Amazon Web Services ブログ
Amazon EMR on Amazon EKS 上の Apache Spark アプリケーションを使用した依存関係のカスタマイズとパッケージ化
前回の AWS re:Invent では、Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) の一般提供が発表されました。これは、Amazon EMR 上での Apache Spark のプロビジョニングと管理の自動化が可能な Amazon EMR の新しいデプロイオプションです。
Amazon EMR on EKS では、他のタイプのアプリケーションと同じ Amazon EKS クラスターに EMR アプリケーションをデプロイできるので、リソースを共有し、すべてのアプリケーションを運用および管理する単一のソリューションで標準化できます。Kubernetes で Apache Spark を実行しているお客様は、EMR on EKS に移行し、パフォーマンス最適化ランタイム、インタラクティブジョブのための Amazon EMR Studio との統合、パイプライン実行を目的とした Apache Airflow および AWS Step Functions との統合、デバッグ用の Spark UI を活用できます。
ジョブを送信すると、EMR は、ビッグデータフレームワークを使用してアプリケーションをコンテナに自動的にパッケージ化し、他の AWS のサービスと統合するための事前構築済みのコネクタを提供します。そして、EMR はアプリケーションを EKS クラスターにデプロイし、ジョブの実行、ログ記録、モニタリングを管理します。現在 Apache Spark ワークロードを実行し、他の Kubernetes ベースのアプリケーションに Amazon EKS を使用している場合は、EMR on EKS を使用して、同じ Amazon EKS クラスター上でこれらを統合し、リソース使用率の改善とインフラストラクチャ管理の簡素化を実現できます。
コンテナ化されたビッグデータ分析ワークロードを実行するデベロッパーからは、イメージをポイントするだけで実行できれば望ましいという意見が寄せられています。現在、EMR on EKS では、ジョブの送信中、外部に保存されたアプリケーションの依存関係が動的に追加されます。
Amazon EMR on EKS のカスタマイズ可能なイメージがサポートされるようになったので、お客様は、EKS クラスターで Apache Spark を使用して分析アプリケーションを実行する Docker ランタイムイメージを変更することが可能になりました。
カスタマイズ可能なイメージでは、独自の継続的インテグレーション (CI) パイプラインを使用して、パフォーマンス最適化された EMR Spark ランタイムに基づいて、アプリケーションとその依存関係の両方を含むコンテナを作成できます。これにより、イメージの構築に要する時間が短縮され、ローカル開発またはテストでのコンテナ起動を予測することが可能になります。
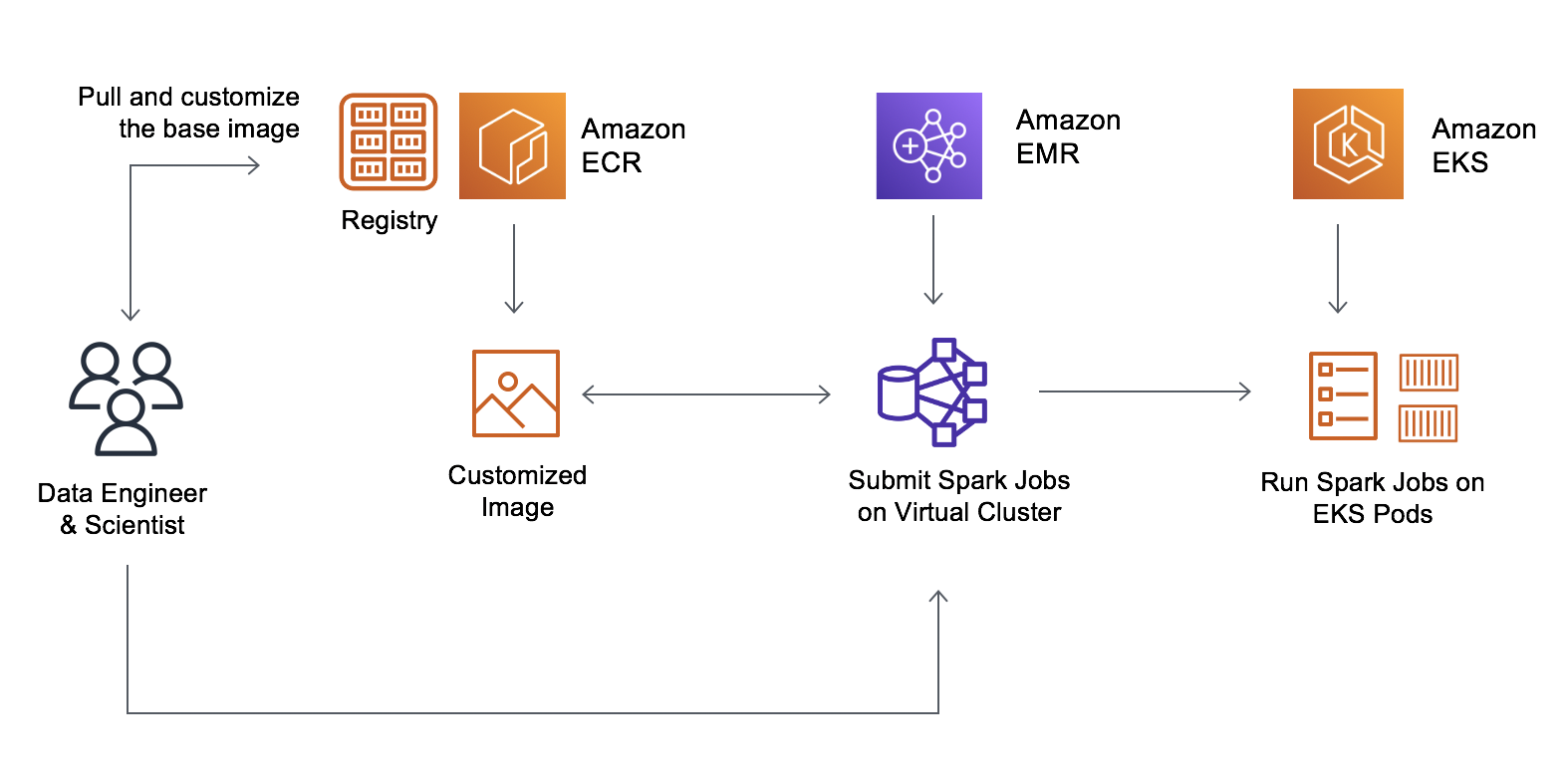
この機能により、データエンジニアとプラットフォームのチームは、ベースイメージを作成し、企業の標準ライブラリを追加して、Amazon Elastic Container Registry (Amazon ECR) に保存できるようになりました。データサイエンティストは、イメージをカスタマイズして、アプリケーション固有の依存関係を含めることができます。結果として生じるイミュータブルイメージは、脆弱性スキャンの実行とテスト環境および実稼働環境へのデプロイが可能です。デベロッパーは、カスタマイズされたイメージをポイントして、EMR on EKS で実行できるようになりました。
カスタマイズ可能なランタイムイメージ – 開始方法
カスタマイズ可能なイメージの使用を開始するには、AWS Command Line Interface (AWS CLI) を使用して以下の手順を実行します。
- Amazon EMR に EKS クラスターを登録します。
- EMR が提供するベースイメージを Amazon ECR からダウンロードし、アプリケーションおよびライブラリでイメージを変更します。
- カスタマイズしたイメージを Amazon ECR などの Docker レジストリに公開し、イメージを参照してジョブを送信します。
次のいずれかのベースイメージをダウンロードできます。これらのイメージには、EMR ジョブ API を使用してバッチワークロードを実行するために使用できる Spark ランタイムが含まれています。使用可能な最新のイメージの完全なリストについては、こちらを参照してください。
| リリースラベル | Spark Hadoop バージョン | ベースイメージタグ |
