Amazon Web Services ブログ
新機能 – Auto Scaling for Amazon DynamoDBについて
Amazon DynamoDBには幅広い業界やユースケースを含む10万人以上の多くのお客様がいます。 お客様は世界中の16の地域で、DynamoDBの一貫性のあるパフォーマンスを利用する事が出来ます。 最近の傾向は、DynamoDBを使用してサーバレスアプリケーションと組み合わせるお客様です。 この使い方は非常にマッチします:DynamoDBでは、サーバーのプロビジョニング、OSとデータベースのソフトウェアパッチ適用、または高可用性を確保するためのAZゾーン間のレプリケーションの設定などを考える必要はありません。テーブルを作成してデータを追加するだけでDynamoDBが処理するようにします。
DynamoDBにはプロビジョニングキャパシティーユニットモデルが用意されており、アプリケーションで必要とされる読み書き容量を設定できます。 これによりサーバの考え方から解放され、簡単なAPIコールまたはAWS Management Consoleのボタンをクリックしてテーブルのプロビジョニングを変更できるようになりましたが、多くのお客様はDynamoDBの容量をさらに簡単に管理できるように望んでいました。
本日、DynamoDBのAuto Scalingを導入して、テーブルとグローバルセカンダリインデックス(GSI)の容量管理を自動化できるようになりました。 維持をしたい使用率を指定し、読み書き容量の上限と下限を指定するだけです。 DynamoDBは、Amazon CloudWatchアラームを使用して消費量を監視し、必要に応じてプロビジョニングされた容量を調整します。 Auto Scalingは、すべての新しいテーブルとインデックスに対してデフォルトでオンに出来ます(但しIAM権限の事前準備が必要です)。また、既存のテーブルやインデックスに対しても設定できます。
あなたが常にマネジメントコンソールに張り付いていなくても、DynamoDB Auto Scalingはテーブルとインデックスを監視して、アプリケーショントラフィックの変化に応じて自動的にスループットを調整します。 これによりDynamoDBデータの管理が容易になり、アプリケーションの可用性を最大化しDynamoDBのコストを削減するのに役立ちます。
どのような機能か早速御覧ください。
Using Auto Scaling
