Amazon Web Services ブログ
Amazon SageMaker Ground Truth を使って大量ラベル付けの品質保証を簡単に行う
このブログの記事では、大量のデータにラベル付けする機械学習システムを構築したばかりで、ラベルの一部に対して手動の品質保証(QA)を行おうとしている皆さんにご覧いただきたいと思います。限られた人員を大量の作業で困らせることなく、これを実現するためにはどうすれば良いでしょうか。本記事では、Amazon SageMaker Ground Truth のカスタムラベリングジョブを使用した実現方法を示します。
一度に1項目ずつワーカーに検証を依頼すると多くの作業が発生してしまいます。そこで、同じラベルが付与された項目をまとめて提示するカスタムラベル付け方法を実現し、各ワーカーには正しくないものをマークするように依頼します。 こうすると、ワーカーは、すべて最初からラベル付けするよりもはるかに多くのデータ量を迅速に評価できます。
品質保証が必要なユースケースの作業には、次のようなものがあります。
- 判断が難しいユースケースにおいて、実際に使用する前に対象分野の専門家によるレビューと承認を必要とする
- ラベルを確認して、ラベルを作成したモデルの品質をテストする
- ラベルに誤りがある項目を特定してカウントし、修正し、学習データセットに戻す
- モデルによって割り当てられたラベルの正確性と確信度の分析する
- 単一のしきい値をすべての分類クラスに適用できるか、あるいはクラスごとに異なるしきい値を使用するかどうかを確認する
- 初期データのラベル付けにより単純なモデルを使用し、次に品質保証のプロセスにより結果を検証し、再学習させることでモデルを改善する
このブログ記事では、これらのユースケースに対応する例について説明します。
背景とソリューションの概要
Amazon SageMaker Ground Truth は、パブリックおよびプライベートのラベル付けワーカーに簡単にアクセスする機能や、一般的なラベリングタスクのための組み込みのワークフローとインターフェイスを提供します。 このブログ記事では、Ground Truth のカスタムラベリングワークフローを活用することで、システムやビジネスプロセス全体で時間のかかるもう一つの部分である、機械学習または人により付与されたラベルの品質保証を行う方法を説明します。
このサンプルケースでは、入力は個々のワーカーによって検証されるラベル付き画像のリストです。 ワーカーは一つの画面上に同じラベルのついた画像をまとめて表示し、一度にラベルのセットを検証できます。 こうすることで、セット全体を素早く確認し、正しくラベル付けされていないものをマークし、「適合しない」ものを選び出すことができます。 検証された結果は、Amazon DynamoDB テーブルに保存されます。 まとめて確認するバッチの項目数は、作業の複雑さと、容易に比較・確認するため一度に表示できる数に応じて、タスクに対し適切に選択する必要があります。 この例では、バッチサイズは 25 (テンプレートで設定可能)を選択し、確認作業の負荷とレビュー対象の画像の量のバランスをとっています。
Amazon SageMaker Ground Truthカスタムラベリングジョブの構造
Amazon SageMaker Ground Truthカスタムラベリングワークフローは、以下の要素から構成されています。
- ラベリングタスクを実行するワーカー。パブリックワークフォース(Amazon Mechanical Turk を使用する場合など)またはプライベートワークフォースから選択できます。
- JSON マニフェストファイル。 マニフェストは、ジョブの入力場所を Ground Truth に伝えます。 各行項目は単一のオブジェクトであり、単一のタスクに対応します。 この例では、各オブジェクトは、品質保証の作業において、一度にワーカーに提示される同じラベルを持った一群の画像を指すカスタムラベリング入力です。
- ラベリング前の AWS Lambda 関数。 ラベリングタスクがワーカーに送信される前に、AWS Lambda によるラベリング前の関数に JSON 形式のリクエストが送信され、詳細が提供されます。 この JSON リクエストには、関数がカスタムラベリングジョブテンプレートに渡すために必要なすべての詳細情報が含まれている必要があります。
- カスタムのラベル付けタスクテンプレート。 テンプレートは、ラベリングタスク中にワーカーに表示される内容を定義します。 タスクへの入力は、ラベリング前の Lambda 関数によってテンプレートで使用できるようになります。
- ラベリング後の Lambda 関数。 ワーカーがタスクを完了すると、Ground Truth は結果をラベリング後の Lambda 関数に送信します。 この Lambda 関数は、一般的にラベル付け結果の統合に使用されます。 実際のアノテーションデータは、ペイロードオブジェクトの s3Uri 文字列で指定されたファイルに格納されます。
