Amazon Web Services 한국 블로그
Amazon Bedrock용 에이전트 미리보기 출시 – 다양한 파운데이션 모델 작업에 대한 지원 제공
올해 4월 AWS의 데이터 및 기계 학습 (M) 부사장인 Swami Sivasubramanian은 AWS 기반 생성형 AI를 사용하여 솔루션을 구축하기 위한 새로운 도구의 일부로 Amazon Bedrock 및 Amazon Titan 모델을 발표했습니다. 현재 제한된 미리보기로 제공되는 Amazon Bedrock은 AI21 Labs, Anthropic, Cohere, Stability AI 등 주요 AI 스타트업과 Amazon의 파운데이션 모델(FM)을 API를 통해 사용할 수 있게 해주는 완전관리형 서비스입니다.
이제 개발자가 클릭 몇 번으로 완전관리형 에이전트를 생성할 수 있는 새로운 기능인 Amazon Bedrock용 에이전트 미리보기를 발표하게 되었습니다. Amazon Bedrock용 에이전트는 회사 시스템에 대한 API 직접 호출을 통해 작업을 관리하고 수행할 수 있는 생성형 AI 애플리케이션의 제공을 가속화합니다. 에이전트는 FM을 확장하여 사용자 요청을 이해하고, 복잡한 작업을 여러 단계로 나누고, 대화를 통해 추가 정보를 수집하며, 요청을 이행하기 위한 조치를 취합니다.
Amazon Bedrock용 에이전트를 사용하면 소매 주문 관리, 보험금 청구 처리 등 내부 또는 외부 고객을 위한 작업을 자동화할 수 있습니다. 예를 들어 에이전트 기반의 생성형 AI 전자 상거래 애플리케이션은 “혹시 이 재킷, 블루 컬러는 없나요?”라는 질문에 간단히 답하는 것은 물론, 고객 주문 업데이트 또는 교환 관리와 같은 작업에도 도움을 줄 수 있습니다.
이를 위해서는 먼저 외부 데이터 소스에 대한 액세스 권한을 에이전트에 부여하고, 에이전트를 다른 애플리케이션의 기존 API에 연결해야 합니다. 그러면 에이전트를 구동하는 FM이 더 확장된 환경과 상호 작용하며, 단순한 언어 처리 작업을 뛰어넘어 더 많은 용도로 모델을 활용할 수 있습니다. 둘째, FM은 취해야 할 조치, 사용할 정보, 이러한 조치를 수행할 순서를 알아내야 합니다. 이를 가능하게 하는 것은 신기술로 떠오르는 FM의 흥미로운 동작, 즉 추론 능력입니다. 정의와 지침이 포함된 프롬프트를 작성하여, 작업을 통해 이러한 상호 작용을 처리하고 추론하는 방법을 FM에 보여줄 수 있습니다. 모델이 원하는 출력을 도출하도록 안내하는 프롬프트를 설계하는 프로세스를 프롬프트 엔지니어링이라고 합니다.
Amazon Bedrock용 에이전트 소개
Amazon Bedrock용 에이전트는 사용자 요청 작업의 프롬프트 엔지니어링 및 오케스트레이션을 자동화합니다. 구성된 에이전트는 자동으로 프롬프트를 작성하고 회사별 정보로 안전하게 보강하여, 사용자에게 자연어로 답을 제시합니다. 에이전트는 사용자가 요청한 작업을 자동으로 처리하려면 어떤 조치를 취해야 할지를 알아낼 수 있습니다. 작업을 여러 단계로 나누고, 일련의 API 호출 및 데이터 조회를 오케스트레이션하며, 사용자를 위한 조치를 완료할 수 있도록 메모리를 유지 관리합니다.
완전관리형 에이전트를 사용하면 인프라를 프로비저닝하거나 관리해야 하는 번거로움이 없습니다. 사용자 지정 코드를 작성하지 않고도 모니터링, 암호화, 사용자 권한 및 API 간접 호출 관리를 원활하게 지원할 수 있습니다. 개발자는 Bedrock 콘솔 또는 SDK를 사용하여 API 스키마를 업로드할 수 있습니다. 그러면 에이전트가 FM의 도움을 받아 작업을 오케스트레이션하고 AWS Lambda 함수를 사용하여 API 직접 호출을 수행합니다.
