Amazon Web Services ブログ
Amazon CloudWatch ServiceLens を使用して高度に分散化されたアプリケーションを視覚化して監視する
数千のメトリックとテラバイトのログをもつ、ますます分散するアプリケーションは、視覚化と監視が課題になる場合があります。アプリケーションとその依存関係のエンドツーエンドのインサイトを得て、パフォーマンスのボトルネック、運用上の問題、顧客への影響を迅速に特定できるようにするためには、多くの場合、それぞれ情報の特定のファセットを提示する複数の専用ツールを使用する必要があります。これは代わりに、データの取り込みがより複雑になり、さまざまなインサイトを手作業でつなぎ合わせて、全体的なパフォーマンスを判別し、複数のソリューションを維持するコストが増加します。
本日発表された Amazon CloudWatch ServiceLens は、サーバーレスとコンテナベースのテクノロジーの依存するアプリケーションを含む、高度に分散化されたアプリケーションの健全性、パフォーマンス、可用性の視覚化と分析をすべて1か所にまとめた新しい完全マネージ型の可観測性ソリューションです。CloudWatch ServiceLens は、相関メトリック、ログ、およびアプリケーショントレースの分析とともに、問題が発生しているエンドポイントとリソースを簡単に分離できるようにすることで、平均解決時間 (MTTR) の短縮をサービスマップを使用して、このすべてのデータを 1 つの場所に統合するのに役立ちます。このマップから、アプリケーション内の関係と依存関係を理解し、単一のツールからさまざまなログ、メトリック、およびトレースを深く掘り下げて、迅速に障害を特定することができます。さまざまなツールからのメトリック、ログ、およびトレースデータの相関に費やす重要な時間が短縮されるため、エンドユーザーに発生するダウンタイムが削減されます。
Amazon CloudWatch ServiceLensの開始方法
