Blog de Amazon Web Services (AWS)
Responde preguntas frecuentes de tus clientes usando un asistente potenciado con IA Generativa
Agosto 2025 (v7.1.1) – AWS QnABot, en su versión actual considera importantes actualizaciones de seguridad y nuevas funcionalidades como la capacidad de personalizar prompts y parámetros de inferencia para Amazon Bedrock Knowledge Base, así como integración mejorada con Guardrails y soporte para nodos maestros dedicados en Amazon OpenSearch.
Junio 2024 (v6.0.0) – Esta última versión tienen Integración con Amazon Bedrock por lo que ya no requiere despliegue de funciones AWS Lambda adicionales. Además, tiene Integración con Amazon Bedrock Knowledge Base como mecanismo de búsqueda alternativa a la base de conocimiento de Amazon OpenSearch Service que maneja por defecto la solución.
Los centros de atención al cliente (call centers) poseen recursos limitados para atender las consultas y problemas de sus clientes a través de canales conversacionales. ¿Y Qué pasa cuando estos recursos se utilizan para responder preguntas frecuentes y recurrentes de los clientes?, esto se puede traducir en:
- Sub utilización de recursos valiosos, tanto humanos como tecnológicos, que podrían emplearse de manera más eficiente en tareas de mayor complejidad o valor al cliente.
- Aumento en los tiempos de espera para los clientes, lo que puede provocar frustración, abandono de llamadas y en última instancia, una disminución en los niveles de satisfacción y lealtad hacia su empresa.
Te has preguntado ¿cuál es el porcentaje de llamados de tu call center con esta características?, tenemos casos que usando la solución de asistente de autoatención, lograron retener entre un 28% (caso de la industria del entretenimiento) y 65% (caso de industria salud) de llamados, también ejemplos de la industria de Retail que lograron disminuir en un 31% el abandono en cola de llamados tras una implementación en 6 días a nivel global.
Con los avances recientes de la Inteligencia Artificial Generativa, especialmente la aparición de los Modelos Fundacionales, modelos entrenados con grandes volúmenes de datos, capaces de generar contenido en diversos formatos, entre ellos los modelos de lenguaje de gran tamaño (o Large Language Models, LLM), se abre un nuevo espectro de posibilidades al utilizar este tipo de tecnologías. Los chatbots y voicebots ahora pueden ejecutar una conversación siguiendo lineamientos especificos, adoptando un tono determinado y respetando reglas sobre el tipo de atención que se desea prestar, logrando una interacción más eficiente y más natural.
En AWS, desde 2023, existen alternativas para el uso de Modelos Fundacionales de Inteligencia Artificial a través de Amazon SageMaker JumpStart, y para septiembre de 2023 anunciamos Amazon Bedrock. Si deseas crear aplicaciones potenciadas con IA Generativa sin preocuparte de la infraestructura o configuraciones de ambiente, te recomendamos empezar con Amazon Bedrock por su facilidad de uso y capacidad de invocar diferentes modelos a través de una sola API. Actualmente contamos con 6 proveedores, Anthropic, AI21Labs, Cohere, Amazon, Meta, Mistral AI y Stability AI, cada uno con múltiples modelos disponibles los que puedes combinar y complementar entre sí para lograr los mejores resultados.
Sin embargo la Inteligencia Artificial Generativa no es la solución completa para resolver el tipo de problema planteado, es una pieza clave que forma parte de la solución, y permite brindar un toque más humano a la interacción entre los centros de atención al cliente y sus cliente finales.
En este post mostraremos cómo utilizar una solución de AWS con plantillas para despliegue automático, construidas por arquitectos de soluciones de AWS y socios. Esta solución llamada QnABot, permite desplegar una interfaz conversacional basada en Amazon Lex y potenciada con Amazon Bedrock en cuestión de unas horas.
Te recomiendo explorar las mas de 1300 soluciones de AWS disponibles y revisar otros posibles casos de uso además del que revisaremos en este blog.

