Amazon Web Services ブログ
Amazon Comprehend MedicalとAmazon Rekognitionを使用した医療画像の匿名化
現代医学において医療画像は、臨床医が患者の診察と治療のための重要な情報を可視化する基本的なツールです。医療画像のデジタル化により、これらの画像を確実に保存、共有、表示、検索、整理する能力が大幅に向上し、医療従事者を支援しています。医療画像のためのモダリティの数も増加しています。CTスキャンからMRI、デジタル病理学、超音波まで、医療画像アーカイブに収集された膨大な量の医療データがあります。
これらの医療画像はまた、医学研究に有用です。機械学習を利用することで、世界中の医療研究機関の科学者は数十万または数百万もの画像データを解析して、医学的問題への深い洞察を得る事が可能です。医療従事者にとって、医療保険の相互運用性と説明責任に関する法令 (HIPAA)のような規制を遵守しながら、このような医療画像をどう扱うかが課題となっています。多くの場合、医療画像には画像自身にテキストとして保存されている保護対象医療情報(PHI)が含まれています。匿名化と呼ばれるPHIを除去するプロセスは、手作業で画像の確認と編集が必要となるため、歴史的に課題として挙げられてきました。この作業は画像1枚あたり何分もかかってしまい、大規模なデータセットの匿名化となると多くの時間と費用がかかります。2017年にAmazon Web Services (AWS)は、機械学習サービスであるAmazon Rekognitionを使用して画像から簡単にテキストを検出、抽出する事ができる事を発表しました。2018年には、テキスト内にあるPHIの検出と識別をサポートするAmazon Comprehend Medical と呼ばれる、医療テキストのための自然言語処理(NLP)の新しい機械学習サービスを発表しました。これら2つのサービスと数行のPythonコードで、blog記事で示しているような医療画像からPHIを安価かつ迅速に検出、識別、マスクする事ができます。
匿名化のアーキテクチャ
この例では、Amazon SageMakerのJupyter Notebooksを利用してPythonコードでインタラクティブなノートブックを作成します。 Amazon SageMakerは事前にビルドされたJupyter notebookとアルゴリズムを使用して、迅速に学習用データの準備と機械学習モデルのビルドができるエンドツーエンドの機械学習プラットフォームです。このblog記事では、実際の機械学習と予測について、Amazon Rekognitionで画像からテキストを抽出し、Amazon Comprehend MedicalでPHIの特定と検出をしています。全てのイメージファイルは、Amazon Simple Storage Service (Amazon S3)という業界トップのスケーラビリティ、データの可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスのバケットから読み書きされます。