Amazon CloudWatch ServiceLensを利用して、アプリケーションからトリガーされたアラームの根本原因を診断する方法を見てみましょう。サンプルアプリケーションは、AWS Lambda 関数を使用して、トランザクションデータを Amazon DynamoDB テーブルに読み書きします。Amazon API Gateway は、アプリケーションのフロントエンドであり、GET および PUTリクエストのリソースで、対応する GET および PUT ラムダ関数にトラフィックをダイレクトします。API ゲートウェイ リソースと Lambda 関数では AWS X-Ray トレースを有効にしており、Lambda 関数内から DynamoDB への API 呼び出しがAWS X-Ray SDKを使用してラップされます。開発者ガイドで、コードをインスツルメントする方法の詳細と AWS X-Rayの操作方法を確認できます。
エラー状態によりアプリケーションのアラームがトリガーされたため、最初に停止するのは Amazon CloudWatch コンソールで、そこで [Alarm] リンクをクリックします。1 つ以上の API ゲートウェイリソースの可用性に問題があることがわかります。
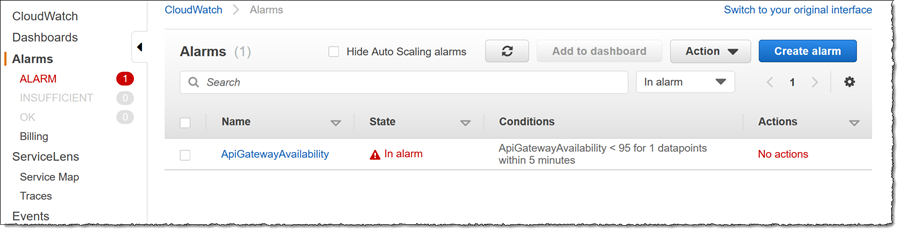
ドリルダウンして、何が起こっているのかを見てみましょう。まず、実行中のアプリケーションの概要を取得したいので、左側のナビゲーションパネルの [ServiceLens] の下にある [Service Map] をクリックします。マップには、アプリケーション内の分散リソースを表すノードが表示されます。ノードの相対的なサイズは、ノード間のリンクの厚さと同様に、それぞれが受信している要求トラフィックの量を表します。リクエストモードまたはレイテンシモードの表示を切り替えることができます。同じドロップダウンを使用して、ノードの相対的なサイズを変更するオプションを切り替えることもできます。リクエストモードまたはレイテンシモードに表示されるデータは、最初にトリアージする必要があるノードを分離するのに役立ちます。[View connections] をクリックすると、着信コールと発信コール、および個々のノードへの影響を理解するのに役立つため、プロセスを支援するために使用することもできます。