고급 추론 및 ReAct 입문서
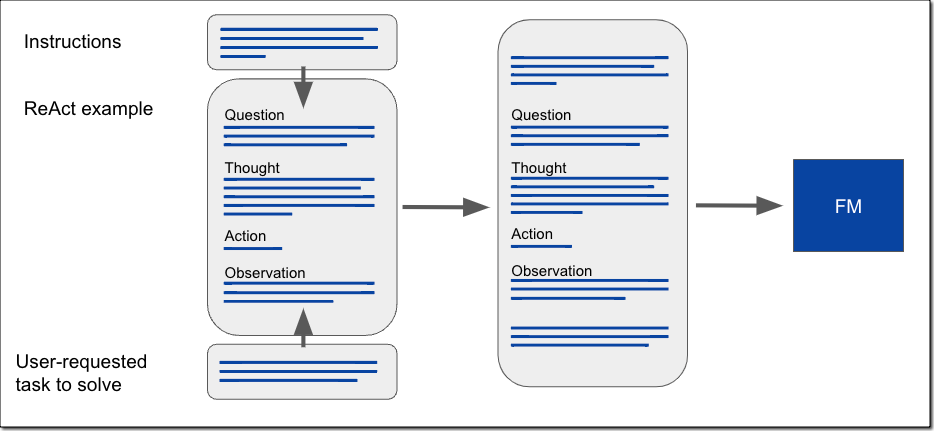
ReAct(추론과 조치의 시너지)라는 추론 기법을 사용하여 FM이 추론을 수행하고 사용자가 요청한 작업을 해결할 방법을 알아내도록 도울 수 있습니다. React를 사용하면 프롬프트를 구성하여, 작업을 통해 추론을 수행하고 솔루션을 찾는 데 도움이 되는 조치를 결정하는 방법을 FM에 보여줄 수 있습니다. 구조화된 프롬프트에는 일련의 질문-사고-조치-관찰 예제가 포함되어 있습니다.
질문은 사용자가 요청한 작업 또는 해결해야 할 문제입니다. 사고는 문제를 해결하고 취해야 할 조치를 식별하는 방법을 FM에 보여주는 데 도움이 되는 추론 단계입니다. 조치는 모델이 허용된 API 세트에서 간접적으로 호출할 수 있는 API입니다. 관찰은 조치를 수행한 결과입니다. FM이 선택할 수 있는 조치는 예제 프롬프트 텍스트 앞에 추가되는 일련의 지침에 의해 정의됩니다. 다음 그림은 ReAct 프롬프트를 작성하는 방법을 보여줍니다.
다행히도 번거로운 작업은 Bedrock이 모두 대신 해 줍니다. Amazon Bedrock용 에이전트는 사용자가 제공한 정보와 조치에 따라 자동으로 프롬프트를 작성합니다.
이제 Amazon Bedrock용 에이전트를 사용하여 작업을 시작하는 방법을 보여 드리겠습니다.
Amazon Bedrock용 에이전트 생성
보험사의 개발자로서, 보험대리점 점주들이 반복적인 작업을 자동화할 수 있도록 도와주는 생성형 AI 애플리케이션을 제공하고자 한다고 가정해 보겠습니다. Bedrock에서 에이전트를 생성하고 이를 애플리케이션에 통합합니다.
에이전트를 시작하려면 Bedrock 콘솔을 열고 왼쪽 탐색 패널에서 Agents(에이전트)를 선택한 다음 Create Agent(에이전트 생성)를 선택합니다.
그러면 에이전트 생성 워크플로가 시작됩니다.
