Amazon Web Services ブログ
AWS DeepLens ディープラーニングと新しいビデオカメラによるハンズオン
過去一度か二度お伝えしましたとおり、私は生涯学習を強く信じる人です。技術の変化は今までよりも早くやってきており、あなたの現在のスキルを追従させるためにあなたも同じことをする必要があります。
私の経歴のほとんどにおいて、人工知能は学術的なトピックであり、実用的なアプリケーションや実世界への展開は”もう間もなく”というものでした。私はコンピュータービジョンやディープラーニングといった機械学習の実用的なアプリケーションの数をもって、人工知能はもうやってきたということができると思いますし、今はハンズオンを開始し、あなたのスキルを磨く時だと思います。また、どちらもより最新で少ない時間で生まれた一方、IoTとサーバレスコンピューティングはここにあり、あなたのリストにあるべきだと言えます。
New AWS DeepLens
今日(2017/11/29 PST)、AWS DeepLensという、ディープラーニングモデルをデバイスで直接で実行する新しいビデオカメラが出 たことをお伝えします。あなたはこれを使ってAI、IoT、サーバレスコンピューティングのハンズオンを体験し、クールなアプリを構築できます。AWS DeepLensは最先端のハードウェアと洗練されたソフトウェアをあわせもち、あなたはAWS Greengrass、AWS Lambda、そしてそのほかのAWS AIやアプリ上のインフラを活用できます。
たことをお伝えします。あなたはこれを使ってAI、IoT、サーバレスコンピューティングのハンズオンを体験し、クールなアプリを構築できます。AWS DeepLensは最先端のハードウェアと洗練されたソフトウェアをあわせもち、あなたはAWS Greengrass、AWS Lambda、そしてそのほかのAWS AIやアプリ上のインフラを活用できます。
ハードウェアから始めましょう。私達はたくさんのパワーをこのデバイスに詰め込みました。2Dのマイクアレイが付随した、1080Pの動画を撮影できる4メガピクセルのカメラがあります。インテルのAtom®プロセッサが100GLOPSを超える、動画をデバイス上のディープラーニングモデルを通して秒間数十フレームで処理するのに十分なコンピューティングパワーを提供します。DeepLensはデュアルバンドのWi-Fi、USBとmicro HDMIポートと接続できます。さらに、学習済みのデータとあなたのコードのための8ギガバイトのメモリがコンパクトなデバイスでありながらこれを強力なものにしています。
ソフトウェアの観点。AWS DeepLensはUbuntu 16.04で実行し、GreenGrass Core(Lambda runtime, メッセージマネージャ、その他)がプレロードされています。また、MXnetのデバイス最適化バージョン、TensorFlowやCaffe2などの他のフレームワークを使用する柔軟性もあります。Intel clDNNライブラリは、コンピュータビジョンおよびその他のAIワークロード用の深い学習プリミティブのセットを提供し、加速した推論のためにIntel Atom® Processorの特別な機能を利用します。
私達はまたデータを提供します!DeepLens上で動作するアプリを構築するとき、画像検出と認識のために一連の学習済みモデルを利用できます。これらのモデルは猫や犬、顔、幅広い家庭や日常の物体、動作や行動、ホットドッグでさえ検出することに役立ちます。私達はこれらのモデルを学習し続け、これをさらに良くしていきます。こちらが最初のモデルの一覧です。

このハードウェア、ソフトウェア、およびデータはすべて、AWS DeepLensをエッジデバイスの好例にするためにまとめられています。目、耳、そして非常に強力な脳がすべてフィールドに配置され、アクションに近い場所に配置されているため、オンボードの深い学習モデルを通じてビデオと音声を素早く低遅延で実行することができ、 クラウドを利用してより多くのコンピューティング集約的な高水準処理を実現します。たとえば、DeepLensで顔検出を行い、Amazon Rekognitionに顔認識をさせることができます。
この装置は壮大な学習機会です! また、サンプルコード(Lambda関数)をそのまま使用したり、離れて学習したり、独自の関数の基礎として使用したりすることができます。 クールで便利なものを作ってしまえば、それをプロダクション形式で展開することができます。 私たちはAWS DeepLensが堅牢で安全であることを確認しました。各デバイスに固有の証明書と、AWSサービスとリソースへのアクセスに対するきめ細かなIAMを備えています。
デバイスの登録
DeepLens Consoleからデバイスを登録して使用できる状態にするプロセスについて説明します。 デバイスの登録をクリックしてください:
 カメラの名前を設定し、Nextをクリックします
カメラの名前を設定し、Nextをクリックします
 次にDownload certificateをクリックし、証明書を安全な場所に保管します
次にDownload certificateをクリックし、証明書を安全な場所に保管します
 次に必要なIAM Roleを作成(コンソールの利用が簡単です)、それぞれ一つづつに必要な権限を割り当てます
次に必要なIAM Roleを作成(コンソールの利用が簡単です)、それぞれ一つづつに必要な権限を割り当てます
 これからDeepLensの作業に入ります!電源を入れ、ノートパソコンをデバイスのネットワークに接続し、組み込みのポータルにアクセスしてプロセスを完了します。 コンソールには次の手順が記載されています。
これからDeepLensの作業に入ります!電源を入れ、ノートパソコンをデバイスのネットワークに接続し、組み込みのポータルにアクセスしてプロセスを完了します。 コンソールには次の手順が記載されています。
 私のDeepLensは完全機能のエッジデバイスとなりました。 デバイス上の証明書によって、AWSへの安全な署名付き呼び出しを行うことができます。 Greengrass Coreが動作しており、Lambda関数を受け入れて実行する準備ができています。
私のDeepLensは完全機能のエッジデバイスとなりました。 デバイス上の証明書によって、AWSへの安全な署名付き呼び出しを行うことができます。 Greengrass Coreが動作しており、Lambda関数を受け入れて実行する準備ができています。
DeepLensプロジェクトの作成
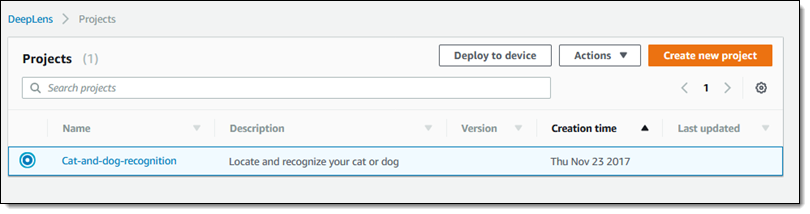
接続とセットアップが完了したので、プロジェクトの作成が可能となりました。ナビゲートからProjectsを選び、Create new projectを選択します
 そしてテンプレートプロジェクトもしくはブランクのプロジェクトを選択します。ここでは、cat and dog recognitionを選択しNextをクリックします
そしてテンプレートプロジェクトもしくはブランクのプロジェクトを選択します。ここでは、cat and dog recognitionを選択しNextをクリックします
 コンソールでプロジェクト名称の設定とカスタマイズができます。ご覧のとおり、Lambda関数と事前学習されたモデルをさん称することができます。デフォルトのままで良さそうなので、ここでは単純にCreateを行います。
コンソールでプロジェクト名称の設定とカスタマイズができます。ご覧のとおり、Lambda関数と事前学習されたモデルをさん称することができます。デフォルトのままで良さそうなので、ここでは単純にCreateを行います。
 これでカメラにdeployをするだけです。
これでカメラにdeployをするだけです。
 Cats and Dogsモデルのトレーニング
Cats and Dogsモデルのトレーニング
関数はカメラ上で実行され、出力をMQTTトピックにパブリッシュします。 ここでは、猫と犬の認識機能の内部ループから抜粋しています(私はエラーハンドリングを削除しました):
while doInfer:
# Get a frame from the video stream
ret, frame = awscam.getLastFrame()
numFrames += 1
# Resize frame to fit model input requirement
frameResize = cv2.resize(frame, (224, 224))
# Run model inference on the resized frame
inferOutput = model.doInference(frameResize)
# Publish a message to the cloud for every 100 frames
if numFrames >= 10:
msg = "Infinite inference is running. Sample result of the last frame is\n"
# Output inference result of the last frame to cloud
# The awsca module can parse the output from some known models
outputProcessed = model.parseResult(modelType, inferOutput)
# Get top 5 results with highest probiblities
topFive = outputProcessed[modelType][0:2]
msg += "label prob"
for obj in topFive:
msg += "\n{} {}".format(outMap[obj["label"]], obj["prob"])
client.publish(topic=iotTopic, payload=msg)
numFrames = 0;
プログラムは変更することも出来ますし、一から作成することも出来ます。これまで見ていただいように始めるのは簡単です。
あなたがDeepLendsを手に入れたら何を思いつくでしょうか?
詳細を知りDeepLendsを手に入れるために、re:Inventで開催される16のワークショップのどれかに参加してください。
先行予約
当初、米国でAWS DeepLensを2018年に出荷する予定です。 価格と在庫状況の詳細、またはご予約の詳細については、DeepLensのページをご覧ください。
–jeff
翻訳はSA園田が担当しました。
原文はこちら