Amazon Web Services ブログ
RDS データベースに汎用 IOPS またはプロビジョンド IOPS のどちらを使用するかを決定するための CloudWatch メトリクスの使用方法
このブログ記事では、最高のパフォーマンスのミッションクリティカルなデータベースワークロードに対して、IO1 としても知られるプロビジョンド IOPS からメリットを得ることができる機会を把握するために Amazon CloudWatch メトリクスを使用する方法について説明します。まず、バーストを生じない一貫性のある高書き込みワークロードをシミュレートするテストケースをセットアップすることから始めます。今回は、価格とパフォーマンスのバランスを保つ、GP2 ボリュームとしても知られる汎用ストレージを使ったデータベースと、IO1 ボリュームを使ったデータベースのパフォーマンスを比較します。次に、対応する CloudWatch メトリクスが明らかにする事柄と、ワークロードのパフォーマンス結果をご覧いただきます。
数ヵ月前、GP2 ボリュームでのバーストバランスとベースラインパフォーマンスを説明する Understanding burst vs. baseline performance with Amazon RDS and GP2 という素晴らしいブログ記事が AWS データベースブログに掲載されました。GP2 ボリュームはプロビジョニングが簡単で使いやすく、低価格です。これは、GP2 ボリュームが必要時にパフォーマンスをバーストさせ、散発的なワークロード、または待機時間が発生する可能性を許容できるアプリケーションを上手く処理できることが理由です。開発、機能テスト、およびサンドボックスなどの環境では、偶発的な負担がかかる場合でさえも GP2 の使用には何ら問題がありません。絶えず負担がかかるデータベースワークロードについては、プロビジョンド IOPS ボリュームがプロビジョニングするレベルでの持続的なパフォーマンスとスループットを提供します。
前提条件
始める前に、先ほど紹介した GP2 バーストパフォーマンスについてのブログ記事、Understanding burst vs. baseline performance with Amazon RDS and GP2 を十分に検討してください。
この記事にあるコードを一通り実行したい場合は、アカウント内に同一の Amazon RDS for MySQL データベースを 2 つ作成してください。ひとつのインスタンスには GP2 ボリューム、もうひとつのインスタンスには IO1 ボリュームを使用するようにします。この記事のスクリプトとコードは、こちらの GitHub リポジトリからダウンロードできます。
テストシナリオ – 同じボリュームサイズ、異なる IOPS
Amazon RDS は、クラウド内でのリレーショナルデータベースのセットアップ、運用、およびスケーリングを容易にし、業界標準のリレーショナルデータベースに対してコスト効率が高く、サイズ変更が可能なキャパシティーを提供し、一般的なデータベースのアドミンタスクを自動で管理します。Amazon RDS を使用することにより、CPU、ストレージ、および IOPS それぞれ単独でスケールでき、必要に応じて必要な分を追加することができます。
