Amazon Web Services ブログ
Snowflake から Amazon Redshift レイクハウスアーキテクチャに移行する
- 生データ、変換データ、および準備済みデータを 現在のデータウェアハウスから Amazon Simple Storage Service (Amazon S3) に移行する
- データパイプラインを再設定して、ソースから Amazon Redshift と Amazon S3 にデータを移動させます。こうすることで、レイクハウスアーキテクチャのネイティブに統合されたストレージレイヤーが提供されます。
この記事では、Snowflake から Amazon Redshift にデータを移行する方法を紹介します。2 番目のステップ、パイプラインの再構成については、後の記事で説明します。
ソリューションの概要
今回のソリューションは、次のアーキテクチャ図に示すように、2 つのステージで設計されています。

レイクハウスアーキテクチャの最初のステージは、データレイクにデータを取り込むことです。AWS Glue Studio とAWS Glue カスタムコネクタを使用して、ソースである Snowflake データベースに接続し、必要なテーブルを抽出して Amazon S3 に保存します。ビジネスインサイトの抽出を高速化するために、頻繁にアクセスされるデータを Amazon Redshift クラスターにロードします。アクセス頻度の低いデータは、クラスターから簡単にアクセスできる外部テーブルとしてAWS Glue Data Catalog にカタログ化します。
この記事では、オープンソースの TPCH_SF10 データセットから Customer、Lineitem、Orders の 3 つのテーブルについて検討します。AWS Glue Studio で AWS Glue ETL ジョブを作成し、Customers テーブルと Orders テーブルを Snowflake から Amazon Redshift クラスターに移動します。Lineitem テーブルは外部テーブルとして Amazon S3 にコピーします。Amazon Redshift でビューを作成し、内部データセットと外部データセットを結合します。
事前準備
開始する前に、ソリューションのセットアップとデプロイにに必要な手順を実行します:
- Snowflake に接続するための認証情報 (ユーザー名、パスワード、ウェアハウスの詳細) を使用して AWS Secrets Manager にシークレットを作成します。手順については、「チュートリアル:シークレットの作成と取得」を参照してください。
- 最新の Snowflake JDBC JAR ファイルをダウンロードし、S3 バケットにアップロードします。このバケットは、CloudFormation の手順で SnowflakeConnectionBucket として参照されます。
- Snowflake データベース内の移行するテーブルを特定します。
AWS Glue Studio を使用して Snowflake コネクタを作成する
接続を正常に完了するには、 Snowflake エコシステムと Snowflake データベーステーブルの関連パラメーターについて理解する必要があります。これらは、実行時にジョブパラメータとして渡すことができます。テストアカウントで取得した次のスクリーンショットは、サンプルジョブで使用するパラメーター値を表示しています。

