Amazon Web Services ブログ
Amazon OpenSearch Service のインフラストラクチャ障害におけるシャードへの影響
本投稿は AWS Big Data Blog に投稿された Impact of Infrastructure failures on shard in Amazon OpenSearch Service の日本語訳版です
Amazon OpenSearch Service は、大規模な OpenSearch およびレガシー Elasticsearch クラスターを AWS クラウドで簡単に保護、デプロイ、運用できるようにするマネージドサービスです。Amazon OpenSearch Service はクラスターのすべてのリソースをプロビジョニング、起動し、障害が発生したノードを自動的に検出して交換することで、自己管理型インフラストラクチャにおけるオーバーヘッドを削減します。本サービスでは、OpenSearch の最新バージョン、19 バージョンの Elasticsearch (1.5 ~ 7.10 バージョン) のサポート、OpenSearch Dashboards と Kibana (1.5 ~ 7.10 バージョン) による視覚化機能 (バージョン 1.5 ~ 7.10) を提供することで、インタラクティブなログ分析、リアルタイムのアプリケーションモニタリング、ウェブサイト検索などを簡単に行うことができます。
最新のサービスソフトウェアリリースでは、シャード割り当てロジックを負荷を意識したものに変更しました。この変更により、ノード障害によってシャードが再配置される際に、過去に障害が発生したノード上に配置されていたシャードによって、存続しているノードが過負荷に陥ることがなくなります。これは、マルチ AZ ドメインが、一貫して予測可能なクラスターパフォーマンスを提供する上で特に重要です。
シャード割り当てロジック全般について詳しく知りたい場合は、”Elasticsearch のシャード割り当てについて解説する” を参照してください。
チャレンジ
ノード数が設定したアベイラビリティーゾーン間で均等に分散され、いずれかのノードに 1 つのインデックスのシャードが集中することなく、シャードの総数が使用可能なすべてのノードに均等に分散されている Amazon OpenSearch Service ドメインは、「バランスが取れている」といえます。加えて、OpenSearch には “Zone Awareness” というプロパティがあり、これを有効にすると、プライマリシャードとそれに対応するレプリカが別のアベイラビリティーゾーンに割り当てられるようになります。データのコピーが複数あり、かつ複数のアベイラビリティーゾーンがある場合、耐障害性と可用性が向上します。ドメインがスケールアウトまたはスケールインされた場合、またはノードに障害が発生した場合、OpenSearchは “Zone Awareness” に基づく割り当てルールに従い、使用可能なノード間でシャードを自動的に再分散します。