Amazon RDS は、DB インスタンスのパフォーマンスと正常性の追加も容易にします。Amazon RDS イベントにサブスクライブして、DB インスタンス、DB スナップショット、DB パラメーターグループ、または DB セキュリティグループで変更が生じた場合に通知を受けるようにすることができます。詳細については、Amazon RDS ユーザーガイドの「Amazon RDS のモニタリング」を参照してください。
また、Amazon CloudWatch を使って DB インスタンスのパフォーマンスと正常性を監視することもできます。パフォーマンスチャートは Amazon RDS コンソールに表示されます。CloudWatch の料金には、Amazon RDS DB インスタンスのための基本モニタリングメトリクス (5 分周期) が含まれています。この記事では、テストワークロードの実績を理解できるように CloudWatch メトリクスを使用します。
インスタンスの詳細
テストを簡素化するために、MySQL インスタンスには db.m4.2xlarge RDS を使用しました。インスタンスにはそれぞれ、400 ギガバイトのストレージをプロビジョニングしました。IO1 インスタンスは 5,000 のプロビジョンド IOPS でプロビジョニングしました。GP2 インスタンスには 1,200 IOPS (1 GB あたり 3 IOPS) のベースレートがあり、必要に応じて 3,000 IOPS にバーストできます。また、2 つの RDS for MySQL インスタンスにアクセスできる 2 つの Amazon EC2 インスタンスも作成しました。EC2 インスタンスは、データベースに接続し、テストを実行するために使用されます。2 つのインスタンスを使用することによって、双方からワークロードを隔離することができました。
MySQL には、数種の異なるデータタイプでシンプルなテーブルをひとつ作成しました。これには、ランダムなデータを簡単に追加することができます。構造の複雑さとワーカーの数が十分であるならば、単一のテーブルに対する挿入が高 I/O をシミュレートするロードを生成できます。
I/O 集約型ワークロードをシミュレートするため、スキーマ設計のアンチパターンを多数使用しました。
- ランダムな文字値を持つプライマリキー。
- ランダムな値を持つ長い文字の列。
- ランダムな値を持つ長い列の全長を対象とするセカンダリインデックス。
- 不必要な列を含むセカンダリインデックス。
このような設計特性は、現実のアプリケーションでは不適当だと見なされます。今回のテストの必要上、これらは比較的シンプルなクエリで高 I/O アクティビティを生成するために役立ちます。
データベースでロードを生成し、多数の小さな挿入をシミュレートするために、Python スクリプトを記述しました。このスクリプトはデータベースに接続し、一度に 100,000 の列を挿入して、500 列ごとにコミットしてから終了します。この Python スクリプトにおける作業のほとんどは、run_mysql(workload) によって行われます。ここで、workload は insert または query の最初のコマンドライン引数です。Python スクリプトの完全なテキストは、前述したリポジトリからダウンロードできます。
