Amazon Web Services ブログ
Apache Hive メタストアを Amazon EMR に移行してデプロイする
Amazon EMR の速さと柔軟性を、Apache Hive の有用性とユビキタス性と組み合わせることで、両方の長所が得られます。ただし、ビッグデータプロジェクトを始めるのは容易なことではありません。EMR に新しいデータをデプロイする場合でも、既存のプロジェクトを移行する場合でも、この記事では開始するための基本を説明します。
Apache Hive は、Apache Hadoop クラスターで動作するオープンソースのデータウェアハウスおよび分析パッケージです。Hive メタストアには、パーティション名やデータ型など、テーブルとその基礎となるデータの説明が含まれています。Hive は、EMR で実行できるアプリケーションの 1 つです。
この記事が提示するソリューションの大半は、メタストアを管理するために、Hiveにスケーラビリティを提供する Apache Hadoop を使用していることを前提としています。Hadoop を使用しない場合は、Amazon EMR のドキュメントを参照してください。
Hive メタストアのデプロイメント
Hive メタストアでは、埋め込み、ローカル、またはリモートの 3 つの構成パターンのいずれかを選択できます。 オンプレミスの Hadoop クラスターを EMR に移行する場合、移行戦略は既存の Hive メタストアの構成によって異なります。
設定を検討する際は、いくつかの重要な事実を考慮してください。Apache Hive には、埋め込みメタストアに使用できる Derby データベースが付属しています。ただし、Derby は本番稼働レベルのワークロードには対応できません。
EMR を実行している場合、Hive はマスターノードのファイルシステム上の MySQL データベースにメタストア情報を一時ストレージとして記録し、ローカルメタストアを作成します。 クラスターが終了すると、そのマスターノードを含めてすべてのクラスターノードがシャットダウンし、データが消去されます。
これらの問題を回避するには、外部 Hive メタストアを作成します。これにより、Hive メタデータストアを実装に合わせて拡張できるようになり、クラスターが終了してもメタストアが維持されるようになります。
EMR 用の外部 Hive メタストアを作成する方法は 2 つあります。
- AWS Glue データカタログを使用する
- Amazon RDS または Amazon Aurora を使用する
AWS Glue データカタログを Hive メタストアとして使用する
AWS Glue データカタログは柔軟で信頼性が高いため、メタストアの構築や維持に不慣れな場合に最適です。AWS がサービスを管理しているため、プロセスに費やす時間やリソースが少なくて済みますが、きめ細かい制御も犠牲になります。データカタログは、可用性が高く、フォールトトレラントで、データレプリカを維持して障害を回避し、使用状況に応じてハードウェアを拡張します。
Hiveメタストアデータベースインスタンスを個別に管理したり、継続的なレプリケーションを維持したり、インスタンスをスケールアップしたりする必要はありません。AWS Glue データカタログは、1 つまたは複数の EMR クラスターを提供し、Amazon Athena および Amazon Redshift Spectrum をサポートすることができます。また、Apache Hive メタストア用の AWS Glue データカタログクライアントのソースコードをダウンロードして、そのコードを互換性のあるクライアントを構築するための参照実装として使用することもできます。
それでも、AWS Glue データカタログでは、十分な制御も可能です。ファイルの暗号化を有効にするか、特定のプロセスを許可または禁止するようにアクションアクセスを設定できます。データカタログは現在列統計、Hive 承認、または Hive 制約をサポートしていないことに注意してください。
AWS Glue データカタログには複数のバージョンがあります。つまり、1 つのテーブルに複数のスキーマバージョンを含めることができます。AWS Glue は、Hive メタストアデータを含めて、情報をデータカタログに保存します。カタログの構成に基づいて、新しいスキーマバージョンを採用するか、または新しいバージョンを無視することができます。
リリースバージョン 5.8.0 以降を使用して EMR クラスターを作成する場合、Hive メタストアとしてデータカタログを選択することができます。データカタログは、以前のリリースでは使用できません。
EMR コンソールを使用して AWS Glue データカタログを指定する
EMR クラスターを設定するときは、ステップ 1 で [Advanced Options] を選択して AWS Glue データカタログ設定を有効にします。Apache Hive、Presto、Apache Spark はすべて Hive メタストアを使用します。EMR 内には、これらのアプリケーションのいずれについても AWS Glue データカタログを使用するオプションがあります。
