- ผลิตภัณฑ์›
- การวิเคราะห์
การวิเคราะห์บน AWS
ชุดความสามารถครบครันสำหรับทุกเวิร์กโหลดการวิเคราะห์ข้อมูล พร้อมการปรับแต่งเพื่อประสิทธิภาพด้านราคาและขนาด
ภาพรวม
AWS มอบชุดความสามารถที่ครอบคลุมสำหรับทุกเวิร์กโหลดการวิเคราะห์ AWS มอบประสิทธิภาพราคาและความสามารถในการปรับขนาดที่ไม่มีใครเทียบได้ด้วยการกำกับดูแลในตัว ตั้งแต่การประมวลผลข้อมูลและการวิเคราะห์ SQL ไปจนถึงการสตรีม การค้นหา และระบบธุรกิจอัจฉริยะ เลือกบริการที่สร้างขึ้นโดยเฉพาะที่ปรับให้เหมาะสมสำหรับภาระงานที่เฉพาะเจาะจง หรือปรับปรุงและจัดการข้อมูลและเวิร์กโฟลว์ของ AI ด้วย Amazon SageMaker ไม่ว่าคุณกำลังจะเริ่มต้นเส้นทางข้อมูลหรือต้องการประสบการณ์แบบผสานรวม AWS จะมอบความสามารถในการวิเคราะห์ที่เหมาะสมให้แก่คุณเพื่อช่วยให้คุณสามารถสร้างสรรค์ธุรกิจใหม่ด้วยข้อมูล
เพิ่มผลลัพธ์ทางธุรกิจที่จับต้องได้ด้วยการวิเคราะห์บน AWS
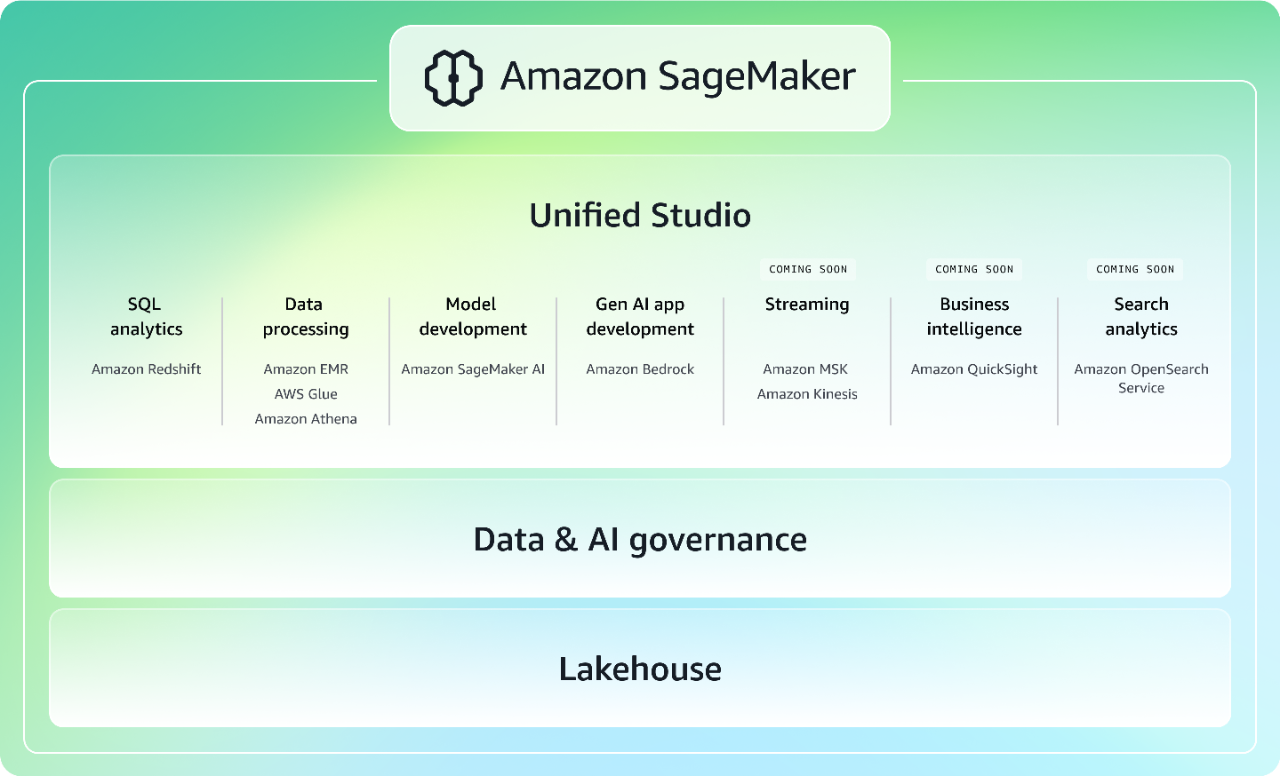
เร่งความเร็วข้อมูล การวิเคราะห์ และ AI ด้วยประสบการณ์แบบผสานรวม
Amazon SageMaker รุ่นถัดไปมอบประสบการณ์แบบผสานรวมสำหรับการวิเคราะห์และ AI พร้อมสิทธิ์แบบครบวงจรในการเข้าถึงข้อมูลทั้งหมดของคุณ โดยการรวมความสามารถของแมชชีนเลิร์นนิง (ML) และการวิเคราะห์ของ AWS ที่มีการนำไปใช้อย่างแพร่หลายเข้าไว้ด้วยกัน ทำงานร่วมกันและสร้างได้เร็วขึ้นจากสตูดิโอแบบครบวงจร โดยการใช้เครื่องมือ AWS ที่คุ้นเคยสำหรับการพัฒนาโมเดล การพัฒนาแอปพลิเคชัน AI ช่วยสร้าง การประมวลผลข้อมูล และการวิเคราะห์ SQL ที่เร่งให้เร็วขึ้นด้วย Amazon Q Developer ซึ่งเป็นผู้ช่วยที่เป็น AI ช่วยสร้างที่มึความสามารถสูงสุดสำหรับการพัฒนาซอฟต์แวร์ เข้าถึงข้อมูลทั้งหมดของคุณไม่ว่าจะเก็บไว้ใน Data Lake, คลังข้อมูล หรือแหล่งที่มาของข้อมูลจากภายนอก หรือแหล่งข้อมูลที่เชื่อมโยงกับส่วนกลาง โดยมีการกำกับดูแลในตัวเพื่อตอบโจทย์ความต้องการด้านความปลอดภัยขององค์กร เรียนรู้เพิ่มเติมเกี่ยวกับ SageMaker
