Amazon Web Services ブログ
低コストかつ高パフォーマンスを実現する Amazon Redshift
この記事は Amazon Redshift: Lower price, higher performance の翻訳記事です。
ほぼすべてのお客様と同様に、あなたも可能な限り最高のパフォーマンスを実現しながら、コストを最小限に抑えたいと考えることでしょう。つまり、コストパフォーマンスに注意を払う必要があるということです。 Amazon Redshift を使用すると、コストを最小限に抑えながら最高のパフォーマンスを実現することができます。 Amazon Redshift は、数百人の同時ユーザーをサポートするための同時実行スケーリングや、クエリパフォーマンスを高速化するための強化された文字列エンコーディング、Amazon Redshift Serverless のパフォーマンス強化といった先進的な技術を使用することで、実際のワークロードにおいて他のクラウドデータウェアハウスと比較して、ユーザーあたりのコストを最大 4.9 倍削減し、最大 7.9 倍優れたコストパフォーマンスを実現します。コストパフォーマンスが重要な理由と、Amazon Redshift では、特定のレベルのワークロードパフォーマンスを得るためにどの程度のコストが必要になるかという尺度、つまりパフォーマンス ROI (投資収益率) を理解するためにぜひ読んでください。
コストとパフォーマンスの両方がコストパフォーマンスの計算に含まれるため、コストパフォーマンスについては 2 つの考え方があります。 1 つ目の考え方は、コストを一定に保つことです。1 ドルを使えるとしたら、データウェアハウスからどの程度のパフォーマンスが得られるでしょうか? コストパフォーマンスの優れたデータベースは、支出した 1 ドルごとに優れたパフォーマンスを提供します。したがって、同じ一定のコストの 2 つのデータウェアハウスを比較する場合、コストパフォーマンスの高いデータベースの方がクエリの実行が速いです。 2 つ目の考え方は、パフォーマンスを一定に保つことです。ワークロードを 10 分以内で完了する必要がある場合、それにかかるコストはいくらでしょうか? コストパフォーマンスに優れたデータベースでは、ワークロードを10 分以内でより低コストで実行できます。したがって、パフォーマンスを一定に保ち、同じパフォーマンスを実現するサイズの 2 つのデータウェアハウスを比較する場合、コストパフォーマンスの高いデータベースの方がコストが低くなり、コストを節約することができます。
最後に、コストパフォーマンスのもう 1 つの重要な観点は、予測可能性です。データウェアハウスのユーザー数が増加するにつれて、データウェアハウスのコストがどれくらいかかるかを把握することは、計画を立てる上で非常に重要です。今日最高のコストパフォーマンスを提供するだけでなく、ユーザーやワークロードが追加されたときに予測どおりに拡張し、最高のコストパフォーマンスを提供する必要があります。理想的なデータウェアハウスは線形にスケールする必要があります。つまり、クエリスループットを 2 倍にするためにデータウェアハウスをスケーリングすることは、理想的にはコストが 2 倍 (またはそれ以下) になるということです。