次のスクリーンショットは、Secrets Manager のアカウント認証情報とデータベースを表示しています。

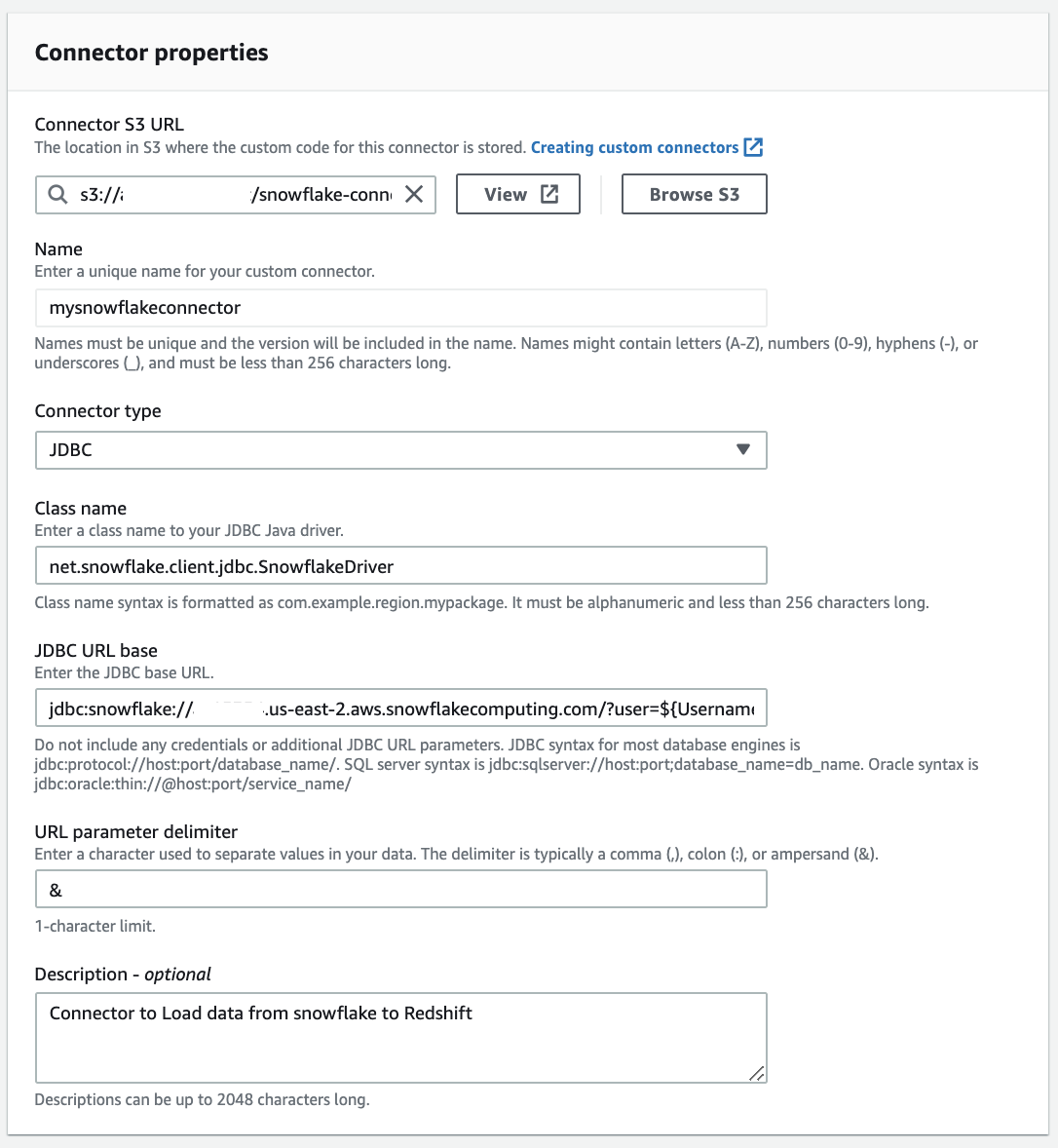
Snowflake 用の AWS Glue カスタムコネクタを作成するには、次の手順を実行します:
- AWS Glue Studio コンソールの Connectors (コネクタ) で、Create custom connector (カスタムコネクタの作成) を選択します。

- Connector S3 URL (コネクタ S3 URL) で、Snowflake JDBC Connector JAR ファイルをアップロードした S3 の場所を参照します。
- Name (名前) に、論理名を入力します。
- Connector type (コネクタタイプ) で、JDBC を選択します。
- Class name (クラス名) に
net.snowflake.client.jdbc.SnowflakeDriverと入力します。 - JDBC URL base を次の形式で入力します。
jdbc:snowflake://<snowflakeaccountinfo>/?user=${Username}&password=${Password}&warehouse=${warehouse} - URL parameter delimiter (URL パラメータ区切り文字) に & と入力します。
- 必要に応じて、コネクタを識別するための説明を Description に入力します。
- Create connector (コネクタの作成) を選択します。
Snowflake JDBC 接続を設定する
Snowflake への JDBC 接続を作成するには、次の手順を実行します:
- AWS Glue Studio コンソールで、Connectors (コネクタ) を選択します。
- 作成したコネクタを選択します。
- Create connection (接続の作成) を選択します。

