Amazon Web Services 한국 블로그
AWS Lambda 함수에 Amazon EFS 공유 파일 시스템 제공 기능 출시 (서울 리전 포함)
오늘 부터 AWS Lambda 함수와 내부와 다중 가용 영역(AZ) 기반 고가용성 및 내구성을 제공하는 탄력적인 NFS 파일 시스템인 Amazon Elastic File System(EFS)를 연동할 수 있습니다. 이를 통해 하나 이상의 Lambda 함수로 구성된 모든 동시 실행 환경에서 익숙한 파일 시스템 인터페이스를 사용하여 데이터를 저장하고 공유할 수 있습니다. Amazon EFS는 강력한 일관성 보장 및 파일 잠금 등 전체 파일 시스템 액세스 의미 체계를 지원합니다.
Amazon EFS 파일 시스템을 Lambda 함수에 연결하려면 EFS 액세스 지점, 파일 시스템에 액세스할 때 사용할 운영 체제 사용자 및 그룹이 포함된 각 애플리케이션의 EFS 파일 시스템 엔드포인트, 파일 시스템 권한을 사용하며, 파일 시스템의 특정 경로로 액세스를 제한할 수 있습니다. 이렇게 하면 애플리케이션 코드에서 파일 시스템 구성을 분리할 수 있습니다.
여러 함수에서 동일하거나 다른 액세스 지점을 사용하여 EFS 파일 시스템에 접근할 수 있습니다. 예를 들어 다른 EFS 액세스 지점을 사용하는 경우 각 Lambda 함수는 파일 시스템의 서로 다른 경로에 접근하거나 다른 파일 시스템 권한을 사용할 수 있습니다.
동일한 EFS 파일 시스템을 Amazon Elastic Compute Cloud(EC2) 인스턴스, Amazon ECS 및 AWS Fargate를 사용하는 컨테이너식 애플리케이션 및 온프레미스 서버와 공유할 수 있습니다. 이 접근 방식을 따르면 동일한 파일을 다양한 컴퓨팅 아키텍처(함수, 컨테이너, 가상 서버)를 사용하여 처리할 수 있습니다. 예를 들어 이벤트에 대응하는 Lambda 함수는 컨테이너에서 실행되는 애플리케이션이 읽는 구성 파일을 업데이트할 수 있습니다. 또는 EC2에서 실행되는 웹 애플리케이션이 업로드한 파일을 Lambda 함수를 사용하여 처리할 수 있습니다.
이와 같이 일부 사용 사례는 Lambda 함수를 사용할 때 훨씬 더 쉽게 구현됩니다. 예를 들면 다음과 같습니다.
/tmp의 사용 가능한 공간(512MB)보다 큰 데이터 처리 또는 로드.- 자주 변경되는 파일의 최신 업데이트 버전 로드.
- 모델 및 기타 종속성을 로드할 스토리지 공간이 필요한 데이터 과학 패키지 사용.
- 여러 호출의 함수 상태 저장(고유한 파일 이름 또는 파일 시스템 잠금 사용).
- 다량의 참조 데이터에 액세스해야 하는 애플리케이션 구축.
- 레거시 애플리케이션을 서버리스 아키텍처로 마이그레이션.
- 파일 시스템 액세스용으로 설계된 데이터 집약적 워크로드와 상호 작용.
- 파일의 부분 업데이트(동시 액세스를 위해 파일 시스템 잠금 사용).
- 원자성 작업으로 파일 시스템 내부의 디렉터리 및 모든 콘텐츠 이동.
Amazon EFS 파일 시스템 생성하기
Amazon EFS 파일 시스템을 탑재하려면 EFS 탑재 대상에 접속할 수 있는 Amazon Virtual Private Cloud에 Lambda 함수를 연결해야 합니다. 여기서는 간단히, 각 AWS 리전에 자동으로 생성되는 기본 VPC를 사용합니다.
