AWS Big Data Blog
Impact of infrastructure failures on shards in Amazon OpenSearch Service
Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch and legacy Elasticsearch clusters at scale in the AWS Cloud. Amazon OpenSearch Service provisions all the resources for your cluster, launches it, and automatically detects and replaces failed nodes, reducing the overhead of self-managed infrastructures. The service makes it easy for you to perform interactive log analytics, real-time application monitoring, website searches, and more by offering the latest versions of OpenSearch, support for 19 versions of Elasticsearch (1.5 to 7.10 versions), and visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5 to 7.10 versions).
In the latest service software release, we’ve updated the shard allocation logic to be load-aware so that when shards are redistributed in case of any node failures, the service disallows surviving nodes from getting overloaded by shards previously hosted on the failed node. This is especially important for Multi-AZ domains to provide consistent and predictable cluster performance.
If you would like more background on shard allocation logic in general, please see Demystifying Elasticsearch shard allocation.
The challenge
An Amazon OpenSearch Service domain is said to be “balanced” when the number of nodes are equally distributed across configured Availability Zones, and the total number of shards are distributed equally across all the available nodes without concentration of shards of any one index on any one node. Also, OpenSearch has a property called “Zone Awareness” that, when enabled, ensures that the primary shard and its corresponding replica are allocated in different Availability Zones. If you have more than one copy of data, having multiple Availability Zones provides better fault tolerance and availability. In the event, the domain is scaled out or scaled in or during the failure of node(s), OpenSearch automatically redistributes the shards between available nodes while obeying the allocation rules based on zone awareness.
While the shard-balancing process ensures that shards are evenly distributed across Availability Zones, in some cases, if there is an unexpected failure in a single zone, shards will get reallocated to the surviving nodes. This might result in the surviving nodes getting overwhelmed, impacting cluster stability.
For instance, if one node in a three-node cluster goes down, OpenSearch redistributes the unassigned shards, as shown in the following diagram. Here “P“ represents a primary shard copy, whereas “R“ represents a replica shard copy.
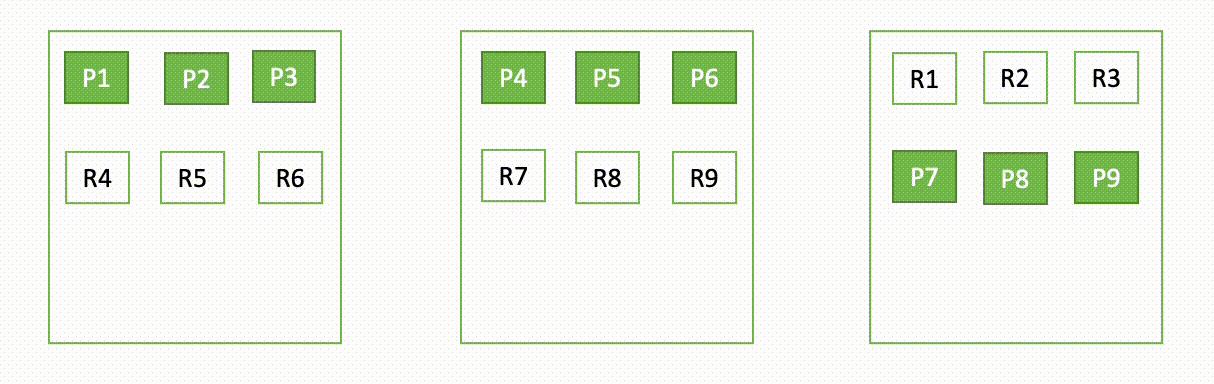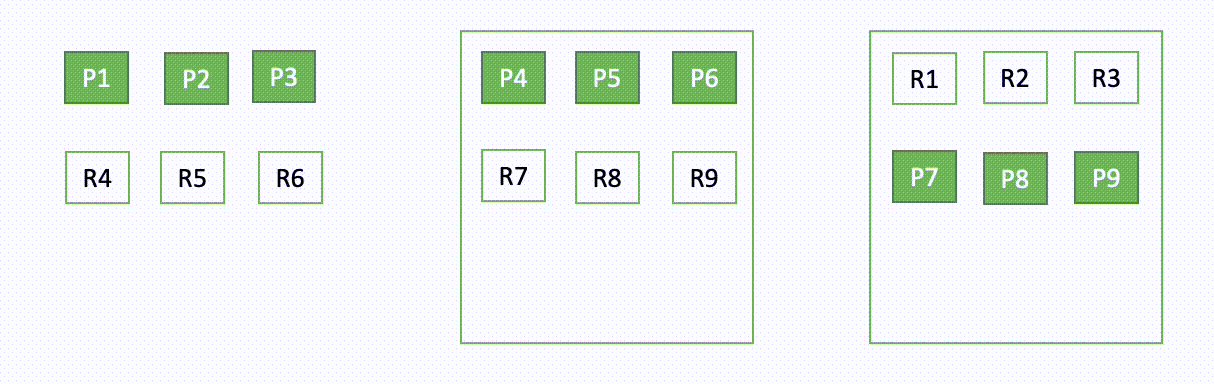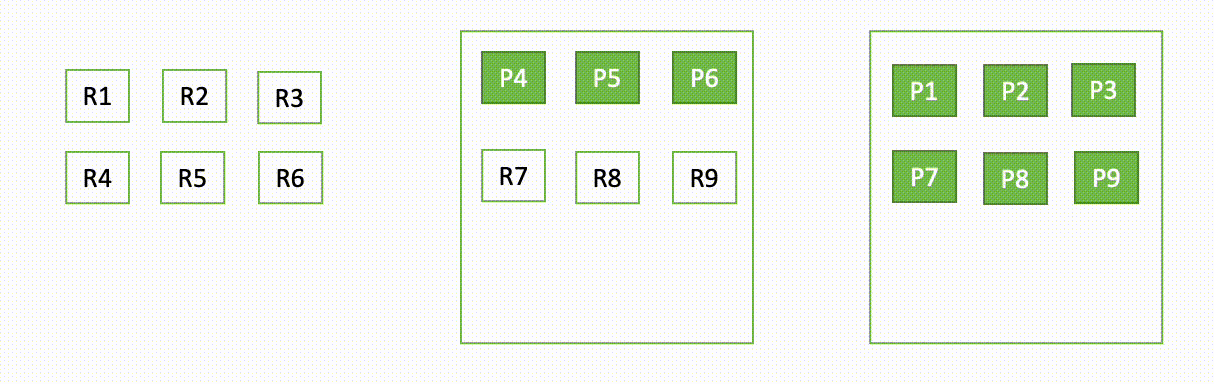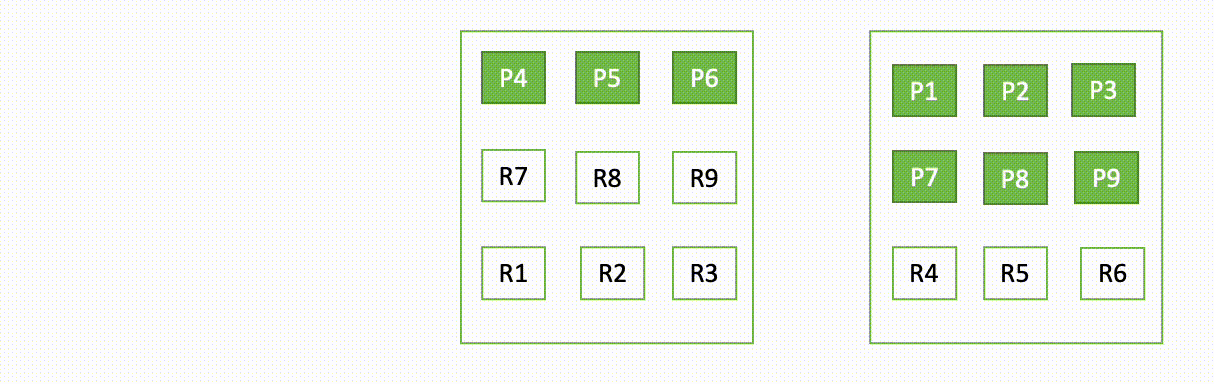
This behavior of the domain can be explained in two parts – during failure and during recovery.