新しいテーブルを作成するときに、DynamoDB Consoleにデフォルトパラメータセットが提示されるようになりました。 あなたはそのまま利用する事も、「Use default settings」のチェックを外して独自のパラメータを入力することもできます
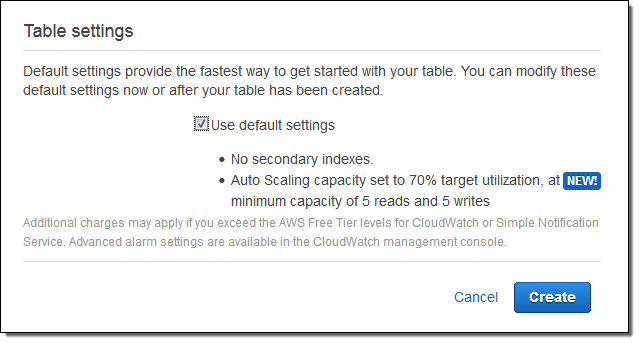
独自にパラメータを設定する方法は以下の通りです。
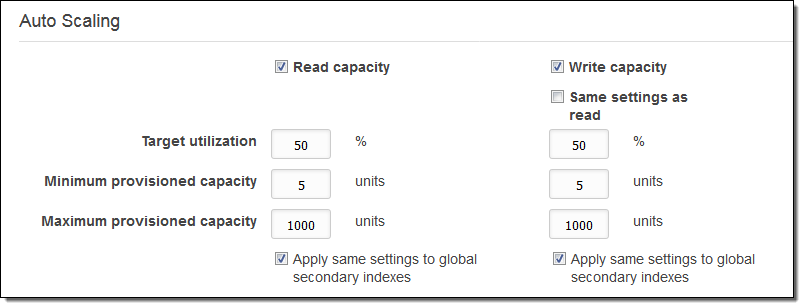
Target utilizationは、消費容量とプロビジョニングされた容量の比率で表されます。 上記のパラメータは、読み取りまたは書き込み要求が増えた時でも消費される容量の2倍になるように十分な空き容量を確保します(DynamoDBの読み書き操作とプロビジョニングされた容量の関係の詳細については容量単位の計算を参照してください)。 プロビジョニングされた容量の変更は、バックグラウンドで行われます。
Auto Scaling in Action
この重要な新機能が実際に動作するのを見るために、「Getting Started Guide」の指示に従いました。 私は、新しくEC2インスタンス起動し、AWS SDK for Pythonを設定(sudo pip install boto3)を実行し利用するための設定(aws configure)を行いました。 次に、PythonとDynamoDBのコードを使用していくつかのデータを含むテーブルを作成し、読み込みと書き込みの各容量を5ずつ手動で設定しました。
CloudWatchメトリクスで綺麗な直線を得るために私は急いで休憩を取ったので、AutoScalingの効果を示すことができました。 負荷を適用する前のメトリクスは次のとおりです。
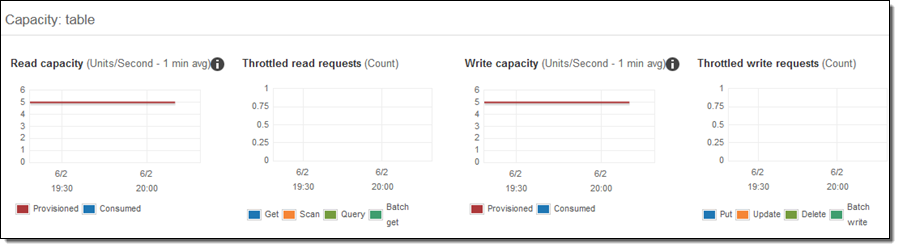
私はステップ3のコードを変更して、1920年から2007年の範囲でランダムにクエリを発行し、1〜2分後に読み取りメトリクスを確認しました。
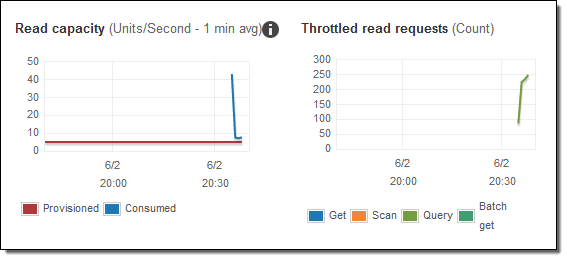
消費された容量はプロビジョニングされた容量よりも多く、その結果多くの読み込みリクエストに対してスロットルが発生します。 AutoScalingが実行される!
私はコンソールに戻ってテーブルのCapacityタブをクリックした。 Read capacityをクリックし、デフォルト値を受け入れ、Saveをクリックしました