Lambda 함수를 VPC에 연결할 때는 네트워킹 작동 방식이 다릅니다. Lambda 함수에 Amazon Simple Storage Service(S3) 또는 Amazon DynamoDB를 사용하는 경우 이러한 서비스에 대한 게이트웨이 VPC 엔드포인트를 생성해야 합니다. Lambda 함수에서 퍼블릭 인터넷에 액세스해야 하는 경우(예: 외부 API를 호출하기 위해) NAT Gateway를 구성해야 합니다. 일반적으로는 기본 VPC의 구성을 변경하지 않습니다. 특정 요구 사항이 있는 경우 AWS Cloud Development Kit를 사용하여 프라이빗 및 퍼블릭 서브넷으로 새 VPC를 생성하거나 AWS CloudFormation 샘플 템플릿 중 하나를 사용합니다. 이렇게 하면 네트워킹을 코드로 관리할 수 있습니다.
EFS 콘솔에서 [파일 시스템 생성]을 선택하고 기본 VPC와 해당하는 서브넷이 선택되었는지 확인합니다. 모든 서브넷에 기본 보안 그룹을 사용합니다. 이 기본 보안 그룹은 동일한 보안 그룹을 사용하여 VPC의 다른 리소스에 대한 네트워크 액세스를 제공합니다.

다음 단계에서 파일 시스템에 [이름] 태그를 지정하고 다른 모든 옵션을 기본값으로 유지합니다.

그런 다음 [액세스 지점 추가]를 선택합니다. [1001]을 사용자 및 그룹 ID로 사용하고 /message 경로로 액세스를 제한합니다. [소유자] 섹션에서 처음에 액세스 지점에 연결할 때 자동으로 폴더를 생성했습니다. 이전과 동일한 사용자 및 그룹 ID를 사용하고 권한에 [750]을 사용합니다. 이 권한이 있으면 소유자가 파일을 읽고 쓰고 실행할 수 있습니다. 동일한 그룹의 사용자는 읽을 수만 있습니다. 다른 사용자에게는 액세스 권한이 없습니다.

계속해서 파일 시스템 생성을 완료합니다.
Lambda 함수와 함께 EFS 사용하기
단순한 사용 사례를 시작하기 위해 텍스트 메시지를 추가하거나 읽거나 삭제하는 MessageWall API를 구현하는 Lambda 함수를 구축합시다. 메시지는 EFS의 파일에 저장되므로 해당 Lambda 함수의 모든 동시 실행 환경에서 동일한 콘텐츠를 볼 수 있습니다.
Lambda 콘솔에서 새 MessageWall 함수를 생성하고 Python 3.8 런타임을 선택합니다. [권한] 섹션에서 기본값을 유지합니다. 그러면 기본 권한이 포함된 새 AWS Identity and Access Management(IAM) 역할이 생성됩니다.
함수가 생성되면 [권한] 탭에서 IAM 역할 이름을 클릭하여 IAM 콘솔에서 역할을 엽니다. 여기서 [정책 연결]을 선택하여 AWSLambdaVPCAccessExecutionRole 및 AmazonElasticFileSystemClientReadWriteAccess AWS 관리형 정책을 추가합니다. 프로덕션 환경에서는 특정 VPC 및 EFS 액세스 지점으로 액세스를 제한할 수 있습니다.
다시 Lambda 콘솔로 돌아와서 EFS 탑재 지점에 사용한 것과 동일한 기본 보안 그룹을 사용하여 MessageWall 함수를 기본 VPC의 모든 서브넷에 연결하도록 VPC 구성을 편집합니다.