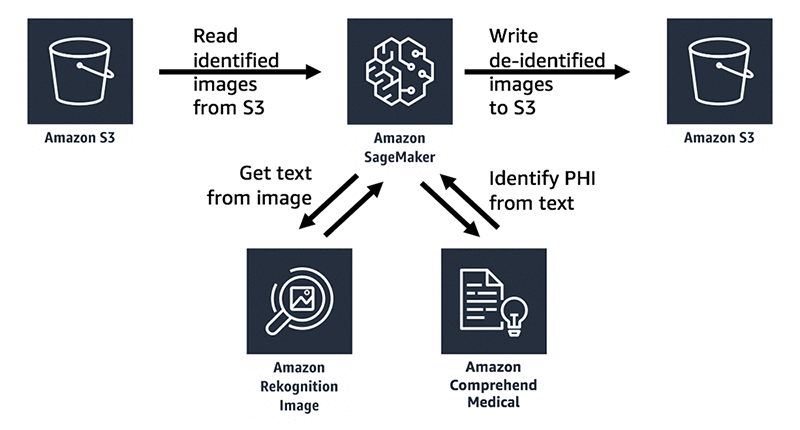
Amazon Comprehend Medical を使用して保護された医療情報を検出・識別する際に留意すべきことは、識別されたエンティティごとに、そのサービスは検出したエンティティの精度に対する信頼度を示す信頼スコアを提供している点です。これらの信頼スコアを考慮に入れて、識別されたエンティティがあなたのユースケースに合致しており適切であるかを確認してください。信頼性スコアの詳細については、 Amazon Comprehend Medicalのドキュメントを参照してください。
Notebookの利用
このblog記事のJupyter NotebookはGitHubからダウンロードできます。
このnotebookは、NIH Clinical Centerによって提供されたデータセットの胸部X線画像の例を示しています。このデータセットは、こちらのリンクからダウンロード可能です。 詳細については、NIH Clinical CenterのCVPR 2017 paperを参照してください。
notebookを開始するにあたり、この例では以下の調整可能な5つのパラメータを利用して匿名化プロセスを制御します。
- bucketは、読み書きされる画像が格納されたAmazon S3バケットを定義します。
- objectは、匿名化したい識別画像を定義します。PNG, JPG , DICM形式の画像が利用可能です。オブジェクト名が拡張子.dcmで終わっていれば、その画像はDICOM画像であるとみなされ、ImageMagickユーティリティによって、識別処理を行う前にPNGに変換されます。
- redacted_box_colorは 、画像内の識別されたPHIテキストをマスクする際の色を定義します。
- dpiは、出力する画像で使用するdpi設定を定義します。
- phi_detection_thresholdは、前述した信頼スコアの閾値です(0.00から1.00の間)。Amazon Comprehend Medicalで検出・識別されたテキストは、出力画像からマスクされるように設定した最小信頼スコアを満たす必要があります。デフォルト値は0.00で、この値は信頼スコアとは関係なく、Amazon Comprehend MedicalがPHIと識別して検出した全てのテキストをマスクします。
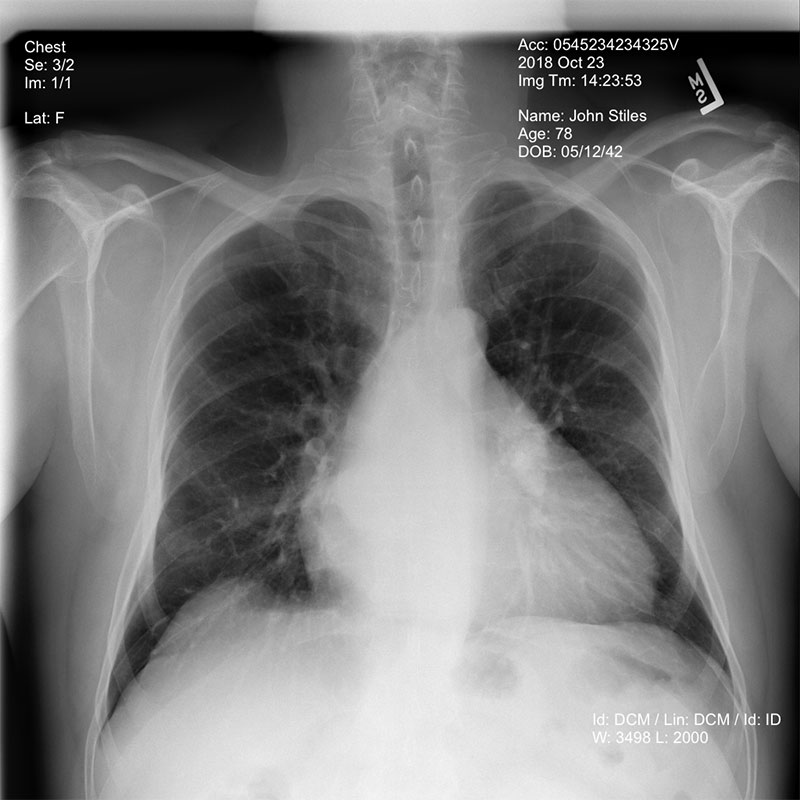
