亚马逊AWS官方博客
利用 Amazon Glue、Amazon Kinesis Data Streams、Amazon DynamoDB 和 Amazon QuickSight 的零售无服务器运营数据湖
解决方案概览
在这篇博文中,我们创建了一个端到端管道,用于摄取、存储、处理、分析及可视化订单、库存和发货更新等运营数据。我们使用以下 AWS 服务作为关键组件:
- Kinesis Data Streams,用于从各种系统实时摄取所有运营数据
- DynamoDB、Amazon Aurora 和 Amazon Simple Storage Service (Amazon S3),用于存储数据
- AWS Glue DataBrew,用于清理和转换数据
- AWS Glue 爬网程序,用于编录数据
- Athena,用于查询处理后的数据
- QuickSight 控制面板,用于提供有关各种运营指标的见解
下图展示了该解决方案的架构。

数据管道由摄取、存储、处理、分析和最终可视化数据几个阶段组成,我们将在以下各部分中更详细地讨论这些阶段。
数据摄取
从 Web 应用程序、移动应用程序和联网设备等多个来源实时摄取订单和库存数据到 Kinesis Data Streams 中。Kinesis Data Streams 是一种可大规模扩展且持久的实时数据流服务。Kinesis Data Streams 每秒可以连续从数十万个来源(如 Web 应用程序、数据库事件、库存交易和支付交易)中捕获数千兆字节的数据。电子商务应用程序和移动应用程序等前端系统会在商品添加到购物车或创建订单后立即摄取订单数据。当订单状态发生变化时,OMS 会摄取订单。OMS、商店和第三方供应商将库存更新摄取到数据流中。
为了模拟订单,计划的 Amazon CloudWatch 事件每分钟触发一次 AWS Lambda 函数,以将订单摄取到数据流中。此函数模拟典型的订单管理系统生命周期(订单创建、计划、发布、发货和交付)。同样,CloudWatch 事件会触发第二个 Lambda 函数,以生成库存更新。此函数模拟不同的库存更新,例如从 OMS 或第三方供应商等系统创建的采购订单。在生产环境中,这些数据将来自前端应用程序和集中订单管理系统。
数据存储
有两种类型的数据:热数据和冷数据。热数据由前端应用程序(如 Web 应用程序、移动应用程序和联网设备)使用。以下是热数据的一些示例用例:
- 当客户浏览商品时,必须显示商品的实时供货情况
- 客户与 Alexa 交互以了解订单状态
- 与客户交互的呼叫中心座席需要知道客户订单的状态或发货详情
使用这些数据的系统、API 和设备需要在交易发生后的几秒钟或几毫秒内获得数据。
冷数据用于长期分析,例如一段时间内的订单;各渠道的订单;订单最多的前 10 大商品;或者各商品、仓库或商店的计划库存与可用库存。
对于此解决方案,我们将订单热数据存储在 DynamoDB 中。DynamoDB 是一种完全托管式 NoSQL 数据库,可在任何规模下提供个位数毫秒级性能。Lambda 函数处理 Kinesis 数据流中的记录并将其存储在 DynamoDB 表中。
库存热数据存储在 Amazon Aurora MySQL 兼容版数据库中。库存是交易数据,需要高度一致性,以便客户在下单时不会被过度承诺或承诺不足。Aurora MySQL 是一种完全托管式数据库,速度最高达到标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。它可以实现商用数据库的安全性、可用性和可靠性,而成本只有商用数据库的十分之一。
Amazon S3 是一种对象存储,旨在从任何地方存储和检索任意数量的数据。它是一项简单的存储服务,以极低的成本提供业界领先的耐用性、可用性、性能、安全性以及几乎无限的可扩展性。订单和库存冷数据存储在 Amazon S3 中。
Amazon Kinesis Data Firehose 从 Kinesis 数据流中读取数据并将其存储在 Amazon S3 中。Kinesis Data Firehose 是将流数据加载到数据存储和分析工具的最简单方法。它可以捕获、转换流数据并将其加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service 和 Splunk 中,从而实现近实时分析。
数据处理
数据处理阶段包括清理、准备和转换数据,以帮助下游分析应用程序轻松查询数据。每个前端系统可能有不同的数据格式。在数据处理阶段,数据被清理并转换为通用的规范形式。
对于此解决方案,我们使用 DataBrew 清理订单并将其转换为通用的规范形式。DataBrew 是一种可视化数据准备工具,它使数据分析师和数据科学家可通过交互点击式可视化界面轻松准备数据,而无需编写代码。DataBrew 提供了 250 多种内置转换,无需编写代码即可合并、透视和调换数据。DataBrew 中的清理和转换步骤称为配方。计划的 DataBrew 作业将配方应用于 S3 存储桶中的数据,并将输出存储在另一个存储桶中。
AWS Glue 爬网程序可以在 AWS Glue 数据目录中访问数据存储、提取元数据和创建表定义。您可以调度爬网程序来抓取转换后的数据并创建或更新数据目录。AWS Glue 数据目录是您的永久性元数据存储。这是一项托管式服务,允许您在 AWS Cloud 中存储、批注和共享元数据,就像在 Apache Hive 元存储中一样。我们使用爬网程序在数据目录中填充表。
数据分析
我们可以使用 Athena 来查询 S3 存储桶中的订单和库存数据。Athena 是一种交互式查询服务,可使用标准 SQL 轻松分析 Amazon S3 中的数据。Athena 是一种无服务器服务,因此您无需管理任何基础设施,而且只需为所运行的查询付费。视图是在 Athena 中创建的,可供诸如 QuickSight 之类的商业智能 (BI) 服务使用。
数据可视化
我们使用 QuickSight 生成控制面板。QuickSight 是一种可扩展、无服务器且可嵌入的 BI 服务,由 ML 提供支持,专为云而构建。借助 QuickSight,您可以轻松创建和发布包含基于 ML 的见解的交互式 BI 控制面板。
QuickSight 还具有预测订单、检测订单中的异常情况以及提供基于机器学习的见解的功能。我们可以创建分析,例如一段时间内的订单、按渠道划分的订单、订单最多的前 10 大位置或订单履行时间表(从订单创建到订单交付所用的时间)。
演练概览
要实施该解决方案,我们需要完成以下几大步骤:
- 使用 AWS CloudFormation 创建解决方案资源。
- 连接到库存数据库。
- 用表加载库存数据库。
- 使用 Amazon Virtual Private Cloud (Amazon VPC) 创建 VPC 端点。
- 在默认 VPC 上为 Amazon S3 创建网关端点。
- 通过 Amazon EventBridge 启用 CloudWatch 规则以摄取数据。
- 使用 AWS Glue 转换数据。
- 使用 QuickSight 可视化数据。
先决条件
完成以下必备步骤:
- 如果尚未创建 AWS 账户,请创建。
- 如果以前从未在此账户中使用过 QuickSight,请注册。要在 QuickSight 中使用预测功能,请注册企业版。
使用 AWS CloudFormation 创建资源
要启动提供的 CloudFormation 模板,请完成以下步骤:
- 选择 Launch Stack(启动堆栈):