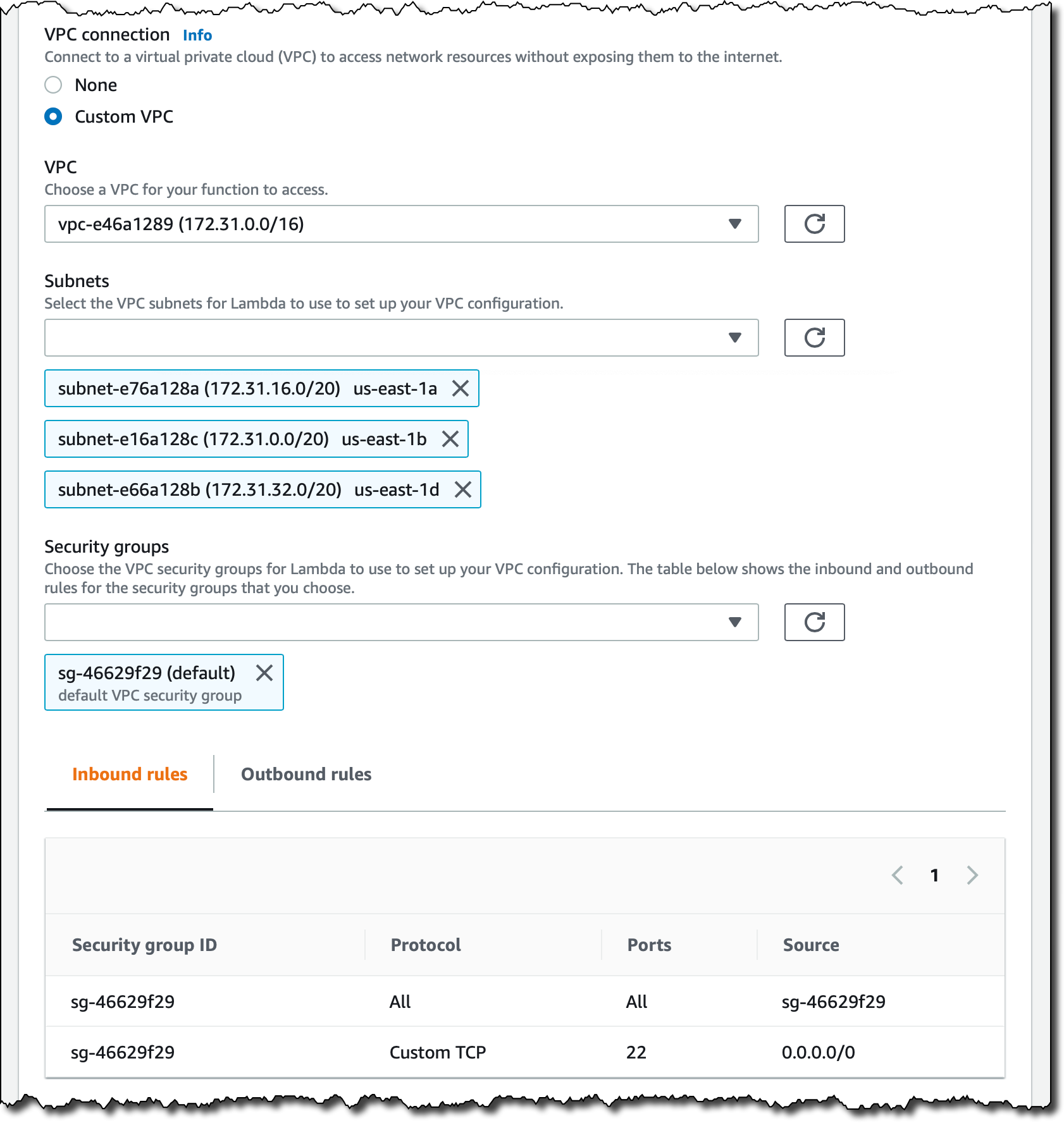
이제, 함수 구성의 새 [파일 시스템] 섹션에서 [파일 시스템 추가]를 선택합니다. 여기서 이전에 생성한 EFS 파일 시스템과 액세스 지점을 선택합니다. 로컬 탑재 지점에는 /mnt/msg를 사용하고 저장합니다. 이 경로는 액세스 지점을 탑재할 경로이며 EFS 파일 시스템의 /message 폴더에 해당합니다.

Lambda 콘솔의 함수 코드 편집기에 다음 코드를 붙여 넣고 저장합니다.
import os
import fcntl
MSG_FILE_PATH = '/mnt/msg/content'
def get_messages():
try:
with open(MSG_FILE_PATH, 'r') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_SH)
messages = msg_file.read()
fcntl.flock(msg_file, fcntl.LOCK_UN)
except:
messages = 'No message yet.'
return messages
def add_message(new_message):
with open(MSG_FILE_PATH, 'a') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_EX)
msg_file.write(new_message + "\n")
fcntl.flock(msg_file, fcntl.LOCK_UN)
def delete_messages():
try:
os.remove(MSG_FILE_PATH)
except:
pass
def lambda_handler(event, context):
method = event['requestContext']['http']['method']
if method == 'GET':
messages = get_messages()
elif method == 'POST':
new_message = event['body']
add_message(new_message)
messages = get_messages()
elif method == 'DELETE':
delete_messages()
messages = 'Messages deleted.'
else:
messages = 'Method unsupported.'
return messages
[트리거 추가]를 선택하고 구성에서 Amazon API Gateway를 선택합니다. 새 HTTP API를 생성합니다. 간단한 설명을 위해 API 엔드포인트를 열어두겠습니다.

