Amazon Web Services ブログ
大規模なデータベースをオープンソースデータベースへ移行する際のカテゴリ分けと優先度づけ
AWS Schema Conversion Tool (AWS SCT)とAWS Database Migration Service (AWS DMS) はコマーシャルデータベースからAmazon RDSの様々なデータベースエンジンへの移行を簡単に行えるようにするツールです。 AWS SCTはプロプライエタリなデータベースをオープンソースデータベースへ移行する際に手助けを行います。移行元のデータベーススキーマや多くのカスタムコードを移行先のデータベースに適した形へ変換を行います。ツールが変換を行うカスタムコードには、ビュー、ストアード・プロシージャー、ストアード・ファンクションを含みます。一方、自動的に変換が出来ないものとしては、手動で変換が行いやすいように該当箇所を抽出します。AWS DMSはダウンタイムを最小限に抑えながら、簡単・安全にデータを移行することを可能にします。
データベースエンジンを変更することは大変な作業ですが、Amazon Auroraのようなスケーラブルでコスト効率がいいフルマネージドサービスの恩恵を受けやすくなる利点があり、移行を行う価値があります。AWS SCTとAWS DMSを用いることで、単一のデータベースからオープンソースへの移行を評価し、計画を行うことが容易になります。 AWT SCTアセスメントレポートを生成し、これらのツールを使用することで、データベースを移行することが、どのくらい簡単であるかということがおわかりになると思います。
以下のブログやビデオは、オープンソースデータベースへ移行するための情報の一例です。
- How to Migrate Your Oracle Database to PostgreSQL
- How to Migrate Your Oracle Database to Amazon Aurora
- Migrate from SQL Server or Oracle into Amazon Aurora using AWS DMS
もし、数百・数千のデータベースを持っていた場合は
評価レポートを作成し、1つ、2つ、またはさらに10のデータベースをオープンソースデータベースへ移行することは、簡単なプロセスです。 おそらく、どのアプリケーションが利用しているデータベースを最初に移動するか判断するための材料は十分お持ちだと思います。 組織内外で利用されている数百または数千のデータベースインスタンスがあり、十分なアプリケーションの知識がない場合はどうなるでしょうか?
集中管理されたIT部門では、管理するデータベースの数、バックアップのスケジュール設定などを一元管理することが出来ます。 しかし、大規模な動向を計画したり、分析のために優先順位を付けるための十分な詳細がないかもしれません。 この記事では、データベースポートフォリオを評価し、管理可能な移行のパイプラインに分解してプロセスを円滑に進めるための方法について説明します。
小さいプロジェクトのコラボレーション
1つの異種データベース移行の詳細なプロジェクト計画は、次の表に示すように12の手順で構成されます。
| フェーズ | 説明 | フェーズ | 説明 |