この投稿では、Amazon Redshift がその他の主要なクラウドデータウェアハウスと比較して、コストパフォーマンスが非常に優れているということを説明するために、パフォーマンスの計測結果を共有します。これは、他のデータウェアハウスに費やすのと同じ金額を Amazon Redshift に費やした場合、Amazon Redshift を使用した方がパフォーマンスが向上することを示しています。あるいは、同じパフォーマンスを実現するように Redshift クラスターのサイズを調整すると、他のデータウェアハウスと比較してコストが低くなるということです。
実ワークロードにおけるコストパフォーマンス
Amazon Redshift を使用すると非常に多様なワークロードを強化できます。複雑な抽出、変換、ロード (ETL) ベースのレポートのバッチ処理やリアルタイムのストリーミング分析から、数百、さらには数千の同時ユーザーに1 秒未満の応答時間でサービスを提供する必要がある低レイテンシーのビジネスインテリジェンス (BI) ダッシュボードまでのありとあらゆるワークロードです。AWS は、お客様のコストパフォーマンスを継続的に向上させる方法の 1 つとして、Amazon Redshift のパフォーマンスをさらに向上できる機会とお客様のユースケースを見つけるために、Redshift フリートからのソフトウェアおよびハードウェアのパフォーマンステレメトリーを常にレビューしています。
フリート テレメトリによるパフォーマンス最適化の最近の例としては、次のようなものがあります。
- 文字列型に対するクエリの最適化 – Amazon Redshift が Redshift フリート内のさまざまなデータ型をどのように処理するかを分析した結果、文字列を多く含むクエリを最適化すると、お客様のワークロードに大きなメリットがあることがわかりました。 (これについては、この投稿の後半で詳しく説明します。)
- 自動化されたマテリアライズド ビュー – Amazon Redshift のお客様は、サブクエリパターンを持つ多くのクエリを実行することが多いことがわかりました。たとえば、いくつかの異なるクエリが同じ結合条件を使用して同じ 3 つのテーブルを結合する場合があります。 Amazon Redshift は、マテリアライズドビューを自動的に作成および維持し、機械学習による自動マテリアライズドビュー の自律的な機能を使用して、マテリアライズドビューを使用するようにクエリを透過的に書き換えられるようになりました。自動マテリアライズドビューを有効にすると、ユーザーの介入なしに、反復的なクエリのパフォーマンスを透過的に向上させることができます。 (ただし、自動マテリアライズドビューは、この投稿で説明したどのベンチマーク結果にも使用されていません)
- 同時実行性の高いワークロード – Amazon Redshift を使用してダッシュボードのようなワークロードを提供するユースケースが増加しています。これらのワークロードの特徴は、要求されるクエリ応答時間が 1 桁秒以下であり、使用パターンが突発的でしばしば予測不可能で、数十から数百のユーザーが同時にクエリを実行します。この典型的な例は、Amazon Redshift を利用した BI ダッシュボードで、多くのユーザーが週初めの月曜の朝にトラフィックが急増します。