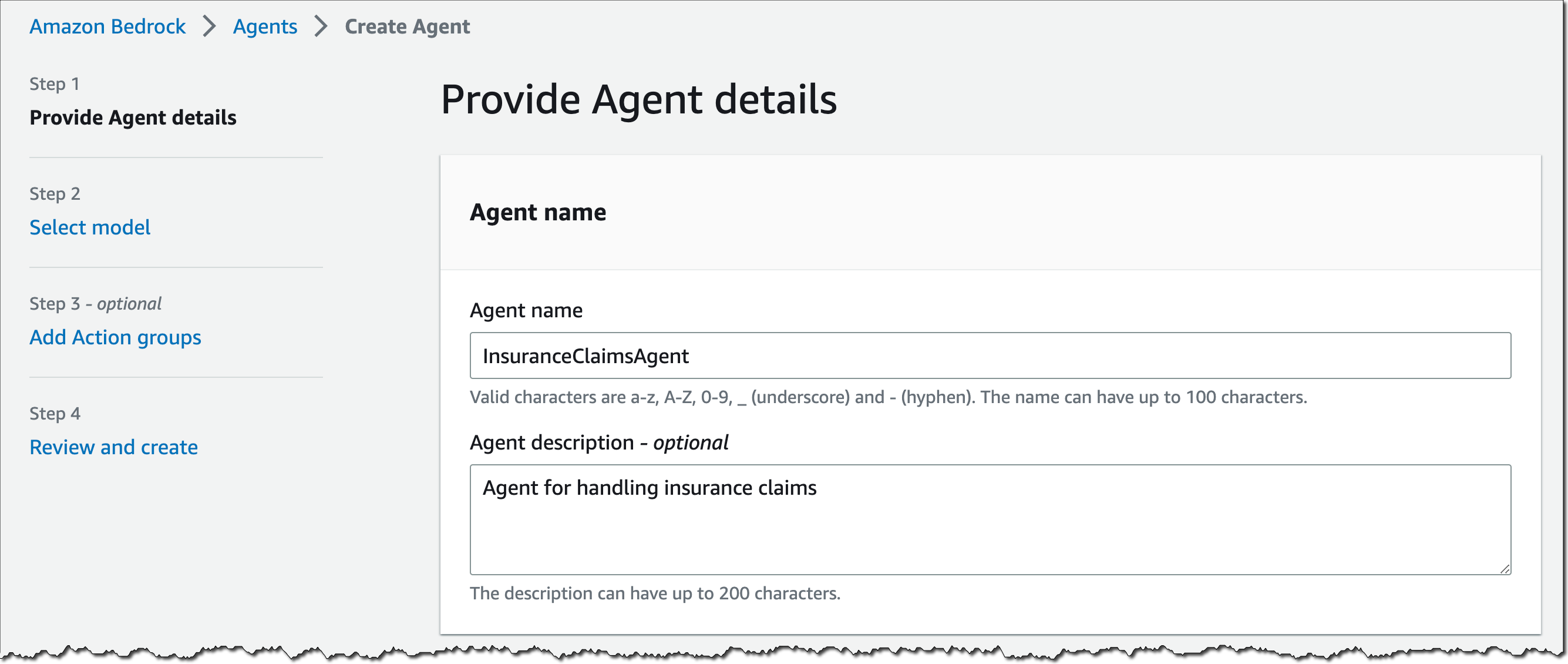
- 에이전트 이름, 설명(선택 사항), 에이전트가 추가 사용자 입력을 요청하도록 허용할지 여부, Amazon Simple Storage Service(S3) 및 AWS Lambda와 같은 다른 필수 서비스에 액세스할 권한을 에이전트에 부여하는 AWS Identity and Access Management (IAM) 서비스 역할 등의 에이전트 세부 정보를 제공합니다.

- Bedrock에서 사용 사례에 맞는 파운데이션 모델을 선택합니다. 여기서는 자연어로 에이전트에 지침을 제공합니다. 이 지침은 수행해야 할 작업과 수임해야 할 페르소나를 에이전트에 알려줍니다. 예를 들어 “너는 보험금 청구 처리와 대기 중인 서류의 관리를 지원하도록 설계된 에이전트야”라고 알려주는 겁니다.

- 조치 그룹을 추가합니다. 조치는 에이전트가 회사 시스템에 대한 API 직접 호출을 통해 자동으로 수행할 수 있는 작업입니다. 조치 그룹에는 일련의 조치가 정의되어 있습니다. 여기서는 그룹 내 모든 조치에 대한 API를 정의하는 API 스키마를 제공합니다. 또한 각 API의 비즈니스 로직을 나타내는 Lambda 함수도 제공해야 합니다. 예를 들어 ClaimManagementActionGroup이라는 조치 그룹을 정의해보겠습니다. 이 조치 그룹은 미결 청구 건의 목록을 가져와 각 청구 건의 미결 서류를 식별하고 보험 계약자에게 알림을 보냄으로써 보험금 청구를 관리합니다. 조치 그룹 설명에 이 정보를 기록해 두세요. FM은 이 정보를 사용하여 취해야 할 조치를 추론하고 결정합니다.