これらを構成したら、それを指定する Ground Truth ラベル付けジョブを作成できます。 Ground Truth は、ワーカーにそれぞれのラベリングタスクを配信し、結果をまとめる作業を支援します。
ソリューションの概要
このブログ記事で説明されているユースケースの場合、このプロセスへの入力は、Amazon Rekognition などの機械学習モデルによって既にラベル付けされている画像で、ラベルと、モデルがラベル付けした際の確信度スコアが付いています。
この例では、 AWS Open Datasets for image classification の CalTech 101[i] データセットのサブセットを使用します。このデータセットは事前にラベル付けされています。 使用するイメージのサブセットとそのラベルを指定するコーパス入力ファイルが用意されています。 たとえば、私たちのモデルは次のような”Crawdad”とラベル付けされた画像を用いています。
images/crayfish-image_0002.jpg,Crawdad,99.73238372802734
images/crayfish-image_0003.jpg,Crawdad,94.8296127319336
images/crayfish-image_0004.jpg,Crawdad,99.267822265625ここで、付与されたラベルの品質を評価することに興味があるものとします。
次の図がプロセス全体の流れを示しています。
- ステップ 1、2、3 では、ユーザーは画像を特定してアップロードします。
- ステップ4では、モデルが画像を分析してラベルを付けます(ステップ5)。
- ステップ 6 では、ラベルと画像が集約され、Ground Truthラベリングジョブが作成されます。
- ワーカーは、ステップ7のラベルを確認します。
- ステップ 8a では、結果がモデルに送り返され、再学習が行われます。
- ステップ8bでは、データサイエンティストがモデルの動作をより良く理解するため、またビジネス側が本番システムにおけるモデル推論の最も良い活用方法を理解するために、それぞれ結果を分析します。

このブログ記事の残りの部分では、手順 6 と 7 に焦点を当てた実現方法について説明します。 手順 8b の結果も確認します。
Amazon SageMaker Ground Truthカスタムラベリングジョブを品質保証に用いる
このセクションでは、次の図に示す実装コンポーネントを設定して実行します。 ソリューション実装では次の2 つの主要コンポーネントを使用します。
- Amazon SageMaker Ground Truth のカスタムラベリングワークフロー
- ラベル付けタスクの結果を保存するための Amazon DynamoDB テーブル
使いやすさのために、起動のための Lambda 関数が Amazon S3 バケットと Amazon DynamoDB テーブルを事前に設定します。

次の手順を実行しましょう。
- まず、AWS マネジメントコンソールを使用して、プライベートワーカー (1) を作成します。
- 次に、提供された AWS CloudFormation スタックを実行して、リソースを設定します。ジョブ入力を含む Amazon S3 バケット、結果を保持する DynamoDB テーブル、および Ground Truth で使用するラベリング前およびラベリング後ラムダ関数です。 スタックはまた、Lambda 関数(Launch)を実行して、ジョブマニフェストを事前に設定します(2)。
- マニフェスト (3) を読み込む Ground Truth ラベリングジョブを作成します。
- Ground Truthは、ラベリングタスクをラベリング前の Lambda 関数に送信してラベリングタスクを準備し、それらをワーカーに送信します(4)。
- プライベートワーカー (5) として、ラベル品質保証ステップ (5) を実行します。
- Ground Truth は、ワーカーがラベル付けしたデータをラベリング後の Lambda 関数 (6) に送信します。この関数は、ワーカーが割り当てたラベルを DynamoDB ラベルテーブルに書き込みます (7)
- 最後に、ラベリングタスクの結果を確認します。
詳細は次のとおりです。こちらでソースコードも見ることができます。
プライベートワーカーを作成する
