Amazon Web Services ブログ
Amazon EMR で GPU インスタンスタイプを持つディープラーニングフレームワークを実行
AWS は Apache MXNet と Amazon EMR での新世代 GPU インスタンスタイプのサポートについて発表いたします。これにより、機械学習ワークフローおよびビッグデータ処理とともに分散ディープニューラルネットワークの実行が可能になります。さらに、GPU ハードウェアにより、EMR クラスター上でカスタムディープラーニングライブラリをインストールおよび実行できます。ディープラーニングフレームワークの使用を通じて、自動運転車から人工知能 (AI)、個人化されたヘルスケア、コンピュータビジョンまで、さまざまなユースケースに対応する新しいツールキットを入手できます。
Amazon EMR は、Apache Spark、Apache Hive、Presto、Apache HBase、Apache Flink などのフレームワークとともに、Amazon S3 で大量のデータを簡単かつ迅速に、コスト効率の高い方法で処理できるマネージド型 Hadoop フレームワークを提供します。ログの分析、ウェブインデックス作成、データ変換 (ETL)、財務分析、科学シミュレーション、リアルタイム処理、バイオインフォマティクスを含む、数多くのビッグデータのユースケースに低コストで対応し、確実かつ安全に処理できます。
EMR には、スケーラブルな機械学習ワークロードを実行可能にしてきた長い歴史があります。2013 年には、Apache Hadoop MapReduce を使用した分散型機械学習ワークロードの実行を支援するため、Apache Mahout のサポートが追加されました。2014 年には、お客様は Apache Spark を利用して (2015 年に公式サポートを追加)、Spark ML で利用できるさまざまなオープンソース機械学習ライブラリを使用して、スケーラブルな機械学習パイプラインを簡単に構築し始めました。
当社は過去 2 年間に、Jupyter ノートブックの簡単なインストールのための Apache Zeppelin ノートブックのサポート、およびデータサイエンティストが機械学習モデルを簡単かつ迅速に開発、トレーニングし、本番稼働に移行するための Apache Livy のサポートを追加しました。EMR の 1 秒あたりの請求と Amazon EC2 スポットインスタンスを使用した最大 80% のコスト削減により、機械学習パイプラインを大規模に、しかも低コストで簡単に実行できます。
本日より、Amazon EMR でのディープラーニングの実装が簡単になります。スケーラブルなディープラーニングフレームワークである Apache MXNet (0.12.0)、Amazon EC2 P3 および P2 インスタンス、必要な GPU ドライバがプリロードされた EC2 コンピューティング最適化 GPU インスタンスのサポートが追加されました。これにより、わずかなクリック操作で、分散トレーニング用の最新の GPU ハードウェアを使用して、迅速かつ簡単にスケーラブルで安全なクラスターを作成することができます。さらに、BigDL や CaffeOnSpark などのカスタムディープラーニングライブラリを、カスタム Amazon Linux AMI にプリロードするか、ブートストラップアクションを使用してクラスターをカスタマイズすることで、インストールおよび使用できます。さらに、EMR は間もなく別の人気の高いディープラーニングフレームワークである TensorFlow のサポートを追加します。
EMR では、ディープラーニングモデルの開発とトレーニングにより、開発のデータ調査フェーズおよび前処理フェーズの両方を簡単に組み合わせることができます。最初に、Apache Spark、Apache Hadoop、Apache Hive を含むさまざまなオープンソースのビッグデータフレームワークを簡単かつコスト効率の高い方法で使用して、S3 の大規模なデータセットを調査および処理できます。
2 番目に、MXNet および Spark を使用して、S3 またはオンクラスター HDFS に保存されている事前処理済みデータを使用したディープラーニングモデルの開発、トレーニング、実行に加えて、予測や推論を実行できます。お支払いは秒単位で、EC2 スポットインスタンスの上限価格を設定し、Auto Scaling を使用できます。その後、ワークロードが完了したら、クラスターをシャットダウンしてお支払いを停止することにより、実験および本番稼働のコストをさらに削減できます。
EMR コンソールでの数回のクリックで、Spark、MXNet、Ganglia モニタリング、および Zeppelin ノートブックにより、1~数千のノードを持つ EMR クラスターを迅速に作成できます。
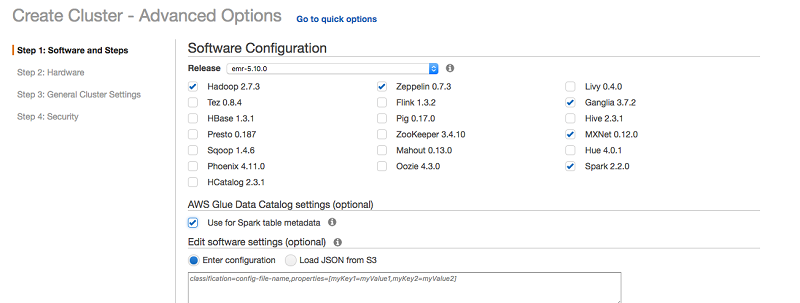
クラスターが起動したら、Zeppelin ノートブックを開き、Spark と MXNet でデータの調査およびモデルの構築を開始できます。

EMR では、以下のいずれの方法でも、アプリケーションを簡単にモニタリング、デバッグできます。
- EMR コンソールで詳細な Spark アプリケーション履歴を直接表示する
- Amazon CloudWatch メトリクスを使用する
- オンクラスターの Hadoop UI を表示する
- S3 にアプリケーションログを直接プッシュする
- リソース使用メトリクスに Ganglia を使用する
近日中に、MXNet および EMR 上のその他のフレームワークをディープラーニングのために大規模に活用する例とベストプラクティスに関する追加の投稿を公開予定です。使用開始の詳細については、Amazon EMR ドキュメントを参照してください。
今回のブログの投稿者について
 Jonathan Fritz は Amazon EMR のプリンシパルプロジェクトマネージャーです。チームの製品管理を統率し、大量のデータでの分析と機械学習を簡単にするべく取り組んでいます。余暇には、訪れたことがない街への旅行、ライブ音楽、アウトドアを楽しんでいます。
Jonathan Fritz は Amazon EMR のプリンシパルプロジェクトマネージャーです。チームの製品管理を統率し、大量のデータでの分析と機械学習を簡単にするべく取り組んでいます。余暇には、訪れたことがない街への旅行、ライブ音楽、アウトドアを楽しんでいます。