 예제 조치 그룹의 비즈니스 로직은 InsuranceClaimsLambda라는 Lambda 함수에 캡처되어 있습니다. 이 AWS Lambda 함수는
예제 조치 그룹의 비즈니스 로직은 InsuranceClaimsLambda라는 Lambda 함수에 캡처되어 있습니다. 이 AWS Lambda 함수는 open-claims,identify-missing-documents,send-reminders라는 API 직접 호출을 위한 메서드를 구현합니다. 다음은 예제의 OrderManagementLambda에서 발췌한 코드입니다.import json import time def open_claims(): ... def identify_missing_documents(parameters): ... def send_reminders(): ... def lambda_handler(event, context): responses = [] for prediction in event['actionGroups']: response_code = ... action = prediction['actionGroup'] api_path = prediction['apiPath'] if api_path == '/claims': body = open_claims() elif api_path == '/claims/{claimId}/identify-missing-documents': parameters = prediction['parameters'] body = identify_missing_documents(parameters) elif api_path == '/send-reminders': body = send_reminders() else: body = {"{}::{} is not a valid api, try another one.".format(action, api_path)} response_body = { 'application/json': { 'body': str(body) } } action_response = { 'actionGroup': prediction['actionGroup'], 'apiPath': prediction['apiPath'], 'httpMethod': prediction['httpMethod'], 'responseCode': response_code, 'responseBody': response_body } responses.append(action_response) api_response = {'response': responses} return api_responseOpenAPI 스키마 JSON 형식으로 API 스키마를 제공해야 한다는 점도 유의하세요. 예제 API 스키마 파일
insurance_claim_schema.json은 다음과 같습니다.{"openapi”: “3.0.0", "info": { "title": "Insurance Claims Automation API", "version": "1.0.0", "description": "APIs for managing insurance claims by pulling a list of open claims, identifying outstanding paperwork for each claim, and sending reminders to policy holders." }, "paths": { "/claims": { "get": { "summary": "Get a list of all open claims", "description": "Get the list of all open insurance claims. Return all the open claimIds.", "operationId": "getAllOpenClaims", "responses": { "200": { "description": "Gets the list of all open insurance claims for policy holders", "content": { "application/json": { "schema": { "type": "array", "items": { "type": "object", "properties": { "claimId": { "type": "string", "description": "Unique ID of the claim." }, "policyHolderId": { "type": "string", "description": "Unique ID of the policy holder who has filed the claim." }, "claimStatus": { "type": "string", "description": "The status of the claim. Claim can be in Open or Closed state" } } } } } } } } } }, "/claims/{claimId}/identify-missing-documents": { "get": { "summary": "Identify missing documents for a specific claim", "description": "Get the list of pending documents that need to be uploaded by policy holder before the claim can be processed. The API takes in only one claim id and returns the list of documents that are pending to be uploaded by policy holder for that claim. This API should be called for each claim id", "operationId": "identifyMissingDocuments", "parameters": [{ "name": "claimId", "in": "path", "description": "Unique ID of the open insurance claim", "required": true, "schema": { "type": "string" } }], "responses": { "200": { "description": "List of documents that are pending to be uploaded by policy holder for insurance claim", "content": { "application/json": { "schema": { "type": "object", "properties": { "pendingDocuments": { "type": "string", "description": "The list of pending documents for the claim." } } } } } } } } }, "/send-reminders": { "post": { "summary": "API to send reminder to the customer about pending documents for open claim", "description": "Send reminder to the customer about pending documents for open claim. The API takes in only one claim id and its pending documents at a time, sends the reminder and returns the tracking details for the reminder. This API should be called for each claim id you want to send reminders for.", "operationId": "sendReminders", "requestBody": { "required": true, "content": { "application/json": { "schema": { "type": "object", "properties": { "claimId": { "type": "string", "description": "Unique ID of open claims to send reminders for." }, "pendingDocuments": { "type": "string", "description": "The list of pending documents for the claim." } }, "required": [ "claimId", "pendingDocuments" ] } } } }, "responses": { "200": { "description": "Reminders sent successfully", "content": { "application/json": { "schema": { "type": "object", "properties": { "sendReminderTrackingId": { "type": "string", "description": "Unique Id to track the status of the send reminder Call" }, "sendReminderStatus": { "type": "string", "description": "Status of send reminder notifications" } } } } } }, "400": { "description": "Bad request. One or more required fields are missing or invalid." } } } } } }사용자가 에이전트에 작업을 완료하도록 요청하면, Bedrock은 에이전트에 대해 구성한 FM을 사용하여 조치 순서를 식별하고 해당 Lambda 함수를 올바른 순서로 간접적으로 호출하여 사용자가 요청한 작업을 해결합니다.
- 마지막 단계에서는 에이전트 구성을 검토하고 Create Agent(에이전트 생성)를 선택합니다.