特に同時実行性の高いワークロードは非常に幅広い適用範囲を持っています。ほとんどのデータウェアハウスのワークロードでは同時実行で動作し、Amazon Redshift では、数百、さらには数千のユーザーが同時にクエリを実行することも珍しくありません。 Amazon Redshift は、クエリの応答時間を予測可能かつ高速に保つように設計されています。 Redshift Serverless は、必要に応じて自動的に処理能力を追加および削除することで、クエリの応答時間を高速かつ予測可能に保ちます。つまり、1 人または 2 人のユーザーがアクセスしているときに迅速に読み込まれる Redshift Serverless のダッシュボードは、多くのユーザーが同時にアクセスしている場合でも引き続き迅速に読み込まれることを意味します。
このタイプのワークロードをシミュレートするために、100 GB データセットを使用した TPC-DS から派生したベンチマークを使用しました。 TPC-DS は、さまざまな典型的なデータウェアハウスクエリを含む業界標準のベンチマークです。 100 GB という比較的小規模なスケールでは、このベンチマークのクエリは Redshift Serverless 上で平均数秒で実行されます。これは、インタラクティブな BI ダッシュボードを読み込むユーザーが期待する典型的な速度であることを表しています。このベンチマークでは 1 ~ 200 の同時テストを実行し、同時にダッシュボードを読み込もうとする 1 ~ 200 人のユーザーをシミュレートしました。また、自動スケールアウトをサポートするいくつかの一般的なクラウドデータウェアハウスに対してテストを繰り返しました (自動スケールアップをサポートしていないため、私たちはブログ「Amazon Redshift の継続的なコストパフォーマンス最適化」の競合他社 A を含めませんでした)。私たちは、平均クエリ応答時間を測定しました。これは、ユーザーがクエリの完了 (またはダッシュボードの読み込み) を待つ時間を意味します。結果を次のグラフに示します。

競合他社 B は、同時クエリ数が約 64 個になるまではうまく拡張できていますが、その時点で追加のコンピューティングを提供できなくなり、クエリがキューに入り始め、クエリの応答時間の増加につながっています。競合他社 C も自動的にスケーリングできていますが、Amazon Redshift や競合他社 B よりもクエリのスループットが低くなり、クエリのランタイムを低く保つことができません。さらに、コンピューティングが不足した場合のクエリのキューイングはサポートしていないため、同時ユーザー数が約 128 人を超えて拡張することができません。これを超えて追加のクエリを送信すると、システムによって拒否されます。
ここで、Redshift Serverless は、数百のユーザーが同時にクエリを実行している場合でも、クエリ応答時間を約 5 秒と比較的一定に保つことができます。競合他社 B と競合他社 C の平均クエリ応答時間は、データウェアハウスの負荷が増加するにつれて着実に増加しています。その結果、データウェアハウスがビジー状態になると、ユーザーはクエリが返るまでより長く (最大 16 秒) 待たなければならなくなります。これは、ユーザーがダッシュボードを更新しようとしている場合 (リロード時に複数の同時クエリを送信することもあります)、Amazon Redshift は、たとえダッシュボードが他の数十、数百ものユーザーによって同時に読み込まれている場合でも、ダッシュボードの読み込み時間を一貫した状態に保つことができることを意味します。