このテストのために、それぞれが 100,000 件の挿入を実行する 250 スレッドを持つプログラムを呼び出しました。今回使用したコードをダウンロードして、独自の目的のためにコードを変更することができます。環境内で実行される挿入の数を変更するには、ファイル submit_workload.py の80 行目を編集します。このスクリプトの 2 番目の引数が、実行するスレッドの数を制御します。
今回使用したものと同じ 250 スレッドでスクリプトを実行するには、このコマンドを発行します。
テストパフォーマンス分析
インスタンスに対して両方のワークロードを実行するには、完了までに多少時間がかかります。それぞれのインスタンスには、データが追加されている間も、引き続きアクセスしてクエリを実行することができます。注目すべきなのは、IO1 ボリュームを使ったインスタンスが、GP2 ボリュームを使ったインスタンスよりも少し早く完了したことです。
スクリプトは、コミット間隔ごとに各スレッドのためのメッセージを output.log に発信するため、挿入レートを確認することができます。挿入レート、および開始時間と終了時間を追跡してクエリできるように、挿入するデータにはタイムスタンプを含めました。テーブルとログを見ると、最後の挿入が myinstance-IO1 で完了してからおよそ 20 分後に myinstance-GP2 で完了したことがわかります。
| max timestamp | |
| GP2 | 2018-04-19 03:20:32 |
| IO1 | 2018-04-19 02:58:27 |
インスタンスに対する挿入パターンの詳細をもう少し詳しく調べてみましょう。挿入タイムスタンプフィールドを分解して時間と分ごとに分類すると、各分に行われた挿入の回数を数えることができます。
ひとつ、またはふたつの挿入タイミングを詳しく調べると、IO1 インスタンスでは各分ごとに数行多く挿入されているのがわかります。参照のため、前述のリポジトリリンク先にはテストからの結果とグラフが含まれています。
| 時間 (時間:分) | GP2 挿入レート | IO1 挿入レート | 差 |
| 21:32 | 99,462 | 131,403 | 31,941 |
| 21:33 | 111,114 | 125,956 | 14,842 |
| 21:34 | 109,431 | 121,396 | 11,965 |
タイミングの向上は、myinstance-IO1 が達成した挿入数の増加に関連しています。ワークロードは同時に開始され、挿入における初期バーストはふたつのシステム間で同等です。テスト期間中、約 60 パーセントの割合で、myinstance-IO1 での挿入ペースが myinstance-GP2 での挿入ペースよりも速くなっています。挿入数は、1 分あたり 100 行から 32,000 行まで様々です。
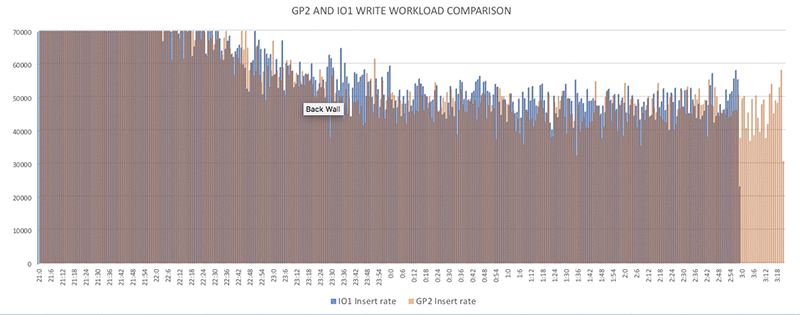
CloudWatch で深層を探る
Amazon CloudWatch を使用して、ワークロード期間中にインスタンスで何が起こっていたのかを掘り下げてみましょう。Amazon CloudWatch は、AWS クラウドリソースと、AWS 上で実行されるアプリケーションのためのモニタリングサービスで、CloudWatch を使って、メトリクスの収集と追跡、ログファイルの収集とモニタリング、およびアラームの設定を行い、AWS のリソースにおける変更に自動で対応することができます。
