Amazon Web Services ブログ
Amazon SageMaker による検索エンジンの強化
この記事は、Ibotta 社の機械学習マネージャー、Evan Harris 氏によるゲスト投稿です。Ibotta 社によると、「Ibotta は、単一のスマートフォンアプリを通じて消費者が簡単に普段の買い物に対するキャッシュバックを獲得できるようにすることでショッピング体験を変革しており、食料品、電子機器、衣料、ギフト、家庭および事務用品、レストランでの食事などに対する特典を提供するために、一流のブランドおよび小売業者と提携してる」とのことです。
急成長するミドルステージの企業間における技術面での隔たりは、ユニークな課題を生みがちです。 このような企業の多くで重要視されるのは、高品質アプリケーションを迅速かつ効率的に構築することです。
普段の買い物に対するキャッシュバックを何百万ものユーザーに提供するモバイルアプリ、Ibotta の機械学習 (ML) チームは、このトピックについてかなりの考察と実験を行ってきました。 今日は、Amazon SageMaker を使った検索など、コア機能を実現するために当社が AWS を活用する方法についてお話したいと思います。
この記事では、Ibotta の検索エンジンのアーキテクチャ、そしてリアルタイムの ML を当社のモバイルアプリケーションの検索経験に統合するために Amazon SageMaker とその他の AWS サービスを使用する方法について説明します。この記事が、皆さんの組織の規模に関わらず、組織内における同じような課題に対する実行可能なソリューションを探す期間を短縮するために役立てば幸いです。
包括的で使いやすい検索フローを備える能率化されたモバイルアプリ経験を生み出すことは、私たちのビジネスにとって必要不可欠です。買い物前にお買い得情報を探すお客様は、価値ある情報をすばやく見つける必要があり、そうでなければあきらめてしまう傾向があります。
検索関連性エンジニア、ML エンジニア、設計者、およびモバイル開発者の専属チームを持つ当社では、検索関連性に対する新しくクリエイティブな改善を迅速に開発し、テストするために出来る限り多くの最新テクノロジーを使用しています。Ibotta はデータ主導のインテリジェンスを検索エンジンに投入するための ML の使用を優先しており、これは私たちを従来の情報取得手法を超えたレベルに押し進めます。
基礎を成す検索インフラストラクチャ
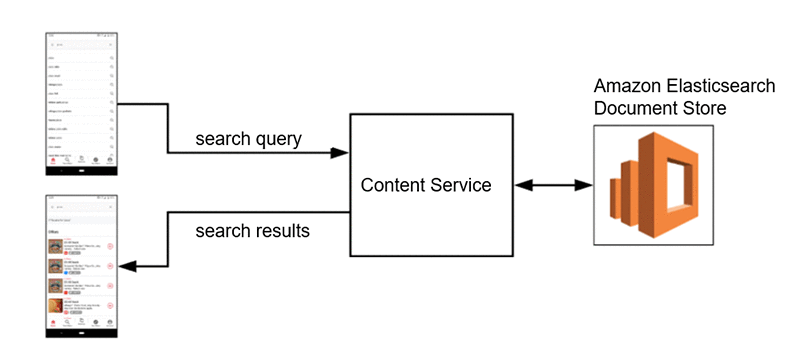
Ibotta での検索のコアインフラストラクチャは、アプリの幅広いマイクロサービスを土台としています。インデックス化されたドキュメントは Amazon Elasticsearch Service に保存され、これにはモバイルクライアントが任意の時点で利用できるコンテンツのすべてが収められています。リクエストに応じて社内のコンテンツサービスがこのドキュメントストアと通信し、リクエストを行っているユーザーが利用できるコンテンツのみが返されることを確実にするための、追加のルールベースのフィルタリング機能を提供します。
