Amazon Web Services ブログ
【寄稿】Amazon DevOps Guru for RDSはパフォーマンスモニタリングにどのような恩恵をもたらすのか
本ブログポストはNRIデジタル株式会社のアプリケーションアーキテクト 島 良太氏とリードアーキテクト 松村 和機氏にAmazon DevOps Guru for RDSについて寄稿いただきました。
NRIデジタルでは、オンプレミス型、クラウド型問わず、多種多様なシステムを本番稼働させています。中でもAWSをベースに構築しているシステムが多く、データベース環境としてAmazon AuroraやAmazon Relational Database Service (Amazon RDS)の採用が多いです。
本番稼働中のシステムにおいて、パフォーマンス問題の原因の上位に来るのはデータベース関連です。十分にテスト環境でテストしたとしても、本番のワークロードは予測が難しく、予防措置を準備するのもなかなか難しいです。その為、高い品質の本番システムを運用していくには、発生時にいかに迅速に検知→原因特定→対応につなげていけるかが重要なポイントになってきます。
しかしながら、データベースのパフォーマンス問題は解析が難しく、自力で解決していくには相当のスキルセットが必要になります。過去、本番環境でパフォーマンス問題が発生した際、原因不明で手の打ちようがなく、トラフィックが落ち着くのを待ったり、サーバの台数やリソースを増やしたりして凌いでいるシーンを何度も見てきました。事後調査しても情報収集や解析の難易度が高く、結局何の改善もできず再発してしまうケースも多いです。さらに昨今のクラウド及びクラウドネイティブ技術の発展によるシステム環境の分散化がより難易度に拍車をかけています。
NRIデジタルでは、個人やチームのスキルに依存したアプローチには限界があると考えており、機械学習(ML)を活用したサービスや、本番ワークロードをリアルタイムに分析してボトルネックを特定し、改善点を提言するサービスが今後必要になると考えています。
そんな中、AWS re:Invent 2021にてAmazon DevOps Guru for RDS が発表されました。Amazon DevOps GuruはMLの機能を利用した新機能で、開発者やDevOpsエンジニアがAmazon RDSのデータベース関連のさまざまな問題を迅速に検出、診断、修正できるように設計されています。
この記事では、NRIデジタルのDevOps Guru for RDSのproof of concept(POC)プロセスについて紹介します。
Guru for RDSは課題をどのように解決してくれるのか
NRIデジタルではパフォーマンスモニタリングに必要な事項は以下と考えています。
- 検知 – 異常発生時、即座に検知できること
- 原因特定 – 問題のある箇所(データベース上で何が起こってパフォーマンスが遅延しているのか、それは何が原因で引き起こされているのか)を即座に特定できること
- 対応(一次/恒久)– 問題のある箇所に対して、具体的な改善方法がわかり、それを適用することで事象が改善し、再発の防止ができること
POCでは、DevOps Guru for RDSの機能や使い勝手を検証するために、通常のSQLと負荷の高い非効率なSQLを混ぜて、複数のSQLを数分間実行しました。今回のPOCでは、Amazon Aurora MySQL-Compatible Editionを使用しました。
以下のスクリーンショットのように、処理が開始された直後にエンジニアにアラートメールが送信されました。

この通知は、DBロードメトリクスの異常を示すものでした。詳細な分析を行うために、DevOps Guru for RDSのダッシュボードにアクセスします。
DevOps Guru Reactive insightsページで、RDS DB load anomalyが発生中のイベントであることに気づきました。RDS DB Load Anomalousを選択することで、集計されたメトリクスを確認出来ます。

anomalyページでは、DevOps Guruが異常として検出したメトリクスが集約されているのが確認できます。DB LoadのView analysisを選択することで、このメトリクスの分析結果を見ることができます。

分析ページの前半では異常な指標を可視化し、下段では分析結果とアドバイスが掲載されています。

上記分析画面の上部が異常なメトリクスを可視化したグラフであり、下部が分析結果とレコメンデーションとなります。
ActiveSessionが「9」を超えているActiveSessionが滞留している原因は、I/O待ちに関連するDB負荷である- そのI/O待ちに関連するDB負荷が総DB負荷の82%を占めている
- 本データベースで正常状態にするには
ActiveSessionを「2」まで下げる必要がある
データベースのパフォーマンスを低下させている原因と、データベース上で何が起きているのかを判断するのは簡単でした。
次のステップは、このイベントを引き起こしているものを見つけることです。Analysis and recommendationsのセクションの右側にある推奨事項には、調査すべきSQLダイジェストIDがリストアップされています。

