Amazon Web Services ブログ
新規 – AWS Deep Learning コンテナ
深層学習について学び、アプリケーションでそれを使う方法をできるだけ簡単にしたいと考えています。大規模なデータセットを取り込み、既存のモデルをトレーニングし、新しいモデルを構築して推論を実行する方法を知っていれば、将来のための十分な準備が整います。
新しい深層学習コンテナ
今日は、新しい AWS Deep Learning コンテナについて説明します。こうした Docker イメージは、他のフレームワークと共に、TensorFlow または Apache MXNet を使用した深層学習トレーニングや推論に使用する準備ができています。顧客が Amazon EKS や ECS を使用して TensorFlow ワークロードをクラウドにデプロイしていることを説明し、そうしたタスクをできる限り単純かつ簡単にすることを当社に依頼したのを受けて、これらのコンテナを構築しました。その間、トレーニング時間の短縮と推論性能の向上を目的として、AWS で使用するイメージを最適化しました。
イメージは事前設定および検証済みなので、Amazon ECS、Amazon Elastic Container Service for Kubernetes、Amazon Elastic Compute Cloud (EC2) でのカスタム環境とワークフローの設定が数分で可能であり、深層学習に集中できます。 AWS Marketplace や Elastic Container Registry で見つけて、無料で使用することができます。イメージはそのまま使用することもできますし、追加のライブラリーまたはパッケージを使用してカスタマイズすることもできます。
次の要素に基づく名前の複数の深層学習コンテナを使用できます (すべての組み合わせが使用できるわけではありません)。
- フレームワーク – TensorFlow または MXNet。
- モード – トレーニングまたは推論。単一ノードまたはマルチノードのクラスターでトレーニングをすることができます。