プライベートワーカーを設定するには、AWS マネジメントコンソールを使用します。リージョンには us-east-1 を選択します(ワーカーは、コードが存在するリージョンに作成する必要があります)。 表示されている3つのオプションのいずれかを使用して、Managing a Private Workforce にある”Creating a workforce using the console”の指示に従います。 この手順では、ラベリングポータルのサインイン URL も作成されます。 この URL は後で必要になります。
bulkQA と呼ばれる新しいチームを作成します。 1 人のワーカー、あなた自身を追加します。 あなたの電子メールアドレスを追加し、登録手順を完了します。
リソースのセットアップ
us-west-2 でこのソリューションの動作を確認するには、次の Launch Stack ボタンを選択します。
コスト: ソリューションの実行コストは計約 1.00 ドルです。 ソリューションでの作業が終了したら、必ず CloudFormation スタックを削除してください。
![]()
Next を選択します。 次のスクリーンショットに示すパラメータがお使いの環境で動作することを確認してください。
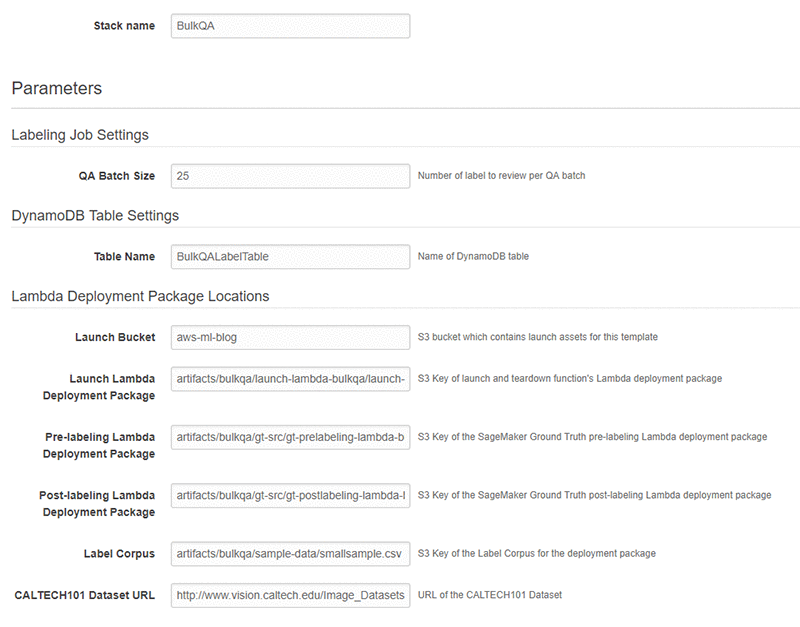
最後に、次のページのすべての設定を確認します。 I acknowledge that AWS CloudFormation might create IAM resources と表示されたボックスを選択し、Create を選択します (このスクリプトは IAM リソースを作成するため必須です) 。
スタックの起動が完了するまで待ち、スタックの Outputs タブを確認します。

- スタックが作成したリソースは、Amazon Simple Storage Service(S3)バケット(キー = BulkQABucket)です。 このバケットには以下が含まれます。
- 生成された JSON ファイル manifest.json 。 このファイルには、カスタムラベリング入力のリストが含まれています。 これらのカスタムラベリング入力のそれぞれは、ラベリングジョブ全体の中で個別の Ground Truth のラベリングタスクになります。
- 画像を含む一連のフォルダ。 これらのフォルダには、このラベリングプロジェクトで使用するために、CalTech 101 データセットからコピーされた画像のバッチが含まれています。
- custom_labeling_inputs という名前のフォルダ。 このフォルダには、生成された一連の JSON ファイルが含まれています。 各ファイルには、同じラベルが割り当てられた画像のバッチと、そのラベルに対してモデルが付与する確信度、およびソース画像の S3 の場所が含まれています。
[{"s3_image_url": "s3://bulkqa-rbulkqas3bucket-13skff6csrdy9/images/dalmatian-image_0001.jpg", "label": "Dog", "confidence": "87.27241516113281"}, {"s3_image_url": "s3://bulkqa-rbulkqas3bucket-13skff6csrdy9/images/dalmatian-image_0002.jpg", "label": "Dog", "confidence": "93.71725463867188"}, {"s3_image_url": "s3://bulkqa-rbulkqas3bucket-13skff6csrdy9/images/dalmatian-image_0003.jpg", "label": "Dog", "confidence": "93.47685241699219"}, {"s3_image_url": "s3://bulkqa-rbulkqas3bucket-13skff6csrdy9/images/dalmatian-image_0004.jpg", "label": "Dog", "confidence": "93.66221618652344"}, {"s3_image_url": "s3://bulkqa-rbulkqas3bucket-13skff6csrdy9/images/dalmatian-image_0006.jpg", "label": "Dog", "confidence": "93.04904174804688"}]
各カスタムラベリング入力は、(選択したバッチサイズの) Ground Truthにおける単一のタスクとなり、すべての画像が、ワーカーが検証するラベルと共に配列にリストされています。
- Ground Truth カスタムラベリングジョブで使用される AWS Identity and Access Management(IAM)ロール(キー = SageMakerRoleARN)。