| 1 | 評価 | 7 | システム全体で機能テスト |
| 2 | データベーススキーマ変換 | 8 | パフォーマンステスト |
| 3 | アプリケーション変換/修正 | 9 | 結合とデプロイ |
| 4 | スクリプト変換 | 10 | トレーニング |
| 5 | サードパーティアプリケーションとのインテグレーション | 11 | ドキュメントと変更管理 |
| 6 | データ移行 | 12 | リリース後のサポート |
このブログの目的上、移行プロジェクトを計画するプロセスは、分析と計画、スキーマ移行、データ移行、アプリケーション移行、およびカットオーバーの5つの作業領域に分類できます。 移行の所要時間は、通常、移行およびテストのフェーズでどのくらいの時間を費やすかによって異なります。 いくつかの移行を並行して計画している場合は、どちらの移行が最も時間がかかるのか、最初に取り組むことができるのか、迅速に取り組むことができるのかを理解する必要があります。
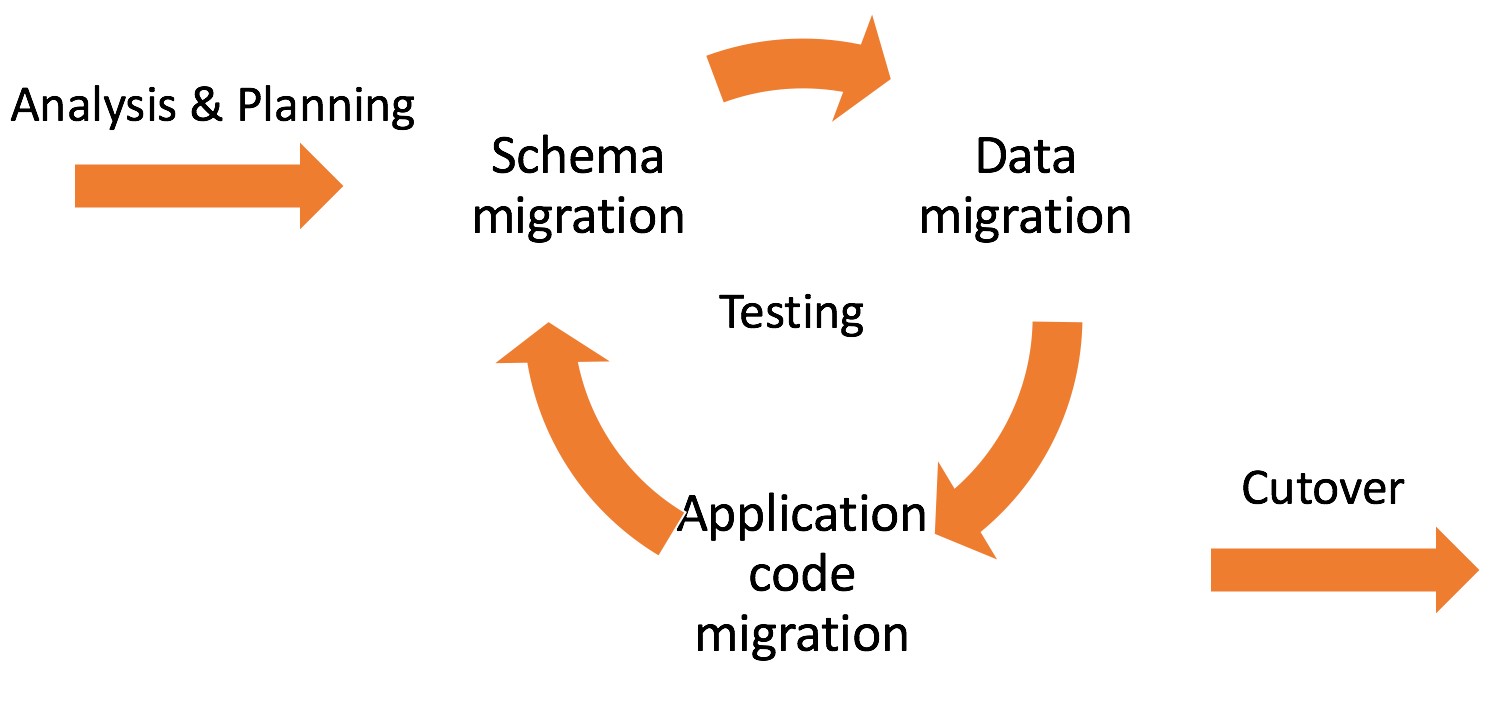
オープンソースデータベースに移行する際に最初に分析するデータベースの優先順位付けは、データベース内で独自のコードがどれくらい使用されているかに左右されます。 使用しているプロプライエタリコードの量は、プロジェクトの移行段階でそれを変換してテストするのにかかる時間に影響します。 カテゴリーと基準を設定した後に、ディクショナリクエリを使用してデータベースをワークロード別に分類できます。
ワークロードを分類するためのフレームワーク
ワークロードは、通常、さらに分析するために5つのカテゴリに分類されます。 このブログでは、カテゴリ1〜3に焦点を当てます。
カテゴリ 1: (ODBC/JDBC)
ODBC(Open Database Connectivity)/ JDBC(Java Database Connectivity)を使用するアプリケーションは、 プロシージャ、ファンクション、トリガー、またはビューで独自のデータベースコードの利用量はとても少ないです。 アプリケーションロジックは、データベース外のコード(例えば、Java、Python、Ruby)にあるため簡単に別のデータベースに移行できます。
カテゴリ2: (独自データベースコードが少ないワークロード)
これらのワークロードでは、アプリケーションレベルのコード(Java、Python、Ruby、bashなど)と独自のデータベースコードを組み合わせて、JavaやPythonで扱いにくい機能を実行します。 経験則として、200未満のプロシージャ/ファンクションがこのカテゴリに分類されます。 高度な機能を使用する場合の許容範囲はさまざまです。 高度な機能を使用すると、ターゲットエンジンへのコードの自動変換が遅くなる可能性があります。 これらのワークロードでは、通常スキーマ設計はかなり簡単です。 テーブルやビューのような基本的なデータ構造を使用します。
カテゴリ3: (独自データベースコードが多いワークロード)