スクリーンショットでマップの凡例を閉じたので、すべてのノードをよく見ることができます。参照用に以下に示します。

マップから、フロントエンドゲートウェイがトリガーされたアラームのソースであることがすぐにわかります。ノードの赤のインジケーターは、リソースに関連する 5xx 障害があることを示しており、円周に対するインジケーターの長さは、成功した要求と比較して障害が発生している要求の数を示しています。次に、API を介して PUT リクエストを処理している Lambda 関数が 4xx エラーを表示していることがわかります。最後に、DynamoDB テーブルに、スロットルが発生していることを示す紫のインジケーターが表示されます。この時点で何が起こっているのかについてかなり良い考えを持っていますが、もう少し掘り下げて、CloudWatch ServiceLens が私が証明するのに役立つことを見てみましょう。
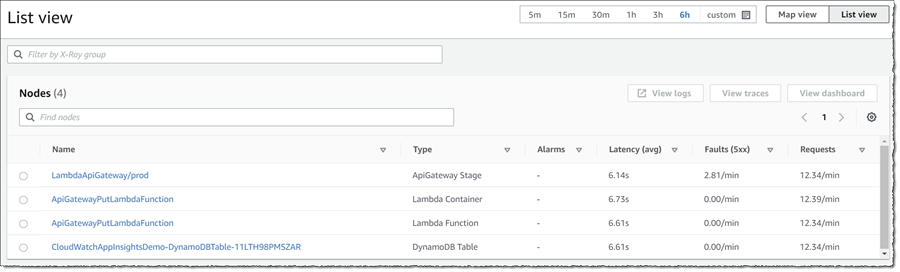
マップビューに加えて、リストビューを切り替えることもできます。これにより、すべてのノードの平均遅延、障害、およびリクエスト/分に関する情報が一目でわかり、デフォルトでは、障害率の降順の並べ替え順序を使用して、最初に「最悪」のノードを表示します。つまり、アラーム内のアラーム数で降順 – ノード名で昇順です。
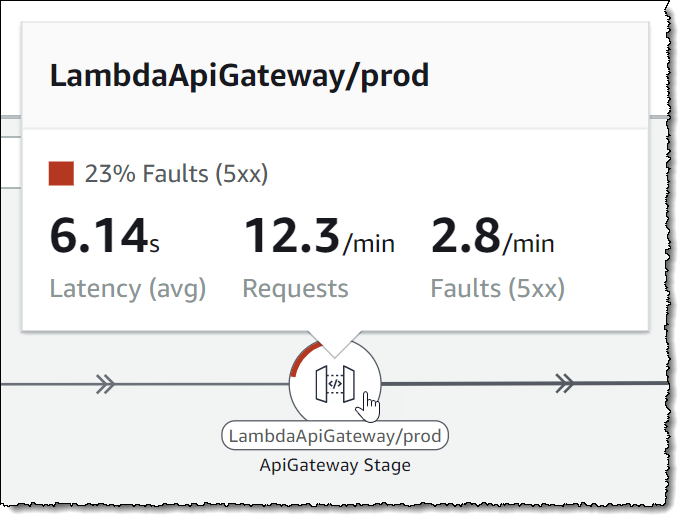
マップビューに戻って、API フロントエンドを表すノードの上にマウスを移動すると、ノードに固有のトラフィックと耐障害性リクエストの割合について同様のインサイトが得られます。
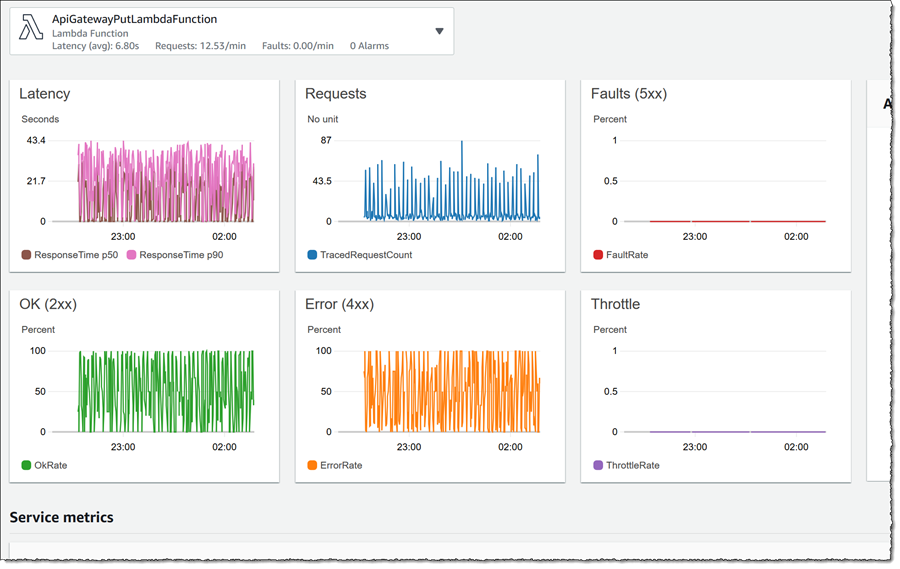