- DynamoDB テーブル (キー = DynamoDBLabelTableName)。 テーブルには、S3 上の画像のリスト、ラベル、およびソースラベリングモデルによって付与されたラベルの確信度がプリロードされています。 これらが検証したいラベルです。

さらに、スタックによって 3 つの Lambda 関数が作成されました。 それらは次のとおりです。
- rLambdaLaunchFunction。この Lambda 関数は、CloudFormation スタックの起動時に 1 回実行され、このユースケースの環境をセットアップします。 画像ファイル名、ラベル、確信度の3つの列を含むCSVファイルを入力として受け取ります。 各行項目について、イメージファイルを S3 にコピーします。 また、DynamoDB 内にその行項目のエントリが作成され、マニフェストファイルが作成されます。
- rLambdaGTPreLabelingFunction。この Lambda 関数は、各カスタムラベリングタスクの開始時に実行されます。 入力として、グランドトゥルースからカスタムラベリング入力のS3 URIを受け取ります。 これは、S3 からマニフェストを読み込み、内容を Ground Truth に渡し、JSONオブジェクトにラップします。
{ "taskInput": { "sourceRef" : custom_labeling_input} } - rLambdaGTPostLabelingFunction。この Lambda 関数は、ラベリングタスクが完了した後に実行され、ワーカーのアノテーション結果が統合されます。 この場合、単にワーカーのアノテーションを読み取り、DynamoDB テーブルで更新します。

これらのコンポーネントが作成されたので、カスタムラベリングジョブを作成する準備が整いました。
カスタムラベリングジョブを作成する
AWS マネジメントコンソールで、Amazon SageMaker コンソールに移動します。 左側のナビゲーションバーで、Ground Truth を選択し、Labeling Job を選択します。Create Labeling Job を選択します。
- ジョブに”BulkQATestJob”という名前を付けます。
- 入力データセットは s3://<BULKQA-BUCKET>/manifest.json にあります。
- 出力データセットの場所を s3://<BULKQA-BUCKET>/output/ に設定します。
- IAM ロールには、カスタムロール ARN を入力します。 ここには、CFNによって生成された SageMakerExecutionRole をコピーします。

- 下にスクロールします。 TaskType で、Custom を選択します。

- Next を選択します。
Select workers and configure ツールページにおいて:
- Workers で、ワーカーの種類を Private に選択します。
- Private teams で、以前に設定したチームを選択します。

下にスクロールします。 「カスタム・ラベリング・タスクの設定」で、
- Custom のテンプレート・タイプを選択します。
- 以下に示す bulkqa htmlテンプレートの全文をコピーして貼り付けます。
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
<style>
.center { text-align: center;
border: 3px solid white;
}
.row { display: flex;
flex-wrap: wrap;
padding: 0 4px;
}
/* Create five equal columns that sits next to each other */
.column { flex: 18%;
padding: 0 4px;
}
</style>
<crowd-form>
<div class="center">
<h1> Confirm that each image is correctly labelled as "{{ task.input.sourceRef[0].label }}"</h1>
</div>
<div class="row">
{% assign length = task.input.sourceRef.size | minus: 1 %}
{% for i in (0..length) %}
<div class="column">
<crowd-card
image="{{ task.input.sourceRef[i].s3_image_url | grant_read_access }}">
<div class="center">Confirm <crowd-checkbox checked="true" name="{{ task.input.sourceRef[i].label }}-{{i}}" value="Confirmed" /></div>