これらのワークロードは、独自のデータベースコードによって完全に実行され、多くの場合、高度な機能が使用されます。 これらのワークロードの多くは、1,000以上の独自の機能を備えています。 また、機能列、マテリアライズド・ビュー、リンクされたサーバーなどの高度なスキーマ機能も使用します。これらのワークロードの課題は、他のフレームワークに変換する際にに多くの作業時間を必要とすることです。 ソースコードで実行されるチューニングオプションは、変換しターゲットエンジンでテストを行う必要があるためです。
カテゴリ4: (ベンダ依存のワークロード)
これらのワークロードは、限定された商用エンジンのサポートのみで動作するフレームワークを使用します。 これらのワークロードをオープンソースに移行することは、アプリケーションを完全に再設計するか、現在サポートされていない高度な機能を必要とします。 機能は移行が非常に難しく、非常に多くの作業時間を消費します。
カテゴリ5: (レガシーワークロード)
これらのワークロードは独自のプログラミングインターフェイスを使用してプログラムを実行します。 例として、Oracle OCIアプリケーションなどが含まれます。 これらは従来のワークロードであることが多く、顧客はこれらのプログラムのソースコードを持っていない可能性があります。 めったに移行されることはありません。
ワークロードの優先度付け
データベースのインベントリを中央のリポジトリに保存しておくと、SQLやスクリプティング言語のような手持ちのツールを使用してポートフォリオ評価を自動化できます。
Oracle
Oracleデータベースの利用が多い場合は、PL / SQLブロックを使用してデータベース内のスキーマをループし、SELECT ANY DICTIONARYが付与されたユーザーに提供される情報を抽出できます。 SQL * Plusを使用し、不要なシステム・スキーマを除外し、コンマで区切られた値のセットをローカル・ファイルmigration_candidates.csvに追加します。 複数のデータベースに適用するには、bashスクリプトまたはプログラムを使用してインベントリシステムまたはファイルから読み込み、スクリプトを繰り返し実行し、同一ファイルに書き込みます。 こちらリポジトリーからOracle用のサンプル・スクリプトをダウンロードできます。
SQL Server
SQL Serverデータベースの利用が多い場合は、SQLブロックを使用してデータベースから読み取り、MSDBおよびsysスキーマから選択する権限を持つユーザーに提供される情報を抽出できます。 SQL Serverデータベースに対してsqlcmdを使用してスクリプトを実行し、コンマ区切りの結果を取得して、ファイルシステムのローカルファイル(migration_candidates.csvなど)に書き込むことができます。 複数のデータベースに適用するには、PowerShellスクリプトまたはプログラムを使用してインベントリシステム、またはファイルから読み取り、同一ファイルに追加するスクリプトを繰り返し実行します。 こちらのリポジトリからSQL Serverのサンプルスクリプトをダウンロードできます。
スクリプトの出力のレビューとカテゴリー分け
すべてのデータベースから結果を取得したら、その結果をMicrosoft Excelまたは別のツールにロードして、データ内のパターンを探します。 次の例では、条件付きデータバーは、ワークロードを分類する際に検討する必要がある度合いを示します。 こちらのリポジトリからサンプルワークロードワークシートをダウンロードできます。