| emr-5.32.0-latest | Spark 2.4.7 + Hadoop 2.10.1 | emr-5.32.0-20210129 |
| emr-5.33-latest | Spark 2.4.7-amzn-1 + Hadoop 2.10.1-amzn-1 | emr-5.33.0-20210323 |
| emr-6.2.0-latest | Spark 3.0.1 + Hadoop 3.2.1 | emr-6.2.0-20210129 |
| emr-6.3-latest | Spark 3.1.1-amzn-0 + Hadoop 3.2.1-amzn-3 | emr-6.3.0:latest |
これらのベースイメージは、ECR レジストリアカウント、AWS リージョンコード、ベースイメージタグ (米国東部 (バージニア北部) の場合) を組み合わせるイメージ URI と共に各 AWS リージョンの Amazon ECR リポジトリに配置されています。
755674844232.dkr.ecr.us-east-1.amazonaws.com/spark/emr-5.32.0-20210129
Amazon ECR リポジトリにサインインし、イメージをローカルワークスペースにプルします。ネットワークレイテンシーを減らすために別の AWS リージョンからイメージをプルする場合は、米国西部 (オレゴン) リージョンからイメージをプルする場所に最も近い別の ECR リポジトリを選択します。
$ aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 895885662937.dkr.ecr.us-west-2.amazonaws.com
$ docker pull 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129EMR が提供するベースイメージを使用してローカルワークスペースに Dockerfile を作成し、イメージをカスタマイズするコマンドを追加します。アプリケーションにカスタム Java SDK、Python、または R ライブラリが必要な場合は、他のコンテナ化されたアプリケーションと同様に、それらをイメージに直接追加できます。
次の Docker コマンド例は、Spark と Pandas を使用して、自然言語処理 (NLP) などの便利な Python ライブラリをインストールするユースケース用です。
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129
USER root
### ここにカスタマイズを追加 ####
RUN pip3 install pyspark pandas spark-nlp // Install Python NLP Libraries
USER hadoop:hadoop前述したように、別のユースケースでは別のバージョンの Java をインストールできます (Java 11 など)。
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129
USER root
### ここにカスタマイズを追加 ####
RUN yum install -y java-11-amazon-corretto // Install Java 11 and set home
ENV JAVA_HOME /usr/lib/jvm/java-11-amazon-corretto.x86_64
USER hadoop:hadoopJava のバージョンを 11 に変更する場合は、Spark の Java 仮想マシン (JVM) オプションも変更する必要があります。ジョブを送信するときに、applicationConfiguration で次のオプションを指定します。Java 11 では一部の Java 8 JVM パラメータがサポートされていないため、これらのオプションが必要です。
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.driver.defaultJavaOptions" : "
-XX:OnOutOfMemoryError='kill -9 %p' -XX:MaxHeapFreeRatio=70",
"spark.executor.defaultJavaOptions" : "
-verbose:gc -Xlog:gc*::time -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:OnOutOfMemoryError='kill -9 %p' -XX:MaxHeapFreeRatio=70
-XX:+IgnoreUnrecognizedVMOptions"
}
}
]EMR on EKS でカスタムイメージを使用するには、カスタマイズしたイメージを公開し、利用可能な Spark パラメーターを使用して Amazon EMR on EKS で Spark ワークロードを送信します。