During failure
A domain deployed across multiple Availability Zones can encounter multiple types of failures during its lifecycle.
Complete zone failure
A cluster may lose a single Availability Zone due to a variety of reasons and also all the nodes in that zone. Today, the service tries to place the lost nodes in the remaining healthy Availability Zones. The service also tries to re-create the lost shards in the remaining nodes while still following the allocation rules. This can result in some unintended consequences.
- When the shards of the impacted zone are getting reallocated to healthy zones, they trigger shard recoveries that can increase the latencies as it consumes additional CPU cycles and network bandwidth.
- For an n-AZ, n-copy setup, (n>1), the surviving n-1 Availability Zones are allocated with the nth shard copy, which can be undesirable as it can cause skewness in shard distribution, which can also result in unbalanced traffic across nodes. These nodes can get overloaded, leading to further failures.
Partial zone failure
In the event of a partial zone failure or when the domain loses only some of the nodes in an Availability Zone, Amazon OpenSearch Service tries to replace the failed nodes as quickly as possible. However, in case it takes too long to replace the nodes, OpenSearch tries to allocate the unassigned shards of that zone into the surviving nodes in the Availability Zone. If the service cannot replace the nodes in the impacted Availability Zone, it may allocate them in the other configured Availability Zone, which may further skew the distribution of shards both across and within the zone. This again has unintended consequences.
- If the nodes on the domain do not have enough storage space to accommodate the additional shards, the domain can be write-blocked, impacting indexing operation.
- Due to the skewed distribution of shards, the domain may also experience skewed traffic across the nodes, which can further increase the latencies or timeouts for read and write operations.
Recovery
Today, in order to maintain the desired node count of the domain, Amazon OpenSearch Service launches data nodes in the remaining healthy Availability Zones, similar to the scenarios described in the failure section above. In order to ensure proper node distribution across all the Availability Zones after such an incident, manual intervention was needed by AWS.
What’s changing
To improve the overall failure handling and minimizing the impact of failure on the domain health and performance, Amazon OpenSearch Service is performing the following changes:
- Forced Zone Awareness: OpenSearch has a preexisting shard balancing configuration called forced awareness that is used to set the Availability Zones to which shards need to be allocated. For example, if you have an awareness attribute called zone and configure nodes in
zone1andzone2, you can use forced awareness to prevent OpenSearch from allocating replicas if only one zone is available:
With this example configuration, if you start two nodes with node.attr.zone set to zone1 and create an index with five shards and one replica, OpenSearch creates the index and allocates the five primary shards but no replicas. Replicas are only allocated once nodes with node.attr.zone set to zone2 are available.
Amazon OpenSearch Service will use the forced awareness configuration on Multi-AZ domains to ensure that shards are only allocated according to the rules of zone awareness. This would prevent the sudden increase in load on the nodes of the healthy Availability Zones.
- Load-Aware Shard Allocation: Amazon OpenSearch Service will take into consideration factors like the provisioned capacity, actual capacity, and total shard copies to calculate if any node is overloaded with more shards based on expected average shards per node. It would prevent shard assignment when any node has allocated a shard count that goes beyond this limit.
Note that any unassigned primary copy would still be allowed on the overloaded node to prevent the cluster from any imminent data loss.