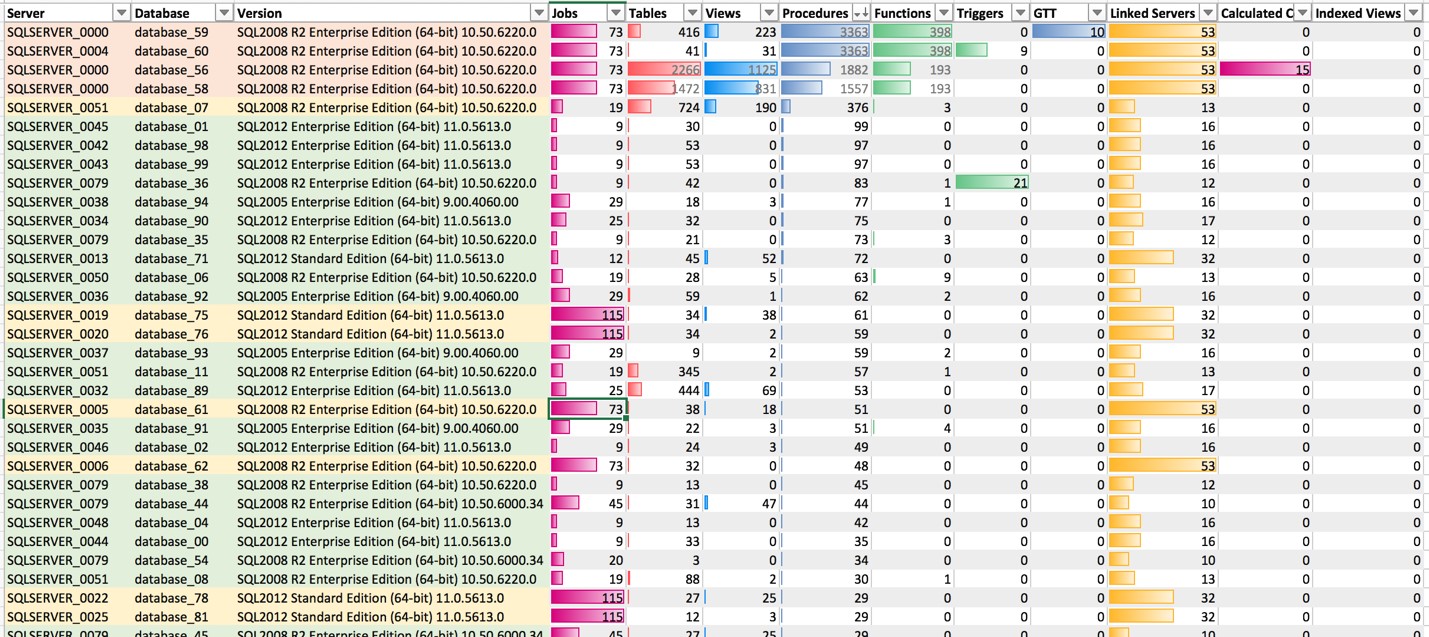
カテゴリ 1
緑で強調表示されたいくつかのワークロードがカテゴリ1と見なされ、分析および移行のためにチームに割り当てる必要があります。 これらのワークロードには、移行が必要なコードオブジェクトがほとんどなく、独自の機能(リンクされたサーバー、ジョブ、索引ビューなど)をほとんど使用しないか、または使用しない単純なスキーマ(たとえば、表やビューの数が少ない)があります。
カテゴリ 2
前述のワークロード例では、黄色で強調表示されているカテゴリ2のワークロードがいくつかあることがわかります。これらのデータベースには、少なくともテストを行うために移行フェーズを延長する可能性のある、かなり多くのプロシージャーや多くの独自機能の利用があります。
カテゴリ 3
ワークロード例の1行目〜4行目には、カテゴリ3に分類されるオレンジ色のワークロードが表示されています。これらのデータベースは1,000以上のプロシージャーとファンクションがあり、複雑な構造とジョブやリンクサーバーなどの高度な機能を持っています。
チーム毎の課題
移行パイプラインの概要を確認したので、チームが作業にどのように取り組むか計画をすることができます。 次の例でチームAは、カテゴリ1の移行に重点を置いています。 彼らは迅速に幾つかの移行を完了、パイプラインを次々と移動させます。 チームBは、移行フェーズでは追加の時間を費やす必要があるカテゴリ2の移行を行い、チームCは、同じ時間枠でより複雑なカテゴリ3の移行の内1つを行うことになります。
各マイグレーションは、分析とスキーマ、データ、およびカットオーバーのためのアプリケーションの移行の計画までのすべての移行フェーズを実行します。 しかし、各チームは必要な作業量に基づいて異なるペースで動きます。

まず、カテゴリ1の移行を対象にすることで、そこで学んだことを後のプロジェクトにすぐに反映させることができます。 大規模なプロジェクトを開始する場合は、拡大したプロジェクトに取り組む前に、チームに勢いを与えることになります。 すべてのプロジェクトを追跡し、作業のパイプラインを維持することで、チームの関与が維持され、全体の進捗状況に関連したステータスを把握することができます。 全体的な結果は、通常、プロジェクトの利害関係者にとって最大の関心事です。 こちらのリポジトリからサンプル計画シートをダウンロードできます。
まとめ
1つの作業としてオープンソースエンジンへの全体的な移行を見ると非常に難しい作業に感じるかもしれません。 作業を最初のハイレベルな評価段階で管理可能サイズに細分化し、最初に速移行可能な物をターゲットにし、全体的なステータスを報告することで、移行の作業パイプラインを管理しし、チームを時間通もしくは早期に作業を完了させることに集中させることができます。
About the Author
 Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.
Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.
翻訳は星野が担当しました。原文はこちら。