このコンテンツサービスは入力検索クエリを受け取り、他の文脈上の考慮事項を計算に入れながら、関連するコンテンツで応答することができます。コンテンツサービスは典型的な lucene スタイルの検索関連性手法を使用して Elasticsearch ドキュメントストア内の適切なコンテンツを取得します。
ML で強化された検索インフラストラクチャ
基礎となる検索インフラストラクチャには、大きな改善の余地があります。Ibotta の検索問題領域には、特にコンテンツに関してユニークな課題があり、ある週に特定ブランドのための特典がアプリ内にあっても、別の週にはその特典がなくなっているという場合があります。これは、私たちが提携する小売業者によるものです。小売業者は、限定された期間だけアイテムを宣伝したいということが多々あるからです。
これに加えて、当社のアプリでは全く利用できないブランドと製品のカテゴリもあります。これは、当社がまだこれらの小売業者と連携していないからですが、私たちは、ユーザーの検索クエリがアプリ内のコンテンツに完全に一致しない場合でも、それらのユーザーに関連するコンテンツを表示したいと考えています。例えば、取り扱っていないブランドのコーヒーに対する検索は、重要な属性 (フレーバー、サイズ、価格など) 全体に一致する他のコーヒーブランドを返すべきです。
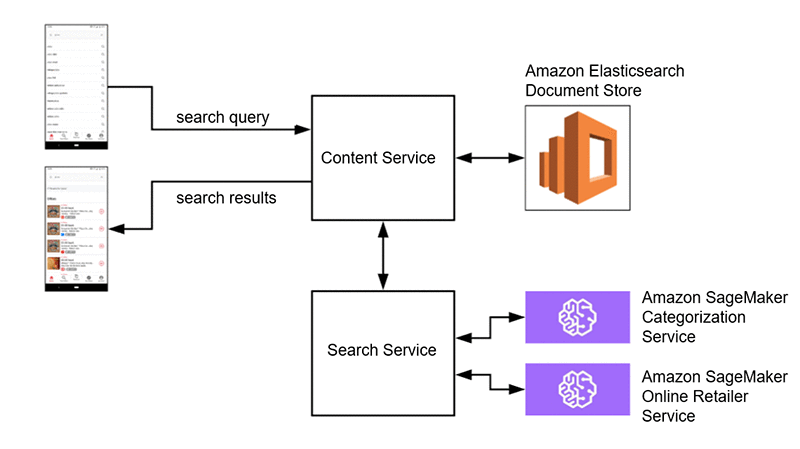
これに対するソリューションがクエリ拡大です。これは、データストアをクエリする前に、ユーザーの検索クエリにコンテンツを追加する一般的な検索手法です。ある状況では、リアルタイムで検索クエリをカテゴリ別に分類することによって価値を付加し、コンテンツ取得とソートアルゴリズムを強化します。別の状況では、カテゴリに分類した後、予測されたカテゴリを専門とするオンライン小売業者を検索してソートし、それらを提案としてユーザーに返します。
Ibotta では、これらのオンデマンドのカテゴリ推論をリアルタイムで行うために Amazon SageMaker を使用しており、簡単にモデルを訓練して、それらを完全マネージド型の REST API としてデプロイすることが可能で、社内マイクロサービスはこれらに対してリクエストを行うことができます。リクエストと応答の例は、以下のコードのようになります。
| Request | Response |
当社では、Amazon SageMaker に組み込まれたアルゴリズムである BlazingText を使用しています。教師ありバージョンの BlazingText は、強力で柔軟性があり、簡単に使用できるテキスト分類モデルです。追加設定を行うことなく、スケーラブルな分散型トレーニング、ハイパーパラメータのベイズ最適化、およびリアルタイムの推論エンドポイントデプロイメントを使用できます。Ibotta では、他のユースケースに対する独自のテキスト分類モデルのトレーニングとデプロイメントにかなりの時間をかけてきました。組み込みの Amazon SageMaker モデル、およびマネージド型のトレーニングとデプロイメントサービスを使用する上で、私たちは好ましい点を多数見つけました。