これらのパラメータを設定した後は、Jupyter Notebook内の全てのセルを実行できます。最初のセルは、必要に応じて、指定した画像ファイルをDICOM形式からPNGへ変換し、S3から得たファイルをメモリに読み込みます。
それから、その画像をAmazon Rekognitionに送り、 DetectText機能を利用してテキストを検出します。Amazon Rekognitionは、画像内で検出されたテキストブロックのリストと、テキストブロックごとに定義されたBounding BoxをJSONオブジェクトとして返します。これにより、画像内のテキストの位置がわかります。
画像内の全てのテキストが検出された後、Amazon Comprehend Medicalへテキストを送信し、DetectPHI機能を使用してPHIが含まれる可能性のあるテキストブロックを判定します。Amazon Comprehend MedicalはPHIの可能性のあるエンティティ、つまりテキストだと思われる情報の種類(名前、日付、住所、ID)や、検出ごとに信頼スコアを定義したJSONオブジェクトを返します。これにより、どのBounding boxにPHIが含まれているかを判定できます。
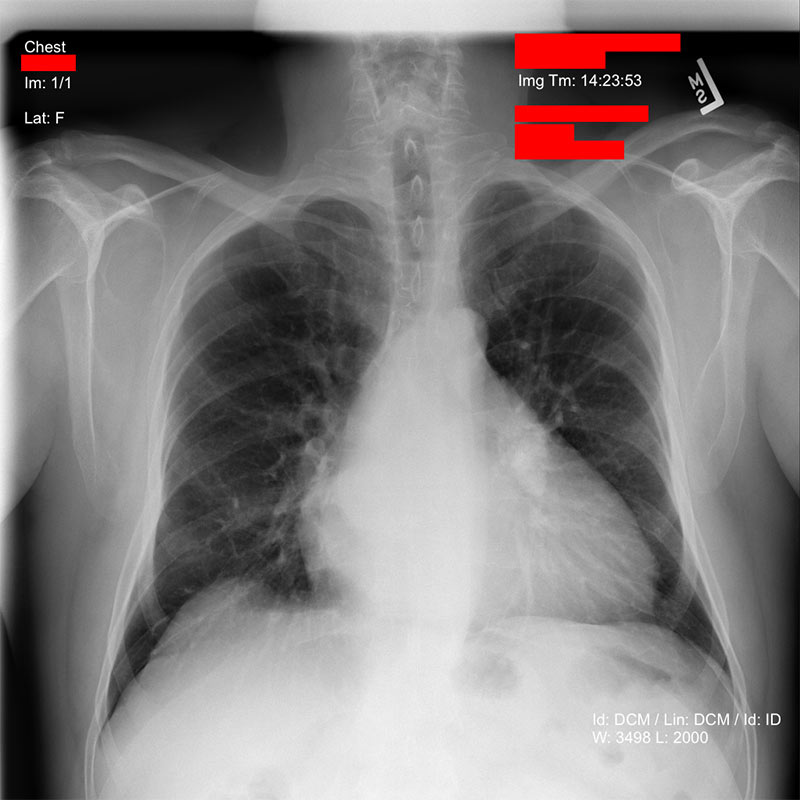
PHIテキストが画像のどの領域に含まれているかが判明したら、その領域をマスクします。
匿名化した画像は指定したS3バケットへ、PNG形式で、元のファイル名の前に「de-id-」というテキストを付けて、書き込まれます。
結論
このblog記事では、事前学習済み機械学習モデルを使用することについてのパワーとアジリティについてご紹介しました。AIサービスを組み合わせて複雑なタスクを実行するのは、それほど多くの開発を必要としません。Amazon SageMaker notebookといった、事前設定された機械学習開発環境でこれらのサービスを使用することで、フルマネージドなインフラストラクチャ上でソフトウェア開発ライフサイクル全体を実行できます。
Amazon SageMaker notebookでこの例を実行することで、ここで使用されているプロセスを理解して結果を確認するのに理想的な環境が提供されます。さらに、数千から数百万もの画像をバッチ処理する場合は、AWS LambdaまたはAWS Batchを使用して同じコードを実装できます。このコードを含むLambda関数をAmazon S3バケットと関連付ける ことで、新しいイメージが追加されるたびに画像を匿名化することもできます。
翻訳:Solution Architect 小泉 秀徳
原文:https://aws.amazon.com/jp/blogs/machine-learning/de-identify-medical-images-with-the-help-of-amazon-comprehend-medical-and-amazon-rekognition/