ワークロードの実行中は、RDS ダッシュボードで CloudWatch メトリクスを表示しました。うれしいことに、このワークロードに対して CPU 上の制約を受けることはありませんでした。
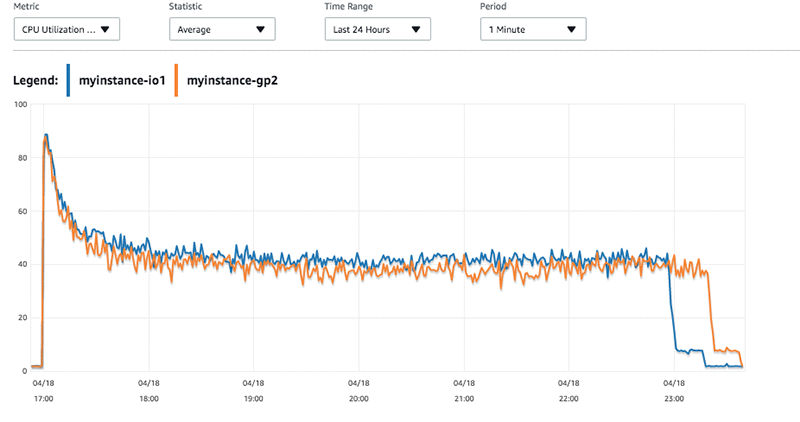
myinstance-IO1 マシンが myinstance-GP2 インスタンスよりも速いレートで書き込みを行っていたことがわかります。
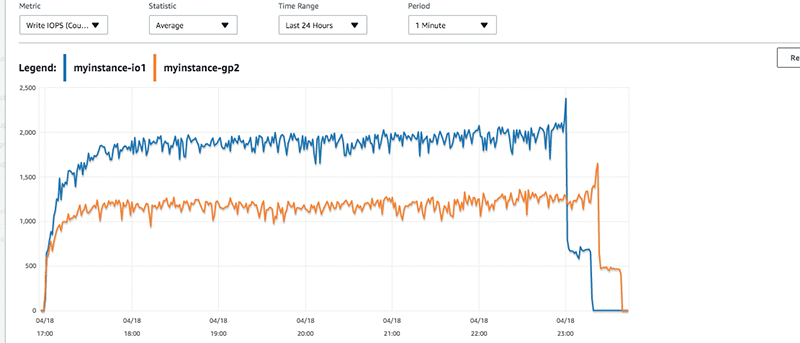
myinstance-IO1 は、ピーク時に 2,500 をやや下回る プロビジョンド IOPS を実現しています。myinstance-GP2 インスタンスでは、数回ピークはあったものの、安定したベース IOPS が 1,200 前後に維持されています。同一のワークロードに対する低い IOPS レートは、トランザクションに対して若干高いレイテンシーにつながります。CloudWatch グラフには、このほんのわずかなレイテンシーが反映されています。
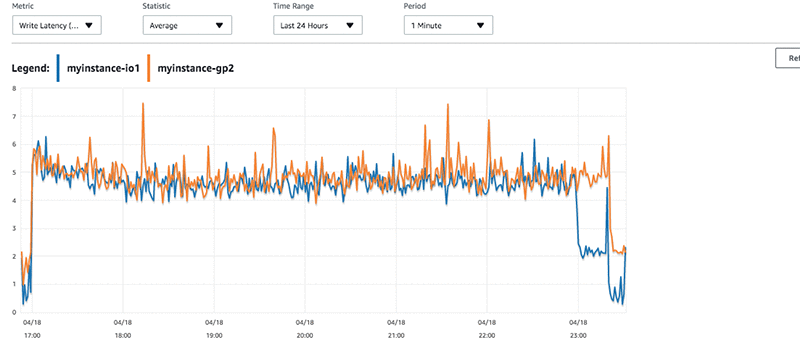
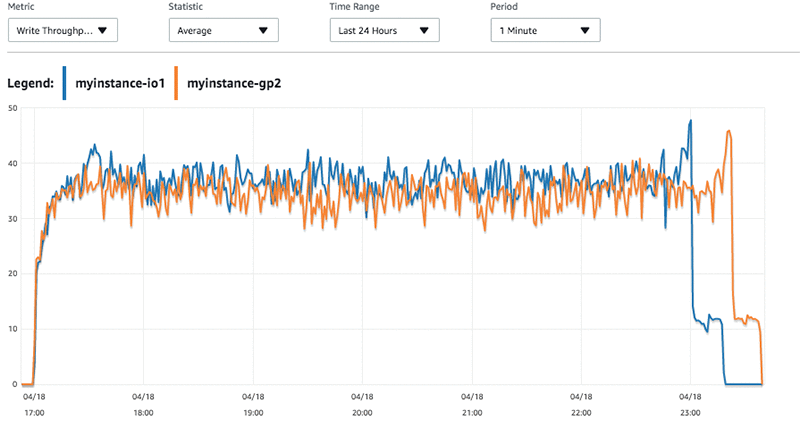
前に測定した挿入数を見直すと、myinstance-GP2 のワークロードに存在するレイテンシーには、さらに数回のピークがあります。書き込みスループットを見ると、myinstance-GP2 よりも myinstance-IO1 からのスループットのほうが高いことがわかります。
GP2 ボリュームがアタッチされた RDS インスタンスは、インスタンスに関連付けられているバーストバランスを追跡します。CloudWatch で myinstance-GP2 に関連付けられているバーストバランスを見ると、初期ワークロード期間中にバーストバランスが消耗されているのがわかります。そうなると、GP2 インスタンスはベース IOPS に依存しなくてはならなくなります。
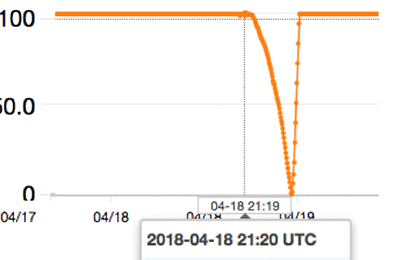
注意: バーストバランスグラフは CloudWatch から UTC 時間で表示されており、RDS グラフに表示される私のブラウザとは +4 時間の時間差があります。
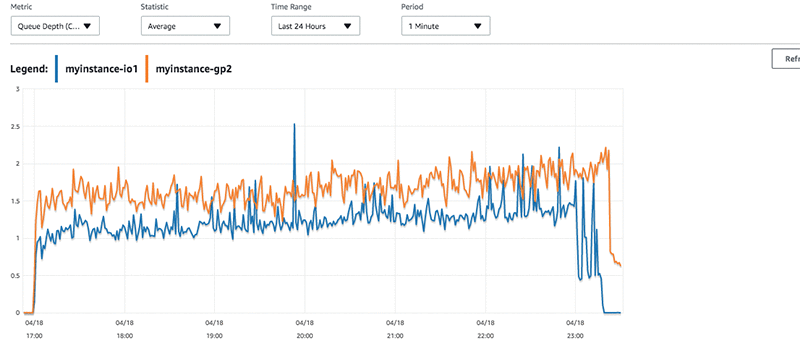
もうひとつのメトリクスは、インスタンスがどれくらいの作業を実行するようにリクエストされているかを理解するために役立てることができます。ディスクのキューの深さは、ストレージに対して一度にキューされている I/O リクエストの数です。ホストからストレージへの I/O リクエストはそれぞれ 1 つのクエリエントリを利用します。
短いバースト、高容量、および同時書き込みがあるインスタンスに対するキューの深さを調べてみるとします。その場合、テスト中はキューの深さが一定しており、IO1 ボリュームよりも GP2 ボリュームに対してより多くの書き込みがキューされていることがわかります。キューの深さ、および Amazon EBS パフォーマンスのその他トピックに関する詳細については、AWS のドキュメントをお読みください。
ソリューションのコスト