以下の図は、1 つの視点から見た、当社の ML 強化された検索サービスアーキテクチャの図です。お分かりいただけるように、先ほど説明したクエリと取得メカニズム (ここにも図示されています) は SageMaker によって補完されており、SageMaker は 2 つの明確な付加価値を提供します。1 つ目は SageMaker が検索クエリを分類してより多くの関連結果を挙げることを可能にするという点で、2 つ目は SageMaker がクエリに関連する製品を持つオンライン小売業者を提供することを可能にするという点です。
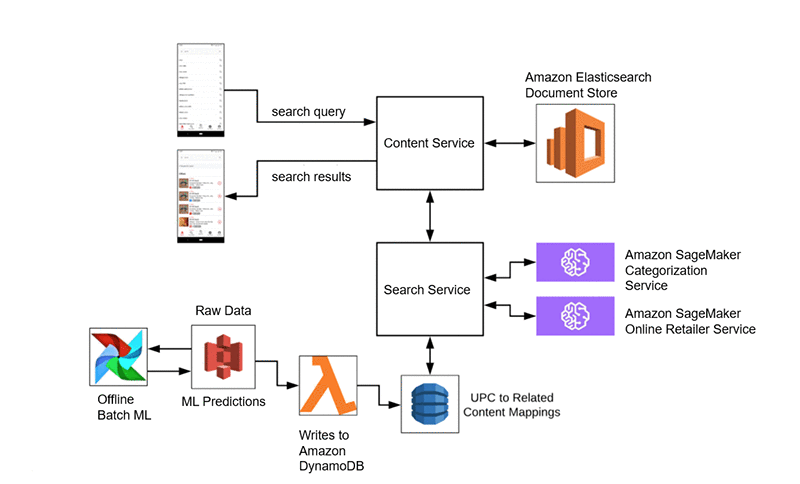
さらなる ML 付加価値に、Ibotta の UPC バーコードスキャン機能があります。ユーザーは、このアプリを使って消費者製品のバーコードをスキャンできます。その UPC の購入が特典条件を満たす場合、Ibotta は完全な一致結果を返します。完全な一致結果がない場合は、教師なしのテキスト類似性アルゴリズムを使って、ユーザーに提案する関連特典を探します。当社のアプリでキャッシュバックを獲得できるならば、ユーザーはスキャンした製品の代替品を検討するかもしれません。
この UPC 機能では、類似する提案が存在する可能性がある UPC の領域を前もって把握しておきます。予測はオフラインで実行し、オンラインデータストアに記述することができます。当社のサービスは、そこで低遅延のリクエストをリアルタイムで実行できます。私たちは、このプロセスのために Amazon S3、AWS Lambda、Apache Airflow、および Amazon DynamoDB の組み合わせを使用しています。以下の図にある当社のアーキテクチャにはこれらが追加されており、ここでは UPC 入力が実行される検索クエリになります。
すると、検索経験を向上させるために、必要に応じてオンデマンドモデルとバッチ ML モデルが組み合わされます。幅広いサービスツールセットが装備されているため、ジョブには適切なツールを選択できます。当社の本番環境は、オフラインデータストレージ、オンラインデータストレージ、データ転送、および ML の各サービスを含む完全マネージド型の AWS サービスで構成されています。
スケーリングを想定した構築
テクノロジストがスケーリングを想定した構築について話すとき、大抵の場合は、おそらくストレージ用の Amazon S3、またはコンピューティング用のマネージド Kubernetes といった水平的なスケーラビリティについて言及しています。これらのサービスを使用すると、水平スケーリングは実質上無限になりますが、
個々のサービスやコードベースを必要以上に複雑にすることなく、サービスに新しい機能を追加する能力という観点からスケーラビリティについて語ることも有益です。AWS 上に構築されたマイクロサービスを使用することにより、私たちは既存のエコシステムに対するリスクを最小限に抑えながら、機能を追加したりアップグレードしたりすることができます。