</crowd-card>
</div>
{% endfor %}
</div>
</crowd-form>ここのコードはほんの数行の長さです。 clowd-form タグは、カスタムタスクコードをラップします。 このセットのラベルを task.input.sourceRef [0] .label から読み取り、そのテキストを使用してこのページでの指示を作成します。 次に、for-loop は、このタスクが入力として受け取った入力 custom_labeling_input にリストされた各イメージに対して cloud-card を作成し、各イメージの下にチェックの入ったチェックボックスを配置します。
- Pre-labeling task Lambda Function で、ドロップダウンリストから LambdaGTPreLabelingFunction を選択します。
- Post-labeling task Lambda Function で、ドロップダウンリストから LambdaGTPostLabelingFunction を選択します。

- Submit を選択します。
Ground Truth は、ジョブのステータスを In Progress として表示し、オブジェクト/合計を空欄で表示します。

Ground Truth があなたの処理の動作検証を行うまで数分間待ちましょう。 数分後、UI の Labeled objects/total 列に、0 / 9 などのカウントが更新されて表示されます。合計は、ワーカーが品質保証を行う Ground Truth カスタムラベリング入力の数です。ここでは、QA バッチサイズで選択したサイズに応じて、各クラスラベルは 1 つ以上の画像になります。
これで、ワーカーは数分以内にラベル付けタスクを受け取り始めるはずです。
画像ラベルの確認
AWS マネジメントコンソールの左ナビゲーションバーで、Ground Truth Labeling Workforces を選択します。 Private タブを選択します。 Private workforce summary の下の、Labeling portal sign-in URL を選択します。ワーカーのユーザー名とパスワードを使用してサインインします。 ワーカーに割り当てられたジョブが表示されます。 表示されない場合は、数分待ってからページを更新します。 データラベル付けジョブが使用可能になるまで繰り返します。
Start Working を選択します。
割り当てられたタスクごとに、ワーカーの Web ページには一連の画像が表示され、それぞれに同じラベルが付与されています。 下の最初のサンプル画像は猫、2 番目はカニです。 各画像には下に Confirm チェックボックスが表示されます。 各チェックボックスはデフォルトでオンになっています。


画像を確認します。 ラベルと一致しない画像については、チェックボックスをオフにします。 ページ上のすべての画像を確認したら、Submit を選択します。
背後では、ラベリング後の Lambda 関数が実行されます。 この Lambda 関数は、確認結果で DynamoDB テーブルを更新します。 各行に最大 2 つのフィールドを追加します。WorkerConfirmCount と WorkerDisconfirmCount です。 これらの列には、個々の画像を確認または却下したレビュー担当者の数が設定されます。
すべてのタスクが完了するまで続行します。 Ground Truth は、タスクをバッチし、次のバッチを割り当てる前に待機します。 10 を超えるタスクがある場合は、次のバッチが使用可能になるまでに待機する必要があります。
結果の評価
すべてのタスクが完了したら、DynamoDB テーブルで最終結果を確認できます。 AWS マネジメントコンソールで、Amazon DynamoDB コンソールに移動します。Tables で、前に作成した BulkQALabelTable を選択します。 Itemsタブを選択し、ワーカーの確認とともにテーブルを確認します。
次の DynamoDB コンソールのスクリーンショットでは、1 人のワーカーが 2 つの画像を却下し、もう一人のワーカーは承認したことが分かります。
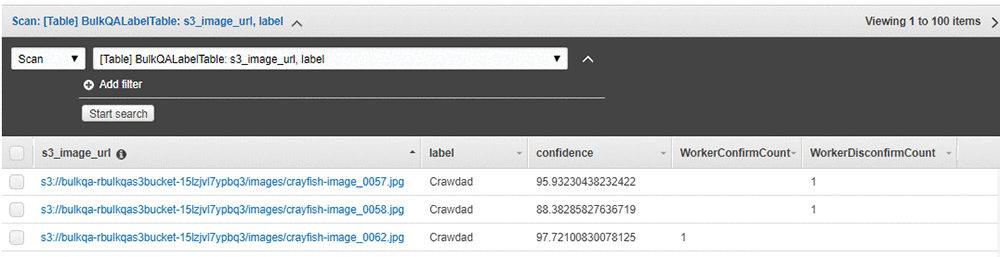
ワーカーが高度な訓練を受けている場合、または信頼できる情報源と考えられる場合、1 人のワーカーに結果を確認させることは妥当かもしれません。 また、判断が難しいユースケースやワーカーの権限が小さい場合は、多数のワーカー (たとえば 3人) が結果を検証し、すべてのワーカーが正しいと確認した結果のみを使用する場合があります。
クリーンアップ