Amazon Redshift は実行時間の短いクエリに対して非常に高いクエリスループットを提供できるため (「Amazon Redshift の継続的なコストパフォーマンス最適化」で説明したように)、スケールアウト時にこれらの高い同時実行性をより効率的に処理できるため、大幅に低いコストで処理することもできます。 これを定量化するために、次のグラフに示すように、前のテストで各データウェアハウスの公開されているオンデマンド価格を使用してコストパフォーマンスを調べます。なお、リザーブドインスタンス (RI)、特に全額前払いオプションで購入した 3 年間の RI を使用すると、プロビジョニングされたクラスター上で Amazon Redshift を実行するコストが最も低くなり、オンデマンドまたは他の RI オプションと比較して、最高の相対的な価格パフォーマンスが得られることには注目すべきでしょう。
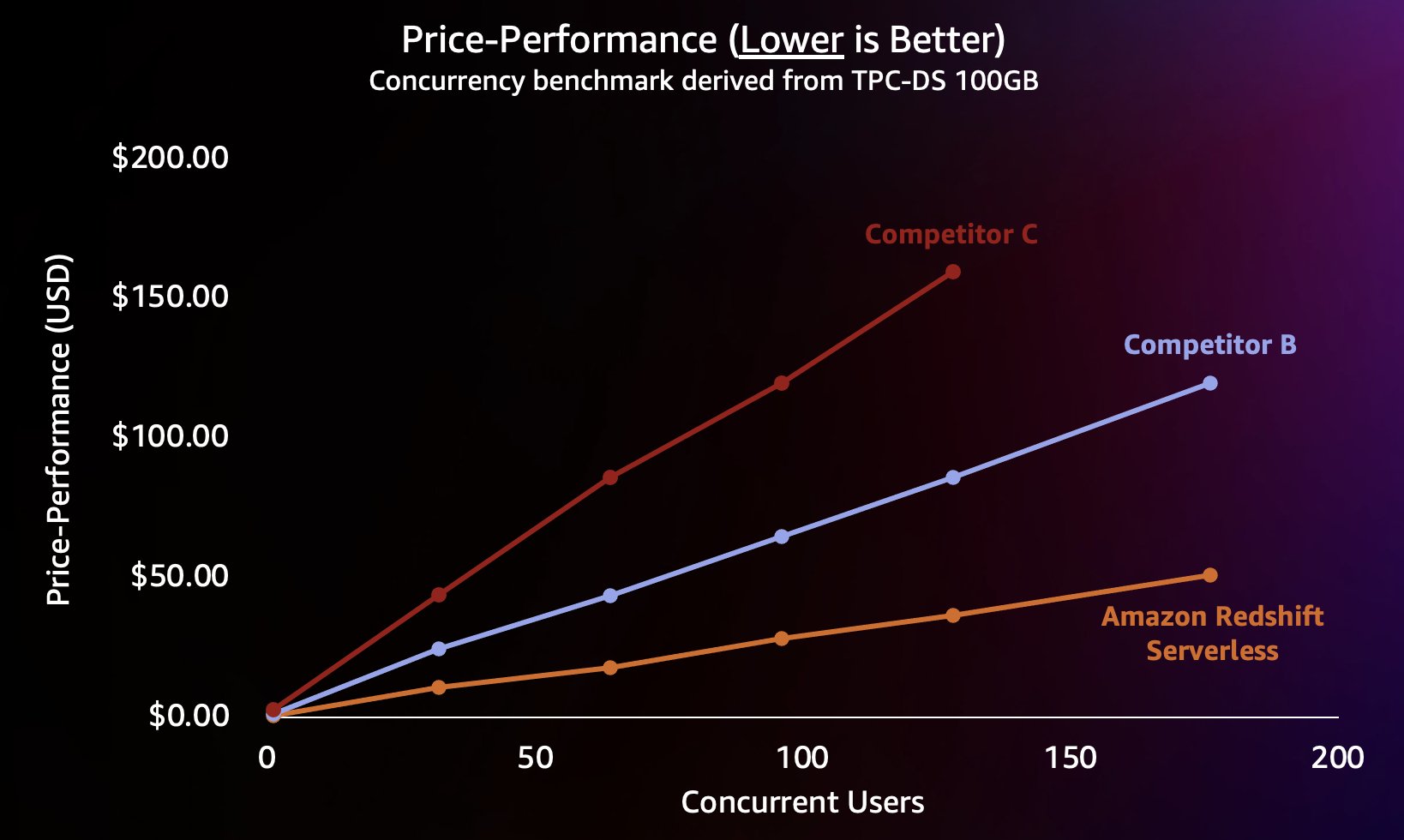
したがって、Amazon Redshift は、より高い同時実行でより優れたパフォーマンスを提供できるだけでなく、大幅に低いコストでそれを実現できます。コストパフォーマンスの図の各データポイントは、指定された同時実行数でベンチマークを実行するコストに相当します。コストパフォーマンスは線形であるため、任意の同時実行数でベンチマークを実行したコストを同時実行数 (このグラフの同時ユーザー数) で割ることで、この特定のベンチマークで新しいユーザーを追加するたびにどれくらいのコストがかかるかを知ることができます。

ここまでの結果は簡単に再現できます。ベンチマークで使用されるすべてのクエリは GitHub リポジトリで利用でき、パフォーマンスはデータウェアハウスを起動し、Amazon Redshift で同時実行スケーリング (または他のウェアハウスで対応する自動スケーリング機能) を有効にし、データをロードすることによってカスタマイズなしの状態で測定します (手動でのチューニングやデータベース固有のセットアップはありません)。そして、各データウェアハウスで 同時実行数を1-200の間で32刻みで変化させ、同時実行テストを行いました。上述の GitHub リポジトリは、公式 TPC-DS データ生成キットを使用して事前生成された (かつ変更されていない)、Amazon Simple Storage Service (Amazon S3) 内にある様々なスケールのTPC-DSデータを参照しています。。
文字列を多く含むクエリの最適化
前述したように、Amazon Redshift チームは、お客様にさらに優れたコストパフォーマンスを提供するための新しい機会を継続的に探しています。パフォーマンスを大幅に向上させるために最近開始した改善の 1 つは、文字列データに対するクエリのパフォーマンスを高速化する最適化です。たとえば、SELECT sum(price) FROM sales WHERE city = ‘New York’のようなクエリを使用して、ニューヨーク市にある小売店から得られた総収益を確認するとします。このクエリは文字列データ ( city = ‘New York’ ) を述語に適用しています。ご想像のとおり、文字列データ処理はデータウェアハウスアプリケーションで広く使用されています。