AWS CLI または EMR API を使用して AWS Glue データカタログを指定する
AWS CLI または EMR API でクラスターを作成するときに AWS Glue Dデータカタログを指定するには、ハイブサイト構成分類を使用します。hive.metastore.client.factory.class プロパティの値を com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory に設定します。
EMR クラスターを作成する場合、構成の分類を JSON ファイルに保存してから、クラスターを作成するときにそのファイルを指定します。詳細については、Amazon EMR リリースガイドのアプリケーションの設定を参照してください。
Amazon RDS または Amazon Aurora を Hive メタストアとして使用する
Hive メタストアを完全に制御したい場合や、Apache Ranger や Apache Atlas などの他のオープンソースアプリケーションと統合したい場合は、Hive メタストアを Amazon RDS でホストできます。
Hive メタストアは単一障害点であることを常に心に留めておいてください。 Amazon RDS はデータベースを自動的にレプリケートしないので、Amazon RDS を使用する場合は、障害発生時にデータが失われないように、レプリケーションを有効にする必要があります。
RDS または Aurora を使用して Hive メタストアを設定するには、主に 3 つの手順があります。
- MySQL または Aurora データベースを作成する。
- MySQL または Aurora データベースを指すように hive-site.xml ファイルを設定する。
- 外部 Hive メタストアを指定する。
MySQL または Aurora データベースを作成する
Amazon RDS または Amazon Aurora データベースで MySQL データベースを設定することから始めます。設定プロセスにすべての情報が必要になるので、URL、ユーザー名、パスワード、およびデータベース名をメモしておきます。
データベースのセキュリティグループを更新して、EMR クラスターと MySQL データベースポート間の JDBC 接続 (デフォルト: 3306) を許可します。
外部 Hive メタストア用に EMR を設定する
EMR を設定するには、以下の Hive サイト分類情報を含む設定ファイルを作成します。
- jdo.option.ConnectionDriverName は、ドライバー org.mariadb.jdbc.Driver (優先ドライバー) に反映される必要があります。
- jdo.option.ConnectionURL、javax.jdo.option.ConnectionUserName、javax.jdo.option.ConnectionPassword はすべて、新しく作成されたデータベースを指す必要があります。
外部 Hive メタストアを指定する
設定を保存したら、外部 Hive メタストアを指定します。これは、EMR コンソールまたは AWS CLI のどちらでも実行できます。
EMR コンソールで、前の手順で作成した分類設定を S3 からの JSON ファイルまたは埋め込みテキストとして入力します。
AWS CLI を使用している場合は、分類情報を hive-configuration.json という名前のファイルとして保存し、設定ファイルをローカルファイルとして、または S3 から渡します。
- ローカルパスの Hive-configuration.json ファイル:
aws emr create-cluster --release-label emr-5.17.0 --instance-type m4.large --instance-count 2 \
--applications Name=Hive --configurations ./hive-configuration.json --use-default-roles
- Amazon S3 の Hive-configuration.json ファイル:
aws emr create-cluster --release-label emr-5.17.0 --instance-type m4.large --instance-count 2 \
--applications Name=Hive --configurations s3://emr-sample/hive-configuration.json --use-default-roles
Hive メタストア移行オプション