- Name (名前) と Description (説明) に、参照用の論理名と説明を入力します。

- Connection credential type (接続認証情報の種類) で、default (デフォルト) を選択します。
- AWS Secret で、事前準備で作成したシークレットを選択します。
- 必要に応じて、プレーンテキスト形式で認証情報をを指定できます。
- Additional options (追加オプション) で、次のキーと値のペアを追加します。
- キー
dbの値にSnowflake のデータベース名 - キー
schemaの値にSnowflake のデータベーススキーマ - キー
warehouseの値に Snowflake のウェアハウス名
- キー
- Create connection (接続の作成) を選択します。
AWS CloudFormation を使用して他のリソースとアクセス権限を設定する
このステップでは、 AWS CloudFormation を使用して追加のリソースを作成します。このリソースには、Amazon Redshift クラスター、AWS Identity and Access Management(IAM)ロールとポリシー、S3 バケット、および Snowflake から Amazon S3 および Amazon S3 から Amazon Redshift へテーブルをコピーする AWS Glue ジョブが含まれます。
- IAM パワーユーザー (できれば管理者ユーザー) として AWS マネジメントコンソールにサインインします。
- リージョンは
us-east-1を選択します。 - Launch Stack を選択します。

- Next (次へ) を選択します。
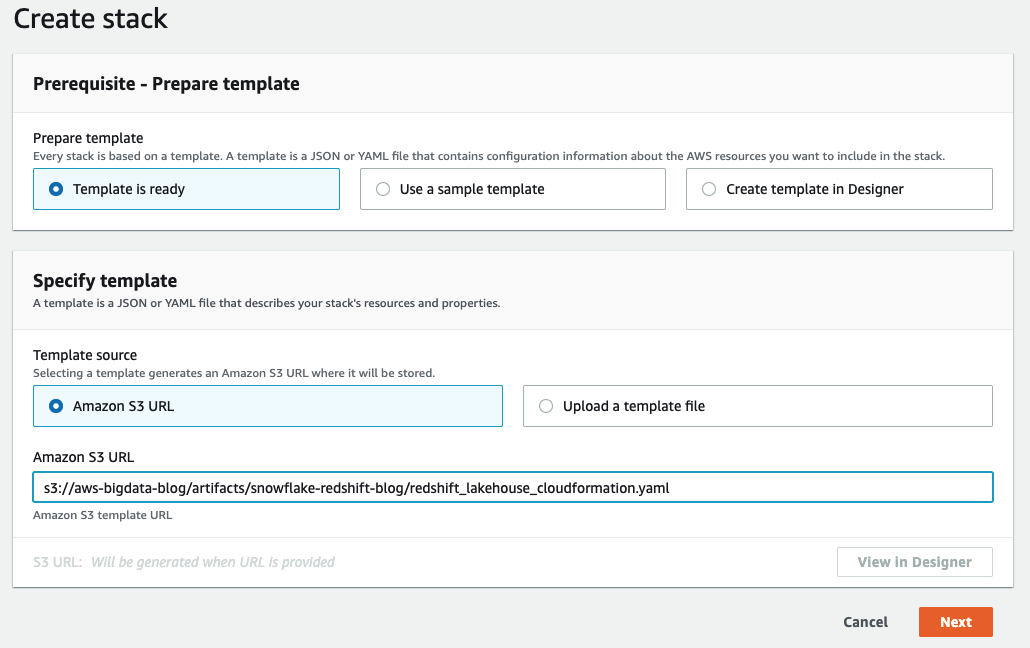
- Stack name (スタックの名前) に、スタックの名前を入力します (例:
snowflake-to-aws-blog.)。 - Secretname には、事前準備で作成したシークレット名を入力します。
- SnowflakeConnectionName に、作成した Snowflake JDBC 接続を入力します。
- SnowflakeConnectionBucket に、Snowflake コネクタがアップロードされる S3 バケットの名前を入力します。
- SnowflakeTableNames に、Snowflake から移行するテーブルのリストを入力します。たとえば、
Lineitem,customers,orderです。 - RedshiftTableNames には、ウェアハウス (Amazon Redshift) にロードするテーブルのリストを入力します。たとえば、
customers,orderです。