シャードバランシングプロセスにより、シャードがアベイラビリティーゾーン全体に均等に分散されることが保証されますが、1 つのゾーンで予期しない障害が発生した場合、シャードは存続しているノードに再割り当てされます。その結果、残っているノードが過負荷になり、クラスターの安定性に影響する可能性があります。
たとえば、3 ノードクラスターの 1 つのノードがダウンした場合、OpenSearch は次の図に示すように、割り当てられていないシャードを再配布します。ここで、”P” はプライマリシャードコピーを表し、”R” はレプリカシャードコピーを表します。
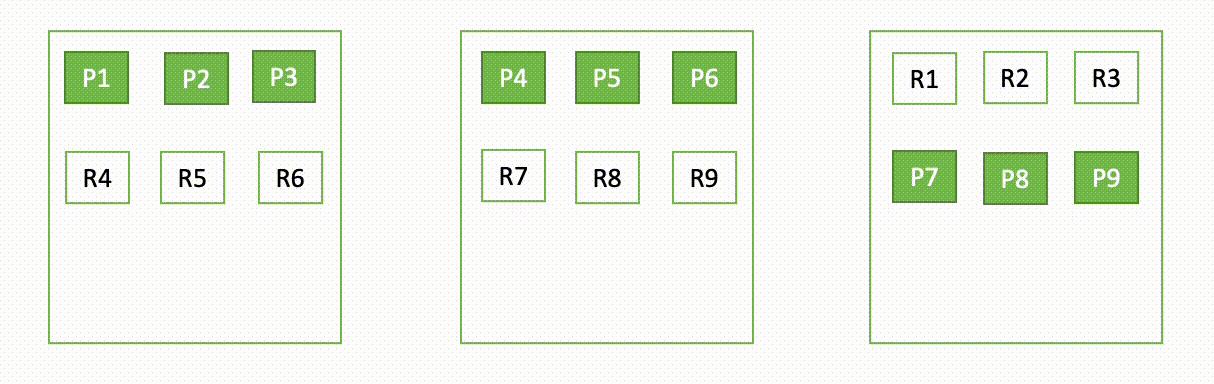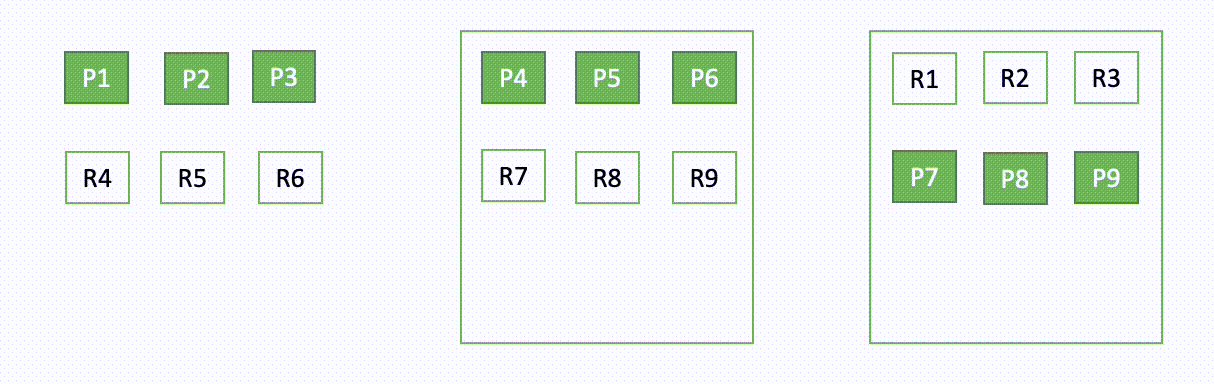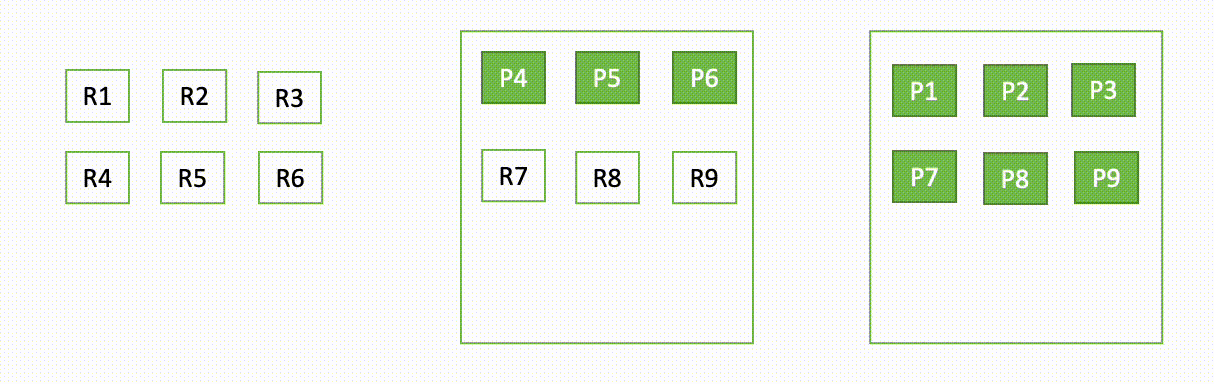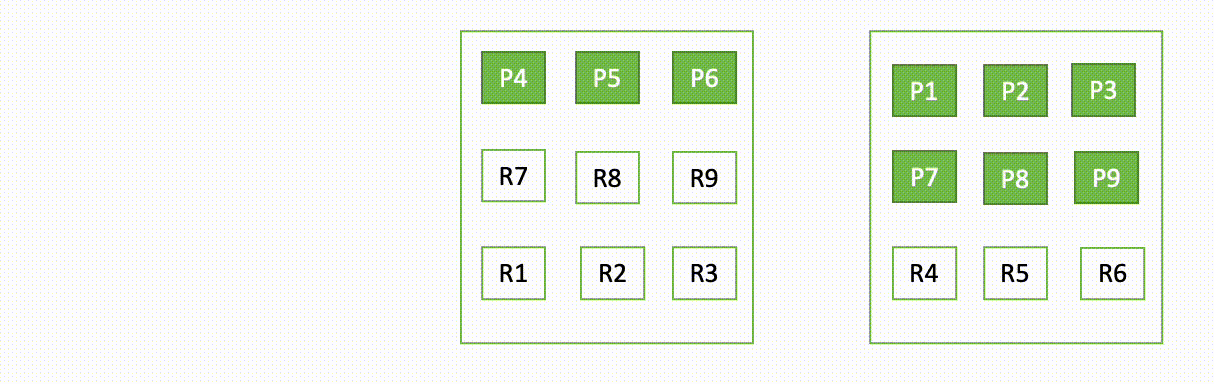
このドメインの動作は、障害発生時と復旧時の 2 つの部分で説明できます。
障害時の動作
複数のアベイラビリティーゾーンにデプロイされたドメインは、そのライフサイクル中に複数のタイプの障害に遭遇する可能性があります。
特定ゾーンの全体的な障害
クラスターは、さまざまな理由により 1 つのアベイラビリティーゾーンを失う可能性があります。また、そのゾーンのすべてのノードも失われる可能性があります。これまでは、サービスは失われたノードを残りの正常なアベイラビリティーゾーンに配置しようとしていました。また、サービスは割り当てルールに従いながら、失われたシャードを残りのノードで再作成しようとしていました。これは、意図しない結果を生む可能性がありました。
- 影響を受けたゾーンのシャードが正常なゾーンに再割り当てされると、シャードのリカバリがトリガーされ、追加の CPU サイクルとネットワーク帯域幅が消費されます。これにより、レイテンシーが増加する可能性があります。
- n-AZ、n コピーの設定 (n>1) では、残りの n-1 アベイラビリティーゾーンに n 番目のシャードコピーが割り当てられます。これは、シャード分散に非対称性を生み、ノード間のトラフィックを不均衡にする可能性があるため、望ましくありません。これらのノードが過負荷になり、さらなる障害に繋がる可能性があります。
特定ゾーンの部分的な障害
ゾーンの一部に障害が発生した場合、またはドメインがアベイラビリティーゾーンの一部のノードのみを失った場合、Amazon OpenSearch Service は障害が発生したノードをできるだけ早く交換しようとします。ただし、ノードの交換に時間がかかりすぎる場合、OpenSearch はそのゾーンの未割り当てのシャードをアベイラビリティーゾーン内の存続ノードに割り当てようとします。サービスが影響を受けたアベイラビリティーゾーンのノードを置き換えることができない場合、それらのノードは、設定された他のアベイラビリティーゾーンに割り当てられる可能性があります。これにより、ゾーン全体およびゾーン内の両方でシャード分散の非対称化がさらに進む可能性があります。これもまた意図しない結果をもたらします。