API Gateway 트리거를 선택한 상태에서 방금 생성한 새 API의 엔드포인트를 복사합니다.
이제, curl을 사용하여 API를 테스트할 수 있습니다.
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello from EFS!' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello again :)' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl -X DELETE https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Messages deleted.
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.여러 사용자에 대해 고유한 파일 이름(또는 특정 하위 디렉터리)을 추가하고 이 단순한 예제를 보다 완전한 메시징 애플리케이션으로 확장하기는 비교적 쉽습니다. 개발자에게 있어서는 익숙한 파일 시스템 인터페이스를 코드에 사용할 수 있다는 단순성이 상당히 유용합니다. 그러나 요구 사항에 따라 EFS 처리량 구성을 고려해야 합니다. 자세한 내용은 이 게시물의 후반부에 있는 EFS 성능 이해 섹션을 참조하십시오.
이제, AWS Lambda의 새 EFS 파일 시스템 지원을 사용하여 좀 더 흥미로운 것을 구축해봅시다. 예를 들어 EFS가 제공하는 추가 공간을 사용하여 이미지를 처리하는 기계 학습 인터페이스 API를 구축할 수 있습니다.
서버리스 기계 학습 인터페이스 API 구축
기계 학습 추론을 구현하는 Lambda 함수를 생성하려면 코드에서 필요한 라이브러리를 가져오고 기계 학습 모델을 로드할 수 있어야 합니다. 이 작업을 수행할 때는 종종 이러한 종속성의 전체 크기가 배포 패키지 크기의 현재 AWS Lambda 제한을 초과합니다. 이 제한을 해결하는 방법 중 하나는 함수 코드를 통해 전달할 라이브러리를 정확히 최소화한 다음 S3 버킷에서 바로 메모리(모델 처리에 필요한 메모리를 포함하여 최대 3GB)로 또는 /tmp(최대 512MB)로 모델을 다운로드하는 것입니다. 이 모델 사용자 지정 최소화 및 다운로드는 구현하기가 쉬운 적이 없었습니다. 이제는 EFS 파일 시스템을 사용할 수 있습니다.
이번에 구축하는 Lambda 함수에서는 퍼블릭 인터넷에 액세스하여 추론을 실행할 미리 훈련된 모델 및 이미지를 다운로드해야 합니다. 따라서 퍼블릭 및 프라이빗 서브넷으로 새 VPC를 생성하고, 퍼블릭 인터넷에 대한 액세스를 제공하도록 프라이빗 서브넷에 사용되는 NAT Gateway 및 라우팅 테이블을 구성합니다. AWS Cloud Development Kit를 사용하면 코드 몇 줄만 추가하면 됩니다.
이전과 유사한 구성을 사용하여 새 VPC에 새 EFS 파일 시스템 및 액세스 지점을 생성합니다. 이번에는 /ml을 액세스 지점 경로로 사용합니다.
그런 다음 권한에 대해 이전과 동일한 설정으로 새 MLInference Lambda 함수를 생성하고 새 VPC의 프라이빗 서브넷에 함수를 연결합니다. 기계 학습 추론은 꽤 작업량이 많은 워크로드이므로 메모리로 3GB를 선택하고 제한 시간으로 5분을 선택합니다. 파일 시스템 구성에서 새 액세스 지점을 추가하고 /mnt/inference 아래에 탑재합니다.