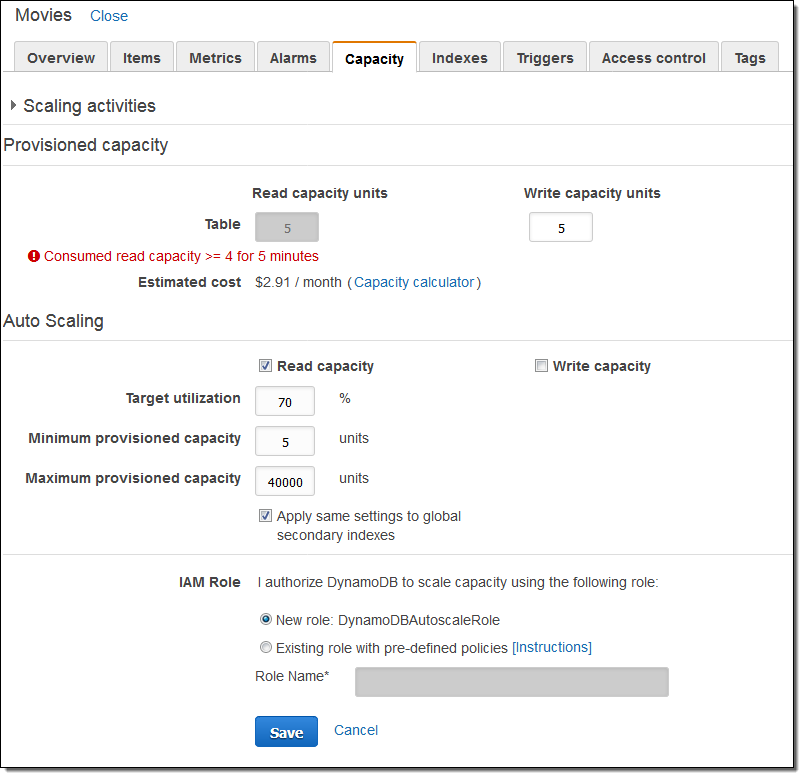
DynamoDBは新しいIAMロール(DynamoDBAutoscaleRole)とCloudWatchアラームのペアを作成して、読み取り容量のAuto Scalingを設定しました。
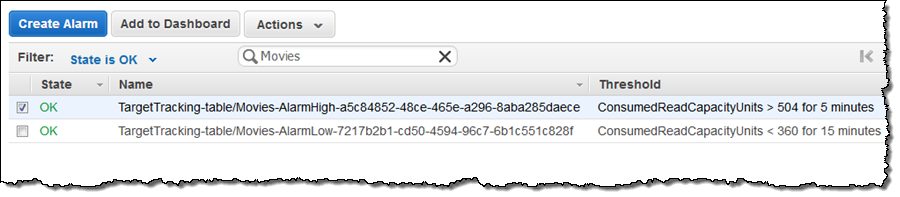
DynamoDB Auto Scalingはアラームのしきい値を管理し、スケーリングプロセスの一部としてアラームのしきい値を上下に調整します。 最初のアラームがトリガーされ追加の読み取り容量がプロビジョニングされている間にテーブルの状態が[Updating]に変更されました。
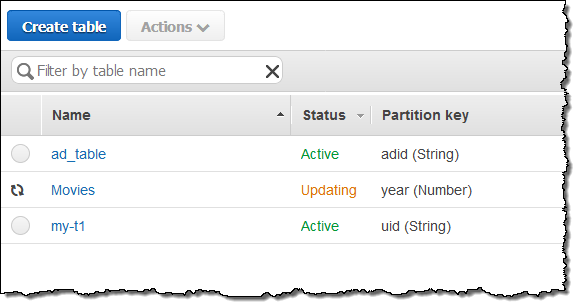
この変更は、数分で読み取りメトリクスに表示されました。
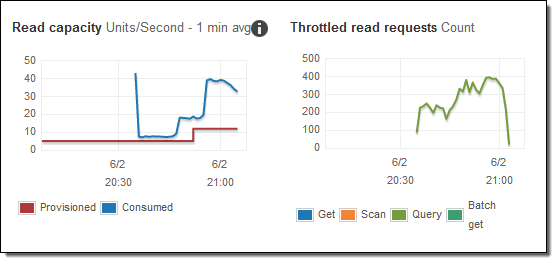
私は変更されたクエリスクリプトをいくつか実行し、追加の容量がプロビジョニングされているのを見てみました。
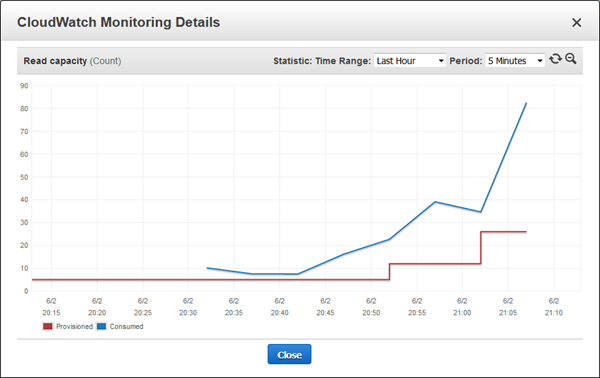
私はすべてのスクリプトを停止しスケールダウンアラームが発生するのを待ちました。:
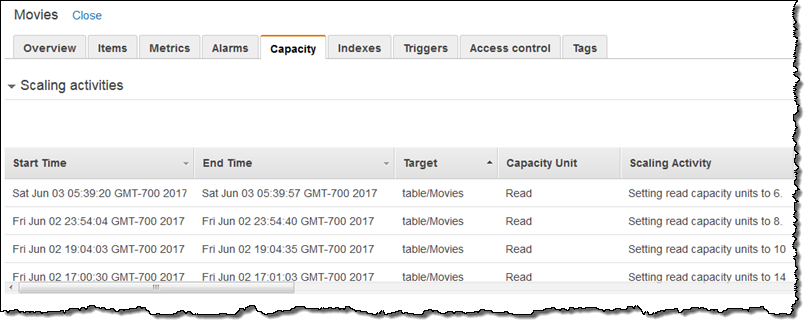
翌朝Scaling activitiesを確認し、アラームが夜の間に何度かトリガされたことを確認しました:
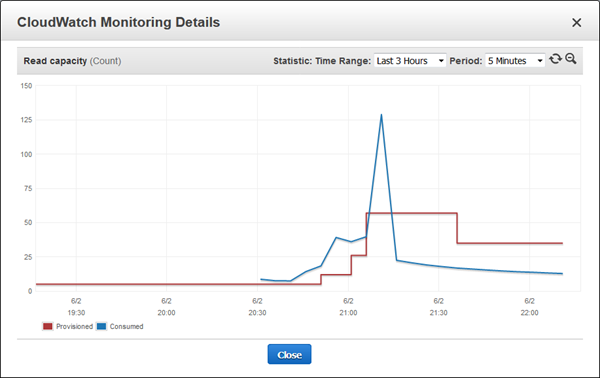
これはメトリクスにも表示されていました。
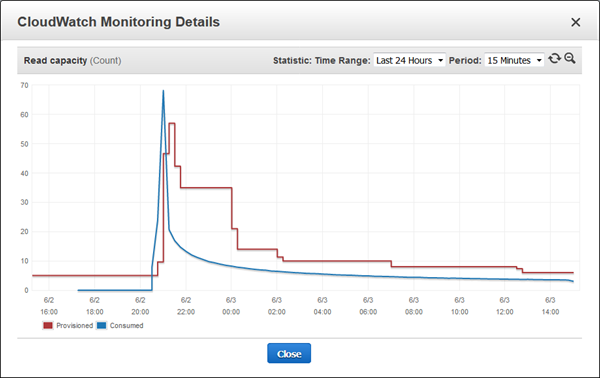
これまでは、あなたが期待した使用量についてプロビジョンキャパシティユニットを十分に設定し、余裕を持たせる設定(青い線と赤い線の間のスペース)を行うことで、このような状況に備えることができました。若しくはプロビジョンキャパシティユニットを少なくしすぎ、監視するのを忘れてトラフィックが増えた時に容量が使い果たされる可能性がありました。 Auto Scalingを使用すると、リクエストが増加し必要な場合は自動的に増やし、もう不要な時は自動的に下げる事が可能です。
Things to Know
