Amazon Web Services ブログ
New – Amazon QuickSight Q の自動データ準備の発表
2021 年 9 月に公開されたこの投稿において、Jeff Barr は Amazon QuickSight Q の一般提供の開始を発表しました。簡単に言えば、Amazon QuickSight Q は、ビジネスユーザーがデータについて簡単な質問をすることを可能にする自然言語クエリ機能です。
QuickSight Q は機械学習 (ML) を利用しており、平易な言葉でデータをクエリできることから、ダッシュボード、コントロール、計算を使用する必要がないため、セルフサービスで分析できます。昨年発表された QuickSight Q では、「2021 年に EMEA で最も多く売り上げたのは誰か」などの簡単な質問をして、(グラフ、地図、表などの関連するビジュアライゼーションとともに) 回答を数秒で得ることができます。
分析に使用されるデータは Amazon Redshift などのデータウェアハウスに保存されることが多く、残念ながら、これらは自然言語による操作ではなく、SQL を介したプログラムによるアクセス向けに最適化される傾向にあります。さらに、BI チームは、当然のことながら、ダッシュボード作成者、BI エンジニア、その他のデータチームによる使用のためにデータソースを最適化する傾向にあるため、ダッシュボード (例: 「Customer」ではなく「CUST_ID」) や SQL クエリ向けに最適化された技術的な命名規則を使用します。ビジネスユーザーは、これらの技術的な命名規則を直感的に使用できません。
この問題を解決することを目的として、BI チームは自然言語による質問向けにデータを準備するために、技術的な名前を、一般的に使用されるビジネス言語の名前に手動で変換するのに何時間も費やしています。
11 月 29 日、Amazon QuickSight Q の自動データ準備を発表します。自動データ準備は、機械学習を利用してデータに関するセマンティック情報を推測し、列 (フィールド) に関するメタデータとしてデータセットに追加することで、自然言語による質問をサポートするためにデータをより迅速に準備できるようにします。
QuickSight Q のトピックの簡単な概要
QuickSight Q の導入により、トピックを使用できるようになりました。トピックは、ビジネスユーザーが質問できる主題領域を表す 1 つ以上のデータセットをまとめたものです。前述の例 (「2021 年に EMEA で最も多く売り上げたのは誰か」) では、このトピックの作成中に 1 つ以上のデータセット (例: Sales/Regional Sales データセット) が選択されることになるでしょう。
トピックが作成されたら、作成者は次を行うことになります。
- トピックに追加する最も関連性の高い列をデータセットから選択するのに時間を費やします (例えば、time_stamp、date_stamp 列などを除外する)。ダッシュボードやレポートの列の使用状況データを可視化しないと、どの列をトピックに含めるのがビジネスユーザーにとって最も関連性が高くなるのかを客観的に判断するのが難しい場合があるため、これは困難であることがあります。
- その後、何時間もかけてデータを確認し、手動で厳選して、自然言語に固有の構成を設定します (例: [Region] (リージョン) 列の同義語として [Area] (地域) を追加する)。
- 最後に、データが表示されたときの有用性を高めるために、データのフォーマット設定に時間を費やすことになります。
-

QuickSight Q トピック
Amazon QuickSight Q の自動データ準備はどのように機能しますか?
