- Generative AI›
- Amazon Bedrock›
- Knowledge Bases
Amazon Bedrock Knowledge Bases
With Amazon Bedrock Knowledge Bases, you can give foundation models and agents contextual information from your company’s private data sources to deliver more relevant, accurate, and customized responses
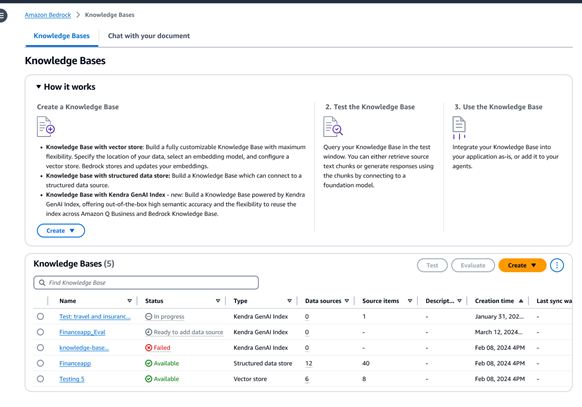
Fully managed support for end-to-end RAG workflow
To equip foundation models (FMs) with up-to-date and proprietary information, organizations use Retrieval Augmented Generation (RAG), a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. Amazon Bedrock Knowledge Bases is a fully managed capability with in-built session context management and source attribution that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows. You can also ask questions and summarize data from a single document, without setting up a vector database. If your data contains structured sources, Amazon Bedrock Knowledge Bases provides a built-in managed natural language to structured query language solution for generating a query command to retrieve the data, without having to move them to another store.
Securely connect FMs and agents to data sources
If you have unstructured data sources, Amazon Bedrock Knowledge Bases automatically fetches data from sources such as Amazon Simple Storage Service (Amazon S3), and Confluence, Salesforce, SharePoint, or Web Crawler, in preview. In addition, you also receive programmatic document ingestion to enable customers to ingest streaming data or data from unsupported sources. Once the content is ingested, Amazon Bedrock Knowledge Bases converts it into blocks of text, the text into embeddings, and stores the embeddings in your vector database. You can choose from multiple supported vector stores, including Amazon Aurora, Amazon Opensearch Serverless, Amazon Neptune Analytics, MongoDB, Pinecone, and Redis Enterprise Cloud. You can also choose to connect to an Amazon Kendra hybrid search index for managed retrieval.
Using Amazon Bedrock Knowledge Bases, you can also connect to your structured data stores to generate grounded responses. This can be especially useful when you have source material like transactional details which are stored in data warehouses, and datalakes. Amazon Bedrock Knowledge Bases uses Natural Language to SQL to convert queries to SQL commands and execute the commands to retrieve the data, without needing to move them from your source.
Customize Amazon Bedrock Knowledge Bases to deliver accurate responses at runtime
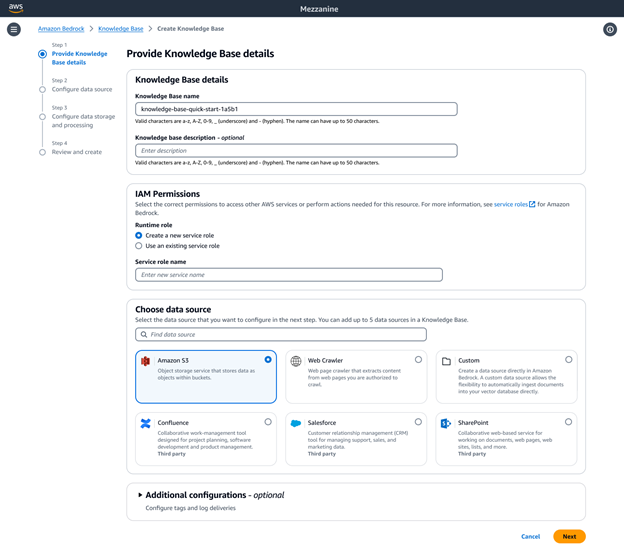
With Amazon Bedrock Knowledge Bases as your fully managed RAG solution, you have the flexibility to customize and improve retrieval accuracy. For unstructured data sources containing multimodal data such as images and visually rich documents with complex layouts (e.g., documents containing tables, figures, charts, and diagrams), you can configure Knowledge Bases to parse, analyze, and extract meaningful insights. You can choose Bedrock Data Automation or foundation models as the parser. This enables seamless processing of complex multimodal data, allowing you to build highly accurate GenAI applications.