- Amazon Redshift のノードタイプ、ノード数、および Amazon Redshift のユーザー名とパスワードを指定するか、デフォルト値を使用するかを選択できます。
- MasterUserPassword には、次の制約に留意して、マスターユーザーのパスワードを入力します。パスワードの長さは 8 ~ 64 文字にする必要があります。少なくとも 1 つの大文字、1 つの小文字、1 つの数字を含める必要があります。
- Create stack (スタックを作成) を選択します。
データロード用に AWS Glue ジョブを実行する
スタックの完了には約 7 分かかります。スタックが正常にデプロイされたら、次のアクションを実行します:
- AWS Glue Studio コンソールの Databases (データベース) で、Connections (接続) を選択します。
- リストから
redshiftconnectionを選択し、Test Connection (接続のテスト) を選択します。 - ドロップダウンメニューから IAM ロール
ExecuteGlueSnowflakeJobRoleを選択し、Test connection (接続のテスト) を選択します。

エラーが表示された場合は、ユーザー名とパスワードを確認または編集して、もう一度やり直してください。
- 接続が正常にテストされたら、AWS Glue Studio コンソールで、ジョブ
Snowflake-s3-load-jobを選択します。 - Action (操作) メニューの Run job (ジョブの実行) を選択します。

ジョブが完了すると、SnowflakeTableNames パラメーターで指定したすべてのテーブルが S3 バケットにロードされます。このジョブの完了にかかる時間は、テーブルの数とサイズによって異なります。
次に、指定したテーブルを Amazon Redshift にロードします。
- ジョブ
s3-redshift-load-jobを実行します。 - ジョブが完了したら、Amazon Redshift コンソールに移動します。
- クエリエディタを使用してクラスターに接続し、
RedshiftTableNamesで指定したテーブルが正常にロードされていることを確認します。
Amazon Redshift からデータセットを表示およびクエリできるようになりました。Lineitem データセットは Amazon S3 上にあり、 Amazon Redshift Spectrum によってクエリします。次のスクリーンショットは、Amazon Redshift から Amazon S3 のデータをクエリするために Amazon Redshift 外部スキーマを作成する方法を示しています。

Amazon Redshift のストレージにロードされたテーブルは、次のスクリーンショットのように表示されます。

AWS Glue ジョブは、標準のワーカータイプを使用して Snowflake データを Amazon S3 に移動しました。このジョブは約 21 分で完了し、全体で 2.089 GB (約 7,650 万レコード) がロードされました。Snowflake コンソールの次のスクリーンショットは、Amazon S3 にコピーしたテーブルとそのサイズを示しています。

AWS Glue ワーカータイプ、ワーカーノード、最大同時実行数をカスタマイズして、分散とワークロードを調整できます。
AWS Glue では、データを列で分割することにより、データストアからの並列データ読み取りが可能です。パーティション列、パーティションの下限、パーティションの上限、およびパーティションの数を指定します。この機能を使用すると、データの並列処理と、Spark アプリケーションを割り当てた複数の Spark エグゼキューターを使用できます。
以上で、Snowflake から Amazon Redshift への移行が完了しました。Amazon Redshift への移行により、レイクハウスアーキテクチャを実現し、より多くの方法でデータを分析できるようになります。さらに一歩踏み出して、データの民主化のためにこのアーキテクチャを拡張し、データウェアハウスをモダナイズするのに役立つ Amazon Redshift の機能について説明します。
データウェアハウスをモダナイズする
Amazon Redshift は、データレイク、データウェアハウス、およびその他のストアからのクエリを可能にするレイクハウスアーキテクチャを強化します。Amazon Redshift は、Redshift Spectrum を使用してデータレイクにアクセスできます。Amazon Redshift は、Redshift クラスタとは別にある Spectrum のフリートから、自動的に Spectrum ノードを活用します。これらのノードは Amazon S3 に対して直接クエリを実行し、スキャンと集計を実行し、データをコンピューティングノードに返して処理します。
AWS Lake Formation は、Amazon S3 ベースのデータレイクに保存されたデータに対するガバナンスソリューションであり、列レベルと行レベル(訳注:2021年11月4日時点でプレビュー)でのきめ細かなアクセスコントロールを備えた中心的なアクセス許可モデルを提供します。Lake Formation では、AWS Glue データカタログをメタデータリポジトリとして使用し、設計図とクローラを使用してデータを簡単に取り込み、カタログ化できます。
次のスクリーンショットは、Lake Formation によって管理される AWS Glue データカタログにおける Snowflake のテーブルを示しています。