このテストの結果を確認したら、必ず CloudFormation テンプレートを削除してください。 削除を行うと、DynamoDB テーブルと作成された S3 バケットが削除され、課金は継続しなくなります。
結果にもとづく判断
このセクションでは、ある2つの大規模なサンプルからの評価結果を示します。 これらはある “専門家”による評価であるため、異なる結果になる可能性もあります。 2 つのサンプルファイルが与えられ、 CloudFormation テンプレート内の bulkqa/smallsample.csv を以下のファイル名に置き換えることで実行できます。
- bulkqa/sample.csv には 10 分類された 510 枚の画像が含まれます
- bulkqa/shellfish.csv には 5 分類された甲殻類の 245枚の画像が含まれます
これらのサンプルにはより多くのクラスと画像があるので、評価には時間がかかります。 Ground Truth は、あなたのワーカーにバッチでオブジェクトを送信します。 つまり、いくつかのタスク (多くの場合 10) をワーカーに割り当て、次のセットを割り当てるまで待機します。
この方法では、任意のグループ内の偽陽性を識別します。 偽陰性(あるクラスに分類されるべきだが、そうでなかった画像)は、識別されません。 この方法に、正しいクラスを判定する (たとえば、取り得るクラスのリストから) 作業を追加することができますが、これは品質保証プロセスの速度を低下させ、正しい分類を業務で使用するまでの速度を遅くする可能性があります。あるいは、Ground Truth 分類ワークフローを使用するなど、誤分類された項目ごとに正しいクラスを割り当てるためのステップを連結させることもできます。 これが適切かどうかは、品質保証プロセスを行う理由によって異なります。
ラベル付けされ確認されたデータは、モデルにフィードバックされ、再学習に使用できます。さらに正確なモデルが得られる場合は推奨される方法です。ただし、既存のモデルがすでに最適な場合や、学習のためのサンプルを追加しても、モデル全体のパフォーマンスが向上せず、単にエラーを別のクラスに移動させるだけの場合もあります。
もう一つのシナリオは、個々のラベルの精度やモデル全体の平均的精度以上に、クラス間の違いに関心がある場合です。 次の表は、提供された sample.csv 入力を実行することによって得られるクラスおよび確信度スコアごとに画像を分けて整理した結果を示しています。 ワーカーの判断が分かれた画像は、Split として扱われます。 確信度スコアが 80 以上の画像のみが 品質保証プロセスに渡されることに注意してください。基本的に、入力プロセスではしきい値 80 を用いています。
| Total | 80-85 Confidence | 85-90 Confidence | 90-95 Confidence | 95-100 Confidence | |||||||||||||
| Label | Total | Confirmed | Disconfirm | Split | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct |
| Beaver | 28 | 27 | 1 | 1 | 96.43% | 2 | 1 | 50.00% | 3 | 0 | 100.00% | 13 | 0 | 100.00% | 10 | 0 | 100.00% |
| Cat | 10 | 9 | 1 | 3 | 90.00% | 1 | 1 | 0.00% | 0 | 0 | 0.00% | 5 | 0 | 100.00% | 4 | 0 | 100.00% |
| Crawdad | 68 | 35 | 33 | 4 | 51.47% | 1 | 1 | 0.00% | 10 | 8 | 20.00% | 10 | 6 | 40.00% | 47 | 19 | 59.57% |
| Dinosaur | 65 | 62 | 3 | 5 | 95.38% | 4 | 0 | 100.00% | 10 | 1 | 90.00% | 12 | 1 | 91.67% | 39 | 1 | 97.44% |
| Dog | 68 | 67 | 1 | 6 | 98.53% | 1 | 0 | 100.00% | 5 | 1 | 80.00% | 34 | 0 | 100.00% | 28 | 1 | 96.43% |
| Saxophone | 40 | 38 | 1 | 7 | 95.00% | 1 | 0 | 100.00% | 2 | 1 | 50.00% | 22 | 1 | 95.45% | 15 | 0 | 100.00% |
| Sea Turtle | 86 | 84 | 1 | 8 | 97.67% | 5 | 1 | 80.00% | 8 | 1 | 87.50% | 13 | 0 | 100.00% | 60 | 0 | 100.00% |