เปิดใช้งานกลยุทธ์มัลติคลาวด์ด้วย AWS
AWS นำเสนอบริการวิเคราะห์ที่มีประสิทธิภาพที่ครอบคลุมซึ่งช่วยให้เข้าถึงและประมวลผลข้อมูลได้อย่างราบรื่นในสภาพแวดล้อมมัลติคลาวด์และไฮบริด คุณสามารถบรรลุความยืดหยุ่นนี้ผ่านการสอบถามแบบรวมส่วน การรวมข้อมูล การเคลื่อนย้ายข้อมูลที่ปลอดภัย และความเข้ากันได้กับมาตรฐานแบบเปิด ช่วยให้คุณสามารถรับข้อมูลเชิงลึกจากข้อมูลทั้งหมดของคุณโดยไม่คำนึงถึงที่ใดก็ตาม
Amazon Athena ช่วยให้คุณสามารถสืบค้นและรับข้อมูลเชิงลึกจากข้อมูลที่เก็บไว้ใน แหล่งข้อมูลภายนอกที่หลาก หลาย รวมถึง Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server และอื่น ๆ อีกมากมาย โดยไม่จำเป็นต้องคัดลอกหรือแปลงข้อมูล
AWS G lue ช่วยลดความยุ่งยากในการค้นพบ การจัดเตรียม และการรวมข้อมูลทั้งหมดของคุณในทุกขนาด ด้วยตัวเชื่อมต่อสำหรับแหล่งข้อมูลที่แตกต่างกันมากกว่า 100 แหล่งที่ครอบคลุมพื้นที่จัดเก็บข้อมูลบนคลาวด์ ฐานข้อมูล และบริการวิเคราะห์ การผสานรวม Zero-ETL ของ Glu e ทำให้การกลืนและทำซ้ำข้อมูลจากแอปพลิเคชันของบุคคลที่สามเช่น Salesforce, SAP, Facebook Ads และ Instagram Ads เข้าไปในบ้านทะเลสาบ AWS, ทะเลสาบข้อมูล และคลังข้อมูลของคุณได้โดยตรง AWS Glue ยังนำเสนอการทำงานร่วมกันของข้อมูลผ่านการสนับสนุนสำหรับมาตรฐานแบบเปิด เช่น Apache Hive, Apache Parquet และ Apache Iceberg
Amazon SageMaker รุ่นถัดไปสร้างขึ้นบนสถาปัตยกรรมทะเลสาบข้อมูลแบบเปิดให้การเข้าถึงทะเลสาบข้อมูลและคลังข้อมูลบน AWS รวมทั้งแหล่งข้อมูลแบบรวมกลุ่มเช่น Google BigQuery และ Snowflake สถาปัตยกรรมบ้านทะเลสาบนี้เข้ากันได้กับ Apache Iceberg อย่างเต็มที่ ทำให้คุณมีความยืดหยุ่นในการเข้าถึงและสืบค้นข้อมูลในสถานที่โดยใช้เครื่องมือและเครื่องยนต์ที่รองรับ Iceberg