Amazon Redshift データレイクのエクスポート機能を使用すると、データを Apache Parquet などのオープンフォーマットで Amazon S3 に保存して、Amazon Athena や Amazon EMR などの分析サービスで使用することもできます。
分散ストレージ
Amazon Redshift RA3 は、コンピューティングとストレージを個別にスケーリングする柔軟性を提供します。Amazon Redshift のデータは、Amazon S3 を利用した Amazon Redshift マネージドストレージに保存されます。クラスターストレージと Amazon S3 の間でデータセットを分散すると、ユースケースに応じてデータに適切なコンピューティングを利用できるというメリットがあります。Amazon S3 に保存したデータは Amazon Redshift にアクセスしなくてもクエリできます。
スタースキーマの例を見てみましょう。急速に成長すると予想されるファクトテーブルはスキーマをデータカタログに、データを Amazon S3 に保存します。ディメンションテーブルはクラスターストレージに保存します。Amazon S3とAmazon Redshiftマネージドストレージ両方からのデータをユニオンするビューを作成することもできます。
データ分散の別のモデルは、ホットデータはAmazon Redshift マネージドストレージ、コールドデータは Amazon S3 に保存するというモデルです。この例では、データセットのlineitem、 customer、および ordersがあります。customer と orders のポートフォリオは、lineitem と比較して更新頻度の低いデータセットです。Amazon S3 から lineitem データ、データカタログデータベースからスキーマを読み取る外部テーブルを作成し、customer と orders を Amazon Redshift テーブルにロードできます。次のスクリーンショットは、データセット間の結合クエリを示しています。
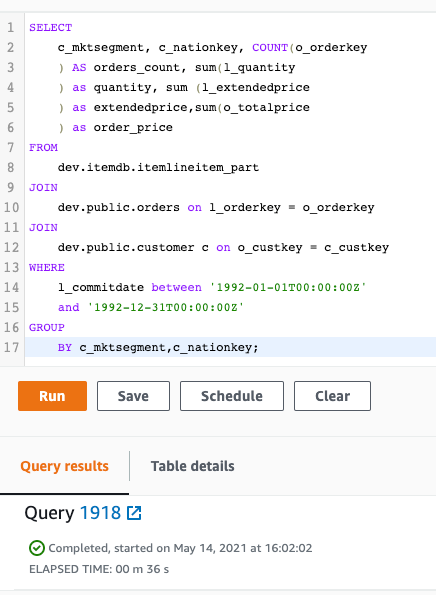
このクエリ全体の実行統計を知ることは興味深いでしょう。このクエリの実行統計は、システムテーブルからクエリできます。次のコードは、svl_s3query_summary を使用して、前のクエリから統計を取得します。
次のスクリーンショットは、クエリの出力を示しています。