DynamoDB Auto Scalingは、ある程度予測可能である程度定期的に変化する要求レートに対応するように設計されています。予期せぬバーストした読み取りアクティビティに対応する必要がある場合は、Auto ScalingをDAXと組み合わせて使用する必要があります(詳細は、Amazon DynamoDB Accelerator(DAX) – Read heavyなワークロード向けインメモリ型キャッシュクラスタを参照してください)。また、AWS SDKを利用したアプリケーションは、スロットリングされた読み込み要求と書き込み要求を検出し、適切な遅延の後に再試行します。
(補足:Auto Scaling実行され実際に使える容量が増えるまでにはどうしても時間が掛かります。その為瞬間的なリクエスト増加に対応するのは難しいケースがあります。その為、瞬間的なリクエスト増加に対応するにはDAXなどのソリューションと組み合わせる事や、瞬間的にスロットリングが発生してもリトライで処理を継続させる事により影響を最小限にする処理が必要です。)
私はDynamoDBAutoscaleRoleを先に述べました。このロールは、テーブルとインデックスのスケールを上下させるために必要な権限をAuto Scalingに提供します。このロールと権限の詳細については、「Grant User Permissions for DynamoDB Auto Scaling」を参照してください。
Auto ScalingにはAuto Scalingポリシーを有効または無効にする機能を含むCLIとAPIの完全なサポートがあります。トラフィックに予測可能な時間的なスパイクがある場合(ゲームなどであれば決まった時間に発生するイベントなど)は、プログラムによって自動スケーリングポリシーを無効にし、一定期間高いスループットをプロビジョニングしてから、後でAuto Scalingを再度有効にすることができます。
DynamoDBの制限ページに記載されているように、プロビジョニングされた容量は、必要に応じて必要なだけ増やすことができます(アカウントごとに設定されている上限内にて)。各テーブルまたはグローバルセカンダリインデックスごとに1日に最大9回まで容量を減らすことができます。(その為、あまり頻繁に容量を下げる設定にしてしまうとこの回数を使い切ってしまいその後下げる事が一時的に出来なくなる可能性があります。)
実際に実行された容量は通常のDynamoDBの価格が掛かります。さらに節約するためにDynamoDBのリザーブドキャパシティユニットを購入することもできます。
今すぐ利用可能
この機能は現在すべての地域で利用可能で、今すぐ使用することができます!
— Jeff;
(この記事はSA 成田が翻訳しました。原文はこちら)