| Soccer Ball | 87 | 69 | 18 | 11 | 79.31% | 8 | 5 | 37.50% | 7 | 5 | 28.57% | 9 | 6 | 33.33% | 63 | 2 | 96.83% |
| Stop sign | 58 | 58 | 0 | 12 | 100.00% | 6 | 0 | 100.00% | 9 | 0 | 100.00% | 12 | 0 | 100.00% | 31 | 0 | 100.00% |
| TOTALS | 510 | 449 | 59 | 57 | 88.04% | 29 | 9 | 68.97% | 54 | 17 | 68.52% | 130 | 14 | 89.23% | 297 | 23 | 92.26% |
| Class Average | 89.31% | 63.06% | 61.79% | 84.49% | 94.47% | ||||||||||||
すぐにいくつかの興味深いパターンが示され、さらなる分析と評価のための質問を提起します。
猫(Cat)クラスとビーバー(Beaver)は、入力が少なすぎます。 これは、元のモデル入力の時点で少なすぎるか、それとも 80より小さい確信度スコアが与えられているため、品質保証プロセスまで来ていないためでしょうか? また、これらのまれなケースはモデル入力のソースの画像にもありますか? (猫の場合、これは直感的にはそうではないようです。)
クラス間で確信度の水準が異なり、正しい割合には大きな違いがあります。 たとえば、すべての一時停止標識が正しいのに対し、95 ~ 100 の確信度であっても、ザリガニ(Crawdad)のほぼ半分は正しくありません。 初期の仮説は、いくつかのクラスが混乱しやすい可能性があるということです。 例えば、サクソフォンは、人間や非専門家は判別が難しいかもしれないカニに比べて判別しやすいです。 この仮説を検証するために、shellfish.csv を使用した2 番目の評価を次の表に示します。
| Total | 80-85 Confidence | 85-90 Confidence | 90-95 Confidence | 95-100 Confidence | |||||||||||||
| Label | Total | Confirmed | Disconfirm | Split | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct | Total | Incorrect | %Correct |
| Crab | 45 | 45 | 0 | 0 | 100.00% | 4 | 0 | 100.00% | 7 | 0 | 100.00% | 11 | 0 | 100.00% | 23 | 0 | 100.00% |
| Crawdad | 68 | 16 | 32 | 20 | 23.53% | 1 | 0 | 100.00% | 10 | 8 | 20.00% | 10 | 8 | 20.00% | 47 | 36 | 23.40% |
| Lobster | 53 | 40 | 11 | 2 | 75.47% | 4 | 4 | 0.00% | 10 | 4 | 60.00% | 11 | 3 | 72.73% | 28 | 2 | 92.86% |
| Scorpion | 77 | 72 | 3 | 2 | 93.51% | 8 | 3 | 62.50% | 6 | 2 | 66.67% | 27 | 0 | 100.00% | 36 | 0 | 100.00% |
| Shrimp | 2 | 0 | 1 | 1 | 0.00% | 0 | 0 | 0.00% | 1 | 1 | 0.00% | 0 | 0 | 0.00% | 1 | 1 | 0.00% |
| TOTALS | 245 | 173 | 47 | 25 | 70.61% | 17 | 7 | 58.82% | 34 | 15 | 55.88% | 59 | 11 | 81.36% | 135 | 39 | 71.11% |
| Class Average | 58.50% | 52.50% | 49.33% | 58.55% | 63.25% | ||||||||||||
興味深いことに、この評価ではすべてのカニが正しく判定され、ほぼすべてのサソリ(Scorpion)が正しく判定されましたが、エビ(2枚)は正しく判定されなかったことを示しています。 ザリガニがモデルにとって特に難しいようです。おそらく、2番目のもっと詳細なモデルを構築して、ザリガニとそれが頻繁に誤認するクラスに特に焦点を当てるように学習させる必要があるでしょう。 初期モデルによってザリガニとして分類されるすべての画像を再分類のために 2 番目のモデルに接続することができます。