- 选择 Next(下一步)。
- 对于 Stack name(堆栈名称),输入名称。
- 提供以下参数:
- 保存数据湖所有数据的 S3 存储桶的名称。
- 保存库存表的数据库的名称。
- 数据库用户名。
- 数据库密码。
- 输入要分配给堆栈的任何标记,然后选择 Next(下一步)。
- 选中确认复选框,然后选择 Create stack(创建堆栈)。
堆栈需要 5-10 分钟才能完成。
在 AWS CloudFormation 控制台上,可以导航到堆栈的 Outputs(输出)选项卡以查看您创建的资源。

如果打开创建的 S3 存储桶,则可以观察其文件夹结构。堆栈创建过去 7 天的示例订单数据。

连接到库存数据库
要在查询编辑器中连接到数据库,请完成以下步骤:
- 在 Amazon RDS 控制台上,选择在其中部署堆栈的区域。

- 在导航窗格中,选择 Query Editor(查询编辑器)。
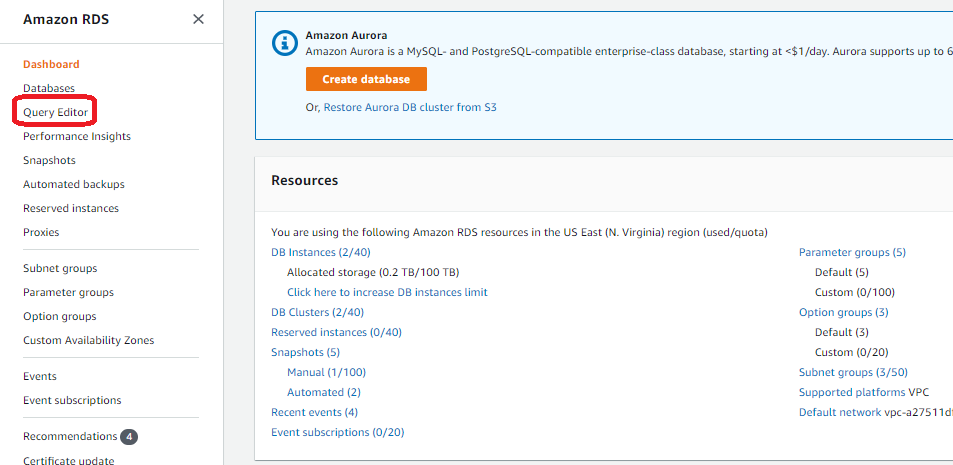
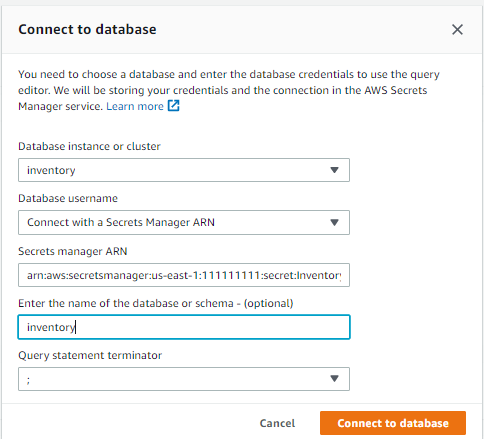
如果之前未连接到过此数据库,则会打开 Connect to database(连接到数据库)页面。 - 对于 Database instance or cluster(数据库实例或集群),请选择您的数据库。
- 对于 Database username(数据库用户名),请选择 Connect with a Secrets Manager ARN(使用 Secrets Manager ARN 连接)。
堆栈创建期间提供的数据库用户名和密码存储在 AWS Secrets Manager 中。或者,您可以选择 Add new database credentials(添加新的数据库凭据),然后输入您在创建堆栈时提供的数据库用户名和密码。 - 对于 Secrets Manager ARN,输入 CloudFormation 堆栈输出中
InventorySecretManager键的值。 - 或者,输入数据库的名称。
- 单击 Connect to database(连接到数据库)。
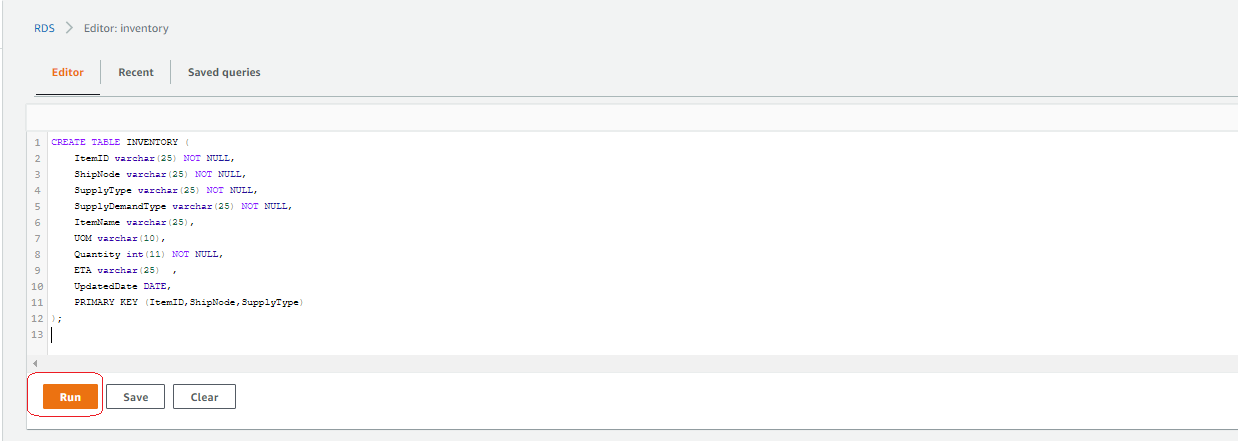
用表加载库存数据库
在查询编辑器中输入以下 DDL 语句,然后选择 Run(运行):
创建 VPC 端点
要创建 VPC 端点,请完成以下步骤:
- 在 Amazon VPC 控制台上,选择 VPC Dashboard(VPC 控制面板)。
- 在导航窗格中选择 Endpoints(端点)。
- 选择 Create Endpoint(创建端点)。

- 对于 Service category(服务类别),选择 AWS services(AWS 服务)。
- 对于 Service name(服务名称),搜索
rds并选择以rds-data结尾的服务名称。 - 对于 VPC,请选择默认 VPC。