이 함수에 사용할 기계 학습 프레임워크는 PyTorch입니다. 이제 EFS 파일 시스템에 추론을 실행하는 데 필요한 라이브러리를 배치해야 합니다. 새 VPC의 퍼블릭 서브넷에서 Amazon Linux EC2 인스턴스를 시작합니다. 인스턴스 세부 정보에서 EFS 탑재 지점이 있는 가용 영역 중 하나를 선택한 다음 파일 시스템을 추가하여 함수에 사용하는 동일한 EFS 파일 시스템을 자동으로 탑재합니다. EC2 인스턴스의 보안 그룹으로 기본 보안 그룹(EFS 파일 시스템을 탑재하기 위해)과 SSH에 대한 인바운드 액세스를 제공하는 보안 그룹(인스턴스에 연결하기 위해)을 선택합니다.
SSH를 사용하여 인스턴스에 연결하고 필요한 종속성이 포함된 requirements.txt 파일을 생성합니다.
torch
torchvision
numpy
EFS 파일 시스템이 EC2의 /mnt/efs/fs1에 자동으로 탑재됩니다. 거기서 /ml 디렉터리를 생성하고 경로 소유자를 연결에 사용하는 사용자 및 그룹(ec2-user)으로 변경합니다.
$ sudo mkdir /mnt/efs/fs1/ml
$ sudo chown ec2-user:ec2-user /mnt/efs/fs1/mlPython 3를 설치하고 pip를 사용하여 /mnt/efs/fs1/ml/lib 경로에 종속성을 설치합니다.
$ sudo yum install python3
$ pip3 install -t /mnt/efs/fs1/ml/lib -r requirements.txt
마지막으로, 전체 /ml 경로의 소유권을 EFS 액세스 지점에 사용한 사용자 및 그룹에 제공합니다.
$ sudo chown -R 1001:1001 /mnt/efs/fs1/ml
전체적으로 EFS 파일 시스템의 종속성에는 약 1.5GB의 스토리지가 사용됩니다.
MLInference Lambda 함수 구성으로 돌아갑니다. 배포 패키지 또는 계층에 종속성이 포함되지 않은 경우 사용하는 런타임에 따라 적절한 방법을 사용하여 종속성을 찾을 위치를 지정해야 합니다. Python의 경우 PYTHONPATH 환경 변수를 /mnt/inference/lib로 설정합니다.
PyTorch Hub를 사용하여 사진의 새 종류를 인지하도록 미리 훈련된 기계 학습 모델을 다운로드할 것입니다. 이 예제에서 사용할 모델은 약 200MB로, 꽤 작습니다. EFS 파일 시스템에서 모델을 캐시하기 위해 TORCH_HOME 환경 변수를 /mnt/inference/model로 설정합니다.

이제 모든 종속성이 함수에 탑재된 파일 시스템에 있으므로 함수 코드 편집기에 바로 코드를 입력할 수 있습니다. 다음 코드를 붙여 넣어 기계 학습 추론 API를 만듭니다.
import urllib
import json
import os
import torch
from PIL import Image
from torchvision import transforms
transform_test = transforms.Compose([
transforms.Resize((600, 600), Image.BILINEAR),
transforms.CenterCrop((448, 448)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True,
**{'topN': 6, 'device': 'cpu', 'num_classes': 200})
model.eval()
def lambda_handler(event, context):
url = event['queryStringParameters']['url']
img = Image.open(urllib.request.urlopen(url))
scaled_img = transform_test(img)
torch_images = scaled_img.unsqueeze(0)
with torch.no_grad():
top_n_coordinates, concat_out, raw_logits, concat_logits, part_logits, top_n_index, top_n_prob = model(torch_images)
_, predict = torch.max(concat_logits, 1)
pred_id = predict.item()
bird_class = model.bird_classes[pred_id]
print('bird_class:', bird_class)
return json.dumps({
"bird_class": bird_class,
})이전에 MessageWall 함수에 수행한 것과 비슷하게 API Gateway를 트리거로 추가합니다. 이제, 방금 생성한 서버리스 API를 사용하여 새 사진을 분석할 수 있습니다. 이 분야의 전문가가 아니기 때문에 Wikipedia에서 흥미로운 이미지 몇 개를 찾았습니다.


API를 호출하여 이러한 사진 2개에 대한 예측을 가져옵니다.