Vista general de la solución
A continuación te explico paso a paso en que consiste la solución QnABot:
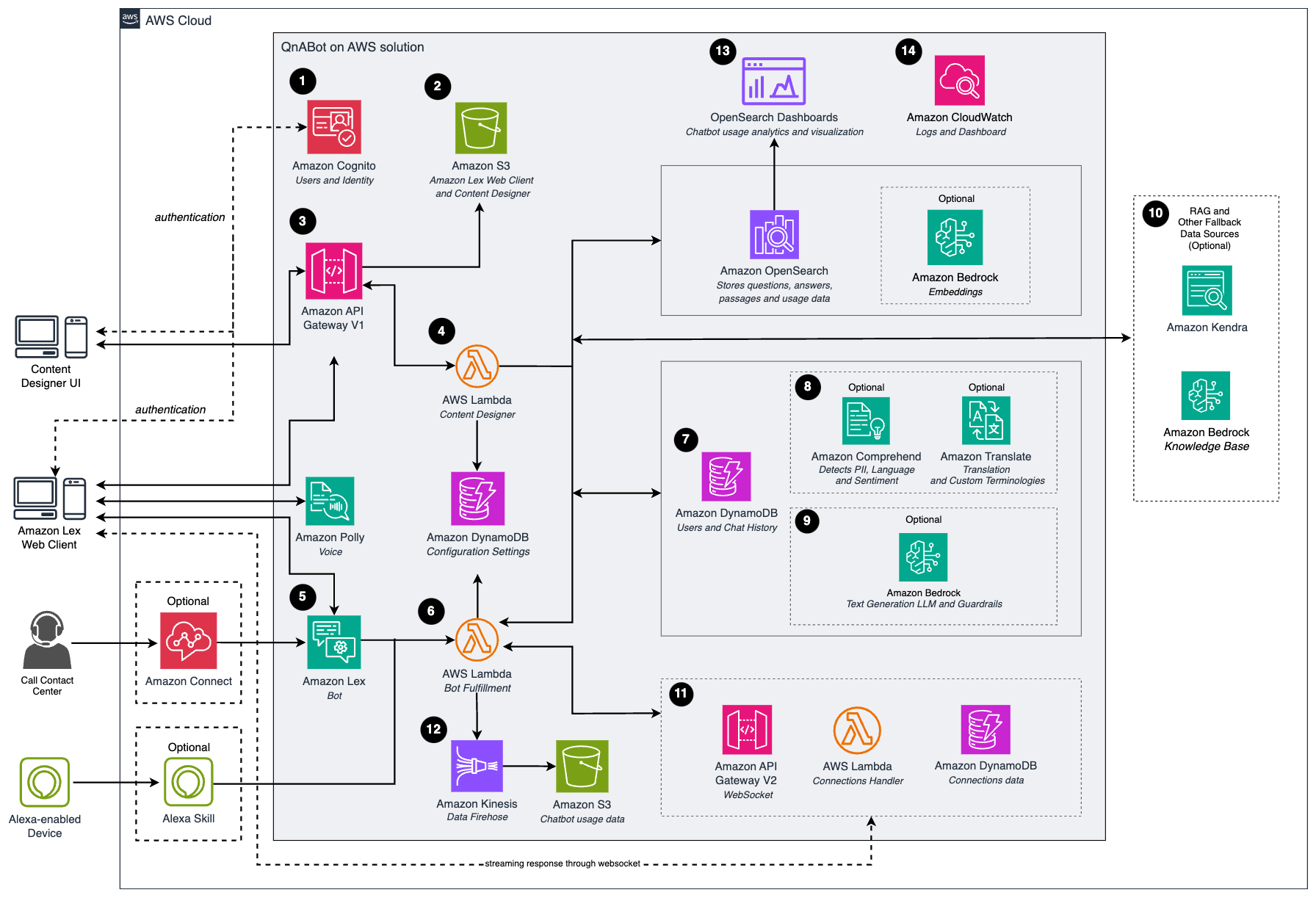
- Una interfaz de usuario (UI) para el diseñador de contenidos y el cliente web de Amazon Lex, con Amazon Cognito para autenticarse.