- 将其余设置保留为默认值,然后选择 Create endpoint(创建端点)。
为 Amazon S3 创建网关端点
要创建网关端点,请完成以下步骤:
- 在 Amazon VPC 控制台上,选择 VPC Dashboard(VPC 控制面板)。
- 在导航窗格中选择 Endpoints(端点)。
- 选择 Create Endpoint(创建端点)。
- 对于 Service category(服务类别),选择 AWS services(AWS 服务)。
- 对于 Service name(服务名称),搜索
S3并选择类型为 Gateway(网关)的服务名称。 - 对于 VPC,请选择默认 VPC。
- 对于 Configure route tables(配置路由表),选择默认路由表。
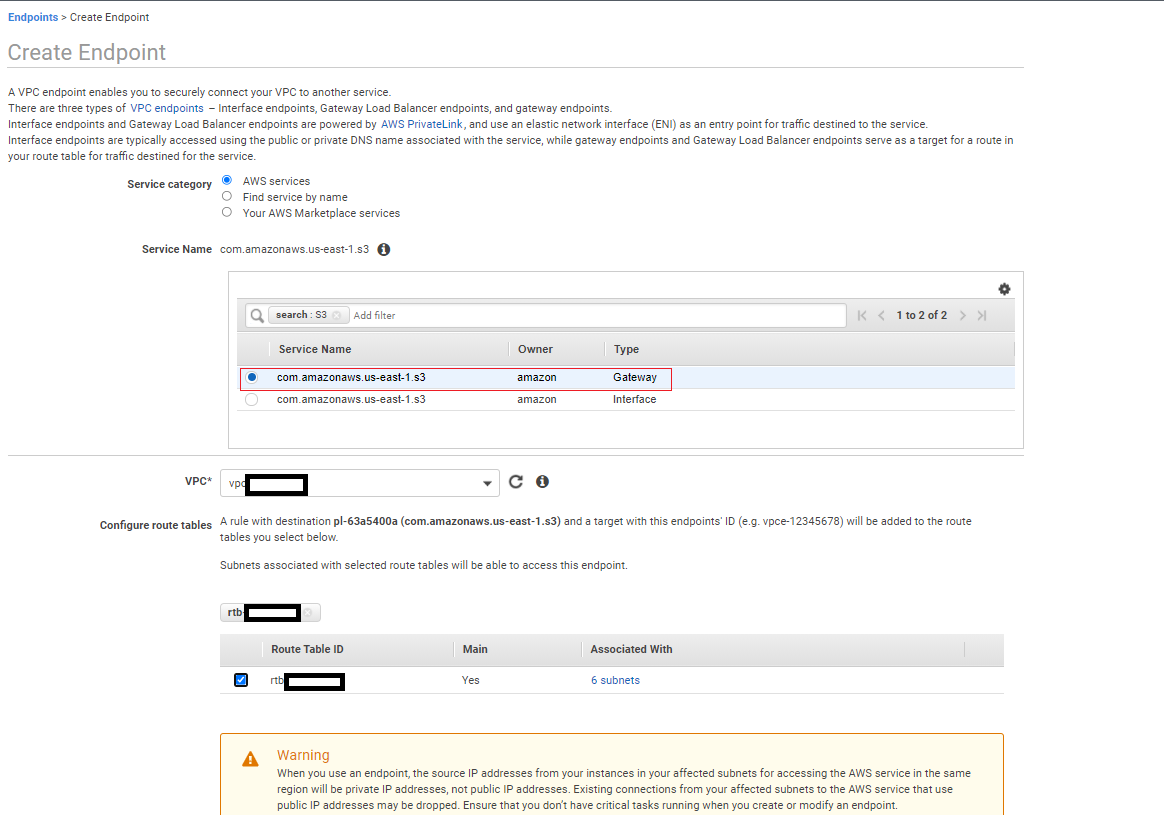
- 将其余设置保留为默认值,然后选择 Create endpoint(创建端点)。
等待网关端点和 VPC 端点状态都变为 Available(可用)。

启用 CloudWatch 规则以摄取数据
我们通过 CloudFormation 模板创建了两条 CloudWatch 规则,用于将订单和库存数据摄取到 Kinesis Data Streams。要通过 EventBridge 启用规则,请完成以下步骤:
- 在 CloudWatch 控制台导航窗格中的 Events(事件)下,选择 Rules(规则)。
- 确保您位于创建堆栈的区域中。
- 选择 Go to Amazon EventBridge(前往 Amazon EventBridge)。

- 选择规则
Ingest-Inventory-Update-Schedule-Rule,然后选择 Enable(启用)。 - 选择规则
Ingest-Order-Schedule-Rule,然后选择 Enable(启用)。

5-10 分钟后,Lambda 函数开始将订单和库存更新摄取到各自的流。您可以检查 S3 存储桶 orders-landing-zone 和 inventory-landing-zone,以确认正在填充数据。
执行数据转换
我们的 CloudFormation 堆栈包括一个 DataBrew 项目、一个每 5 分钟运行一次的 DataBrew 作业,以及两个 AWS Glue 爬网程序。要使用我们的 AWS Glue 资源执行数据转换,请完成以下步骤:
- 在 DataBrew 控制台的导航窗格中,选择 Projects(项目)。
- 选择项目
OrderDataTransform。

您可以在此页面上查看该项目及其配方。

- 在导航窗格中,选择 Jobs(作业)。
- 查看作业状态以确认其已完成。

- 在 AWS Glue 控制台的导航窗格中,选择 Crawlers(爬网程序)。
爬网程序会抓取转换后的数据并更新数据目录。 - 查看两个爬网程序的状态,它们每 15 分钟运行一次。

- 在导航窗格中选择 Tables(表)以查看爬网程序创建的两个表。
如果没有看到这些表,可以手动运行爬网程序来创建它们。
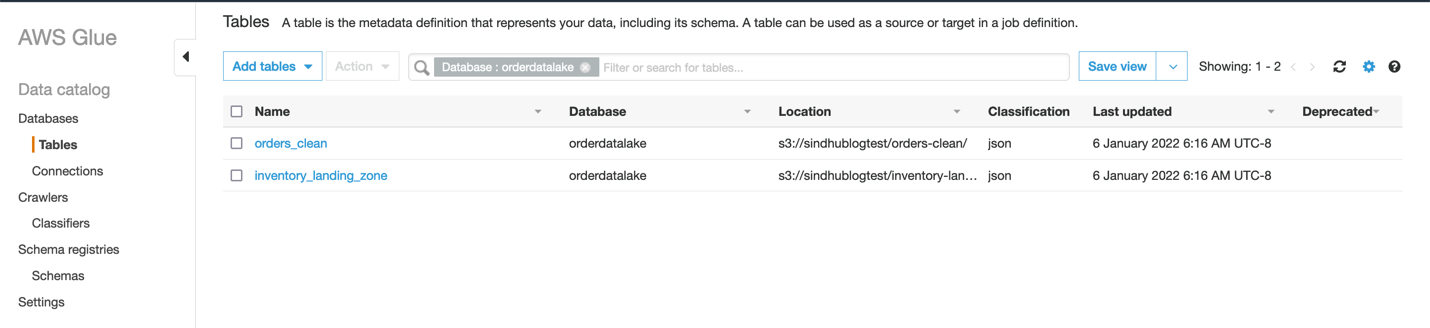
您可以使用 Athena 查询表中的数据。 - 在 Athena 控制台上,选择 Query editor(查询编辑器)。
如果尚未创建查询结果位置,系统会提示您先创建。 - 选择 View settings(查看设置)或选择 Settings(设置)选项卡。