- ドメイン上のノードに追加のシャードを収容するために十分なストレージ容量がない場合、ドメインの書き込みがブロックされ、インデックス処理に影響が及ぶ可能性があります。
- シャードの分散が偏ることで、ドメインのトラフィックがノード間で偏る可能性もあります。これにより、読み取りおよび書き込み操作のレイテンシーやタイムアウトがさらに増加する可能性があります。
リカバリ時の動作
これまでは、Amazon OpenSearch Service は、ドメインの必要なノード数を維持するために、上記の障害セクションで説明したシナリオと同様に、残りの正常なアベイラビリティーゾーンでデータノードを起動していました。このようなインシデントが発生した後、すべてのアベイラビリティーゾーンにノードを適切に分散させるには、AWS による手動操作が必要でした。
今回の変更点
障害時の処理を全体的に改善し、障害によるドメインの健全性とパフォーマンスに与える影響を最小限に抑えるために、Amazon OpenSearch Service は次の変更を行っています。
Forced Zone Awareness
OpenSearch には、シャードを割り当てる必要があるアベイラビリティーゾーンを設定するために使用される、forced awareness と呼ばれる既存のシャードバランシング設定があります。たとえば、zoneという awareness 属性があり、zone1 と zone2 にノードを設定している場合、forced awareness 機能を使用して、使用可能なゾーンが1つしかない場合にOpenSearchがレプリカを割り当てないようにすることができます。
この構成例では、node.attr.zone を zone1 に設定して 2 つのノードを起動し、5 つのシャードと 1 つのレプリカでインデックスを作成すると、OpenSearch はインデックスを作成して 5 つのプライマリシャードを割り当てますが、レプリカは割り当てません。レプリカは、node.attr.zone が zone2 に設定されているノードが使用可能になったときにのみ割り当てられます。
Amazon OpenSearch Service は、マルチ AZ ドメインの forced awareness 設定を使用して、シャードが zone awareness のルールに従ってのみ割り当てられるようにします。これにより、正常なアベイラビリティーゾーンのノードの突発的な負荷の増加を防ぐことができます。
Load-Aware Shard Allocation (負荷に応じたシャード割り当て)
Amazon OpenSearch Service は、プロビジョニングされたキャパシティ、実際のキャパシティおよびシャードコピーの合計数などの要素を考慮し、ノードごとに予想される平均シャード数に基づいて、いずれかのノードがより多くのシャードによって過負荷状態であるかを計算します。いずれかのノードにこの制限を超えるシャード数が割り当てられている場合、シャードの割り当てができなくなります。
注意: クラスターにおける差し迫ったデータ損失を防ぐため、未割当のプライマリーシャードは、過負荷ノードに対しても引き続き割り当てが許可されます。