分析からの作成: Amazon QuickSight Q の新しい自動データ準備は、分析からトピックを作成する機能を実現し、対象のデータフィールドの同義語や一般的な用語を検索する ML トレーニング済みモデルに基づいてユーザーにとってわかりやすい名前と同義語が自動的に選択するため、この機能がなければすべての変換に費やしていたであろう時間を節約できます。さらに、Amazon QuickSight Q の自動データ準備は、最も関連性の高い列を選択する代わりに、分析における使用方法に基づいて価値の高い列を自動的に選択します。その後、この既存の分析データセットにトピックをバインドし、データ内の一意の文字列の値のインデックスを準備して、自然言語による検索を可能にします。
自動フィールド選択と分類: Amazon QuickSight Q の自動データ準備では価値の高い列が選択される旨を前述しましたが、価値の高い列はどのように判断されるのでしょうか? Amazon QuickSight Q の自動データ準備は、レポートやダッシュボードなどの既存の QuickSight アセットからのシグナルに基づいて列選択を自動化し、ビジネスユーザーに関連するトピックを作成するのをサポートします。Amazon QuickSight Q の自動データ準備は、データセットから価値の高いフィールドを選択するだけでなく、作成者が分析で作成した新しい計算フィールドもインポートするため、トピック内でこれらを再作成する必要はありません。
自動言語設定: この記事の冒頭で、ビジネスユーザーにとって直感的でない技術的な命名規則について述べました。この機能により、列名は、一般的な用語を使用してわかりやすい名前や同義語で自動的に更新されるため、これらの技術的な名前の変換に時間を費やさずに済みます。Sales データセットの例を見ると、CUST_ID には「Customer」というわかりやすい名前と、いくつかの同義語が割り当てられています。ビジネスユーザーに関連する可能性のある幅広い語彙をサポートするために、同義語が列に自動的に追加されるようになりました (さらにカスタマイズするためのオプションもあります)。

列のわかりやすい名前と同義語
自動メタデータ設定: Amazon QuickSight Q の自動データ準備は、列の値に基づいて列の Semantic Type を検出し、対応する設定を自動的に更新します。今後、値のフォーマットは、回答に特定の列が表示されている場合に使用されるように設定されます。これらのフォーマットは、分析で定義したフォーマットから派生します。
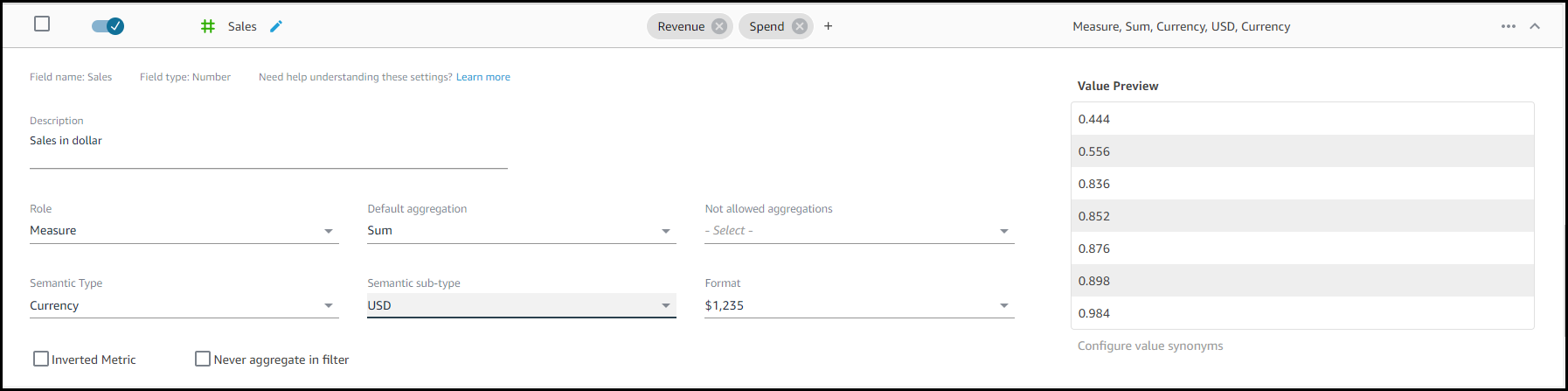
セマンティックタイプの設定
今すぐご利用いただけます
Amazon QuickSight Q の自動データ準備は、QuickSight Q が利用可能なすべての AWS リージョンで 11 月 29 日からご利用いただけます。詳細については、Amazon QuickSight Q ページをご覧ください。QuickSight コミュニティに参加して、QuickSight コミュニティで他のユーザーとともに、質問、回答、学習できます。
– Veliswa x
原文はこちらです。