- Tras la autenticación, Amazon API Gateway y Amazon Simple Storage Service (Amazon S3) entregan el contenido de la interfaz de usuario del diseñador de contenidos.
- Configure las preguntas y respuestas en el diseñador de contenidos, esto enviará solicitudes a API Gateway para guardar las preguntas y las respuestas.
- La función de AWS Lambda del diseñador de contenidos guarda los datos ingresados en Amazon OpenSearch Service en un índice de banco de preguntas. Si utiliza text embeddings, estas solicitudes pasan por un modelo de machine learning de Amazon Bedrock, para generar los embeddings antes de guardarlos en el banco de preguntas de Amazon OpenSearch Service.
- Los usuarios interactúan con el asistente a través de formatos como chat (Cliente web) o voz (Amazon Connect).
- Amazon Lex utiliza una función de AWS Lambda para el cumplimiento (Fulfillment) de la acción. Los usuarios del chatbot también pueden enviar solicitudes a esta función de AWS Lambda a través de dispositivos con Amazon Alexa.
- La función de AWS Lambda encargada del cumplimiento toma la entrada del usuario y:
- Usa Amazon Comprehend y Amazon Translate (en caso que se configure para análisis de sentimiento y manejo de multilenguaje) para procesar las solicitudes, y a continuación, busca la respuesta en OpenSearch Service.
- Si utilizas LLM para text embeddings y generación de respuesta, estas solicitudes pasan primero por varios modelos de Amazon Bedrock:
- Primero para generar una consulta de búsqueda simplificada en base al historial de la conversación
- Luego genera los text embeddings para compararlas con las guardadas en el banco de preguntas de Amazon OpenSearch Service
- Finalmente pasa por un modelo para generar una respuesta a partir del contenido encontrado.
- Si tienes bases de conocimiento cargadas en un índice de Amazon Kendra o Amazon Bedrock Knowledge Base puedes integrarlo con el QnABot como opción alternativa, la función de AWS Lambda Bot que completa la solicitud, invoca a Amazon Kendra o Amazon Bedrock Knowledge Base si el banco de preguntas de OpenSearch Service no devuelve ninguna coincidencia.
- Las interacciones de los usuarios con la función de AWS Lambda encargada del cumplimiento, generan registros y datos de métricas que se envían a Amazon Kinesis Data Firehose y Amazon S3 donde se pueden analizar posteriormente.
Pre-Requisitos
- Una cuenta en AWS.
- Habilitar el acceso a los modelos en Bedrock para la región us-east-1, para el tutorial deberás habilitar :
- Amazon
-
- Titan embeddings – text v2
- Nova → Pro
-
- Otros modelos soportados que te interese explorar
- Amazon
Tutorial
¡Es hora de empezar! Los principales pasos son:
- Despliega la Solución de AWS QnABot.
- Configura el QnABot.
- Alimenta a tu bot con información.
- Prueba
- Limpia eliminando los recursos creados
Nota: es importante saber que tanto el plugin como el QnABot tiene versiones y mantienen actualizaciones constantes para generar mejoras, arreglos, adaptaciones ante nuevas versiones de los servicios.
1. Despliega la Solución de AWS QnABot.
- Dirígete al link de la solución del QnABot.
- Ubica la sección de Opciones de despliegue.
- Selecciona el botón Lanzar en la consola de AWS, esto te dirigirá a AWS CloudFormation para desplegar la última versión del QnaBot. Completa los siguientes parámetros:
Stack name : NombreDeTuBot
Email: TuCorreo@mail.com
PublicOrPrivate: selecciona si quieres que el cliente web del QnABot requiera autenticación (PRIVATE) o no (PUBLIC)
Language: Spanish
OpenSearchNodeCount: 1
LexV2BotLocaleIds: es_US
EmbeddingsApi: BEDROCK
EmbeddingsBedrockModelId: amazon.titan-embed-text-v2
LLMApi: BEDROCK
LLMBedrockModelId: amazon.nova-pro-v1
Mantén el resto de las opciones con lo valores por defecto.
