Amazon Web Services ブログ

Agentic AI でサプライチェーン ロジスティクスを変革
本記事は 2025/10/10 に公開された “Transform Supply Chain Lo […]

AWS Weekly Roundup: Amazon Bedrock の Claude Sonnet 4.6、Kiro in GovCloud リージョンの Kiro、新しいエージェントプラグインなど (2026 年 2 月 23 日)
2026 年 2 月 16 日週、私のチームは米国サンノゼで開催された Developer Week で大勢の […]
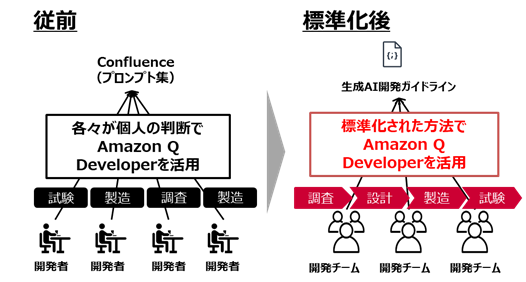
Amazon Q Developer 活用をプロジェクト全体へ拡げた取り組み
※ この投稿はお客様に寄稿いただいた記事です。 開発チームに生成AIアシスタントを導入しても、「どう使えばいい […]

週刊AWS – 2026/2/16週
Amazon EC2 がネスト仮想化をサポート、AWS Backup が AWS 上の SAP HANA に対する PrivateLink をサポート、Amazon DocumentDB 5.0 での長期サポート (LTS) の発表、AWS Glue 5.1 が大阪リージョンで利用可能、Claude Sonnet 4.6 が Amazon Bedrock で利用可能、Amazon Aurora DSQL が Kiro powers と AI エージェントスキルと統合、Amazon EC2 M8i-flex インスタンスが東京リージョンで利用可能、Amazon RDS for Oracle が Spatial パッチバンドルをサポートなど

アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
Amazon SageMaker Catalog を使用してデータメッシュパターンを実装する方法を説明します。既存のアプリケーションやデータリポジトリを変更せずに、Amazon SageMaker Unified Studio でデータをオンボード、公開、サブスクライブする手順を紹介します。

第 5 世代 AMD EPYC プロセッサを搭載した Amazon EC2 Hpc8a インスタンスの一般提供開始
2026 年 2 月 16 日、Amazon Elastic Compute Cloud (Amazon EC […]

カスタム Amazon Nova モデル用の Amazon SageMaker Inference の発表
AWS New Summit 2025 で Amazon SageMaker AI の Amazon Nova […]

週刊生成AI with AWS – 2026/2/16 週
今回の週刊生成AI with AWSでは、BMW Group や三菱電機、メック、東芝テックなど国内外の生成 AI 事例ブログに加え、開発者向けエージェント型 IDE「Kiro」の新機能やエンタープライズ対応、セキュリティに関する最新ブログ記事をまとめてご紹介します。 サービスアップデートでは、Amazon Bedrock の強化学習ファインチューニングによるオープンウェイトモデル対応や Claude Sonnet 4.6 の提供開始、Kiro の AWS GovCloud リージョン対応など、生成 AI 活用の選択肢を広げる注目のアップデートをお届けします。

新しい Amazon Aurora クラスターに対する保管時のデフォルト暗号化の使用
Amazon Aurora では、すべての新しいデータベースクラスターに対して AWS 所有キーによる保管時の暗号化がデフォルトで有効になりました。追加コストや設定作業なしでセキュリティの強化とコンプライアンスの簡素化を実現できます。

Microcredentials であなたのスキルをもっとアピールしましょう
AWS 認定を取得したが、もっと自分のスキルをアピールしたい!全冠の次の目標が欲しい!そんな方に朗報です。Microcredentials は実践的なスキルを証明する新しい手法として、2025 年 11 月より AWS Skill Builder のサブスクリプションコンテンツとして利用が可能になりました。Microcredentials は AWS 認定だけでは証明することが難しい、特定分野におけるスキルの深度を証明できます。ぜひ AWS 認定と合わせて取得いただき、AWS 認定 × Microcredentials の新しいスキル証明を体感ください。