Amazon Web Services ブログ
SAP HANA システムレプリケーション – セカンダリインスタンスのメモリサイズ削減
はじめに
事業継続に不可欠なSAPシステムでは、計画的または非計画的な停止時にアプリケーションの可用性を最大化するために、入念に設計、テストされた高可用性およびディザスタリカバリ(HA/DR)フレームワークが必要です。SAP HANAは、ミッションクリティカルなワークロードをサポートするインメモリデータベースであり、障害から保護する必要のあるSAPシステムの重要なコンポーネントです。プライマリまたはアクティブなSAP HANAデータベースは、SAP HANAシステムレプリケーション(HSR)を使用してセカンダリインスタンスにレプリケートすることができます。SAP HSRは継続的にデータを複製し、プライマリインスタンスに障害が発生した場合でも、変更内容がセカンダリインスタンスに反映されるようにします。Amazon Web Services(AWS)では、セカンダリSAP HANAデータベースインスタンスは、同じリージョン(異なるアベイラビリティゾーン)内に配置することも、別のリージョンに配置することも可能です。
ニアゼロRTO(Recovery Time Objective)を実現するためには、プライマリとセカンダリのSAP HANAデータベース・インスタンスが同程度のメモリ容量とすることが必要です。しかし、より長いRTOを許容できるのであれば、セカンダリSAP HANAデータベースインスタンスのメモリ容量を削減して運用することも可能です。この場合、より小さなインスタンスサイズを選択するか、セカンダリの余剰メモリを利用して他のSAP HANAデータベースのワークロードを運用することでコストを大幅に削減することができます。
セカンダリのSAP HANAノードにおけるメモリ要件の低減は、SAP HANAカラムデータをメインメモリにロードしないようにセカンダリを構成することで実現しています。プライマリに昇格する前には再起動が必要となり、その際にはメモリへ全データをロードする時間も必要です。セカンダリホストの実際のメモリ要件は、SAP HANAシステムレプリケーション(HSR)の設定と本番データの変更率に大きく依存します。SAP HANAのカラムテーブルのロードを無効にしても、セカンダリホストのメモリ要求は実際の本番SAP HANAのメモリ使用量の60%を超えることがあります。セカンダリインスタンスのサイズが適切でない場合、メモリ不足によるクラッシュや回復性の低下を招く可能性があります。
このブログでは、セカンダリSAP HANAデータベースインスタンスのサイズを決め、メモリ使用量を削減しながら運用する方法について、複数の導入シナリオの例を挙げて詳しく説明します。
アーキテクチャ
AWSでメモリ使用量を削減したSAP HANAセカンダリデータベースを展開するには、2つの一般的なアーキテクチャがあります。このブログでは、「スモールセカンダリ」と「シェアードセカンダリ」という言葉でこれらを区別しています。スモールセカンダリとは、インフラのサイズをプライマリよりも小さくし、テイクオーバー時にサイズを変更するものです。ブログ「Rapidly recovery mission-critical systems in a disaster」のように、これをPilot Light DRと呼ぶこともあります。共有セカンダリとは、未使用のメモリを非本番または身代わり用インスタンスが使用する場合です。SLESのドキュメントでは、これを「コスト最適化シナリオ」と呼んでいます。
これらのシナリオのいずれにおいても、セカンダリHANAデータベースではカラムテーブルのプリロードを無効にします。この変更を実行するための具体的な構成は、SAP HANAデータベースのパラメータpreload_column_tablesをfalseに設定することです。このインスタンスをプライマリとして昇格させる前に、この構成を「true」に変更する必要があります。テイクオーバー後にSAP HANAデータベースがSQL接続用にオープンになる前にカラムテーブルをロードするために必要なタスクと時間を考えると、これらのシナリオは高可用性(HA)ソリューションよりもディザスタリカバリ(DR)に適しています。
スモールセカンダリ
次の図は、同じリージョン内の別のAmazon Web Services(AWS)アベイラビリティーゾーンにスモールセカンダリを展開した場合を示しています。ただし、このような展開は、複数のAWSリージョンにまたがって行うことも可能です。AWSリージョン間でレプリケーションを行う場合、レイテンシーが増加するため、HSRの推奨レプリケーションモードは非同期となります。

共有セカンダリ