プロビジョンド IOPS ボリュームにかかるコストは GP2 ボリュームよりも高くなっています。現在、us-west-2 における 400 ギガバイトの GP2 ストレージの月額は 1 月あたり 40 USD です。同じ 400 ギガバイトに 5,000 IOPS をプロビジョニングする価格はそれよりも高く、1 月あたり 375 USD になります。
インスタンスにプロビジョンド IOPS ボリュームの使用を選択する場合、ワークロードのニーズに合った値を選択してください。控え目な値で開始する場合は、必要に応じて値を増やすことができます。必要時にのみ増加させれば、オーバープロビジョニングによる不必要なコストが発生しないことを確実にできます。伸縮自在なボリュームに関する詳細については、AWS で読むことができます。これらは、ボリュームの使用中におけるストレージの拡大とパフォーマンスの調整を容易にします。
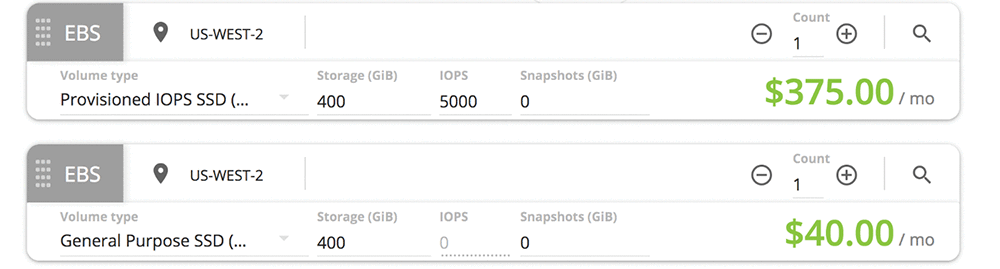
今回は、ワークロードに対してオーバープロビジョニングしています。これがミッションクリティカルでテストケース以上のものであるならば、プロビジョンド IOPS を選択しながらも、値をピーク使用率に一致するものに引き下げるかもしれません。ピーク使用率を 2500 IOPS にすることによって、ボリュームのコストを 212.50 USD/月に低減することができます。PIOPS ボリュームはバースト対応ではないため、ピーク使用率に合わせてプロビジョニングする必要があります。これらは、99.9 パーセントの割合で、プロビジョニングしたレベルでの一貫的なパフォーマンスを提供するように設計されています。

例に挙げたアプリケーションは非常に小さく、必要とされる IOPS は GP2 ボリュームの範囲内です。ボリュームサイズを増加させることによって、3 IOPS/GB の一貫的なベースラインパフォーマンスを実現するために GP2 ボリュームを使用できます。GP2 は、99 パーセントの割合でプロビジョニングされたパフォーマンスを提供するように設計されています。今回のデータベースワークロードには、850~900 GB の GP2 ストレージをプロビジョニングできます。これは、毎月 90 USD かかり、99 パーセントの割合で 2,500 IOPS を達成します。GP2 ボリュームのサイズを増加させると IOPS がスケールアップされるため、GP2 ボリュームを 3.34 TiB に増加させることによって、少なくとも 10,000 IOPS のパフォーマンスがボリュームに提供されます。
システムがクリティカルなもので、システムからのより優れた IO パフ―マンスの保証が必要な場合は、プロビジョンド I/O を選択できます。しかし、コスト効率性がより良い選択は、容量の多い GP2 ボリュームをプロビジョニングすることでしょう。アプリケーションの保証された IOPS のニーズが 10,000 IOPS 以上に増加する場合は、プロビジョンド IOPS を使用する必要が生じるかもしれません。変更をいつ行う必要があるかを理解するために、このブログ記事で説明した CloudWatch メトリクスを使うことができます。