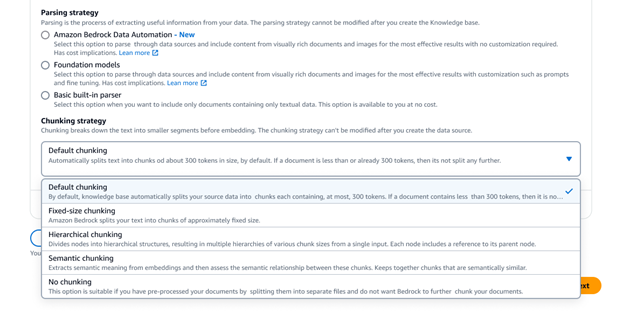
Amazon Bedrock Knowledge Bases offers a variety of advanced data chunking options including semantic, hierarchical, and fixed size chunking. For full control, you can also write your own chunking code as a Lambda function, and even use off-the-shelf components from frameworks like LangChain and LlamaIndex. If you choose Amazon Neptune Analytics as a vector store, Amazon Bedrock Knowledge Bases automatically creates embeddings, and graphs that link related content across your data sources. Bedrock Knowledge Bases leverages these content relationships with GraphRAG to improve the accuracy of retrieval, enabling more comprehensive, relevant and explainable responses to end users.
Retrieve data and augment prompts
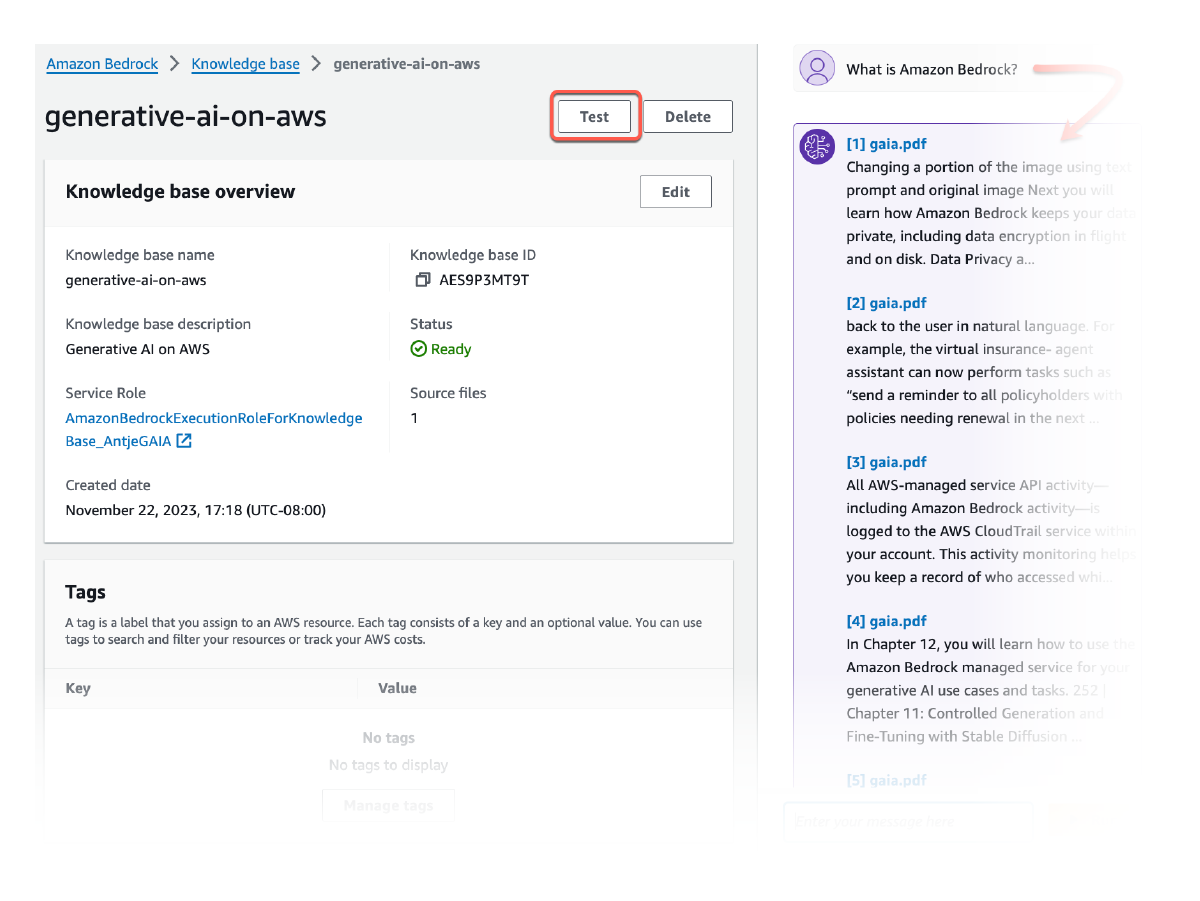
Using Retrieve API, you can fetch relevant results for a user query from knowledge bases, including visual elements such as images, diagrams, charts, tables, audio and video content, or structured data from databases when applicable. The RetrieveAndGenerate API goes one step further by directly using the retrieved multimodal results to augment the FM prompt and return the response. You can also choose to provide filters or use FM to generate implicit filters to restrict the returned results to only the relevant content. Amazon Bedrock Knowledge Bases offer reranker models to improve the relevance of retrieved document chunks across text, visual, and multimedia content.