このクエリの詳細については、「SVL_QUERY_SUMMARY ビューの使用」を参照してください。
自動テーブル最適化
分散キーとソートキーは、データの物理的な格納方法を定義するテーブルプロパティです。これらは Amazon Redshift によって管理されています。自動テーブル最適化では、クエリがテーブルとどのように相互作用するかを継続的に監視し、ML を使用して最適なソートキーと分散キーを選択し、クラスタのワークロードのパフォーマンスを最適化します。パフォーマンスを向上させるために、Amazon Redshift はキーを選択し、テーブルは自動的に変更されます。
前のシナリオでは、lineitem テーブルには distkey (L_ORDERKEY)、customer テーブルには distribution ALL、orders テーブルには distkey (O_ORDERKEY) がありました。
ストレージの最適化
データ形式の選択は、データサイズ (JSON、CSV、または Parquet) によって異なります。Redshift Spectrum は現在、Avro、CSV、Grok、Amazon Ion、JSON、ORC、Parquet、RCFile、RegexSerDe、Sequence、Text、TSV のデータフォーマットをサポートしています。形式を選択するときは、小さなデータセットには CSV または JSON 形式を使用するのか、同じデータセットで列指向の Parquet 形式を使用するのか、スキャンするデータ全体と I/O 効率を考慮します。小規模なスキャンの場合、CSV と比較して Parquet はより多くの計算リソースを消費し、実際には CSV とほぼ同じ時間がかかる可能性があります。ほとんどの場合、Parquet が最適な選択ですが、ボリューム、コスト、レイテンシなどの要件を考慮する必要があります。
SUPER データ型
SUPER データ型は、半構造化データをネイティブにサポートします。JSON ファイルや Ion ファイルなどのネストされたデータ形式をサポートしています。これにより、ネストされたデータを Amazon Redshift でネイティブに取り込み、保存したり、クエリできます。
SUPER データ型は、PartiQL を搭載した使いやすい SQL 拡張機能を使用してクエリできます。PartiQLは、データが構造化されているか半構造化されているかにかかわらず、フォーマットに関係なく効率的で簡単にデータをクエリできるSQL言語です。
一時停止と再開
一時停止と再開を使用すると、クラスターを簡単に開始および停止して、断続的なワークロードのコストを節約できます。この方法により、アクセス頻度の低いデータを含むクラスターをコスト効率よく管理できます。
コンソール、API、およびユーザー定義のスケジュールを使用して、一時停止と再開を適用できます。
AQUA
AQUA for Amazon Redshift は、Amazon S3 の上位にある大規模な高速キャッシュアーキテクチャで、スケールアウトして多数のノード間でデータを並列処理できます。これは、データをコンピューティングに持ち込むという現在のパラダイムを逆転します。AQUA はコンピューティングをストレージレイヤーに持ち込み、データが 2 つの間を行き来する必要がなくなるため、Amazon Redshift はクエリをより高速に実行できます。
データ共有
データ共有機能により、複数の Amazon Redshift クラスターが RA3 クラスターとそのマネージドストレージにあるデータをシームレスにクエリできます。この機能は、相互に分離されつつも、グループ間のコラボレーションのために実際にデータをコピーすることなくデータを共有する必要があるワークロードに最適です。
Concurrency scaling
Amazon Redshift は、一時的なクラスターを数秒で自動的に追加することで、同時にリクエストされた突発的なスパイクに一貫して高速なパフォーマンスで対応します。1 日の使用ごとに、1 時間の Concurrency Scaling が無料で利用できます。
まとめ
この記事では、Snowflake データウェアハウスを、Amazon Redshift を介してアクセスできるデータレイクを備えたレイクハウスアーキテクチャに移行するアプローチについて説明しました。
AWS Glue を使用して、Snowflake などのソースからデータレイクにデータを移動し、カタログ化し、分析に利用できるようにするまでを、いくつかの簡単なステップで説明しました。また、Lake Formation を使用して、データレイクでガバナンスときめ細かなセキュリティを実現する方法についても説明しました。最後に、ビジネスニーズに合わせて、使いやすく、パフォーマンスが向上し、スケールする Amazon Redshift のいくつかの新機能について説明しました。
原文はこちらです。
本ブログは Solutions Architect の宮田が翻訳しました。