Amazon Web Services ブログ

AI で強化された脅威アクターによる FortiGate デバイスへの大規模な不正アクセス
Amazon Threat Intelligence が観測した、AI で強化された脅威アクターによる FortiGate デバイスへの大規模な不正アクセスキャンペーンについて解説します。ロシア語話者の脅威アクターが複数の商用生成 AI サービスを活用し、55 か国以上、600 台超の FortiGate デバイスの認証情報を悪用して内部ネットワークに侵入し、AI が生成した攻撃計画やツールを駆使して Active Directory の侵害やバックアップインフラストラクチャの標的化を行いました。攻撃手法の詳細と、組織が講じるべき防御策および AWS 固有の推奨事項を紹介します。

Integral Ad Science における Amazon OpenSearch Service を使った日次 1 億件超のドキュメント処理の紹介
Integral Ad Science (IAS) が Amazon OpenSearch Service を活用し、日次 1 億件以上のドキュメントを処理するスケーラブルな SaaS 型 ML プラットフォームを構築した事例を紹介します。ベクトル検索の最適化により、複雑な検索オペレーションで 40〜55% のパフォーマンス向上を達成しました。

エージェンティック・クラウドモダナイゼーション: AWS MCP と Kiro によるモダナイゼーションの加速
今日の急速に進化するテクノロジー環境において、組織はレガシーシステムのモダナイゼーションを進めながら、運用上の優秀性を維持し、コストを管理するという大きなプレッシャーに直面しています。従来のクラウドモダナイゼーションでは、数週間にわたる手作業での調査と広範なドキュメント作成が必要でした。しかし、AWS の Kiro や Cline のような AI を活用した開発アシスタントが、公式の AWS MCP serversと統合されて登場したことで、手動で時間のかかっていたプロセスを自動化し、実装期間を数週間から数日に短縮します。

Kiro のエンタープライズ ID 連携と使用状況メトリクス
Kiro はエンタープライズ向けに外部 ID プロバイダー(Okta、Microsoft Entra ID)のサポートとユーザーレベルのアクティビティメトリクスを提供します。既存の ID インフラストラクチャに直接接続し、SSO ポリシーや MFA を活用可能に。管理者は日次集計使用状況データでチームのツール利用状況を可視化でき、AI がエンジニアリングにもたらす効率向上を測定できます。

小売業界の未来を切り拓く:東芝テックが AWSの AI エージェントを活用した店舗運営支援ソリューションを開発
はじめに 東芝テック株式会社は、流通・小売業界やさまざまなワークプレイスに向けたソリューションを開発、提供して […]

Claude Sonnet 4.6 が Kiro で利用可能になりました
本日より Kiro IDE と CLI で Claude Sonnet 4.6 が利用可能になりました。Sonnet 4.6 は Opus 4.6 の知能に近づきながらトークン効率が高く、複雑なコードベースでの機能構築、リファクタリング、デバッグなどの反復的なワークフローを高品質に処理します。マルチモデルパイプラインでリードエージェントとサブエージェントの両方の役割を果たし、エージェント作業に最適化されています。Pro、Pro+、Power のお客様に AWS の 2 リージョンで提供され、1.3 倍のクレジット乗数でコスト効率も優れています。
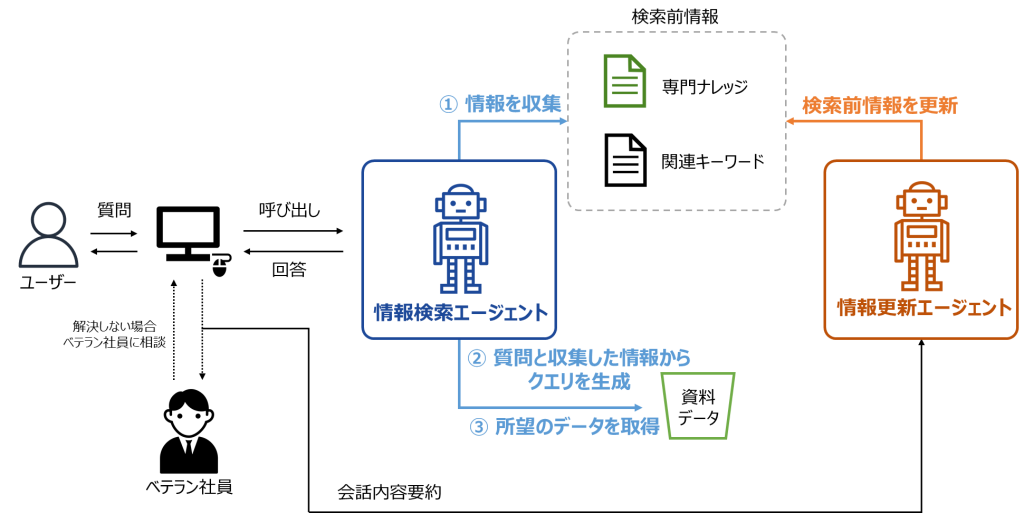
メック株式会社の事例:Amazon Bedrock AgentCore で研究業務を効率化 – AI エージェントによる情報検索と更新の自動化
本ブログは、メック株式会社 様と Amazon Web Services Japan が共同で執筆いたしました […]