同様に、手動によるリカバリの問題 (上記の「リカバリ時の動作」セクションで説明) に対処するために、Amazon OpenSearch Service は内部のスケーリングコンポーネントにも変更を加えています。新しい変更により、Amazon OpenSearch Service は、前述の障害シナリオが発生した場合でも、残りのアベイラビリティーゾーンでノードを起動しなくなります。
これまでの動作と新しい動作を図で比較する
ある Amazon OpenSearch Service ドメインが 3 つの AZ、6 つのデータノード、12 のプライマリシャード、24 のレプリカシャードで構成されているとします。ドメインは AZ-1、AZ-2、AZ-3 にまたがってプロビジョニングされ、各ゾーンにはノードが 2 つずつあります。
現在のシャード割り当て:
シャードの総数:12 プライマリ + 24 レプリカ = 36 シャード
アベイラビリティーゾーンの数:3
ゾーンごとのシャード数 (zone awareness = true): 36/3 = 12
アベイラビリティーゾーンごとのノード数:2
ノードあたりのシャード数:12/2 = 6
次の図は、ドメイン設定を視覚的に表現したものです。〇の中の数字はノードに割り当てられたシャードの数を示します。Amazon OpenSearch Service はノードごとに 6 つのシャードを割り当てます。

これまで、AZ-3 の 1 つのノードに障害が発生するような部分的なゾーン障害時では、障害が発生したノードは残りのゾーンに割り当てられ、ゾーン内のシャードは利用可能なノードに基づいて再分配される動作となっていました。今回の変更により、クラスタはノードの障害後に新しいノードを作成したり、シャードを再分配することはなくなりました。
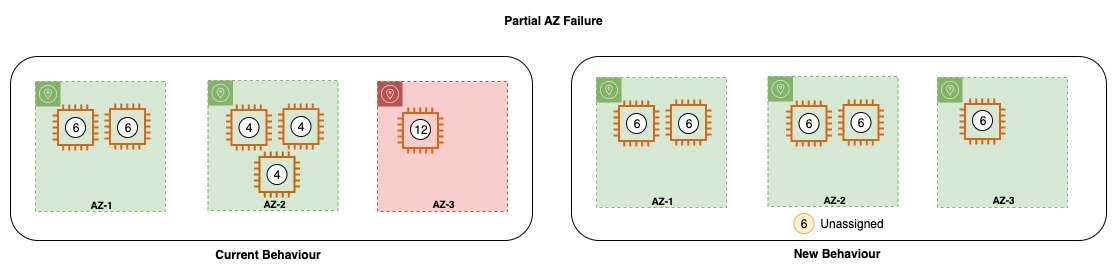
上の図にもあるように、これまでは AZ-3 で 1 つのノードが失われると、Amazon OpenSearch Service は同じゾーンで代替のキャパシティを立ち上げようとしていました。しかし、何らかの障害により、そのゾーンに問題が発生し、代替のキャパシティを起動することができないかもしれません。このような場合、サービスは不足分のキャパシティを別の健全なゾーンで起動しようとします。これにより、アベイラビリティーゾーン間でゾーンのバランスが崩れる可能性がありました。また、影響を受けたゾーンのシャードは、同じゾーンの生存ノードに詰め込まれていました。しかし、新しい動作では、サービスは同じゾーンでキャパシティを起動しようとする一方で、アンバランスを避けるために他のゾーンで不足キャパシティを起動することを避けます。シャードアロケーターは、存続しているノードが過負荷にならないようにする役割も果たします。
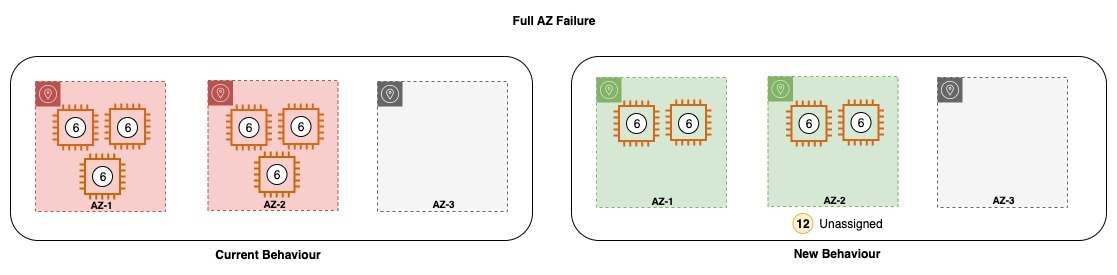
同様に、これまでは AZ-3 のすべてのノードが失われた場合や AZ-3 に障害が発生した場合、Amazon OpenSearch Service は残りのアベイラビリティーゾーンで失われたノードを起動し、ノード上のシャードを再分散します。一方、新しい変更後は、Amazon OpenSearch Service は残りのゾーンにノードを割り当てないか、失われたシャードを残りのゾーンに再割り当てしようとします。Amazon OpenSearch Service は、復旧が完了し、復旧後にドメインが元の設定に戻るのを待ちます。
アベイラビリティーゾーンの喪失に耐えるだけのキャパシティがドメインにプロビジョニングされていない場合、ドメインのスループットが低下する可能性があります。そのため、ドメインのサイズを決める際はベストプラクティスに従うことを強くお勧めします。つまり、1 つのアベイラビリティーゾーンに障害が発生しても十分なリソースをプロビジョニングしておく必要があります。

これまでは、ドメインが回復すると、アベイラビリティーゾーン間でキャパシティのバランスを取るためにサービスの手動操作が必要でいた。これにはシャードの移動も含まれます。一方、新しい動作では、影響を受けたゾーンにキャパシティが復帰すると、シャードは回復されたノードに自動的に割り当てられるため、復旧プロセスに介入する必要がなくなりました。これにより、残りのリソースに競合する優先順位がないことが保証されます。
期待できること
Amazon OpenSearch Service ドメインを最新のサービスソフトウェアリリースに更新すると、ベストプラクティスに沿って構成 されたドメインは、アベイラビリティーゾーン内の 1 つまたは複数のデータノードが失われた後でも、より予測可能なパフォーマンスを発揮します。ノードでシャードが過剰に割り当てられるケースが減ります。1 つのゾーンで障害が発生しても許容できる十分な容量を用意しておくとよいでしょう。
過負荷のノードにはレプリカシャードを割り当てないため、このような予期しない障害が発生したときにドメインのステータスが Yellow になることがあります。ただし、これは適切に構成されたドメインでデータが失われることを意味するものではありません。割り当ての停止中もすべてのプライマリーが割り当てられていることを確認してください。自動リカバリが実施され、ドメイン内のノードのバランスが取れ、障害が回復したらレプリカが割り当てられるようになります。
Amazon OpenSearch Service ドメインのサービスソフトウェアを更新して、これらの新しい変更がドメインに適用されるようにしてください。サービスソフトウェアの更新プロセスの詳細については、Amazon OpenSearch Service のドキュメント を参照してください。
結論
本投稿では、Amazon OpenSearch Service が最近、ゾーン障害時にノードおよびシャードをアベイラビリティーゾーンをまたがって分散するロジックをどのように改善したかを説明しました。 この変更は、ノードまたはゾーンの障害時に、サービスがより一貫した予測可能なパフォーマンスを保証するのに役立ちます。ドメインは、以前はノードへの過剰なシャード割り当てにより顕在化していた、書き込みや読み込み処理中のレイテンシの増大、および書き込みブロックを経験することはないでしょう。
翻訳はソリューションアーキテクトの榎本が担当いたしました