Provide source attribution
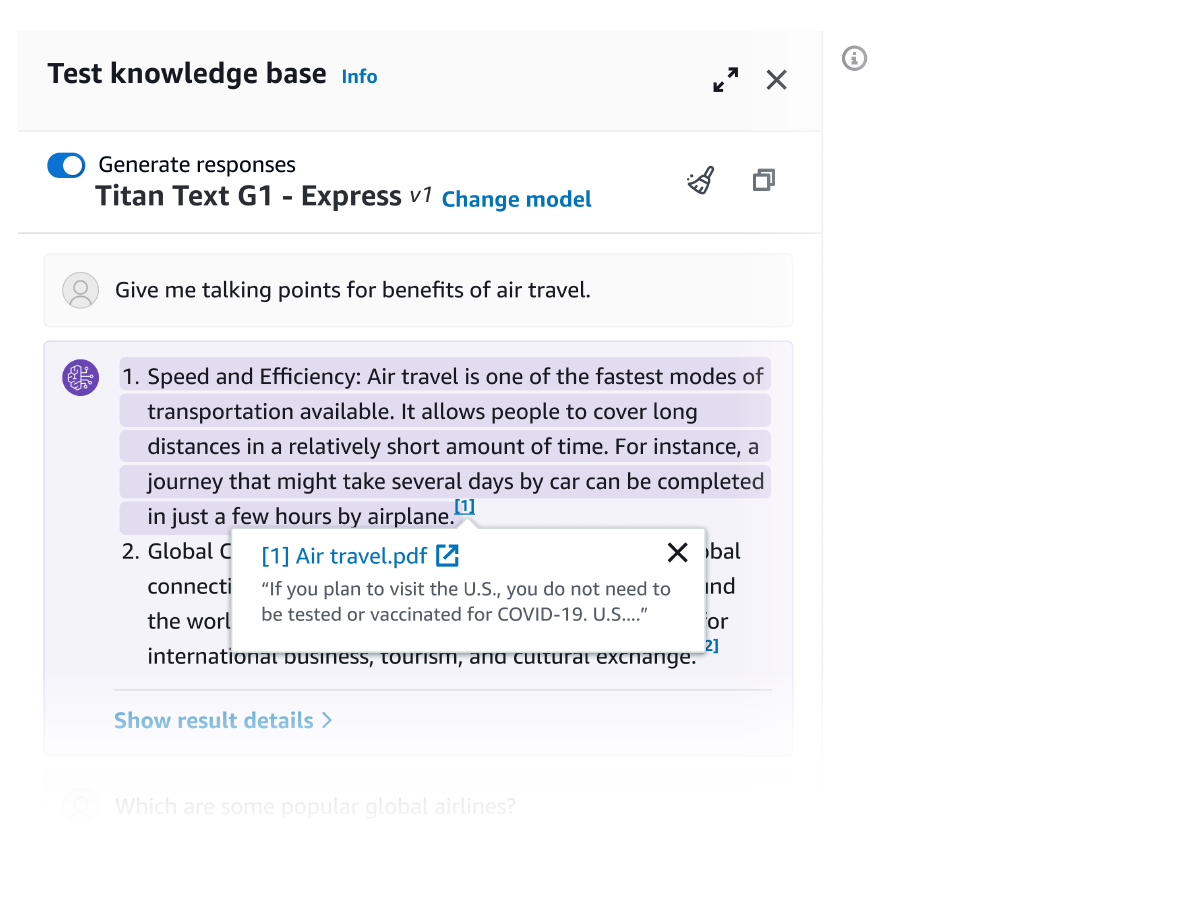
All the information retrieved from Amazon Bedrock Knowledge Bases is provided with citations (which also includes visuals) to improve transparency and minimize hallucinations.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages