Amazon Web Services ブログ
Amazon QuickSight ML insight を使用して詐欺電話を検出する
どの業界でも詐欺が経済に及ぼす影響は非常に大きいです。Financial Times の記事、電気通信業界の詐欺費用は年間 170 億 USD (有料サブスクリプションが必要) によると、電気通信業界は詐欺によって毎年 170 億 USD の損失を被っています。
詐欺師は常に新しいテクノロジーを探し、新しい技術を考案しています。これにより詐欺パターンが変わるため、検知が難しくなります。企業は通常、ルールベースの詐欺検知システムで対応しています。しかし、詐欺師が現在の技術やツールが特定されていることに気づくと、すぐにそれを回避する方法を見つけてしまいます。また、ルールベースの検知システムは、大量のデータを使用するときに苦労し、処理速度が低下します。これによって詐欺を発見し、迅速に行動することが難しくなります。その結果、収入に対して損失を被ることになります。
概要
異常検知を実装し、詐欺に対応するために使用する AWS サービスには色んなものがありますが、次の 3 つに焦点を当てたいと思います。
詐欺行為を検知しようとすると、高レベルの課題が 2 つ発生します。
- スケール – 分析するデータの量。たとえば、各通話は呼詳細レコード (CDR) イベントを生成します。これらの CDR には、発信電話番号および着信電話番号、通話時間など、さまざまな情報が含まれています。これらの CDR イベントに 1 日にかけられる通話回数分の電話を掛けた、オペレーターが管理しなければならない規模に関するアイデアを得ることができます。
- 機械学習の知識とスキル – 機械学習でビジネス上の問題を解決するのに役立つ適切なスキルセットです。これらのスキルを磨いたり、十分な専門知識を持った有資格のデータサイエンティストを雇ったりするのは簡単ではありません。
Amazon QuickSight ML Insight の紹介
Amazon QuickSightは、リッチでインタラクティブなダッシュボードにより組織内のすべての人がデータからビジネスに役立つインサイトを簡単に手に入れることができる高速クラウドベースの BI サイトです。セッションごとに料金が発生する仕組みとアプリケーションに組み込むダッシュボードによって、BI はさらに費用対効果が高くなり、誰もがアクセスできます。
しかし、顧客が生み出すデータの量が日々増えるにつれて、ビジネスのインサイトのためにデータを活用することがますます大変になっています。こうした背景から機械学習が役に立つようになりました。 Amazon は機械学習を使用して、サプライチェーン、マーケティング、小売業、および財務におけるビジネス分析の多様な側面を自動化し拡張する先駆者です。
ML Insight は実績のある Amazon テクノロジーを Amazon QuickSight に統合して、視覚化を超えて ML を活用したインサイトを顧客に提供しています。
- ML を活用した異常検知は、数十億のデータポイントを連続的に分析することで、隠されたインサイトを顧客が発見するのに役立ちます。
- ML を活用した予測と what-if 分析は、簡単なポイントアンドクリックでビジネスのメトリックを予測できます。
- 顧客がダッシュボードの話をやさしい言葉で伝えるのに役立つ自動ナラティブ
この記事では、ML の専門知識が皆無かそれに近い状態の電気通信プロバイダーが Amazon QuickSight ML の機能を使用して詐欺通話を検知する方法について説明します。
前提条件
このソリューションを実装するには、以下のリソースが必要です。
- Amazon S3 を使用して、「リボン」通話詳細レコードサンプルを CSV 形式でステージング。
- AWS Glue を使用して、PySpark で ETL ジョブを実行。
- AWS Glue クローラーを使用して、テーブルのスキーマを発見し、AWS Glue Data Catalog を更新。
- Amazon Athena を使用して、Amazon QuickSight データセットをクエリ。
- Amazon QuickSight で、ML Insight を使用して視覚化を構築し、異常検知を実行。
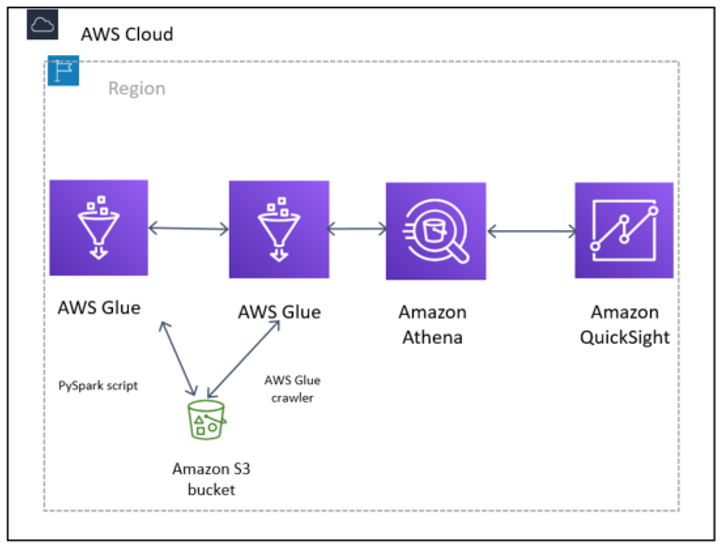
データを準備して Parquet に変換する PySpark スクリプトと、AWS Glue Data Catalog を構築するための AWS Glue クローラーを使用した、詐欺通話検知アーキテクチャの図。
データセット
この記事では、Ribbon Communications のおかげで合成データセットを使用しました。データは通話テストジェネレーターによって生成されたもので、顧客データや機密データではありません。
データの検査
下記の例は典型的な CDR です。次の STOP CDR は、通話が終了した後に生成されます。

ご覧のとおり、ここにはたくさんの値があります。それらのほとんどは、詐欺の特定や防止とは関係ありません。
レベニューシェア詐欺
レベニューシェア詐欺は、今日の電気通信業界を脅かしている最も一般的な詐欺スキームの 1 つです。これは、詐欺番号または盗まれた番号を使用してプレミアム料金の B 番号を繰り返し呼び出すことを含みます。B 番号はその後、発生した現金を詐欺師と共有します。
Amazon QuickSight ML を使用して国内外のレベニューシェア詐欺を検知したいとします。レベニューシェア詐欺電話の典型的な特徴について考えてみましょう。レベニューシェア詐欺のパターンは、同じ B 番号を呼び出す複数の A 番号、または同じプレフィックスを持つ B 番号の範囲にあります。通話時間は通常平均より長く、最大 2 時間に及ぶ可能性があります。これは国際交換機が許可する最大時間です。一般的に、通話は 1 つのセルまたはセルグループから発信されます。
詐欺行為の前ぶれとして、1 つの SIM がさまざまな B 番号に短いテスト電話をかける可能性があります。金曜日の夜、週末、休日など、ほとんどの場合は検出リスクが最も低いときに発生します。電話会議は、1 つの A 番号から複数の同時通話を発信するために使用できます。
多くの場合、このタイプの詐欺に使用される SIM は、同じ販売業者または販売業者のグループからまとめて販売または活性化されています。SIM は、盗まれたクレジットカード番号を使用するなど、オンラインまたは IVR 決済による詐欺を使用して補給される可能性があります。PAYG クレジットとバンドルの両方を使用できます。上記の使用例に基づいて、次の情報では詐欺の検知に最も関連している内容をお届けします。
- 通話時間
- 発信番号 (A 番号)
- 着信番号 (B 番号)
- 通話開始時刻
- アカウント ID
この参照を使用して、CDR 内のフィールドを便利に識別します。
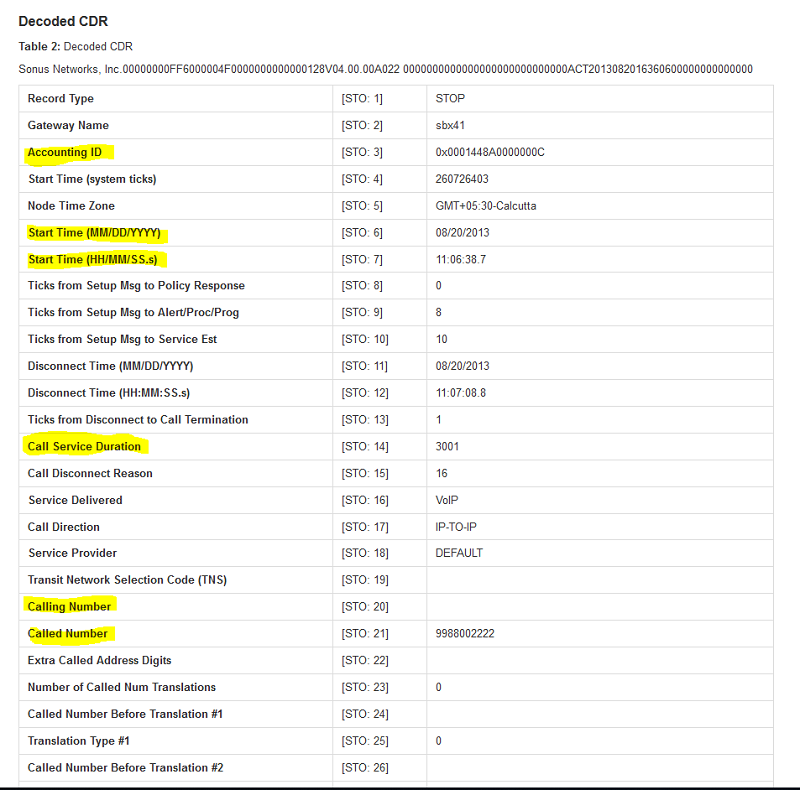
図 2: デコードされた CDR データ。関連するフィールドを強調表示しています。
CDR の 235 列から必要な列を特定しました。
生のサンプルデータを検査してみると、ヘッダーがないことがすぐにわかります。
作業を楽にするために、生の CSV データを変換し、列名を追加して、Parquet に変換しました。
データの発見
AWS Glue コンソールで、クローラーを設定し、CDR_CRAWLER という名前を付けます。
クローラーを、Parquet CDR データが存在する s3://telco-dest-bucket/blog に向けます。
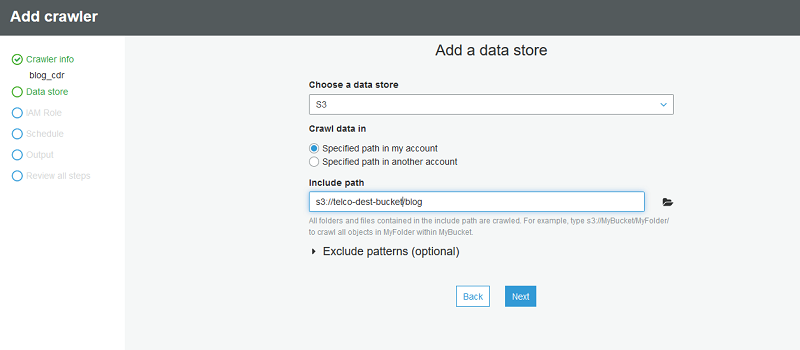
次に、AWS Glue クローラーが使用する新しい IAM ロールを作成します。
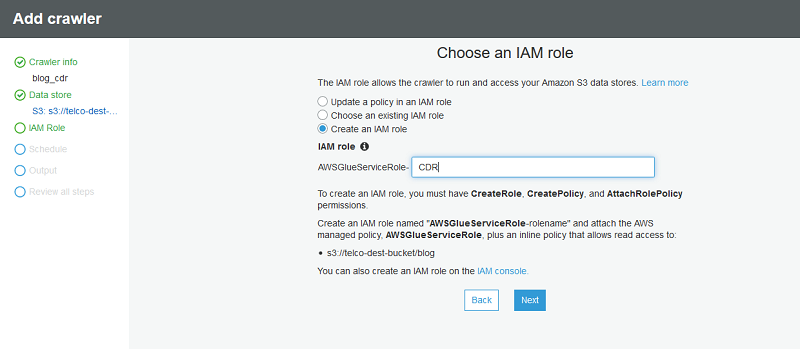
頻度には、デフォルトのオンデマンド実行の定義をそのまま使用します。
次に、[データベースの追加] を選択してデータベースの名前を定義します。このデータベースには、AWS Glue クローラーによって検知されたテーブルが含まれています。
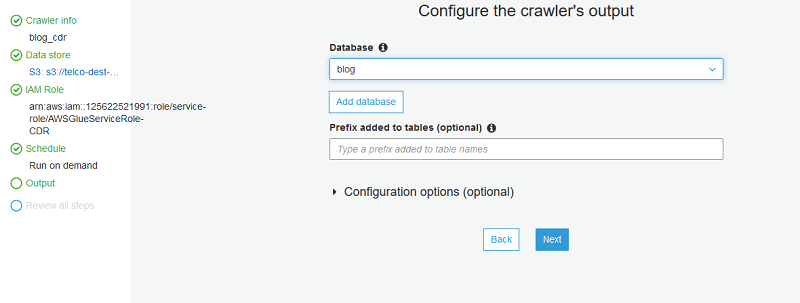
[次へ] を選択して、クローラー設定を確認します。満足したら、[完了] を選択します。
次に、[クローラー] を選択し、作成したクローラー (CDR_CRAWLER) を選択して、[クローラーの実行] を選択します。
AWS Glue クローラーがデータベースのクロールを開始します。完了までに 1 分以上かかることがあります。
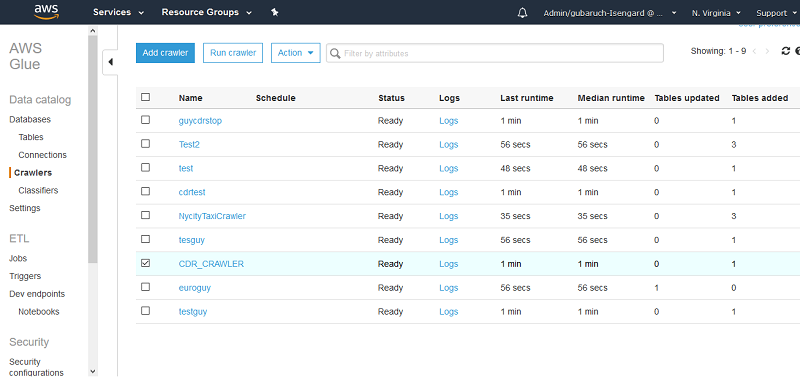
完了したら、[データカタログ] で [データベース] を選択します。 AWS Glue クローラーで作成した新しいデータベースを確認することができます。この例では、データベースの名前は blog です。
このデータベースの下に作成したテーブルを表示するには、関連データベースを選択してテーブルを選択します。クローラーのテーブルでは、Parquet 形式の CDR の場所も示します。
テーブルのスキーマを表示するには、クローラーで作成したテーブルを選択します。
データ準備
詐欺を検知するために ML モデルで使用する関連ディメンションを定義しました。これで、先ほど Amazon SageMaker ノートブックと AWS Glue エンドポイントを使用して構築した PySpark スクリプトを使用できます。スクリプトは以下のタスクを取り扱います。
- データセットを減らして、関連する列のみに注目してください。
- Amazon QuickSight を使用して、分析を作成するために必要なタイムスタンプ列を作成します。
- パフォーマンスを向上させるためにファイルを CSV から Parquet に変換します。
お使いの CDR の生の CSV 形式で PySpark スクリプトを実行することができます。生の CSV 形式の場所は次のとおりです。
s3:/telco-source-bucket/machine-learning-for-all/v1.0.0/data/cdr-stop/cdr_stop.csv
こちらは私が作成した PySpark スクリプトです。
データセットは AWS Glue Data Catalog にカタログ化されており、Athena を使用してクエリできます。
Amazon QuickSight と異常検知
次に、Amazon QuickSight を使用して異常検知を構築します。開始するには、次の手順に従います。
- Amazon QuickSight コンソールで、[新規分析] を選択します。
- 新規データセットの作成をクリック
- Athena を選択
- データソース名を入力
- データソースの作成をクリック
- AWS Glue クローラーで作成した関連データベースとテーブルをドロップダウンリストから選択し、[選択] をクリック
- [データを直接クエリ] を選択して [視覚化] をクリック
Amazon QuickSight を使用してデータを可視化
- ビジュアルタイプの下で、[折れ線グラフ] を選択します。
- call_service_duration を値フィールドにドラッグします。
- timestamp_new を X 軸フィールドにドラッグします。
次のスクリーンショットのように、Amazon QuickSight がダッシュボードを生成します。
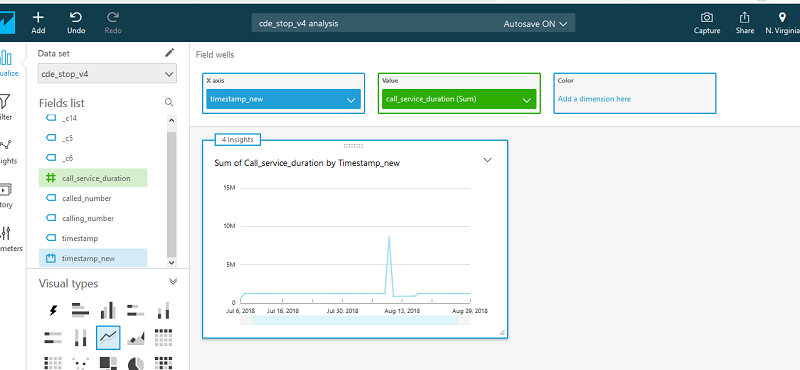
x 軸はタイムスタンプです。デフォルトでは、1 日の集計に基づいています。これは異なる値を選択することで変更できます。

私は現在 1 日の集計を調べるようにタイムスタンプを定義しているので、通話時間は 1 日中の全通話記録での全通話時間の合計です。合計通話時間が長い日を探してから、検索を開始できます。
異常検出
それでは、ML insight 異常検知機能の使用方法をご覧ください。
- インサイトパネルの上部にある、[シートに異常を追加] を選択します。これにより、異常検知のためのインサイトビジュアルが生まれます。
- 次の例のように、画面上部で [フィールドウェル] を選択してカテゴリに 1 つ以上のフィールドを追加します。不正使用の事例に関連するようになったので、発信番号/着信番号を追加しました。たとえば、1 つの A 番号が複数の B 番号を呼び出す、または複数の A 番号が B 番号を呼び出すなどです。

カテゴリは、Amazon QuickSight がメトリクスを分割するためのディメンション値を表します。たとえば、商品カテゴリが 10 個で、それぞれに 10 個の商品 SKU があると仮定します。すべての商品カテゴリと商品 SKU にわたって売上の異常を分析できます。Amazon QuickSight は固有の組み合わせ 100 個でメトリクスを分割し、分割された各メトリクスに対して異常検知を実行します。 - [はじめに] を選択して、異常検知ジョブを設定します。
- 異常検知設定画面で、以下のオプションを設定します。
- これらのカテゴリのすべての組み合わせを分析する – デフォルトでは、3 つのカテゴリを選択した場合、Amazon QuickSight は階層的に A、AB、ABC の組み合わせで異常検知を実行します。このオプションを選択した場合、QuickSight は A、AB、ABC、BC、AC を含むすべての組み合わせを分析します。データが階層的でない場合は、このオプションを確認してください。
- スケジュール – データとニーズに応じて、毎時、毎日、毎週、または毎月、データに対して異常検知を実行するようにオプションを設定します。スケジュールの開始日とタイムゾーンに値を入力して [OK] をクリックします。重要: 分析をダッシュボードとして公開するまで、スケジュールは有効になりません。分析内で、異常検知を手動で (スケジュールなしで) 実行することができます。異常の貢献度分析 – 異常が検知されたときに上位の貢献者を分析するために、Amazon QuickSight で最大 4 つの追加ディメンションを選択できます。例えば、Amazon QuickSight を使用して、売上高の急増に寄与した上位の顧客を表示することができます。現在の例では 1 つの追加ディメンション、つまり、アカウント ID を追加しました。電気通信詐欺について考える場合は、追加ディメンションとして充電時間またはセル ID のようなフィールドも考慮することができます。
- 設定を設定したら、[今すぐ実行] を選択して「異常を検知しています… しばらくお待ちください…」というメッセージを含むジョブを手動で実行します。データセットのサイズによっては、数分から 1 時間かかる場合があります。
- 異常検知ジョブが完了すると、ビジュアルインサイトで異常が指摘されます。デフォルトでは、データ内で直近の期間中に上位を占めた異常のみがインサイトビジュアルに表示されます。

異常検知により、2018 年 8 月 29 日の通話サービス期間中に複数の A 番号から複数の B 番号を呼び出すことが明らかになりました。面白そうですね。 - このインサイトについてすべての異常を調査するには、ビジュアルの右上にあるメニューを選択して [異常の調査] を選択します。
- 異常に関する詳細のページでは、直近の期間に検知された異常のすべてを見ることができます。

このビューでは、2 つの異常が検知され、2 つの時系列を示していることがわかります。ビジュアルのタイトルは、カテゴリフィールドの一意の組み合わせに対して実行されるメトリクスを表します。この場合:
- [All] | 9645000024
- 3512000024 | [ALL] そのため、システムは 9645000024 を呼び出す複数の A 番号、および 351200024 を呼び出す複数の B 番号で異常を検知しました。どちらの場合も、通話時間が長いことがわかりました。チャートのラベル付きデータポイントは、その時系列で検知された最新の異常を表しています。
- 日付ピッカーを表示するには、右上にある [日付別に異常を表示] を選択します。この図では、毎日 (または異常検知設定に応じて 1 時間ごとに) 検知された異常の数を示します。特定の日を選択すると、その日に検知された異常を確認できます。たとえば、上のグラフで 2018 年 8 月 10 日を選択すると、その日の異常が表示されます。

重要: データセットの最初の 32 ポイントはトレーニングに使用されます。異常検知アルゴリズムではスコアリングされません。最初の 32 個のデータポイントでは異常を確認できないかもしれません。画面上部のフィルターコントロールを拡張できます。フィルターコントロールを使用して、異常のしきい値を変更し、高、中、または低の重要度で異常を表示できます。予想より高い、または予想より低い異常のみを表示するように選択できます。データセットに存在するカテゴリ値でフィルターして、それらのカテゴリの異常のみを調べることもできます。 - 貢献者のコラムをご覧ください。異常検知を設定したときに、アカウント ID を別のディメンションとして定義しました。これが練習データではなく実際の通話トラフィックである場合は、異常の原因となっている特定のアカウント ID を選び出すことができます。

- 完了したら、[分析に戻る] を選択します。
まとめ
この記事では、レベニューシェア詐欺と呼ばれる一般的な詐欺パターンについて調べました。Amazon QuickSight で異常検知モデルをトレーニングするための関連データの抽出方法を調べました。次に、このデータを使用して、アカウント ID などの追加貢献者を確認しながら、通話時間、発信当事者、および着信当事者に基づいて異常を検知しました。プロセス全体でサーバーレステクノロジーを使用しており、機械学習の経験は皆無かそれに近い状態でした。
オプションと戦略の詳細については、Amazon QuickSight が ML Insight の一般提供を開始を参照してください。
ご質問またはご提案については、以下でコメントを残してください。
著者について
 Guy Ben Baruch はアマゾンウェブサービスのソリューションアーキテクトです。
Guy Ben Baruch はアマゾンウェブサービスのソリューションアーキテクトです。