お客様のワークロードが文字列にアクセスする頻度を定量化するために、Amazon Redshift が管理する数万のお客様のクラスターのフリートテレメトリを使用して、文字列データ型の使用状況の詳細な分析を実施しました。分析の結果、クラスターの 90% では文字列カラムが全カラムの少なくとも 30% を構成し、クラスターの 50% では文字列カラムが全カラムの少なくとも 50% を構成していることがわかりました。さらに、Amazon Redshift クラウドデータウェアハウスプラットフォームで実行されるクエリの大部分は、少なくとも 1 つの文字列カラムにアクセスしています。もう 1 つの重要な要素は、文字列データはカーディナリティが低いことが非常に多く、列に含まれる一意の値のセットが比較的少ないことを意味します。たとえば、販売データを表す orders テーブルには数十億の行が含まれている場合がありますが、そのテーブル内の order_status 列には、 pending 、 in process 、 completed などの数十億の行にわたって一意の値がわずかしか含まれていない可能性があります。
この記事の執筆時点では、Amazon Redshift のほとんどの文字列カラムは LZO または ZSTD アルゴリズムで圧縮されています。これらは優れた汎用圧縮アルゴリズムですが、カーディナリティの低い文字列データを活用するように設計されていません。特に、データを操作する前に解凍する必要があり、ハードウェアメモリ帯域幅の使用効率が低くなります。カーディナリティの低いデータの場合、より最適な別のタイプのエンコーディングである BYTEDICT があります。このエンコードでは、ディクショナリエンコードスキームが使用されており、データベースエンジンは圧縮データを最初に解凍する必要がなく、圧縮データに対して直接操作できます。
文字列の多いワークロードのコストパフォーマンスをさらに向上させるために、Amazon Redshift は現在、BYTEDICT としてエンコードされたカーディナリティの低い文字列カラムのスキャンと述語評価を、LZO や ZSTD などの圧縮エンコーディングと比較して 5 ~ 63 倍高速化する追加のパフォーマンス強化を導入しています (次のセクションの結果を参照)。 Amazon Redshift は、CPU 効率が高い軽量なBYTEDICT でエンコードされたカーディナリティの低い文字列カラムをベクトル化スキャンすることで、このパフォーマンスの向上を実現します。これらの文字列処理の最適化により、最新のハードウェアが提供するメモリ帯域幅が効果的に利用され、文字列データのリアルタイム分析が可能になります。これらの新しく導入されたパフォーマンス機能は、カーディナリティの低い文字列カラム (最大数百の一意の文字列値) に最適です。
Amazon Redshift データウェアハウスで自動テーブル最適化を有効にすることで、この新しい高パフォーマンス文字列の機能強化の恩恵を自動的に受けられます。テーブルで自動テーブル最適化が有効になっていない場合は、Amazon Redshift コンソールの Amazon Redshift Advisor から、文字列絡むの BYTEDICT エンコードへの適合性に関する推奨事項を受け取ることができます。 BYTEDICT エンコードを使用したカーディナリティの低い文字列列を持つ新しいテーブルを定義することもできます。 Amazon Redshift の文字列の拡張機能は、Amazon Redshift が利用可能なすべての AWS リージョンで利用できるようになりました。