- 축하합니다. Amazon Bedrock에서 첫 번째 에이전트를 만들었습니다.

Amazon Bedrock용 에이전트 배포
애플리케이션에 에이전트를 배포하려면 별칭을 만들어야 합니다. 그러면 Bedrock이 해당 별칭에 대한 버전을 자동으로 생성합니다.
- Bedrock 콘솔에서 에이전트를 선택한 다음 Deploy(배포)를 선택하고 Create(생성)를 선택하여 별칭을 생성합니다.

- 별칭 이름과 설명을 입력하고 새 버전을 생성할지 아니면 에이전트의 기존 버전을 이 별칭에 연결할지를 선택합니다.

- 그러면 에이전트 코드 및 구성의 스냅샷이 저장되고 별칭이 이 스냅샷 또는 버전과 연결됩니다. 별칭을 사용하여 에이전트를 애플리케이션에 통합할 수 있습니다.

이제 보험 에이전트를 테스트해보겠습니다. Bedrock 콘솔에서 바로 테스트할 수 있습니다.
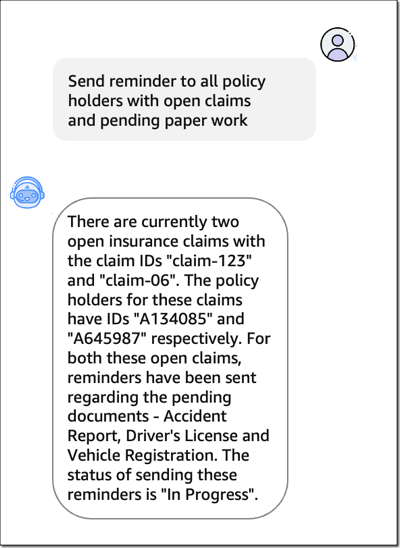
에이전트에 “미결 청구 건이 있고 대기 중인 서류 작업이 있는 모든 보험 계약자에게 알림을 보내줘”라고 요청해보겠습니다. FM으로 구동되는 에이전트가 어떻게 사용자 요청을 이해하고, 작업을 여러 단계(미결 보험금 청구 건 수집, 청구 ID 조회, 알림 전송)로 나누며, 해당 조치를 수행하는지 확인할 수 있습니다.
Amazon Bedrock용 에이전트는 생산성을 높이거나, 고객 서비스 경험을 개선하거나, DevOps 작업을 자동화하는 데 도움이 될 수 있습니다. 여러분이 어떤 사용 사례를 구현할지 기대됩니다.
 생성형 AI의 기초 알아보기
생성형 AI의 기초 알아보기
생성형 AI의 기초를 배우고 싶거나 고급 프롬프트 기법과 에이전트를 비롯하여 FM 관련 작업 방법을 알고 싶다면, DeepLearning.AI와의 협업을 통해 제가 AWS 동료 및 업계 전문가들과 함께 개발한 이 새로운 실습 과정을 확인해보세요.
대규모 언어 모델(LLM)을 사용한 생성형 AI는 LLM을 사용하여 생성형 AI 애플리케이션을 구축하는 방법을 배울 데이터 사이언티스트와 엔지니어를 위한 3주 온디맨드 과정입니다. Amazon Bedrock으로 구축을 시작하기에 완벽한 토대가 됩니다. 지금 등록하고 LLM을 사용한 생성형 AI를 사용해보세요.
지금 가입하여 Amazon Bedrock(미리보기)에 대해 자세히 알아보기
Amazon Bedrock은 현재 미리보기로 제공됩니다. 미리보기로 Amazon Bedrock용 에이전트에 액세스하려면 저희에게 문의하시기 바랍니다. 정기적으로 신규 고객에게 액세스 권한을 제공하고 있습니다. Amazon Bedrock에 대해 자세히 알아보려면 Amazon Bedrock 기능 페이지를 방문하고 가입하세요.
— Antje
추신: AWS는 더 나은 고객 경험을 제공하기 위해 콘텐츠 개선에 초점을 맞추고 있으며, 이를 위해서는 여러분의 피드백이 필요합니다. 간단한 설문조사를 통해 AWS 블로그에 대한 경험과 관련된 인사이트를 공유해 주세요. 이 설문조사는 외부 기업에서 주최하므로 링크가 AWS 웹사이트로 연결되지 않습니다. AWS는 AWS 개인정보 처리방침에 설명한 대로 사용자 정보를 처리합니다.