 さらに多くのデータを表示するには、任意のノードをクリックすると、そのリソースのグラフ化されたデータを含むマップの下にドロワーが開きます。以下のスクリーンショットでは、ApiGatewayPutLambdaFunction ノードをクリックしています。
さらに多くのデータを表示するには、任意のノードをクリックすると、そのリソースのグラフ化されたデータを含むマップの下にドロワーが開きます。以下のスクリーンショットでは、ApiGatewayPutLambdaFunction ノードをクリックしています。
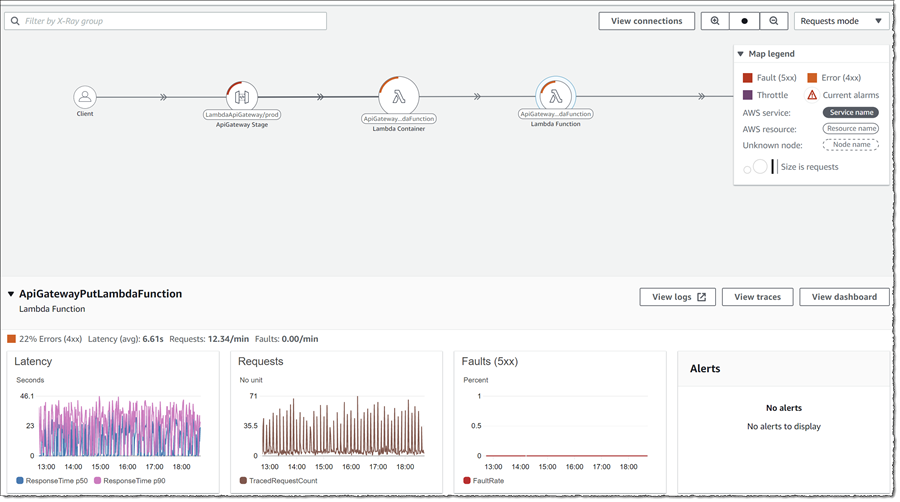
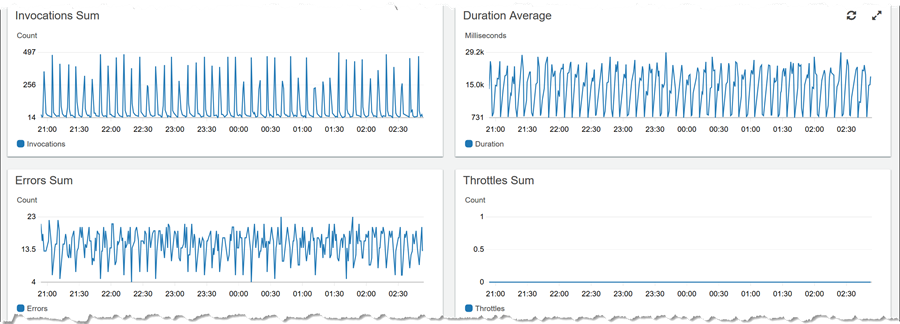
各リソースの引き出しを使用すると、リソース (View logs)、トレース (View trace) またはダッシュボード (View dashboard) に対するログを表示するためにジャンプすることができるようになります。以下では、同じ Lambda 関数に対する [View dashboard] をクリックしました。そのリソースに対して提示されたデータをスクロールすると、実行の期間は長くないが、すべての呼び出しは並行してエラーになります。
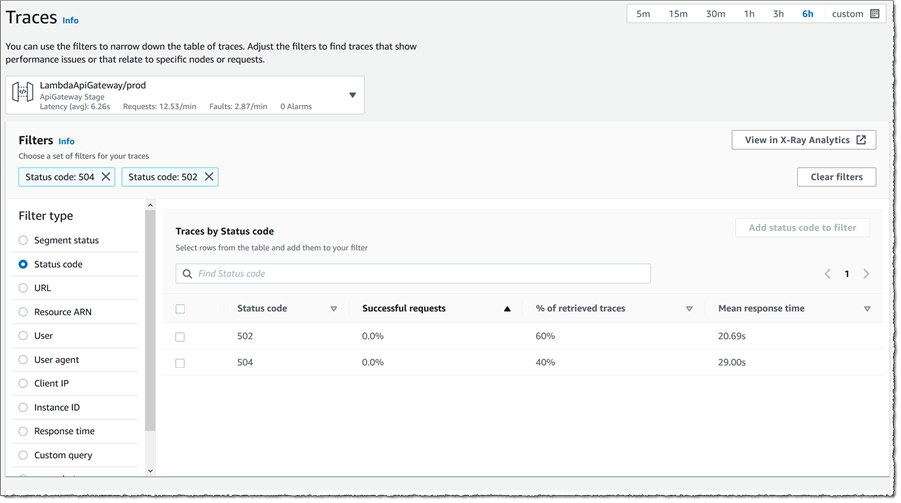
アラームを表示している API フロントエンドに戻り、リクエストトレースを確認したいので、ノードをクリックしてドロワーを開き、[View traces] をクリックします。5xx および 4xx ステータスコードが、アプリケーションに着信する PUT リクエストによって選択されたコードパスで生成されていることをマップからすでに知っているので、[Filter type] を Status code に切り替えて、リストで 502 と 504 の両方のエントリを選択し、最後に [Add to filter] をクリックします。Traces ビューが切り替わり、これらのエラーコード、応答時間分布、および一連のトレースの原因となったトレースが表示されます。