パフォーマンス測定結果
文字列処理の強化によるパフォーマンスへの影響を測定するために、カーディナリティの低い文字列データで構成される 10 TB (テラバイト) データセットを生成しました。 Amazon Redshift フリートテレメトリからの文字列の長さの 25、50、および 75 パーセンタイルに対応する、短、中、長の文字列を使用して 3 つのバージョンのデータを生成しました。このデータを Amazon Redshift に 2 回ロードし、1 つは LZO 圧縮を使用し、もう 1 つは BYTEDICT 圧縮を使用してエンコードしました。最後に、多くの行 (テーブルの 90%)、中程度の行 (テーブルの 50%)、および少数の行 (テーブルの 1%) を返すスキャンを多用するクエリのパフォーマンスを、これらのカーディナリティの低いデータセットに対して測定しました。パフォーマンス結果を次のグラフにまとめます。
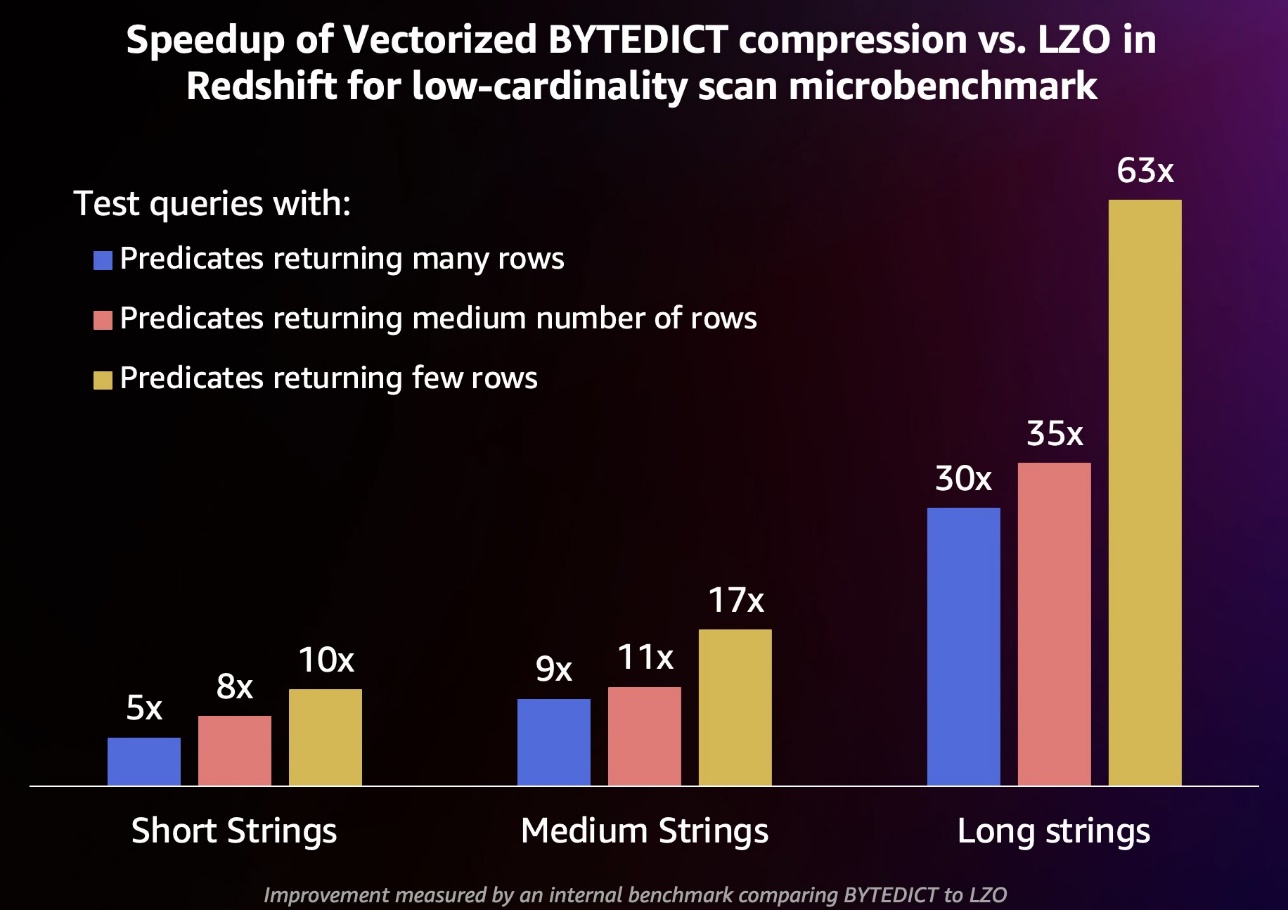
この内部ベンチマークでは、多くの行に一致する述語を含むクエリでは、LZO と比較して新しいベクトル化 BYTEDICT エンコーディングで 5 ~ 30 倍の改善が見られました。一方で、少ない行に一致する述語によるクエリでは 10 ~ 63 倍の改善が見られました。
Redshift Serverless コストパフォーマンス
この投稿で示した高い同時実行パフォーマンスの結果に加えて、より大きな 3 TB データセットでTPC-DS 派生のクラウドデータウェアハウスのベンチマークも使用して、Redshift Serverless のコストパフォーマンスを、他のデータウェアハウスと比較しました。私たちは同様の価格のデータウェアハウスを選択しました。今回のケースでは、公開されているオンデマンド価格を使用すると、1 時間あたり 32 ドルの 10% 以内に収まっています。結果は、Amazon Redshift RA3 インスタンスと同様に、Redshift Serverless が他の主要なクラウドデータウェアハウスと比較して優れたコストパフォーマンスを実現していることを示しています。いつものように、これらの結果は、GitHub リポジトリの SQL スクリプトを使用して再現できます。

Amazon Redshift がデータ分析のニーズをどのように満たすかを確認する最良の方法として、自身の PoC ワークロードを使用して Amazon Redshift を試してみることをお勧めします。
あなたのワークロードにおける最高のコストパフォーマンスを見つける
この投稿で使用されているベンチマークは、業界標準の TPC-DS ベンチマークから派生したもので、次の特徴があります。
- スキーマとデータは TPC-DS から変更せずに使用しています。