Similarly, to address the manual recovery issue (as described in the Recovery section above), Amazon OpenSearch Service is also making changes to its internal scaling component. With the newer changes in place, Amazon OpenSearch Service will not launch nodes in the remaining Availability Zones even when it goes through the previously described failure scenario.
Visualizing the current and new behavior
For example, an Amazon OpenSearch Service domain is configured with 3-AZ, 6 data nodes, 12 primary shards, and 24 replica shards. The domain is provisioned across AZ-1, AZ-2, and AZ-3, with two nodes in each of the zones.
Current shard allocation:
Total number of shards: 12 Primary + 24 Replica = 36 shards
Number of Availability Zones: 3
Number of shards per zone (zone awareness is true): 36/3 = 12
Number of nodes per Availability Zone: 2
Number of shards per node: 12/2 = 6
The following diagram provides a visual representation of the domain setup. The circles denote the count of shards allocated to the node. Amazon OpenSearch Service will allocate six shards per node.

During a partial zone failure, where one node in AZ-3 fails, the failed node is assigned to the remaining zone, and the shards in the zone are redistributed based on the available nodes. After the changes described above, the cluster will not create a new node or redistribute shards after the failure of the node.
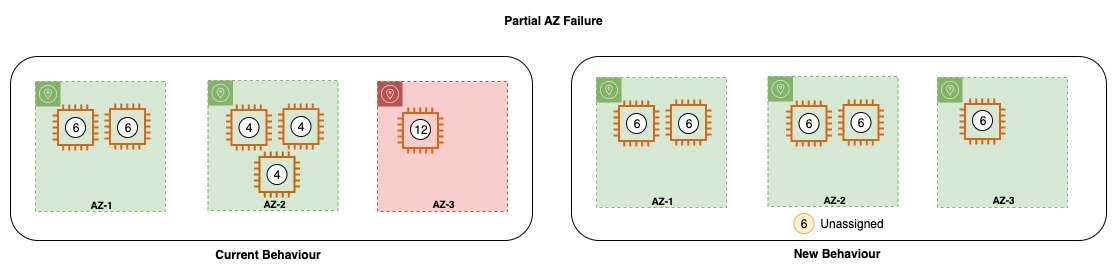
In the diagram above, with the loss of one node in AZ-3, Amazon OpenSearch Service would try to launch the replacement capacity in the same zone. However, due to some outage, the zone might be impaired and would fail to launch the replacement. In such an event, the service tries to launch deficit capacity in another healthy zone, which might lead to zone imbalance across Availability Zones. Shards on the impacted zone get stuffed on the surviving node in the same zone. However, with the new behavior, the service would try to attempt launching capacity in the same zone but would avoid launching deficit capacity in other zones to avoid imbalance. The shard allocator would also ensure that the surviving nodes don’t get overloaded.
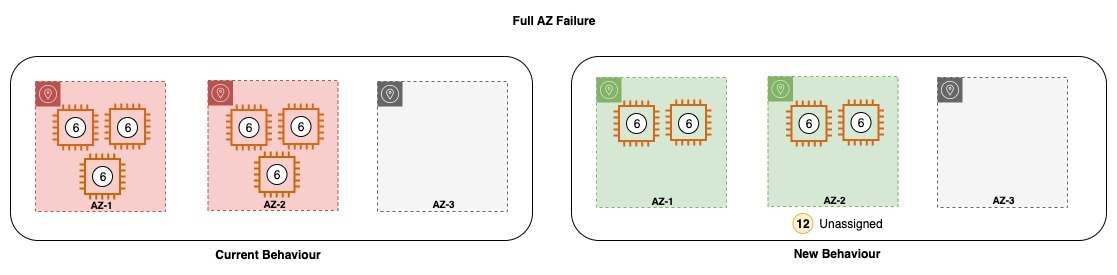
Similarly, in case all the nodes in AZ-3 are lost, or the AZ-3 becomes impaired, Amazon OpenSearch Service brings up the lost nodes in the remaining Availability Zone and also redistributes the shards on the nodes. However, after the new changes, Amazon OpenSearch Service will neither allocate nodes to the remaining zone or it will try to re-allocate lost shards to the remaining zone. Amazon OpenSearch Service will wait for the Recovery to happen and for the domain to return to the original configuration after recovery.