- 选择 Manage(管理)。
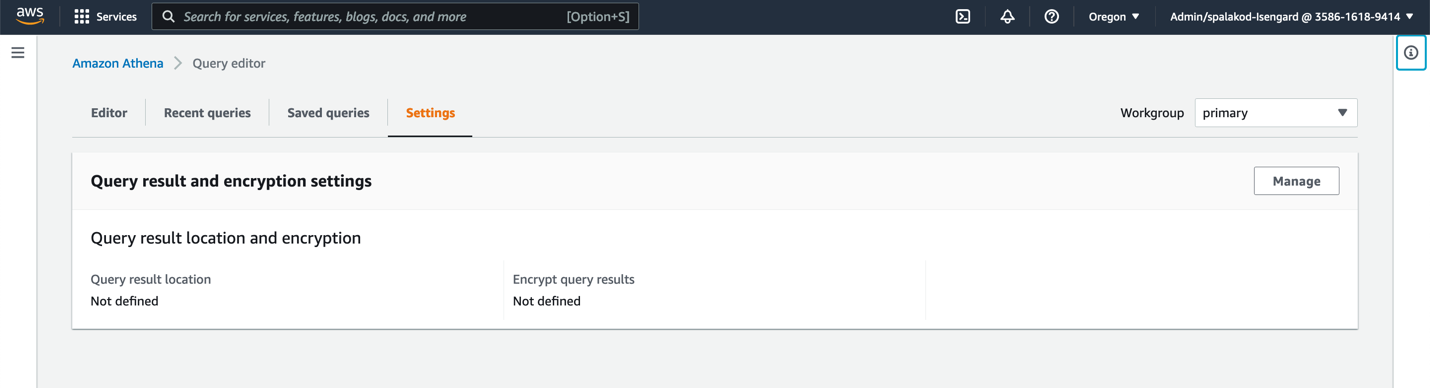
- 选择用于存储结果的 S3 存储桶,然后选择 Choose(选择)。

- 在导航窗格中选择 Query editor(查询编辑器)。

- 选择任一表(右键单击),然后选择 Preview Table(预览表)以查看表内容。

可视化数据
如果以前从未在此账户中使用过 QuickSight,请完成先决条件步骤以注册 QuickSight。要使用 QuickSight 的 ML 功能(例如预测),请按照本文档中的步骤注册企业版。
注册 QuickSight 时,请确保使用创建 CloudFormation 堆栈的同一区域。
向 QuickSight 授予权限
要使数据可视化,必须先向 QuickSight 授予访问数据的相关权限。
- 在 QuickSight 控制台的 Admin(管理员)下拉菜单中,选择 Manage QuickSight(管理 QuickSight)。

- 在导航窗格中,选择 Security & permissions(安全和权限)。
- 在 QuickSight access to AWS services(QuickSight 访问 AWS 服务的权限)下,选择 Manage(管理)。

- 选择 Amazon Athena。
- 选择 Amazon S3 以编辑 QuickSight 对 S3 存储桶的访问权限。
- 选择您在堆栈创建期间指定的存储桶(就这篇博文而言,为
operational-datalake)。 - 选择 Finish(完成)。

- 选择 Save(保存)。
准备数据集
要准备数据集,请完成以下步骤:
- 在 QuickSight 控制台的导航窗格中,选择 Datasets(数据集)。
- 选择 New dataset(新建数据集)。
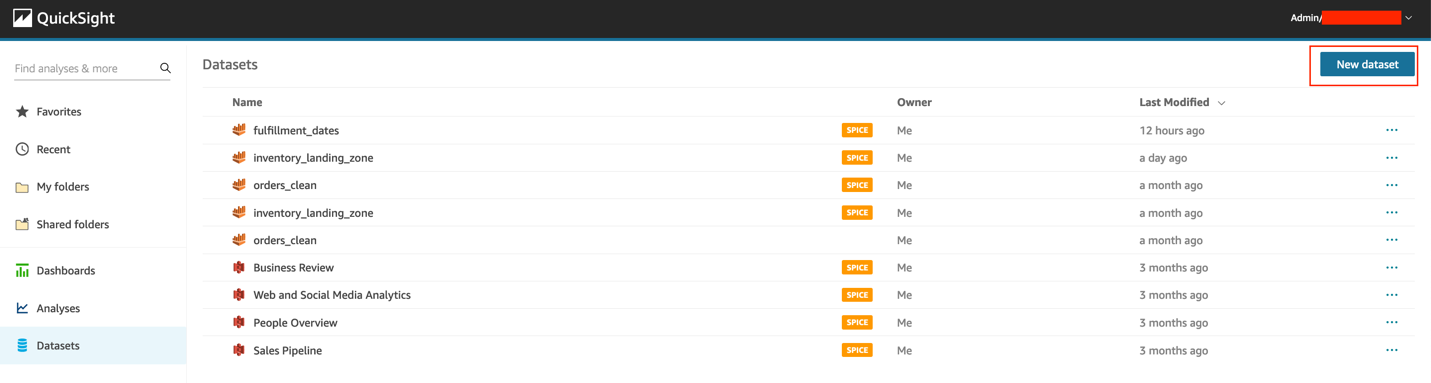
- 选择 Athena。
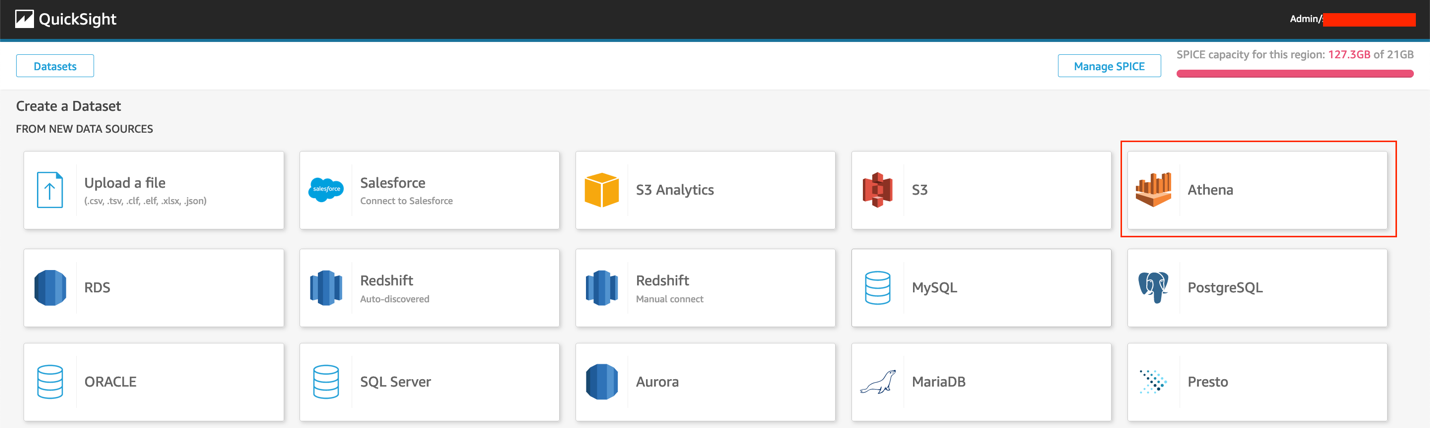
- 对于 Data source name(数据源名称),输入
retail-analysis。 - 选择 Validate connection(验证连接)。
- 验证连接后,选择 Create data source(创建数据源)。