共有セカンダリの一般的な使用例は、アクティブな品質保証(QAS)インスタンスとセカンダリHANAデータベースインスタンスを同じホスト上で運用することで、MCOS(Multiple Components One System)とも呼ばれます。この設定では、追加のインスタンスを運用するための追加のストレージが必要になります。テイクオーバー時には、優先度の低いインスタンス(QAS)をシャットダウンして、ホストのリソースを本番ワークロードに利用できるようにすることができます。

どちらのシナリオでも、セカンダリHANAデータベースインスタンスの構成はpreload_column_tables = falseに設定されています。このパラメータのデフォルト値は「true」で、メモリを削減して動作させるためには、セカンダリインスタンス上で明示的に変更する必要があります。この変更は、ファイルパス(/hana/shared/<SID>/global/hdb/custom/config)にあるHANAデータベース構成ファイル(global.ini)で行います。
SAP HANA システムレプリケーションのオペレーションモード
SAP HANAシステムレプリケーション(HSR)では、セカンダリシステムを構築するために、logreplayとdelta_datashippingの2つのオペレーションモードをサポートしています。logreplayとdelta_datashippingのオペレーションモードを比較すると、以下のようになります。
| # | 項目 | オペレーションモード
|
|
| logreplay | delta_datashipping | ||
| 1. | 動作方法 | ログはセカンダリシステムに転送され、継続的に適用される | 差分データは、プライマリからセカンダリへ不定期に送信される(デフォルトは10分)。ログは転送されるだけで、テイクオーバーされるまで適用されない |
| 2. | リカバリ時間 | 障害が発生するまでログが継続して適用されるため、テイクオーバーは短時間 | テイクオーバー時間は比較的に長い |
| 3. | Data transfer needs | ログのみが転送されるため、データ転送量は比較的少ない | 差分データとログの両方を転送するためデータ転送量が多い |
| 4. | Network bandwidth | データ転送量が減少するため、サイト間の帯域幅要求は少ない | サイト間の帯域幅要求は高い |
| 5. | Memory footprint on DR instance | デルタマージの処理速度を上げるためにカラムストアをロードする必要があり、要求されるメモリ量が多い | カラムプリロードを無効にすると、カラムストアがメインメモリにロードされないため、要求されるメモリ量が大幅に少なくなる |
| 6. | Multi-tier replication | サポート | サポート |
| 7. | Multi-target replication | サポート | サポート外 |
| 8. | Secondary time travel | サポート | サポート外 |
3ティアレプリケーションでは、オペレーションモードの混在はサポートされていないことに注意が必要です。例えば、プライマリとセカンダリのSAP HANAデータベースインスタンスがHSRにlogreplayを使用するように設定されている場合、delta_datashippingオペレーションモードはセカンダリと3次システム間では使用できず、その逆も同様です。
カラムプリロードの無効化に関するSAPのガイダンス
セカンダリホストでの実際のメモリ使用量は、HSRのオペレーションモードの設定と、カラムテーブルのプリロード設定に依存します。そのため、HSRの設定において、異なるオペレーションモードのサイジング要件を理解することが重要です。以下の図は、SAP Note : 1999880 – FAQ: SAP HANA System Replication から抜粋したものです。(要SAPサポートポータルログイン)

上記のガイダンスによると、プリロードをオフにした場合でも、オペレーションモード「logreplay」の最小必要メモリには、変更のあるテーブルのカラムストアのメモリサイズも考慮されています。目安としては、現在の評価日から過去30日間にデータが変更されたカラムストアテーブルのサイズを考慮します。
SAP Note 1969700 – SQL Statement Collection for SAP HANAでは、SAP HANAデータベースの様々な管理面やパフォーマンス面の分析に使用できるSQLスクリプトのコレクションを提供しています。このスクリプト集にある「HANA_Tables_ColumnStore_Columns_LastTouchTime」というスクリプトは、若干の変更を加えることでこれらのテーブルを収容するために必要な最小メモリの概算を示すことができます。このスクリプトの正確な実行手順については、このブログの最後にある「追加情報」のセクションを参照してください。