- 環境 – CPU または GPU。
- Python バージョン – 2.7 または 3.6。
- 分散トレーニング – Horovod フレームワークを使用。
- オペレーティングシステム – Ubuntu 16.04。
深層学習コンテナの使用
AWS Deep Learning コンテナを使用するために、p2.8xlarge インスタンスを使用して Amazon ECS クラスターを作成します。
クラスターが実行されていることを確認し、ECS Container Agent が有効であることを確認します。
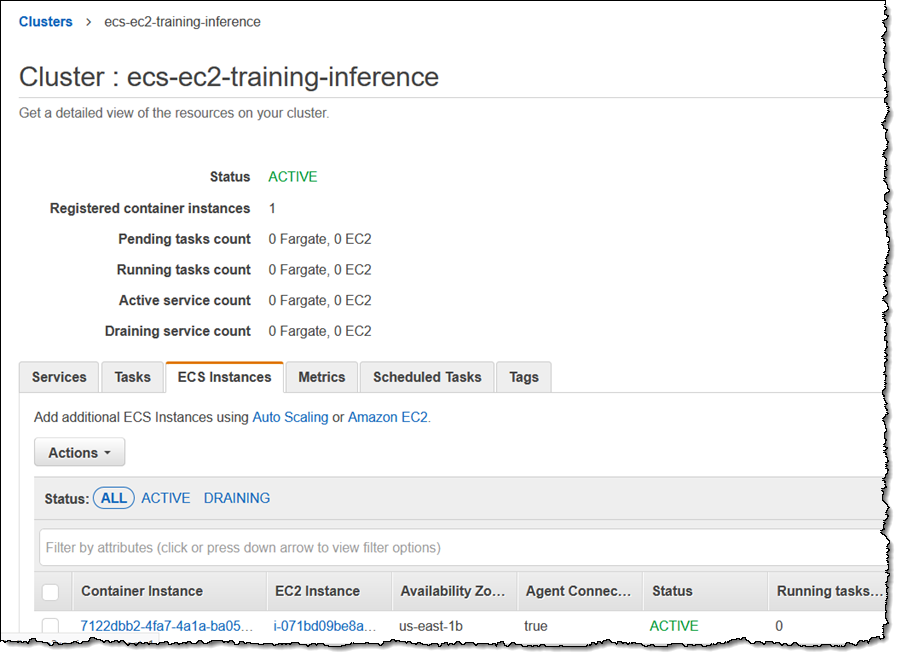
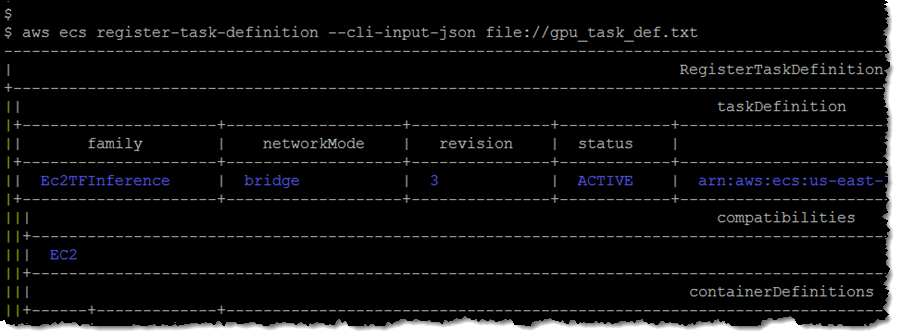
次に、テキストファイル (gpu_task_def.txt) でタスク定義を作成します。
タスク定義を登録してリビジョン番号 (3) を取得します。
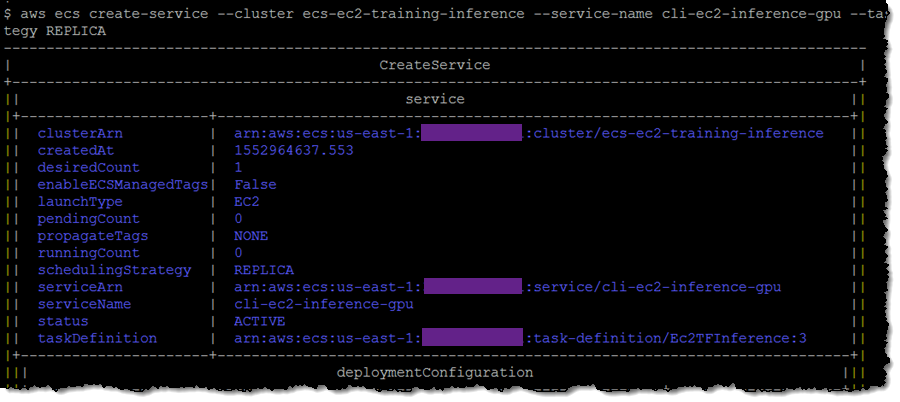
 次に、タスク定義とリビジョン番号を使ってサービスを作成します。
次に、タスク定義とリビジョン番号を使ってサービスを作成します。
コンソールを使用して、タスクに移動します。
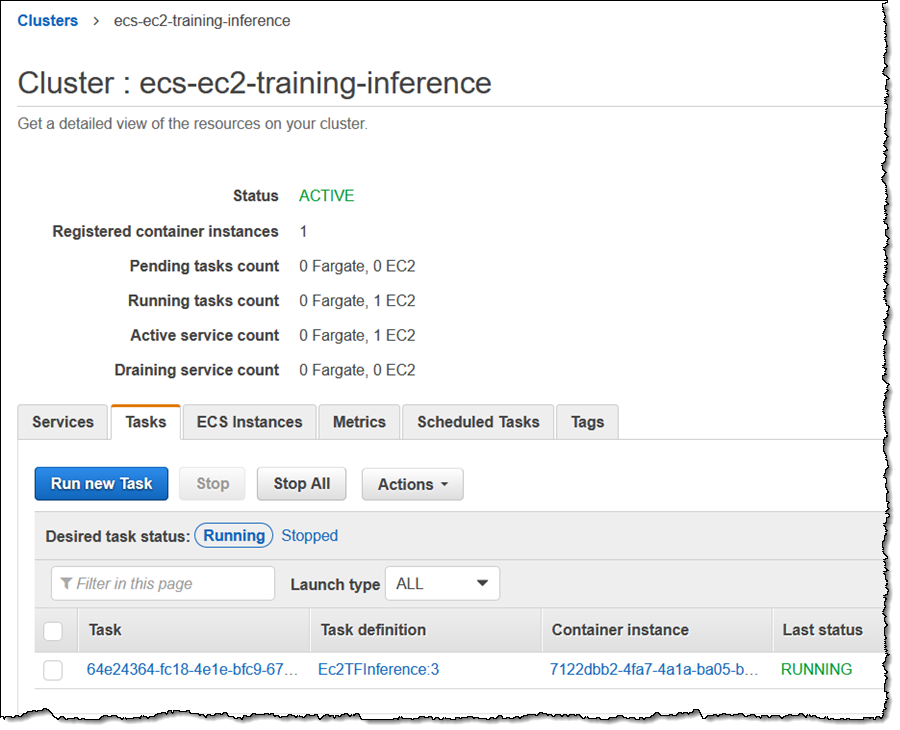
それから、ポート 8501 の外部バインディングを見つけます。
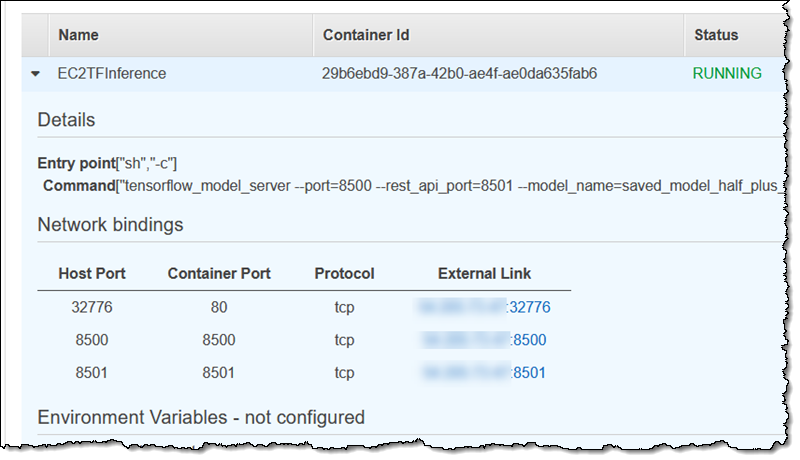
次に、3 つの推論を実行します (この特定のモデルは、a = 0.5 および b = 2 として、y = ax + b という関数でトレーニングされています)。
ご覧のとおり、入力が 1.0、2.0、5.0 の場合、推論は 2.5、3.0、4.5 の値を予測しました。これは本当に非常に単純な例ですが、新しい深層学習コンテナを使用して ECS で推論を実行するための事前トレーニング済みモデルの使用方法を示しています。また、トレーニング目的でモデルを起動し、トレーニングを実行してから、いくつかの推論を実行することもできます。
— Jeff;