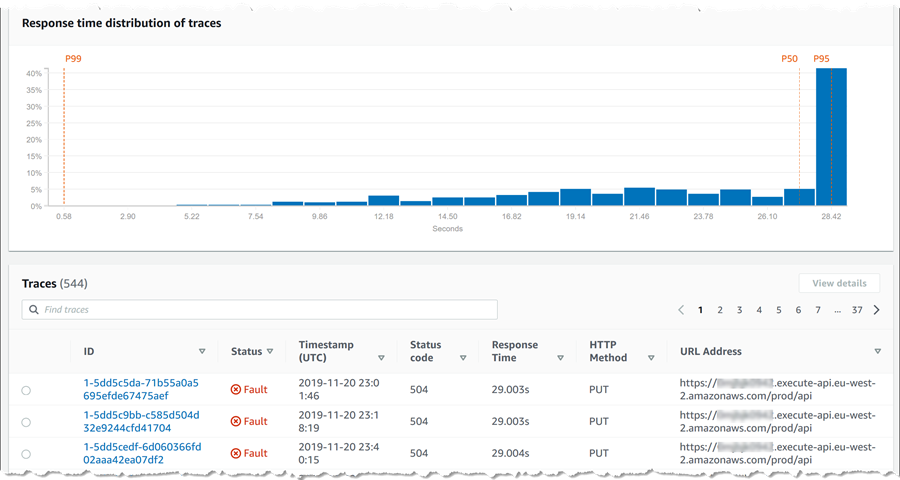
わかりました、そろそろ終わりに近づいています! 最初のトレース ID をクリックすると、そのリクエストに関する例外メッセージを含む豊富なデータが得られます。1 つのスクリーンショットでは表示できません ! たとえば、リクエストの一部としてトレースされた各セグメントのタイムラインを確認できます。
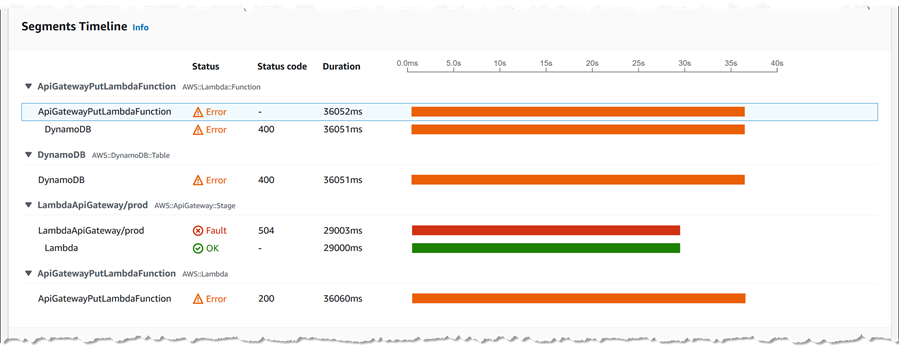
さらに下にスクロールすると、例外の詳細を表示できます (これより下のトレースに固有のログメッセージも表示できます)。ここに、元のマップで見た調整インジケーターを確認して、答えを示します。ページの下部に表示される、トレースに固有のログデータにもこの例外メッセージが表示されます。以前は、このメッセージを見つけるためにアプリケーション全体のログをスキャンする必要がありました。マップから掘り下げることができると、時間を大幅に節約できます。
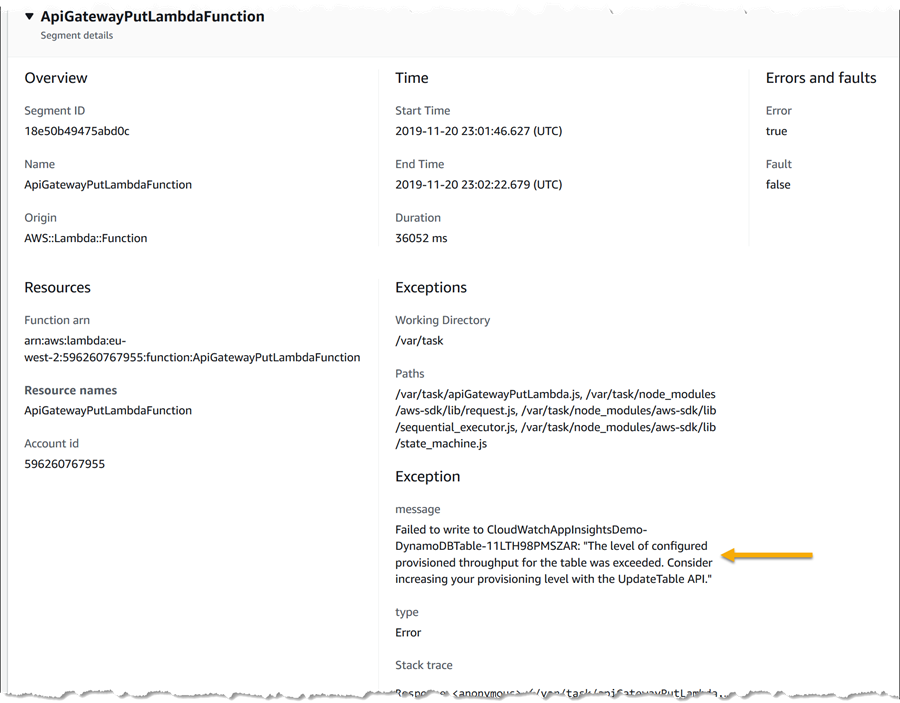

これで、問題を修正してアラームを解決する方法がわかりました。テーブルの書き込みプロビジョニングを増やします。
CloudWatch ServiceLens とともに、Amazon CloudWatch は CloudWatch Synthetics は、365 日毎日24時間稼働するカナリアを使用してエンドポイントを監視するのに役立ちます。これにより、顧客が直面している問題を迅速に警告できます。これらはサービスマップでも視覚化され、上記と同様に、トレースにドリルダウンしてカナリアから発信されたトランザクションを表示できます。運用障害またはアラームの統合ビューをより早く深く掘り下げるほど、問題の根本原因をより迅速に特定し、解決までの時間を短縮し、顧客への影響を軽減できます。
Amazon CloudWatch ServiceLens は、すべての商用 AWS リージョンで利用可能になりました。