2. Configura el QnABot.
- Revisa la salida del despliegue: Una vez finalizado el despliegue de tu QnABot, dirígete a la pestaña de Outputs de tu Stack de AWS CloudFormation, allí encontrarás la URL del diseñador de contenidos (ContentDesignerURL) y deberás haber recibido un correo con las credenciales.

- Inicio de sesión: Esto te llevará a un inicio de sesión como el siguiente, donde deberás ingresar tus credenciales y hacer el cambio de password.

- Para este blog nos concentraremos en las primeras opciones de configuración, empezando por las Settings.

- Para las settings que no modificamos en el punto anterior usa la siguiente configuración, te invito a jugar variando estos prompts para darle el tono a la respuesta que represente más a tu caso, sobre todo al prompt de generación de respuesta:
- EMBEDDINGS_TEXT_PASSAGE_SCORE_THRESHOLD: 0.6
- LLM_GENERATE_QUERY_PROMPT_TEMPLATE: este prompt es el usado para refrasear la consulta del cliente basándose en la historia de la conversación, con el objetivo de simplificar la pregunta
<br><br>Human: Acá esta la historia de la conversación:<br><chatHistory><br>{history}<br></chatHistory><br>Human: Y acá es la última consulta del cliente:<br><followUpMessage><br>{input}<br></followUpMessage><br>Human: Analiza la historia y la pregunta y genera una pregunta que resuma lo que está requiriendo consultar el cliente en el mismo idioma en que se hizo la pregunta. Responde solo con la nueva pregunta, sin agregar tu razonamiento<br><br>Assistant: acá esta la pregunta refraseada:
-
- LLM_GENERATE_QUERY_MODEL_PARAMS: esta configuración nos permite indicar que modelo será usado para ejecutar el prompt LLM_GENERATE_QUERY_PROMPT_TEMPLATE, y que parámetros de inferencia le pasaremos al modelo, en este caso estamos usando Claude 3 Haiku.
{\"temperature\":0, \"maxTokens\":300, \"topP\":1}{ "temperature": 0, "max_tokens": 300, "top_p": 1}
-
- LLM_QA_PROMPT_TEMPLATE: este prompt es el utilizado para generar la respuesta usado un modelo de IA generativa a partir de la referencia encontrada en la base de conocimiento.
<br><br>Human: Eres un amigable asistente AI que se apoya en una base de conocimiento con información sobre Soluciones de AWS. Recibirás una pregunta y una referencia para generar una respuesta. Acá está la referencia:<br><references><br>{context}<br></references><br>Acá esta la pregunta:<br><question><br>{query}<br></question><br>Si en la referencia encuentras la información para responder la pregunta, genera una respuesta confiada sobre el tema, si no dice literal algo sobre la pregunta, pero tienes información para responder algo parcialmente confiada responde, con la información que inferiste y añade la cita de la frase que te hace conectar con la pregunta. Si en la referencia no se dice nada acerca de lo pregunta, responde, \"Lo siento, no tengo información para responderte\". Siempre entrega la información en idioma español, incluyendo las citas o referencias.<br><br>Assistant: De acuerdo a la referencia, en menos de 50 palabras esta es la respuesta:
-
- LLM_QA_MODEL_PARAMS: esta configuración nos permite indicar que modelo será usado para ejecutar el prompt LLM_QA_PROMPT_TEMPLATE, y que parámetros de inferencia le pasaremos al modelo, en este caso sumamos el parámetro system que permite proporcionar un contexto e instrucciones al modelo, como por ejemplo especificar su función.