- 对于 Database(数据库),选择
orderdatalake。 - 对于 Tables(表),选择
orders_clean。 - 选择 Edit/Preview data(编辑/预览数据)。

- 对于 Query mode(查询模式),选择 SPICE。
SPICE(超快速、并行、内存中计算引擎)是 QuickSight 使用的强大内存中引擎。

- 选择
orderdatetime字段(右键单击),选择 Change data type(更改数据类型),然后选择 Date(日期)。
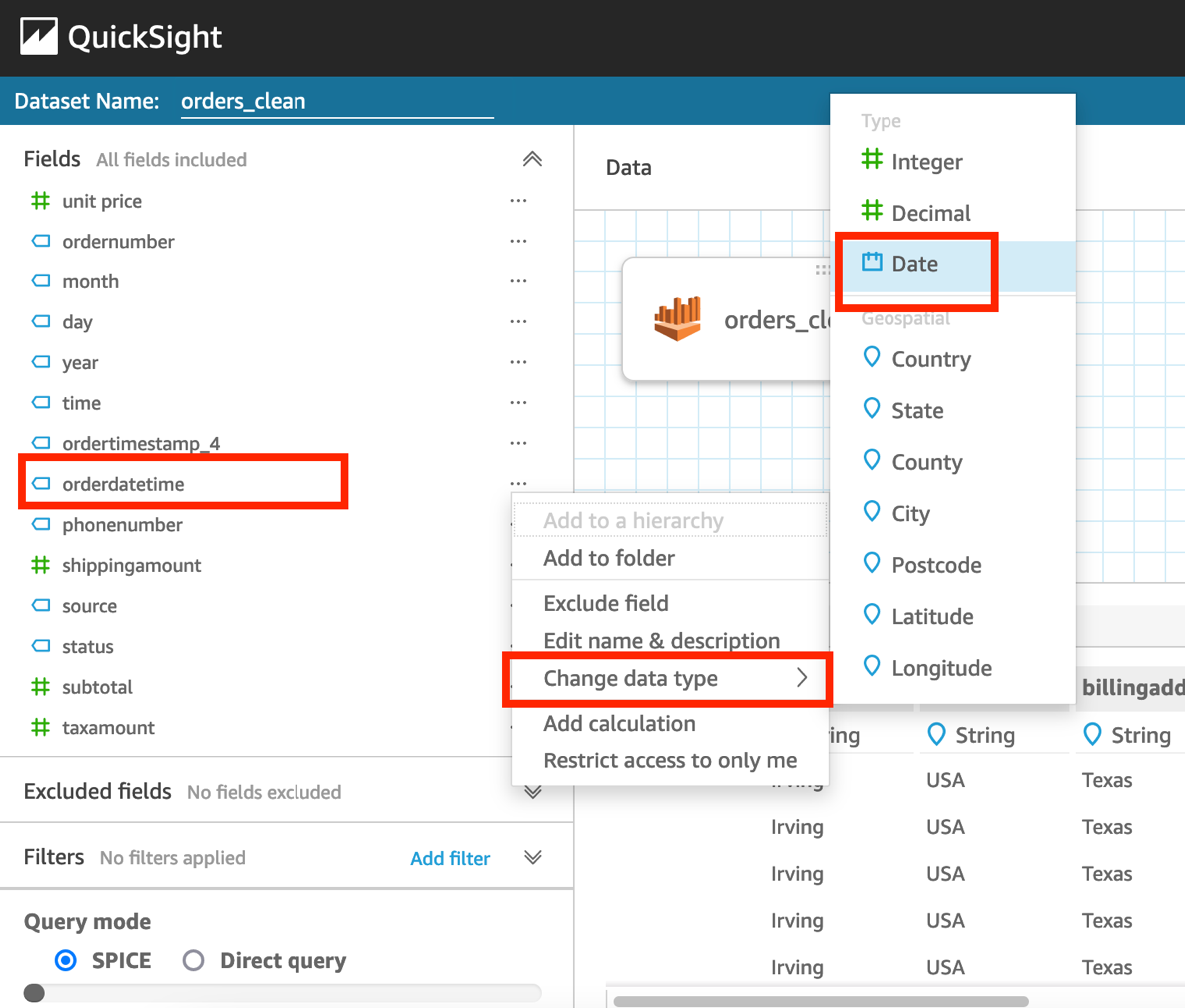
- 以
MM/dd/yyyy HH:mm:ss格式输入日期。 - 选择 Validate(验证)和 Update(更新)。

- 将以下字段的数据类型更改为 QuickSight 地理空间数据类型:
- billingaddress.zipcode — 邮编
- billingaddress.city — 城市
- billingaddress.country — 国家/地区
- billingaddress.state – 州/省/直辖市
- shippingaddress.zipcode — 邮编
- shippingaddress.city — 城市
- shippingaddress.country — 国家/地区
- shippingaddress.state — 州/省/直辖市
- 选择 Save & publish(保存并发布)。
- 选择 Cancel(取消)退出此页面。