If your domain is not provisioned with enough capacity to withstand the loss of an Availability Zone, you may experience a drop in throughput for your domain. It is therefore strongly recommended to follow the best practices while sizing your domain, which means having enough resources provisioned to withstand the loss of a single Availability Zone failure.

Currently, once the domain recovers, the service requires manual intervention to balance capacity across Availability Zones, which also involves shard movements. However, with the new behaviour, there is no intervention needed during the recovery process because the capacity returns in the impacted zone and the shards are also automatically allocated to the recovered nodes. This ensures that there are no competing priorities on the remaining resources.
What you can expect
After you update your Amazon OpenSearch Service domain to the latest service software release, the domains that have been configured with best practices will have more predictable performance even after losing one or many data nodes in an Availability Zone. There will be reduced cases of shard overallocation in a node. It is a good practice to provision sufficient capacity to be able to tolerate a single zone failure
You might at times see a domain turning yellow during such unexpected failures since we won’t assign replica shards to overloaded nodes. However, this does not mean that there will be data loss in a well-configured domain. We will still make sure that all primaries are assigned during the outages. There is an automated recovery in place, which will take care of balancing the nodes in the domain and ensuring that the replicas are assigned once the failure recovers.
Update the service software of your Amazon OpenSearch Service domain to get these new changes applied to your domain. More details on the service software update process are in the Amazon OpenSearch Service documentation.
Conclusion
In this post we saw how Amazon OpenSearch Service recently improved the logic to distribute nodes and shards across Availability Zones during zonal outages.
This change will help the service to ensure more consistent and predictable performance during node or zonal failures. Domains won’t see any increased latencies or write blocks during processing writes and reads, which used to surface earlier at times due to over-allocation of shards on nodes.
About the authors
 Bukhtawar Khan is a Senior Software Engineer working on Amazon OpenSearch Service. He is interested in distributed and autonomous systems. He is an active contributor to OpenSearch.
Bukhtawar Khan is a Senior Software Engineer working on Amazon OpenSearch Service. He is interested in distributed and autonomous systems. He is an active contributor to OpenSearch.
 Anshu Agarwal is a Senior Software Engineer working on AWS OpenSearch at Amazon Web Services. She is passionate about solving problems related to building scalable and highly reliable systems.
Anshu Agarwal is a Senior Software Engineer working on AWS OpenSearch at Amazon Web Services. She is passionate about solving problems related to building scalable and highly reliable systems.
 Shourya Dutta Biswas is a Software Engineer working on AWS OpenSearch at Amazon Web Services. He is passionate about building highly resilient distributed systems.
Shourya Dutta Biswas is a Software Engineer working on AWS OpenSearch at Amazon Web Services. He is passionate about building highly resilient distributed systems.
 Rishab Nahata is a Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is active contributor to OpenSearch.
Rishab Nahata is a Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is active contributor to OpenSearch.
 Ranjith Ramachandra is an Engineering Manager working on Amazon OpenSearch Service at Amazon Web Services.
Ranjith Ramachandra is an Engineering Manager working on Amazon OpenSearch Service at Amazon Web Services.
 Jon Handler is a Senior Principal Solutions Architect, specializing in AWS search technologies – Amazon CloudSearch, and Amazon OpenSearch Service. Based in Palo Alto, he helps a broad range of customers get their search and log analytics workloads deployed right and functioning well.
Jon Handler is a Senior Principal Solutions Architect, specializing in AWS search technologies – Amazon CloudSearch, and Amazon OpenSearch Service. Based in Palo Alto, he helps a broad range of customers get their search and log analytics workloads deployed right and functioning well.