また、オーナーシップをコンパートメント化することもでき、特に ML エンジニアが彼ら自身のサービスを全面的に所有することを可能にします。API コントラクトが変更されない限り、ML チームは、依存サービスの所有者とのコントラクトに関係なくチームのモデルでイテレーションを行うことができます。Amazon SageMaker は、基本的な Python スキルと ML 知識を持つ開発者が、当社のスタックに直接統合される実稼働マイクロサービスをサポートすることを可能にします。
これは、部門間での大幅な取り組みを必要としない、検索サービスアーキテクチャの今後のイレテ―ションにつながります。
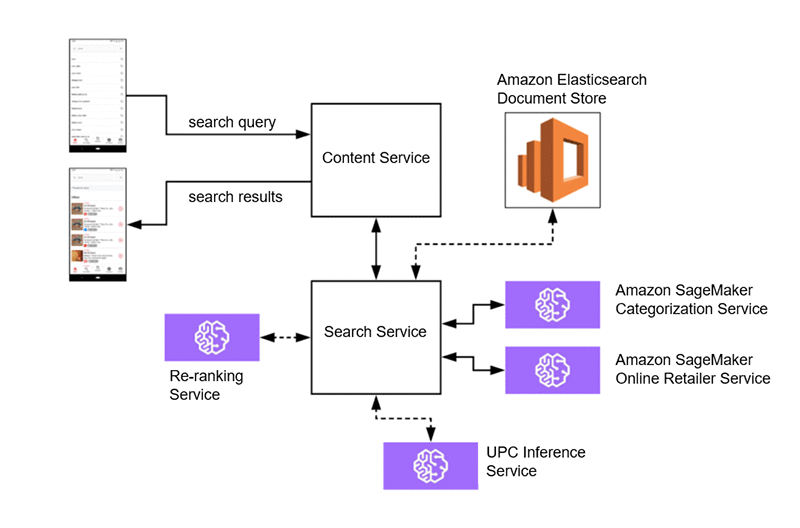
このセットアップでは、UPC からのより高度な特徴抽出と推論を行う能力を持つ Amazon SageMaker サービスに UPC 予測パイプラインを移行して、関連コンテンツを予測するとよいかもしれません。また、さらに特化された検索指向のドキュメントインデックスのために、Elasticsearch ドキュメントストアを検索サービスのすぐ後ろに移行させることもできます。その結果、ルールベースのユーザーレベルフィルタリングについてコンテンツサービスのみに依存することになります。
最後に、既存の ML ユースケースにランク学習があります。検索サービスがコンテンツの候補一式を取得した後、Ibotta は Amazon SageMaker サービスを使用してコンテンツをリアルタイムで動的に再ランクできます。これには、コンテンツ、パーソナライズ化に加えて、トレンドと季節性に関する既知の特徴を考慮することができます。
AWS のおかげで、Ibotta には成功につながるアーキテクチャが存在します。プロジェクトの作業はシンプルな統合ポイントでコンパートメント化され、オーナーシップは単純明確です。ML チームは、当社のバックエンドプラットフォームに直接統合されるシンプルなサービスのすべてをマネージドインフラストラクチャ上で構築できます。
結論
Ibotta は、Airbnb、Etsy、Linkedin、Wayfair、および Pinterest などのテクノロジー関連の大手企業がどのように検索エンジンを運用するかを研究し、当社でも同じ手法を使用すべく努力を重ねています。これらの企業と比べて Ibotta のエンジニアリングチームがサイズ的にどれほど小さいかを考えることもよくありますが、AWS 上の独自のマイクロサービスというセットアップにより、Ibotta ではそれに似た経験を実現する資質が十分にあります。私たちが頼る AWS のサービスは、これらのサービスがなければあり得ない、または実装に途方もない時間がかかると思われる迅速なイテレーションとテストの実施を可能にしてくれます。推奨 AI/ML プロバイダー、そしてテクノロジースタックの土台として AWS を使用する Ibotta は、今後の展開に心を躍らせています。