以下のセクションでは、共有セカンダリシナリオで展開した場合のサイジングを評価する方法の詳細を例示します。図には示されていませんが、同じホスト上で2つ目のSAP HANAデータベースインスタンス(QASなど)を実行するという追加の考慮事項がない限り、同様のサイジング例はスモールセカンダリシナリオにも適用できます。
オプション1 – HSR、オペレーションモード:logreplay
次の例では、プライマリおよびセカンダリのプロダクションSAP HANAデータベースインスタンスは、2台の9TBハイメモリインスタンスに配置されています。セカンダリのインスタンスホストは、QAS(Quality Assurance)HANAデータベースインスタンスもホストしています。これらのインスタンスを展開するためには、3つのHANAデータベースインスタンス(PRD-Primary、PRD-Secondary、QAS)すべてのglobal_allocation_limitを評価する必要があります。次のセクションでは、これらの値を算出する方法を説明します。

以降、Global Allocation Limitを「GAL」と表記します。
- プライマリインスタンスのGAL
この例では、プライマリインスタンスに global_allocation_limit が設定されていません (デフォルト値は0、単位は MB)。デフォルト値では、データベースが使用できる物理メモリの量は制限されません。ただし、SAP Note 1681092 – Multiple SAP HANA systems (SIDs) on the same underlying server(s) によると、オペレーティングシステムによるHANAデータベースへの最大割り当ては、ホスト上で利用可能な最初の64GBの物理メモリの90%と残りの物理メモリの97%というルールに従います。
- セカンダリインスタンスのGAL
SAPのガイダンスによると、preload=off、logreplayオペレーションモードのセカンダリHANAデータベースインスタンスの最小メモリ要件は、「行ストアサイズ+変更のあるテーブルの列ストアメモリサイズ+50GB」となっています。例として、プライマリインスタンスでSQLスクリプト「HANA_Tables_ColumnStore_Columns_LastTouchTime」を実行したところ、過去30日間に変更があったカラムテーブルが3077GBと認識されました。このスクリプトを実行する詳細な手順については、このブログの「追加情報」セクションを参照してください。

同様に、SAP Note 1969700 – SQL Statement Collection for SAP HANAに掲載されているSQLスクリプト「HANA_Memory_Overview」を使って、「Row store」に必要なメモリ容量を求めることができます。以下の評価では、例として153GBの値を考慮しています。
注:この値は、最低限のサイジングの目安となるものです。カラムストアテーブルの変更が急増した場合に備えて、この値の10~20%の余裕を追加で確保することをお勧めします。
同様に、DRサイトで稼働する2つ目のHANAデータベースインスタンス(QAS)にもglobal_allocation_limit(GAL)を設定する必要があります。SAP Note 1681092 – Multiple SAP HANA systems (SIDs) on the same underlying server(s) によると、特定のホスト上のすべてのHANAデータベースの割り当て制限の合計は、ホスト上で利用可能な最初の64GBの物理メモリの90%と残りの物理メモリの97%を超えてはなりません。
この指針を9 TiB(9896 GB)のハイメモリインスタンスの例に適用すると以下のようになる。
すべてのHANAデータベース・インスタンスで利用可能なメモリの合計は9595GBであり、ハイメモリインスタンスで利用可能な物理メモリの合計は9TiB(9896GB)です。HANA DRインスタンスのメモリサイジングは3280GBとなっているため、残りのサイズはQASインスタンスの最大割り当て可能メモリとなります。
オプション2 – オペレーションモード:delta_datashippingのHSR