おそらく、これらのクラスの入力画像には、水中での撮影や低い照度など、体系的な違いがあるのでしょう。 あるいは、モデルには分類バイアスが含まれているかもしれません。 モデルはもともと転移学習を介して構築されたため、転移されたモデルは大きく異なるコーパスで訓練されており、いくつかの追加のトレーニングが必要だといえます。
クラスの違いや偏りが重要な意味を持つ条件(たとえば Corbett と Daviesの The Measure and Mismeasure of Fairness を参照)では、グローバルなしきい値(ここでの”80”など)を使用することは適切ではない場合があります。
たとえば、業務上、各クラスを等価に分類することを保証したいとします。 すなわち、各クラスのしきい値を超えるアイテムに対して、ほぼ同じエラー率(偽陽性と真陽性の比率が同じ)を持たせたいと考えているとします。以前のデータを考えると、ザリガニ、ロブスター、一時停止標識に同じしきい値を使用しても、明らかにこの目標は達成できません。 偽陽性の処理に関連するコストは、真陽性の処理の10 倍であると見積もるとします。 目標を達成するには、クラスごとに適切なしきい値を指定する必要があります。 直感的には、すべての一時停止標識が正しく識別されたため、一時停止標識クラスにはグローバルしきい値 80 は適切です。 ザリガニについては、より詳細に確認すると、99.5の確信度を超えても、エラーが多すぎることが明らかです。 上記のに示したパイプライン方式を、ザリガニのラベルが付いたイメージを業務側に送信する前に適用する必要があります。
これらのクラスに適切なしきい値を特定する方法の 1 つは、次のとおりです。上記の表中の右端の列から開始し、誤って分類された画像の比率が業務上受け入れられるよりも低い場合は、次の左の列に移動します。 そうでない場合にはその列で停止し、現在の列の上限値をしきい値として使用します。 1:10 の比率と猫のクラス(今のところ、このクラスの小さなサイズを見下ろす)の場合、これはクラスのしきい値を85にします。 そのほかのアプローチとより深い分析については On Calibration of Modern Neural Networks を参照してください。
結論
このブログ記事では、Amazon SageMaker Ground Truth カスタムラベリングワークフローを使用して、ラベルの一括品質保証を簡単に実行する方法について説明しました。 この方法を用いると、割り当てられたラベルをすばやく検証し、結果を返してモデルの品質を向上させることができます。 また、判断が難しいビジネスユースケースでのラベルを検証することもできます。
また、このアプローチを使用して、モデルが割り当てるすべてのラベルクラスで単一のしきい値が適切に用いられるかどうか、または分類パリティを達成するために一部のクラスに高いしきい値を割り当てる必要があるかどうかを確認する方法についても説明しました。
これらのアプローチを使用することでモデルの品質を向上させ、幅広いビジネスユースケースに自信を持ってモデルを使用できます。 お楽しみください!
[i] L. Fei-Fei, R. Fergus and P. Perona. Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. IEEE. CVPR 2004, Workshop on Generative-Model Based Vision. 2004
著者について
 Veronika Megler は、AWS プロフェッショナルサービスのビッグデータ、アナリティクス、データサイエンティストの主任コンサルタントで、空間時間的なデータ検索に関してコンピュータサイエンスの博士号を持っています。彼女は新しい技術の採用や、お客様が新しい問題を新しい技術で解いたり古い問題をもっと効率的に解いたりするのを支援することを専門にしています。
Veronika Megler は、AWS プロフェッショナルサービスのビッグデータ、アナリティクス、データサイエンティストの主任コンサルタントで、空間時間的なデータ検索に関してコンピュータサイエンスの博士号を持っています。彼女は新しい技術の採用や、お客様が新しい問題を新しい技術で解いたり古い問題をもっと効率的に解いたりするのを支援することを専門にしています。
 Chris Ghyzel はAWS プロフェッショナルサービスのデータエンジニアです。現在、AWS上の機械学習のソリューションをお客様の業務用のパイプラインと統合するために働いています。
Chris Ghyzel はAWS プロフェッショナルサービスのデータエンジニアです。現在、AWS上の機械学習のソリューションをお客様の業務用のパイプラインと統合するために働いています。