Hadoop ベースのワークロードをオンプレミスからクラウドに移行するときは、Hive メタストアも移行する必要があります。移行計画または要件に応じて、次の 2 つの方法のいずれかで移行することができます。
- 1 回限りのメタストア移行。既存の Hive メタストアを完全に AWS に移行します。
- 継続的なメタストア同期。Hive メタストアを移行しますが、移行フェーズ中に 2 つのメタストアがリアルタイムで同期できるように、オンプレミスでコピーも保持しています。
1 回限りのメタストア移行
1 回限りの移行オプションを使用すると、ワークスペース全体を移動でき、再度移行することを心配する必要はありません。 既存の Hive ワークロードを EMR 上で実行する予定であれば、この状況は完璧です。次の図は、このシナリオを示しています。
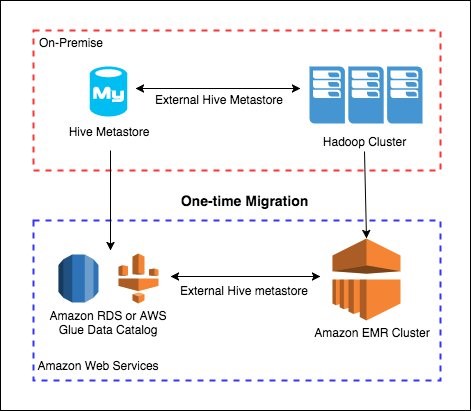
Hive メタストアを AWS Glue データカタログに移行する
この場合、目標は既存の Hive メタストアをオンプレミスから AWS Glue データカタログに移行することです。この移行を進める方法はいくつかありますが、最も簡単な方法は AWS Glue ETL ジョブを使用して Hive メタストアからメタデータを抽出することです。 その後、AWS Glue ジョブを使用してメタデータをロードし、AWS Glue データカタログを更新します。このプロセスを管理するためのスクリプトは、既に GitHub に多数存在しています。
Hive メタストアを Amazon RDS または Amazon Aurora に移行する
AWS Glue データカタログを使用する代わりに、Hive メタストアデータをオンプレミスデータベースから AWS ベースのストレージに移動することができます。データベースのソースと、AWS での目的のターゲットに応じて、このプロセスには異なる手順が必要です。詳細については、以下のトピックを参照してください。
- オンプレミスの MySQL データを Amazon RDS に移行する (およびその逆)
- DB スナップショットを使用した MySQL DB インスタンスから Amazon Aurora MySQL DB クラスターへのデータの移行
- Amazon RDS で PostgreSQL にデータをインポートする
- Aurora リードレプリカを使用して RDS PostgreSQL DBインスタンスから Aurora PostgreSQL DB クラスターにデータを移行する
- Amazon RDS で Oracle にデータをインポートする
継続的なメタストア同期
大規模な移行は継続的な同期プロセスの恩恵を受けることができ、移行フェーズ中もデータセンターとクラウドの両方で Hive メタストアを実行し続けることができます。
継続的な同期プロセスは、移行プロセス中に入力された変更を使用して、両方の Hive メタストアを正確かつ最新の状態に保ちます。Hive メタストアの更新には 1 つのアプリケーションだけを使用してください。そうしないと、メタストアが同期しません。
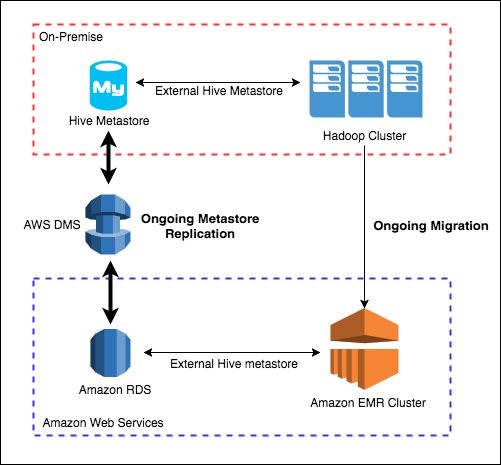
AWS DMS は継続的なレプリケーションに理想的なデータ移行サービスであり、このニーズに合わせてカスタマイズされています。レプリケートされたトランザクションのバイナリログファイルの位置を使用して、外部データベースを Amazon RDS にレプリケートすることもできます。
結論
この記事では、Hive の移行をできるだけ円滑かつ容易にするためのさまざまな既存のリソースについて説明しました。
このブログ記事の内容は、Hadoop エコシステムの各移行アプローチの長所と短所の包括的な概要を提示する EMR 移行ガイドの一部です。このガイドを読むには、今すぐ Amazon EMR 移行ガイドをダウンロードしてください。
追加の洞察やフィードバックがある場合は、ここにコメントを残すか、Twitter でお知らせください!
著者について
 Tanzir Musabbir は、AWS の EMR スペシャリストソリューションアーキテクトです。彼はオープンソース型ビッグデータテクノロジーをいち早く採り入れた人物です。AWS で、彼はお客様と協力しながら、Amazon EMR、Amazon Athena 、AWS Glue の分析ソリューションを実行するための構造的なガイダンスを提供しています。Tanzir はリアルマドリードの大ファンで、余暇には旅に出るのが好きです。
Tanzir Musabbir は、AWS の EMR スペシャリストソリューションアーキテクトです。彼はオープンソース型ビッグデータテクノロジーをいち早く採り入れた人物です。AWS で、彼はお客様と協力しながら、Amazon EMR、Amazon Athena 、AWS Glue の分析ソリューションを実行するための構造的なガイダンスを提供しています。Tanzir はリアルマドリードの大ファンで、余暇には旅に出るのが好きです。