{ "temperature": 0, "max_tokens": 300, "top_p": 1, "system": "Eres un Asistente AI amigable que responderá preguntas del cliente sobre soluciones de AWS, responde en un tono amable y personal"}
Nota: Para ver todas las posibles configuraciones que se pueden realizar en el QnABot te invito a revisar la documentación de Settings.
3. Alimenta a tu bot con información.
- Copia al siguiente json y guárdalo en un archivo . json, este funcionará como una base de conocimiento del QnABot y las soluciones de Contact Center Intelligence tomados de algunos blogs de AWS sobre estos temas.
- Carga el contenido para que sea indexado en Amazon OpenSearch Service y te sirva como base de conocimiento, para esto:
- Dirígete a Import
- Selecciona el botón Browse y selecciona el archivo
- Automáticamente el empezará a cargar la data y te mostrará el estado de carga en la sección Import Jobs, el cual pasará de Submitted a InProgress y finalmente quedará Complete.
Nota: Amazon OpenSearch Service es donde se almacena la base de conocimiento principal con la que interactúa el QnABot. El QnABot realiza la búsqueda y retorna el artículo con mayor similitud a la pregunta (Top 1), pero te recuerdo que existe la opción de configurar un índice de Amazon Kendra, con este tendrás capacidades de retornar múltiples extractos de documentos. Te invito a probar todas estas opciones para que evalúes cual es más efectiva para tu caso.
4. Prueba
En menos de 5 minutos podrás ir al cliente del QnABot para iniciar tus preguntas, la url del cliente podrás encontrarla entre los Outputs del stack de AWS CloudFormation de QnABot bajo la key ClientURL o en el menú QnABot Designer UI en la opción QnABot Client.

Al preguntar: “Te suena Post Call Analytics”, esta es su respuesta:

Ante consultas como “muchas gracias y me puedes indicar que es el qnabot” estas es la respuesta.

5. Limpieza
Para eliminar los recursos creados sigue los pasos indicados en la documentación.
Conclusión
Al desplegar la solución de QnABot vas a obtener:
- Un bot de preguntas y respuestas con soporte multilenguaje en un par de horas.
- Múltiples alternativas para manejo de base de conocimiento como Amazon OpenSearch Service y Amazon Kendra.
- Integraciones a distintos Modelos Fundacionales usando Amazon Bedrock. En nuestra prueba nos centramos en Anthropic Claude 3 Haiku, pero puedes probar fácilmente con las demás alternativas que Bedrock tiene disponible.
- Capacidades probadas para añadir funcionalidades como interacción con ServiceNow, Alexa o Genesys Cloud.
Te invito a ser parte de los que mejoran cada día este tipo de soluciones, contribuyendo en el código, solicitando nuevas características o reportando alguna mejora a través del repositorio del QnABot.
Te dejo estos recursos para que sigas explorando otras capacidades e integraciones para el QnABot:
- Despliega una interfaz de preguntas y respuestas, potenciada con Amazon Kendra y Amazon Bedrock.
- Integra al QnABot con Service Now.
- Integra al QnaBot con Alexa.
- Construye un agente virtual pontenciado con Inteligencia Artificial para tu call center en Genesys Cloud
- QnABot workshop
Acerca de la autora
 |
Rosmar Torres es Arquitecta de Soluciones en Amazon Web Service, con más de 12 años de experiencia en Analítica en SAP y Desarrollo de Software. Basada en Santiago, Chile. Con intereses en Análitica e IA. |
Sobre los revisores
 |
Enrique Rodríguez es Arquitecto de Soluciones de Amazon Web Servicies (AWS) Basado en Chile actualmente ayudando a los clientes de la región a lograr sus desafíos en la nube. Con intereses en Machine Learning y Contact Center en la Nube. |
 |
Francisco Fagas es Arquitecto de Soluciones Senior en Amazon Web Services, basado en Chile actualmente ayudando a los clientes de la región a lograr sus desafíos en la nube. Con intereses en Machine Learning, analítica e IA DevOps. |