让我们为 Athena 表inventory_landing_zone创建另一个数据集。 - 按照步骤 1-7 创建新数据集。对于 Table(表)选项,选择
inventory_landing_zone。 - 选择 Edit/Preview data(编辑/预览数据)。
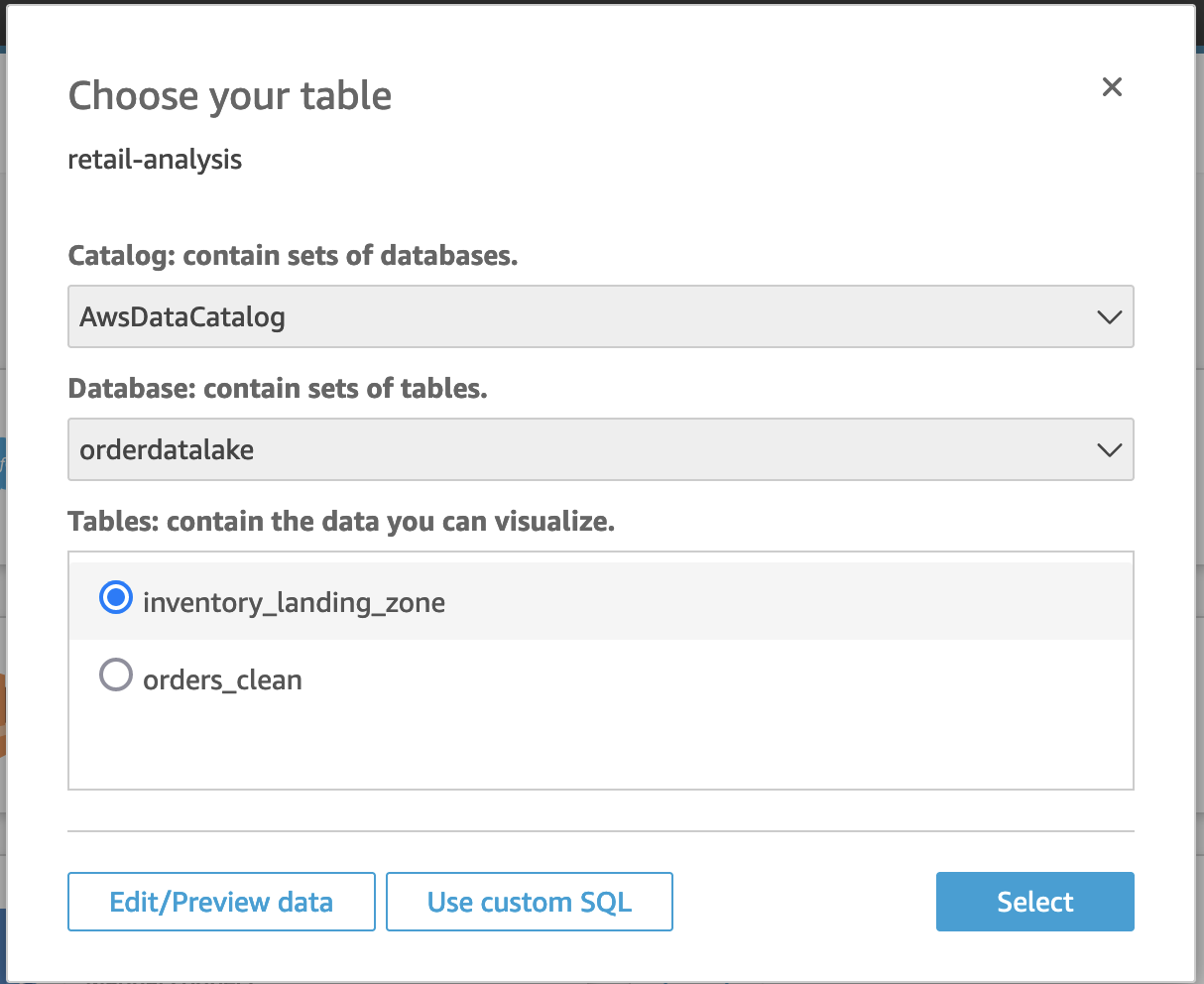
- 对于 Query mode(查询模式),选择 SPICE。
- 选择 Save & publish(保存并发布)。
- 选择 Cancel(取消)退出此页面。

这两个数据集现在都应列在 Datasets(数据集)页面上。

- 选择每个数据集,然后选择 Refresh now(立即刷新)。

- 选择 Full refresh(完全刷新),然后选择 Refresh(刷新)。

要设置计划刷新,请选择 Schedule a refresh(计划刷新)并提供计划详情。

创建分析
要在 QuickSight 中创建分析,请完成以下步骤:
- 在 QuickSight 控制台的导航窗格中,选择 Analyses(分析)。
- 选择 New analysis(新建分析)。
- 选择
orders_clean数据集。
- 选择 Create analysis(创建分析)。

- 要调整主题,请在导航窗格中选择 Themes(主题),选择首选主题,然后选择 Apply(应用)。

- 将分析命名为
retail-analysis。
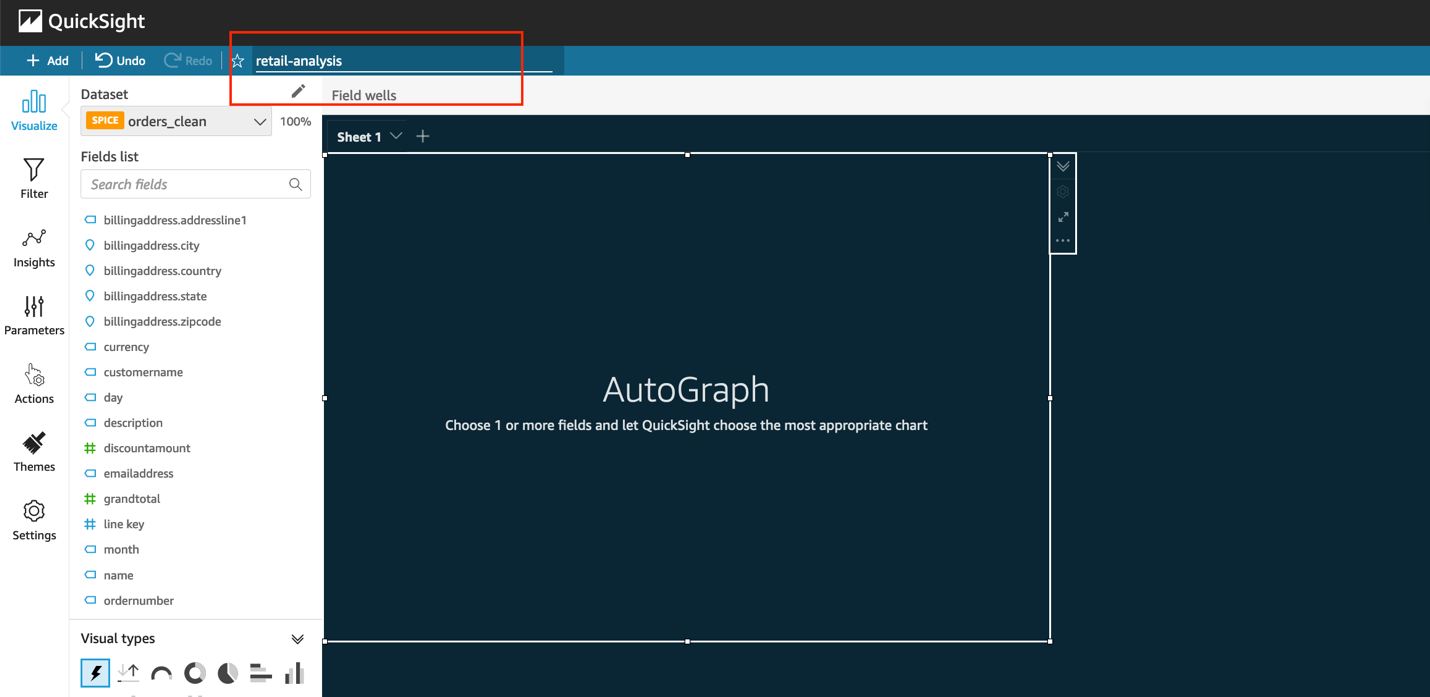
在分析中添加可视化效果
接下来,我们开始创建可视化效果。第一个可视化效果显示一段时间内创建的订单。
- 选择控制面板上的空图,对于 Visual type(视觉队形类型),选择折线图。
有关视觉对象类型的更多信息,请参阅 Amazon QuickSight 中的视觉对象类型。