バグ修正と既存アプリの上に構築するための新しい Spec タイプ
Kiro の Specs に 2 つの新しいタイプが追加されました。既存アプリやブラウンフィールドプロジェクトで技術アーキテクチャがすでに決まっている場合に設計ドキュメントから始められる「デザインファーストワークフロー」と、現在の振る舞い・期待される振る舞い・変更されない振る舞いの 3 セクションで構造化し、プロパティベーステストでリグレッションを防ぎながら外科的にバグを修正できる「バグ修正 Spec」です。従来の要件ファーストに加え、開発者の思考の出発点に合わせた柔軟なワークフローが選択できるようになりました。

「導入しても使われない」を解決する ― 三菱電機 電力ICTセンターが Kiro と GitLab で実現した開発ワークフローの標準化
本ブログは、三菱電機株式会社 電力システム製作所 電力ICTセンター 小森様と、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト稲田、GitLab 合同会社 ソリューションアーキテクトの小松原様の共著です。三菱電機 電力ICTセンターにおける Kiro と GitLab を組み合わせたソフトウェア開発効率化の取り組みについてご紹介します。
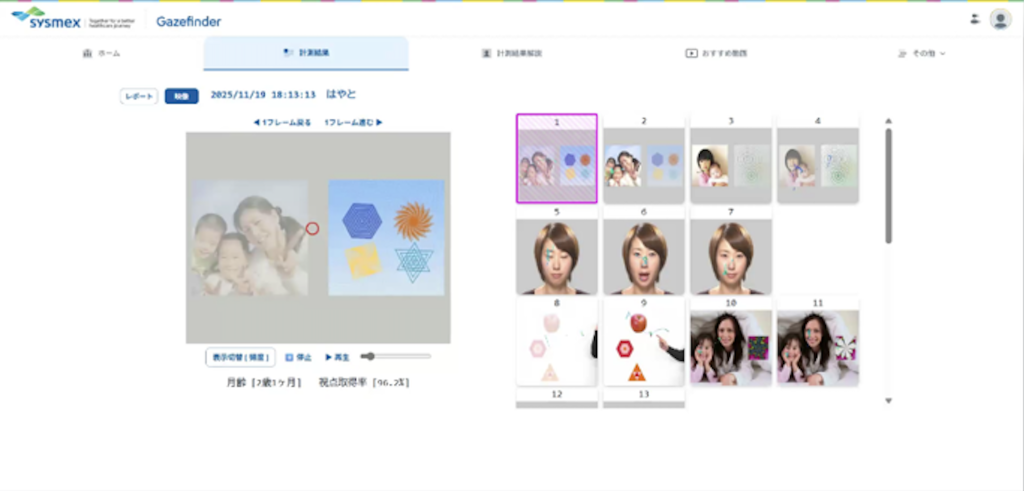
シスメックス株式会社:子どもの個性や社会性を理解するための視線計測アプリ「Gazefinder」を支えるAWSアーキテクチャ
このブログは、シスメックス株式会社 次世代医療事業開発室と、ディピューラメディカルソリューションズ株式会社、ア […]