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/atlantic-puffin.jpg
{"bird_class": "106.Horned_Puffin"}
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/western-grebe.jpg
{"bird_class": "053.Western_Grebe"}제대로 작동합니다! Lambda 함수에 대한 Amazon CloudWatch Logs를 보면 함수가 미리 훈련된 추론 모델을 CPU에 로드하고 준비하는 첫 번째 호출에 약 30초가 소요되는 것을 알 수 있습니다. 느린 응답 또는 API Gateway의 시간 초과를 방지하기 위해 프로비저닝된 동시성을 사용하여 함수를 준비된 상태로 유지합니다. 다음 호출에는 약 1.8초가 소요됩니다.
EFS 성능 이해
EFS를 Lambda 함수와 함께 사용할 때는 EFS 성능의 작동 원리를 이해하는 것이 중요합니다. 처리량의 경우 버스트 또는 프로비저닝 모드를 사용하도록 각 파일 시스템을 구성할 수 있습니다.
버스트 모드를 사용하는 경우 모든 EFS 파일 시스템을 크기에 관계없이 최소 100MiB/s의 처리량으로 버스트할 수 있습니다. Standard 스토리지 클래스에서 1TiB를 초과하는 파일 시스템의 경우 파일 시스템에 저장된 데이터의 TiB당 100 MiB/s까지 버스트될 수 있습니다. EFS는 크레딧 시스템을 사용하여 파일 시스템의 버스트 가능 시기를 결정합니다. 각 파일 시스템에는 시간이 지남에 따라 기준 비율로 크레딧이 쌓입니다. 기준 비율은 Standard 스토리지 클래스에 저장되는 파일 시스템의 크기에 따라 결정됩니다. 파일 시스템은 데이터를 읽거나 쓸 때마다 크레딧을 사용합니다. 기준 비율은 스토리지 GiB당 50KiB/s입니다.
CloudWatch에서 크레딧 사용을 모니터링할 수 있으며 각 EFS 파일 시스템에는 BurstCreditBalance 지표가 있습니다. 모든 크레딧이 소진되고 있고 BurstCreditBalance 지표가 0에 근접하면 파일 시스템의 프로비저닝 처리량 모드를 1~1,024MiB/s로 활성화해야 합니다. 기준 비율에 더해 추가하는 처리량의 양에 따라 프로비저닝 처리량을 사용할 때 추가 비용이 발생합니다.
크레딧 소진을 방지하려면 하루에 필요한 평균으로 처리량을 생각해야 합니다. 예를 들어 10GB 파일 시스템이 있고, 기준 비율은 500KiB/s이며, 매일 읽고 쓸 수 있는 양은 500KiB/s * 3,600초 * 24시간 = 43.2GiB입니다.
라이브러리와 함수가 초기화 중에 로드해야 하는 모든 항목은 약 2GiB이고, EFS 파일 시스템에는 위의 MLInference Lambda 함수와 마찬가지로 함수 초기화 중에만 액세스합니다. 그러면 함수 초기화는 하루에 20회 가량 수행될 수 있습니다(예: 업데이트 또는 확장 활동으로 인해). 많지는 않습니다. 그렇지만 EFS 파일 시스템의 프로비저닝 처리량을 구성해야 할 것입니다.
프로비저닝 처리량이 10MiB/s인 경우 매일 10MiB/s * 3,600초 * 24시간 = 864GiB를 읽거나 쓸 수 있습니다. 함수 초기화에만 EFS 파일 시스템을 사용하여 약 2GB의 종속성을 읽는다면 하루 400회의 초기화가 수행될 수 있습니다. 이 정도면 사용 사례로 충분할 수 있습니다.
Lambda 함수 구성에서 동시성 예약 제어를 사용하여 함수에 사용되는 실행 환경의 최대 수를 제한할 수도 있습니다.
파일 시스템이 비교적 작은 경우(예: 몇 GiB) 실수로 BurstCreditBalance가 0이 되면 함수가 중단되고 제한 시간 전에 실행되지 못할 수 있습니다. 이 경우 EFS 파일 시스템의 프로비저닝 처리량을 활성화(또는 증가)하거나 예약 동시성을 0으로 설정하여 함수를 조절함으로써 EFS 파일 시스템에 충분한 크레딧이 쌓일 때까지 모든 호출을 차단해야 합니다.