- 在 Field wells(字段井)下,将
orderdatetime拖到 X axis(X 轴),将ordernumber拖到 Value(值)。 - 将
ordernumber设置为 Aggregate: Count distinct(聚合: 非重复计数)。

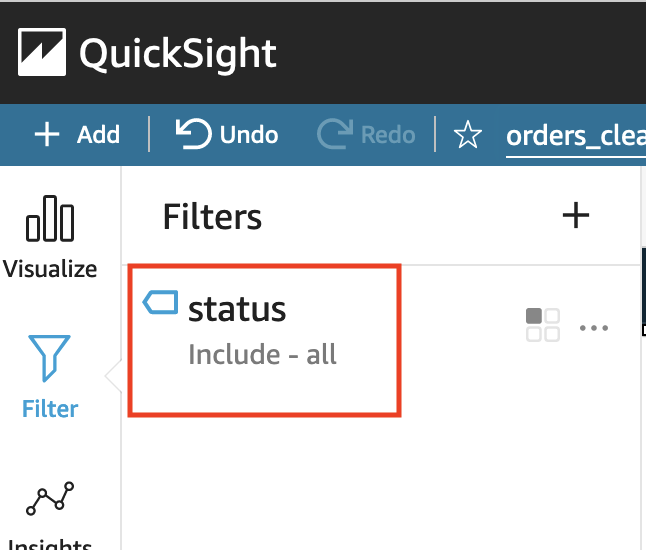
现在我们可以按Created(已创建)状态筛选这些订单。 - 在导航窗格中选择 Filter(筛选器),然后选择 Create one(创建一个)。
- 搜索并选择 status(状态)。

- 选择您刚刚创建的 status(状态)筛选器。

- 从筛选器列表中选择 Created(已创建),然后选择 Apply(应用)。

- 选择图表(右键单击),然后选择 Add forecast(添加预测)。
仅企业版提供预测功能。QuickSight 使用 Random Cut Forest (RCF) 算法的内置版本。有关更多信息,请参阅了解 Amazon QuickSight 使用的 ML 算法。

- 将设置保留为默认值,然后选择 Apply(应用)。
- 将可视化效果重命名为“Orders Created Over Time”(一段时间内创建的订单)。

如果成功应用预测,则可视化效果显示预期的订单数量以及上限和下限。

如果您收到以下错误消息,请先让数据累积几天,然后再添加预测。

接下来,我们创建一个各位置的订单可视化效果。
- 在 Add(添加)菜单上,选择 Add visual(添加视觉对象)。

- 选择地图视觉对象类型上的点。

- 在 Field wells(字段井)下,将
shippingaddress.zipcode拖到 Geospatial(地理空间),将ordernumber拖到 Size(大小)。 - 将
ordernumber更改为 Aggregate: Count distinct(聚合: 非重复计数)。