私が構築した架空のテストシナリオでは、ワークロード (一貫性のある書き込み) がどのようにより高い IOPS の恩恵を受けたかについて説明しました。お使いのアプリケーションでは、プロファイルが異なる可能性があり、手がかりも把握しにくく、比較のために二次的なインスタンスをプロビジョニングする余裕がないかもしれません。ワークロードがより高い IOPS の恩恵を受けるかどうかを判断するには、データベースについて CloudWatch メトリクスを評価し、そのパフォーマンスを詳細に調べる必要があります。
導入事例
最近、CPU、または接続アクティビティがそれほど増加していないにもかかわらず、アプリケーションで突然大幅な減速が発生したというお客様がおられました。このアプリケーションは、最近の減速まで、一定数のユーザーが接続された状態で良好に動作していました。

お客様の RDS ダッシュボードは、アプリケーションにおける減速に対応する読み取りのスパイクと、CPU の緩やかな増加が発生したことを示していました。
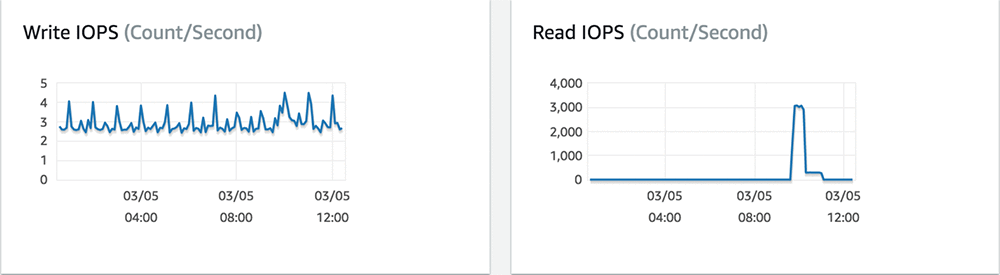
使用していた GP2 インスタンスに関する CloudWatch 統計を調べると、読み取りレイテンシーと書き込みレイテンシーの増加に対応してバーストバランスを消耗していたことがわかりました。

このお客様は、アクティビティをスパイク中に行われたビジネスクリティカルなレポートの作成まで遡りました。私たちは、それに対応するアプリケーションユーザーへの減速なしでレポートアクティビティを維持するために、ワークロードに十分な IOPS をプロビジョニングしました。
追加された IOPS のメリットとして、エンドユーザーは、読み取りレイテンシーと書き込みレイテンシーの減少に伴うアプリケーションにおける全体的な応答時間の向上も報告しました。バーストバケットバランスが消耗されたときに通知を行う CloudWatch アラームを設定していれば、お客様はユーザーよりも先にこの問題を把握していたでしょう。今後のため、お客様は残りの GP2 ボリューム RDS インスタンスに、2 周期にわたってバランスが 50 パーセント未満に落ちたときのためのアラームを設定しました。
お使いのワークロードは、今回のテストとこの導入事例とは異なると思われますが、CloudWatch メトリクスからの洞察を利用することによって、不十分な IOPS といった問題がいつ発生する可能性があるかを把握するために役立つアラートと通知を設定できます。適切なメトリクスと通知のセットは、どのボリュームが適切かを判断するために役立ちます。ワークロードの特性を評価して、ベース IOPS とバースト IOPS を持つ GP2 ボリュームが十分であるかどうかを決定できます。または、ワークロードには、ユーザーに持続的なパフォーマンスを提供するためのプロビジョンド IOPS が必要になるかもしれません。
著者について
 Wendy Neu は、2015 年 1 月から Amazon でデータアーキテクトとして活躍しています。 Amazon 入社前は、オハイオ州シンシナティでコンサルタントとして働いており、お客様が関連性のないさまざまなデータソースからのデータを統合し管理するお手伝いをしていました。
Wendy Neu は、2015 年 1 月から Amazon でデータアーキテクトとして活躍しています。 Amazon 入社前は、オハイオ州シンシナティでコンサルタントとして働いており、お客様が関連性のないさまざまなデータソースからのデータを統合し管理するお手伝いをしていました。