การใช้ประโยชน์จากการวิเคราะห์สำหรับมนุษย์และ AI
การวิเคราะห์พลังงานในขนาดด้วยบริการที่สร้างขึ้นโดยเฉพาะสำหรับการจัดเก็บ สืบค้นสตรีม การประมวลผล และการควบคุมข้อมูล จาก Open Table Formats (OTF) ไปจนถึงโครงสร้างพื้นฐานของตัวแทน AWS กำลังพัฒนาเครื่องมือวิเคราะห์และแอปพลิเคชันสำหรับภูมิทัศน์ของการวิเคราะห์ที่เปลี่ยนแปลงอย่างรวดเร็ว ในเซสชันนี้ดูว่า AWS นำเสนอโซลูชันที่เหมาะสมที่สุดที่สร้างขึ้นสำหรับทั้งผู้ใช้มนุษย์และเวิร์กโฟลว์ตัวแทนได้อย่างไร
บริการ
|
หมวดหมู่การวิเคราะห์
|
คำอธิบาย
|
บริการและความสามารถ AWS
|
|---|---|---|
|
การสตรีม
|
สร้าง ปรับขนาด และใช้งานไปป์ไลน์และแอปพลิเคชันแบบเรียลไทม์โดยไม่ต้องรับภาระในการจัดการโครงสร้างพื้นฐาน |
|
|
Data lakehouse, คลังข้อมูล, Data Lake
|
เข้าถึงและวิเคราะห์ข้อมูลทั้งหมดของคุณใน Data Lakehouse คลังข้อมูล และ Data Lake |
|
|
การประมวลผลข้อมูล
|
วิเคราะห์ จัดเตรียม และรวมข้อมูลสำหรับการวิเคราะห์และ AI โดยใช้เฟรมเวิร์กโอเพนซอร์ส |
|
|
ระบบธุรกิจอัจฉริยะ
|
สร้าง ค้นพบ และแบ่งปันข้อมูลเชิงลึกที่มีความหมายผ่านแดชบอร์ดแบบโต้ตอบที่ทันสมัย รายงานที่สมบูรณ์แบบสำหรับพิกเซล การสืบค้นภาษาธรรมชาติ และการวิเคราะห์แบบฝังตัว |
|
|
การวิเคราะห์การค้นหา
|
ปลดล็อกการค้นหา การเฝ้าติดตาม และการวิเคราะห์ข้อมูลธุรกิจและการปฏิบัติงานแบบเรียลไทม์ได้อย่างปลอดภัย |
|
|
การกำกับดูแลข้อมูลและ AI
|
แคตตาล็อก ค้นพบ แบ่งปัน และควบคุมข้อมูลที่จัดเก็บไว้ใน AWS ในสถานที่ และแหล่งที่มาของบุคคลที่สาม |
ผลกระทบทางเศรษฐกิจโดยรวมของ AWS Modern Data Strategy
การประหยัดต้นทุนและผลประโยชน์ทางธุรกิจที่ขับเคลื่อนโดย Amazon Web Services Modern Data Strategy ตามที่รายงานเอาไว้โดย Forrester
สถิติ
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้