现在,您应该会看到一张地图,指示各位置的订单。 - 相应地重命名可视化效果。

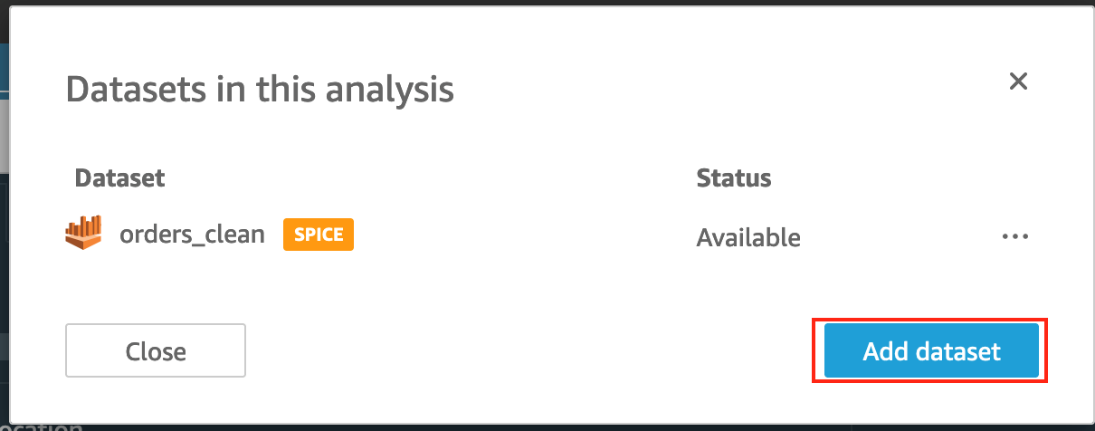
接下来,我们创建库存计数的向下钻取可视化效果。 - 选择铅笔图标。

- 选择 Add dataset(添加数据集)。

- 选择
inventory_landing_zone数据集,然后选择 Select(选择)。

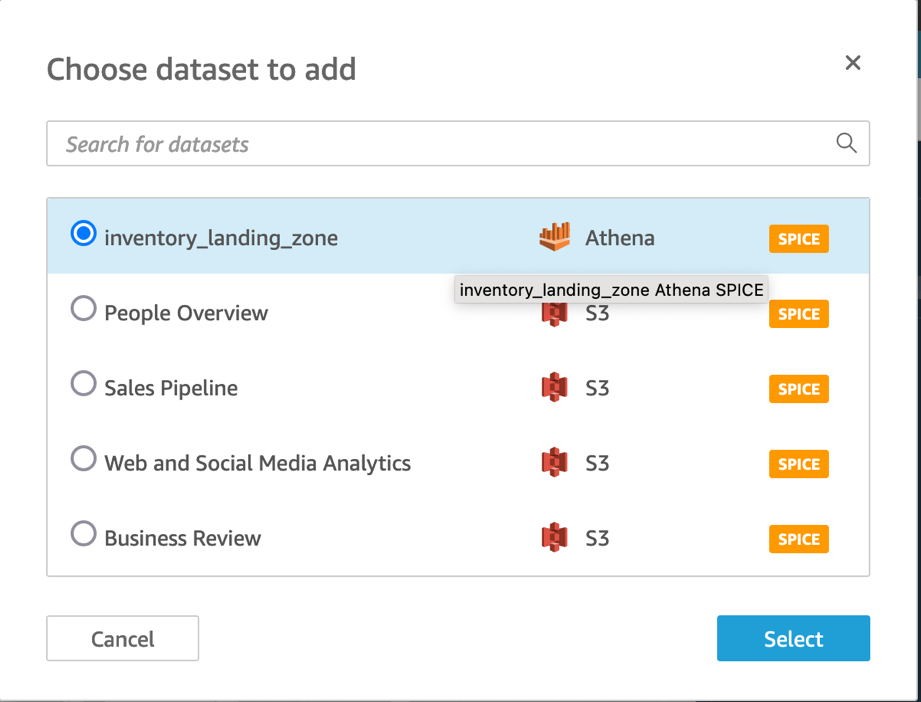
- 选择
inventory_landing_zone数据集。

- 添加纵条图视觉对象类型。

- 在 Field wells(字段井)下,将
itemname、shipnode和invtype拖到 X axis(X 轴),将 quantity 拖到 Value(值)。 - 确保将 quantity 设置为 Sum(求和)。

以下屏幕截图显示了订单库存的可视化效果示例。

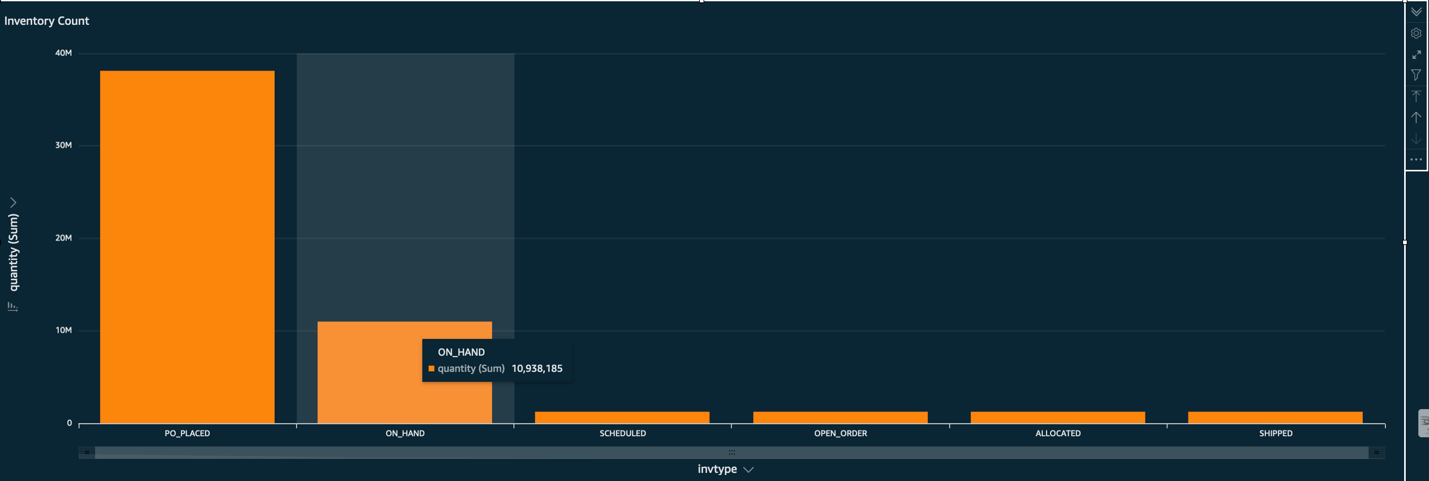
- 要确定从每个船舶节点发运了多少口罩,请选择 Face Masks(口罩)(右键单击),然后选择 Drill down to shipnode(向下钻取到船舶节点)。

- 您可以进一步向下钻取到
invtype,以查看特定船舶节点有多少口罩处于哪种状态。




以下屏幕截图显示了此向下钻取的库存计数。
下一步,您可以根据创建的分析创建 QuickSight 控制面板。有关说明,请参阅教程:创建 Amazon QuickSight 控制面板。
清理
为避免产生任何持续费用,请在 AWS CloudFormation 控制台上选择您创建的堆栈,然后选择 Delete(删除)。这将删除所有创建的资源。在堆栈的 Events(事件)选项卡上,您可以跟踪删除进度,并等待堆栈状态更改为 DELETE_COMPLETE。
Amazon EventBridge 规则每 15 分钟生成一次订单和库存数据,为避免生成大量数据,请确保在测试博客后删除堆栈。
如果删除任何资源失败,请确保手动删除它们。要删除 Amazon QuickSight 数据集,您可以按照这些说明进行操作。您可以使用这些步骤删除 QuickSight 分析。要删除 QuickSight 订阅并关闭账户,您可以按照这些说明进行操作。
结论
在这篇博文中,我们向您展示了如何使用 AWS 分析和存储服务来构建无服务器运营数据湖。Kinesis Data Streams 可让您摄取大量数据,DataBrew 可让您直观地清理和转换数据。我们还向您展示了如何使用 AWS Glue、Athena 和 QuickSight 分析和可视化订单及库存数据。有关 AWS 上数据湖的更多信息和资源,请访问 AWS 上的分析。
关于作者
 Gandhi Raketla 是 AWS 的高级解决方案架构师。他与 AWS 客户和合作伙伴就云采用以及构建解决方案来帮助客户提高敏捷性和创新能力进行合作。他擅长 AWS 数据分析领域。
Gandhi Raketla 是 AWS 的高级解决方案架构师。他与 AWS 客户和合作伙伴就云采用以及构建解决方案来帮助客户提高敏捷性和创新能力进行合作。他擅长 AWS 数据分析领域。
 Sindhura Palakodety 是 AWS 的解决方案架构师。她热衷于帮助客户在 AWS Cloud 上构建架构完善的企业级解决方案,擅长容器和数据分析领域。
Sindhura Palakodety 是 AWS 的解决方案架构师。她热衷于帮助客户在 AWS Cloud 上构建架构完善的企业级解决方案,擅长容器和数据分析领域。