動的ノードは、使用量の需要や AWS 料金の最新情報に合わせてスケールアップしたりスケールダウンするよう、動的に調整されています。この動的にスケールされるコンピューティングクラスターと当社のナレッジベースサービスや社内のゲノミクスおよび腫瘍のコンピューティングパイプラインを共有することで多大な節約を実現しています。この柔軟性のおかげで、当社が必要とする処理能力を利用しながらコストを抑えることが可能になっています。こうした選択により、オンデマンドモデルを使用していた時に比べコンピューティングに掛かる費用を 50% 削減することができました。また、当社は AWS プロフェッショナルサービスを利用して特定のハードデータストレージにおけるチャレンジにも取り組みました。当社は Amazon S3 バケットに何百ものゲノミクスデータを保存しています。その多くはペタバイトレベルで何十億ものオブジェクトを含んでいます。中には未使用または 1 度か 2 度使用し再使用することのない何十億ものオブジェクトがあります。何十億というオブジェクトの中から 1 つを見つけることは大変なタスクです。Amazon S3 の頻繁にアクセスしないストレージクラスに当てはまるファイルやファイル形式がどれか識別する場合にさらなる負荷が掛かってしまいます。そうした状況でプロフェッショナルサービスは Amazon S3 オブジェクトのインデックス作成をソリューションとして提供し、当社の時間とコスト節約を可能にしました。
スピードの上昇とコスト削減
遺伝子配列とクラウドコンピューティングという 2 つの重要なテクノロジーの変曲点において、当社はタイミング良く AWS を選ぶことができました。つい最近まで、1 つのゲノム配列には 1 年間と約 1 億ドルの費用が掛かっていました。今では 1 つのゲノム配列に 3 日と数百ドルのコストが掛かる程度です。スピードとコスト低下の劇的な改善、可視化と分析ツールの急速な進展により、ほぼリアルタイムで大量のデータを収集し分析することが可能になりました。従来は何か月、何年と掛かっていたプロセスも、今ではユーザーがデータに基づく疾患性の検証を数日あるいは数時間で行うことができるようになりました。最終的には、これが患者の利益になるのです。当社のビジネスには HLI Health Nucleus があります。これはホールゲノム配列分析、高度な臨床画像、機械学習、収集し要約した個人の医療情報を使用し、ゲノミクスを利用する臨床研究プログラムで個人の健康の全体像を表す情報を提供します。当社では、これにより医師が病を識別し治療や予防を劇的に向上させ、患者の長期生存とより健康的なライフスタイルを可能にできると考えています。– Yaron Turpaz (最高情報責任者)、Bryan Coon (エンタープライズサービス部長)、Ashley Van Zeeland (最高技術責任者)
詳細
AWS が クラウドでゲノミクスをサポートする方法やゲノミクスのイノベータ―である Illumina が AWS を使用して遺伝子配列のスピードを促進しコスト効率を高めている方法をご覧ください。