Performance InsightsのView Top SQLを選択することで、Amazon RDS Performance Insightsを使って原因となりそうなSQL情報を確認することができました。
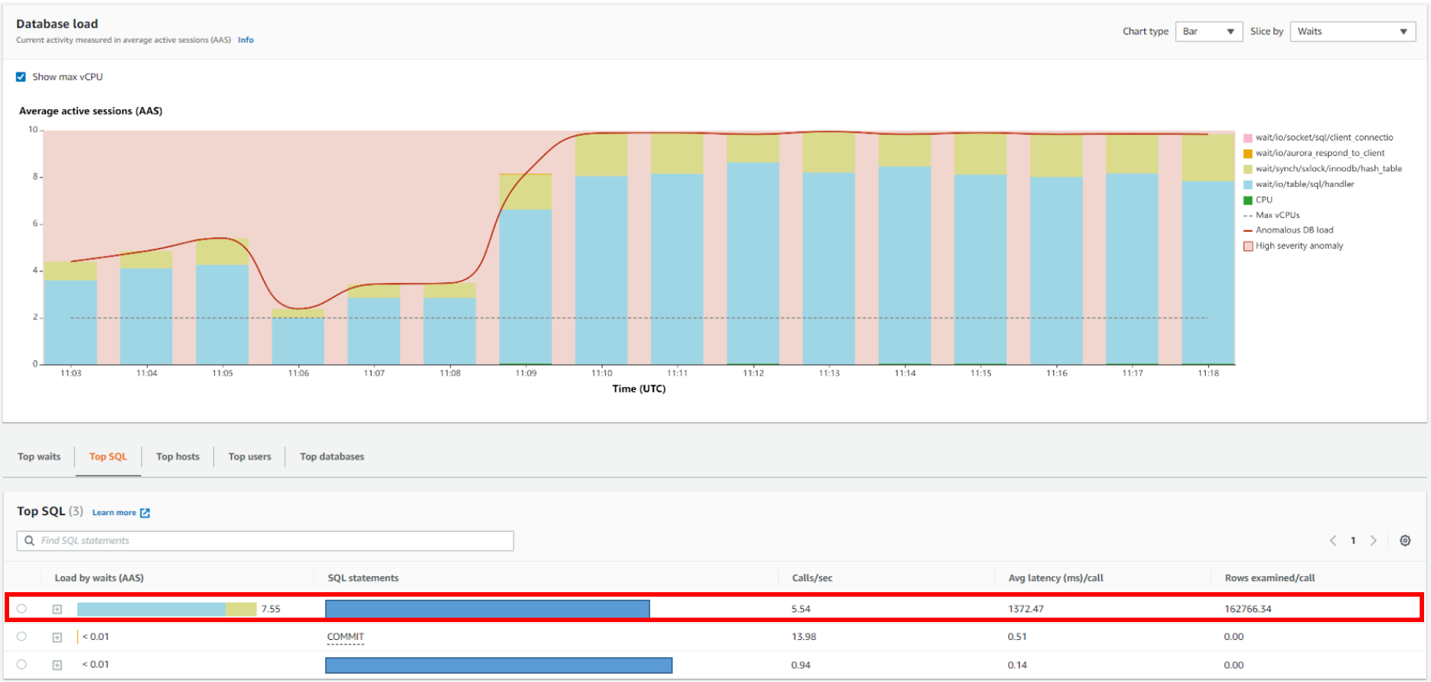
パフォーマンス遅延の原因となっているものを簡単に特定することが可能です。今回は、遅延の原因となっているSQLと統計情報(平均遅延時間)を確認しました。
そして、原因となっていると思われるSQLについて、具体的な改善策をレコメンドで確認しました。

Aurora MySQLのトラブルシューティングガイドに、待機イベントio/table/sql/handlerへのリンクが提供されています。ドキュメントには待機イベントの増加の原因として考えられることと、調査するためのアクションが記載されています。
この記事の執筆時点では、DevOps Guru for RDSは、SQLクエリを最適化する方法についての推奨事項を提供していませんが、この追加機能が利用できるようになる日を楽しみにしています。一方、私たちは問題のクエリを自分たちでチューニングすることを進めました。
この検証結果と仕様調査の結果、DevOps Guru for RDSを使用した場合と使用しない場合のパフォーマンス監視を比較すると、以下の表のようになります。
| 検知 | 原因特定 | 対応(一次/恒久) | |
| DevOps Guru for RDS未使用 | 適切なパラメータと閾値を組み合わせた監視設計や、変動するワークロードに応じたチューニングが難しい。 | Performance Insights等で状態を参照しても、何が問題となっているかの判断が難しい。
また、以前のパフォーマンスデータと比較するために、以前の状態を手動で保持する必要がある。 |
利用者のスキルセットに依存する為、DB専門家が不在のプロジェクトでは、事象改善に多くの期間やコストを要する。 |
| DevOps Guru for RDS使用 | 過去のベースラインと異なるDB負荷指標の異常な挙動を特定することで、データベースの性能問題を自動的に発見することができる。 | 解析結果をもとに、考えられる問題点をピンポイントで表示するため、問題の根本的な原因を容易に特定することができる。
また、以前の状態との差分も自動的に解析される。 |
DevOps Guru for RDSでは、推奨されるアクションアイテムを示してくれるものの、ある程度の専門知識がないと完全に解決することは難しいが、根本原因の特定にかかる時間は大幅に短縮されました。 |
まとめ
POCを通じて、DevOps Guru for RDSは、この投稿で述べた従来のパフォーマンス監視の問題を解決する可能性があると考えられます。
長期的なパフォーマンスの問題は、エンドユーザーの信頼を失い、機会損失の可能性を増大させることにつながります。DevOps Guru for RDSは、個人のスキルや専門知識に依存することなく、あらゆるスキルを持つチームが問題解決に迅速にアプローチできる可能性を持っています。
会社紹介

NRIデジタルは、2016年8月に設立された、野村総合研究所(NRI)グループのデジタルビジネス専門会社です。デジタル分野におけるコンサルティングとソリューションそれぞれの専門家が顧客企業と併走し、デジタル化戦略の構想立案から、先端ITソリューションの選定・構築、事業の実行支援、プロジェクト全体の検証・改善に至るまで支援しています。
著者について
![]() 島 良太 アプリケーションアーキテクト
島 良太 アプリケーションアーキテクト
 松村 和機 リードアーキテクト
松村 和機 リードアーキテクト
翻訳はAurora MySQL開発チーム 星野が担当しました。原文はこちらをご覧ください。