カスタマイズした Spark イメージを使用して、バッチワークロードを送信できます。StartJobRun API または CLI を使用してバッチワークロードを送信するには、spark.kubernetes.container.image パラメーターを使用します。
$ aws emr-containers start-job-run \
--virtual-cluster-id <enter-virtual-cluster-id> \
--name sample-job-name \
--execution-role-arn <enter-execution-role-arn> \
--release-label <base-release-label> \ # Base EMR Release Label for the custom image
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "local:///usr/lib/spark/examples/jars/spark-examples.jar",
"entryPointArguments": ["1000"],
"sparkSubmitParameters": [ "--class org.apache.spark.examples.SparkPi --conf spark.kubernetes.container.image=123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_custom"
]
}
}'kubectl コマンドを使用して、ジョブがカスタムイメージを実行していることを確認します。
$ kubectl get pod -n <namespace> | grep "driver" | awk '{print $1}'
Example output: k8dfb78cb-a2cc-4101-8837-f28befbadc92-1618856977200-driverドライバーポッド (jq を使用) でメインコンテナのイメージを取得します。
$ kubectl get pod/<driver-pod-name> -n <namespace> -o json | jq '.spec.containers
| .[] | select(.name=="spark-kubernetes-driver") | .image '
Example output: 123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_customAmazon EMR コンソールでジョブを表示するには、[EMR on EKS] で [Virtual clusters] (仮想クラスター) を選択します。仮想クラスターのリストから、ログを表示する仮想クラスターを選択します。[Job runs] (ジョブ実行) テーブルで [View logs] (ログの表示) を選択して、ジョブ実行の詳細を表示します。

CI プロセスとワークフローの自動化
EMR が提供するベースイメージをカスタマイズしてアプリケーションを含めることにより、アプリケーションの開発と管理を簡素化することができるようになりました。カスタムイメージでは、既存の CI プロセスを使用して依存関係を追加できるので、Spark アプリケーションとそのすべての依存関係を含む単一のイミュータブルイメージを作成できます。
Amazon EMR イメージに対する脆弱性スキャンなど、既存の開発プロセスを適用できます。EMR 検証ツールを使用して、正しいファイル構造とランタイムバージョンを検証することもできます。EMR 検証ツールは、ローカルで実行するか、CI ワークフローに統合することができます。
Amazon EMR on EKS の API は、AWS Step Functions や AWS Managed Workflows for Apache Airflow (MWAA) のようなオーケストレーションサービスと統合するので、自動ワークフローに EMR カスタムイメージを含めることができます。
今すぐご利用いただけます
Amazon EMR on EKS が利用可能なすべての AWS リージョンで、カスタマイズ可能なイメージをセットアップできるようになりました。カスタムイメージには追加料金は必要ありません。詳細については、Amazon EMR on EKS 開発ガイド、および Amazon EMR on EKS で Spark ジョブを実行するための独自のイメージを構築する方法に関するデモビデオをご覧ください。
Amazon EMR の AWS フォーラム、または通常の AWS サポート担当者を通じてフィードバックをお寄せください。
— Channy