このセクションでは、「delta_datashipping」オペレーションモードで導入されたHANAシステムレプリケーションの概要と、個々のインスタンスのメモリ・サイジングを評価する手順を説明します。

- セカンダリインスタンスのGAL
SAPのガイダンスによると、preload=off、delta_datashippingオペレーションモードのセカンダリHANAデータベースインスタンスの最小メモリ要件は以下の通りです。このガイダンスを私たちの例のシナリオに適用して、DR用のGALを導き出すと次のようになります。
このガイダンスをシナリオ例に適用してDRのGALを導出すると次のようになります。
すべてのHANAデータベース・インスタンスの利用可能なメモリの合計は9595GB、ベアメタル・インスタンスの利用可能な物理メモリの合計は9TiB(9896GB)です。前のステップで、セカンダリHANAデータベース・インスタンスのメモリ・サイジングは173GBと導き出され、ホスト上の残りのサイズはQASインスタンスに割り当て可能な最大メモリとすることができます。
結論
このブログでは、メモリ使用量を削減したセカンダリHANAデータベースインスタンスを導入しても、logreplay オペレーションモードではコスト削減が実現しないことを紹介しました。これは、セカンダリHANAデータベースのメインメモリにロードされるカラムストアのメモリ要求が高くなるためで、カラムテーブルのプリロード設定に関係なく発生します。この動作は、継続的なlogreplay のために設計されています。さらに、プライマリでのカラムストアのデータ増加を常に監視し、セカンダリでのメモリ不足の問題を回避するために、セカンダリでのメモリ割り当てを調整する必要があります。delta_datashippingオペレーションモードは、セカンダリHANAデータベースインスタンス上のカラムテーブルのプリロードを無効にすることで、logreplay と比較してより良いコスト削減を可能にします。しかし、この選択には制限があり、復旧時間が長くなったり、レプリケーションサイト間のネットワーク帯域幅への要求が高くなったりします。
delta_datashippingを選択するには、このブログで説明されているように、コスト面とこの運用モードのその他の制限との間でトレードオフが必要です。RTO要件が緩和され、レプリケーションサイト間のネットワーク帯域幅が広くなれば、「logreplay 」の使用を促進することができます。また、データベースインスタンスが大きくなれば、コスト削減の可能性も高くなります。これは、セカンダリのメモリ要件は、小さいデータベースインスタンスであっても、行ストアメモリとバッファの必要性が最小限であるためです。特定のオペレーションモードの選択に影響を与える様々な要因と、delta_datashippingオプションによるコスト削減の可能性との関連性を以下の図に示します。これらの要因は互いに独立しており、それぞれが「delta_datashipping」を使用する能力とそれによるコストメリットに影響を与えます。
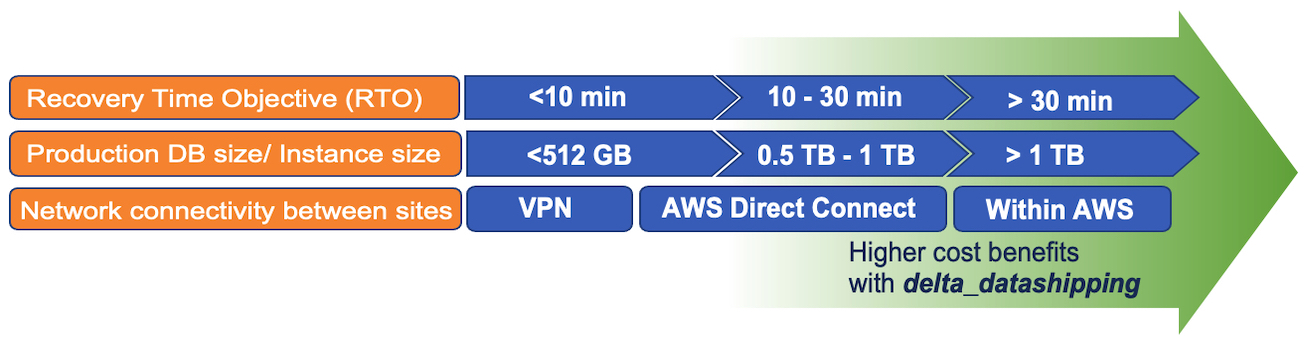
また、セカンダリのメモリ要件の計算と、それに続くglobal_allocation_limitの設定は、反復的なプロセスであることを理解することも重要です。本番データベースのサイズが大きくなると、最終的にはセカンダリインスタンスのデルタマージ用のカラムストアの需要も大きくなります。したがって、セカンダリのメモリ割り当てを定期的に監視する必要があります。また、大量のデータをロードした後や、稼動開始後、SAPシステム固有のライフサイクルイベントの後にも監視する必要があります。
追加情報
以下は、SAP SQLスクリプトを実行するための手順です。
1. SAP Note 1969700 – SQL Statement Collection for SAP HANAの添付ファイルであるSQLStatements.zipをダウンロードします。
2.ファイルを解凍し、HANA_Tables_ColumnStore_Columns_LastTouchTime_2.00.x+.txt という名前の SQL スクリプトを確認します(HANA 1.0 の場合は、同じスクリプトの別のバージョンを選択してください)。
3. 以下の2点を変更して、スクリプトを修正します。
4. SAP HANA Cockpit、SAP HANA Studio、DBACOCKPITのいずれかのSQLエディタ、またはhdbsqlツールを使用して、HANAプロダクションテナントDB上でスクリプトを実行します。
5. スクリプト実行日から過去30日間に変更されたカラムストアサイズの列「MEM_GB」の下に出力されたものを確認します。
翻訳はPartner SA 松本が担当しました。原文はこちらです。