- クエリは、TPC-DS キットのデフォルトのランダムシードを使用して生成されたクエリパラメーターを持つ公式 TPC-DS キットを使用して生成しています。データウェアハウスがデフォルトの TPC-DS クエリの SQL 言語をサポートしていない場合は、TPC で承認された変更を加えたクエリを使用しています。
- テストには 99 個の TPC-DS の SELECT クエリを含みます。これには、メンテナンスとスループットの手順は含んでいません。
- 単発の 3TB 同時実行テストでは、3 回の POWER RUN が実行され、データウェアハウスごとに最良の実行結果を採用しました。
- TPC-DS クエリのコストパフォーマンスは、時間あたりのコスト (USD) にベンチマークの実行時間 (時間単位) を掛けたものとして計算しています。これは、ベンチマークの実行コストに相当します。前述したようにリザーブド インスタンスの価格ではなく、すべてのデータウェアハウスで最新の公開されたオンデマンド価格を使用しています。
これをクラウドデータウェアハウスベンチマークと呼びます。GitHub リポジトリで利用可能なスクリプト、クエリ、データを使用して、前述のベンチマーク結果を簡単に再現できます。この投稿で説明されているように、これは TPC-DS ベンチマークから派生したものであり、テストの結果は公式仕様に準拠していないため、公開されている TPC-DS の結果と比較することはできません。
結論
Amazon Redshift は、さまざまなワークロードに対して業界最高のコストパフォーマンスを提供することに尽力しています。 Redshift Serverless は、最良の (最も低い) コストパフォーマンスでリニアにスケールし、一貫したクエリ応答時間を維持しながら数百人の同時ユーザーをサポートします。この投稿で説明したテスト結果に基づくと、Amazon Redshift は、最も近い競合他社 (競合 B) と比較して、同じレベルの同時実行数で最大 2.6 倍優れたコストパフォーマンスを示しました。前述したように、3 年間全額前払いオプションでリザーブドインスタンスを使用すると、Amazon Redshift の実行コストが最も低くなり、この投稿で使用したオンデマンドインスタンスの価格と比較して、相対的なコストパフォーマンスがさらに向上します。継続的なパフォーマンス向上に対する当社のアプローチには、顧客のユースケースとそれに関連するスケーラビリティのボトルネックを理解するというお客様を中心とした考え方と、パフォーマンスを大幅に最適化する機会を特定するための継続的なフリートデータ分析を組み合わせた独自の組み合わせが含まれます。
各ワークロードには独自の特性があるため、まだ始めたばかりの場合は、Amazon Redshift がどのようにコストを削減しながらパフォーマンスを向上させるかを理解するための最良の方法は PoC です。独自の PoC を実行する場合は、クエリスループット (1 時間あたりのクエリ数)、応答時間、コストパフォーマンスなどの適切な指標に焦点を当てることが重要です。 PoC を自分で実行するか、AWS またはシステムインテグレーターおよびコンサルティングパートナーの支援を受けて、データ主導の意思決定を行うことができます。
Amazon Redshift の最新の開発状況を常に把握するには、Amazon Redshift の最新情報フィードをフォローしてください。
翻訳はソリューションアーキテクトの池田 敬之が担当しました。