보안 제어 이해
EFS 파일 시스템을 AWS Lambda와 함께 사용하는 경우 여러 수준의 보안 제어를 구현할 수 있습니다. 이러한 보안 제어는 서버리스 애플리케이션의 설계 및 구현 중에 모두 고려되어야 하므로 여기서는 요점만 말하도록 하겠습니다. 자세한 정보는 이 게시물의 EFS의 IAM 권한 부여 및 액세스 지점에서 확인할 수 있습니다.
Lambda 함수를 EFS 파일 시스템에 연결하려면 다음이 필요합니다.
- VPC 라우팅/피어링 및 보안 그룹의 측면에서 네트워크 가시성.
- Lambda 함수에서 VPC에 액세스하고 EFS 파일 시스템을 탑재(읽기 전용 또는 읽기/쓰기)하기 위한 IAM 권한.
- IAM 정책 조건에서 Lambda 함수에 사용할 수 있는 EFS 액세스 지점을 지정할 수 있습니다.
- EFS 액세스 지점을 사용하면 파일 시스템의 특정 경로로 액세스를 제한할 수 있습니다.
- 파일 시스템 보안(사용자 ID, 그룹 ID, 권한)을 사용하면 Lambda 함수에 탑재된 각 파일 또는 디렉터리에 대한 읽기, 쓰기 또는 실행 액세스 권한을 제한할 수 있습니다.
Lambda 함수 실행 환경 및 EFS 탑재 지점은 업계 표준 TLS(전송 계층 보안) 1.2를 사용하여 전송 중 데이터를 암호화합니다. Amazon EFS를 프로비저닝하면 저장된 데이터를 암호화할 수 있습니다. 저장 중에 암호화된 데이터는 쓰는 동안 투명하게 암호화되며 읽을 때 투명하게 복호화되므로 애플리케이션을 수정하지 않아도 됩니다. 암호화 키는 AWS Key Management Service(KMS)를 통해 관리됩니다. 따라서 보안 키 관리 인프라를 구축하고 유지 관리할 필요가 없습니다.
정식 출시
중국을 제외하고, AWS Lambda 및 Amazon EFS를 사용할 수 있는 모든 리전에서 제공됩니다. 중국에서 가능한 빨리 이 통합을 제공하기 위한 작업을 현재 진행 중입니다. 가용성에 대한 자세한 내용은 AWS 리전 표를 참조하십시오. 자세히 알아보려면 설명서를 참조하십시오.
Lambda용 EFS는 콘솔, AWS Command Line Interface(CLI), AWS SDK 및 Serverless Application Model을 사용하여 구성할 수 있습니다. 이 기능을 사용하면 큰 파일을 처리해야 하는 데이터 집약적 애플리케이션을 구축할 수 있습니다. 예를 들어 코드 몇 줄로 1.5GB 파일의 압축을 풀거나 10GB JSON 문서를 처리할 수 있습니다. 또한 AWS Lambda의 패키지 배포 크기 제한인 250MB를 초과하는 라이브러리 또는 패키지를 로드하여 기계 학습, 데이터 모델링, 재무 분석 및 ETL 작업 시나리오를 지원할 수 있습니다.
Amazon EFS for Lambda는 출시 후 Epsagon, Lumigo, Datadog, HashiCorp Terraform 및 Pulumi와 같은 AWS Partner Network 솔루션에서 지원됩니다.
Lambda 함수에서 EFS를 사용하는 데 추가 요금은 없습니다. AWS Lambda와 Amazon EFS에 대한 표준 요금만 지불하면 됩니다. Lambda 실행 환경은 항상 AZ의 올바른 탑재 대상에 연결되며 AZ를 교차하여 연결되지는 않습니다. 교차 계정 VPC를 통해 동일한 AZ의 EFS에 연결할 수 있지만 이 경우 데이터 전송 비용이 발생할 수 있습니다. 교차 리전 또는 EFS와 Lambda 간의 교차 AZ 연결은 지원되지 않습니다.
— Danilo