Amazon Web Services ブログ
プラネタリースケールコンピューティング – 9.95 PFLOPS、TOP500 リストで 40 位を達成
天気予報、ゲノムシーケンシング、ジオアナリティクス、計算流体力学 (CFD)、その他の種類のハイパフォーマンスコンピューティング (HPC) ワークロードでは、大量の処理能力が活躍します。こうしたワークロードは、多くの場合、スパイクがあり、大規模並列で、結果までの時間が重要な状況で使用されます。
古い方法
政府、豊富な資金を持つ研究機関、Fortune 500 企業などは、競争力を獲得するために、スーパーコンピューターに数千万 USD を投資しています。最先端のスーパーコンピュータを構築するには、特別な専門知識、長年にわたる計画、アーキテクチャと実装に対する長期的なコミットメントが必要です。構築されると、投資を正当化するためにスーパーコンピューターを常に活用する必要があり、ジョブが順番を待つ間に、キューが長くなります。容量の追加や新しいテクノロジーの活用にはコストがかかり、時には混乱を招くこともあります。
新しい方法
クラウドで仮想スーパーコンピュータを構築できるようになりました!
10 年以上にわたって数千万 USD を投入する代わりに、必要なリソースを取得し、問題を解決して、リソースを解放するだけです。必要なだけ、必要な時に、そして必要なときに限ってパワーを手に入れることができます。問題を利用可能なリソースに強制的に適合させる代わりに、必要なリソースの数を把握し、それらを入手し、可能な限り自然で迅速な方法で問題を解決することができます。単一のプロセッサアーキテクチャに対して数十年にわたってコミットメントする必要はなく、新しいテクノロジーが利用可能になれば簡単に導入できます。長期的なコミットなしで、あらゆる規模で実験を行うことができ、GPU などの新しいテクノロジーや機械学習のトレーニングや推論に特化したハードウェアで経験を積むことができます。
上位 500
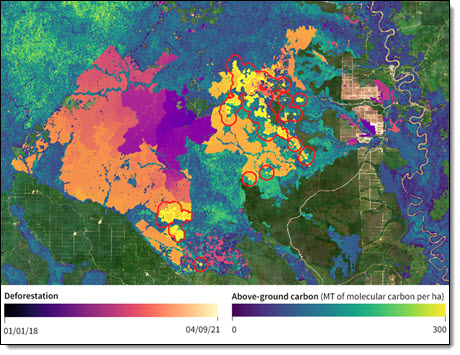 ボルネオ島カリマンタンのある地域での歴史的な森林破壊と推定される森林炭素損失に関する、Descartes 研究所による光学およびレーダー衛星画像分析
ボルネオ島カリマンタンのある地域での歴史的な森林破壊と推定される森林炭素損失に関する、Descartes 研究所による光学およびレーダー衛星画像分析
AWS のお客様であるDescartes 研究所は、HPC を使用して世界を把握し、地上、水中、宇宙にあるセンサーから押し寄せるデータの洪水に対処しています。同研究所は当初からクラウドベースであり、多くの場合、ペタバイト規模のデータを含む地理空間アプリケーションに焦点を当てています。
CTO 兼 Co-Founder である Mike Warren 氏は、彼らがやりたいことが処理能力によって制限されることはないと言いました。キャリアの初期に、Mike は宇宙のシミュレーションに取り組み、Loki、Avalon、スペースシミュレータを含む複数のクラスターおよびスーパーコンピュータを構築しました。Mike は、コモディティハードウェアからクラスターを構築した最初の 1 人であり、その過程で多くのことを学びました。
Los Alamos 国立研究所を退職後、Mike は Descartes 研究所を共同設立しました。2019 年、Descartes 研究所は AWS を使用して、1.93 PFLOPS を達成した TOP500 の実行を成功させ、 2019 年 6 月の TOP500 リストで 136 位を獲得しました。この実行では、C5 インスタンスのクラスターで 41,472 コアが使用されました。特に、Mike は、EC2 チームからの支援や調整なしにこの実行を開始したと話しました (Descartes 研究所は顧客向けにこうした規模の本稼働ジョブを定期的に実行しているため、アカウントにはすでに十分なservice quotasがありました)。この実行の詳細については、クラウドからの雷: AWS で協調実行される 40,000 コアをご覧ください。これは、そのストーリーで私のお気に入りの部分です。
AWS 米国東部 1 リージョンのノードのグループへのアクセスが許可され、会社のクレジットカードに約 5,000 USD が請求されました。カスタムハードウェアをその速度で実行するためのコストはおそらく 2,000 万 USD から 3,000 万 USD に近いため、この HPC が非常に経済的であることは明白でした。6~12 か月の待ち時間が必要であることは言うまでもありません。
この実行が成功した後、Mike と彼のチームは 2021 年の目標を 7.5 PFLOPS とかなり高い目標にすることに決めました。EC2 チームと協力して、6 月上旬に 48 時間の EC2 オンデマンド容量予約を取得しました。一度に 1024 インスタンスしか使用しないいくつかの「小規模」の実行の後、彼らは記録を計測する準備ができました。合計 172,692 コアで、4,096 の EC2 インスタンス (C5、C5d、R5、R5d、M5, M5d) を起動しました。結果をご覧ください。
- Rmax – 9.95 PFLOPS。これが、達成された実際のパフォーマンスです。毎秒ほぼ 10 兆回の浮動小数点演算になります。
- Rpeak – 15.11 PFLOPS。これは、理論上のピークパフォーマンスです。
- HPL 効率 – 65.87%。Rmax と Rpeak の比率、またはハードウェアがどれだけ適切に使用されているかを示します。
- N: 7,864,320。これは、Top500 ベンチマークを実行するために反転されるマトリックスのサイズです。N2 は約 61.84 兆です。
- P x Q: 64 x 128。これは実行のパラメータであり、処理グリッドを表します。
この実行は、2021 年 6 月の TOP500 リストで第 41 位にランクされており、わずか 2 年で 417% のパフォーマンス向上を表しています。他の CPU ベースの実行と比較すると、この実行は 20 位の位置にあります。GPU ベースの実行は確かに印象的ですが、別々にランク付けすることで、最適な同一条件での比較となります。
Mike と彼のチームはこの結果に非常に満足しており、あらゆる規模の HPC ジョブに対するクラウドのパワーと価値を実証すできたと確信しています。Mike は、1993 年にトップの座を獲得した (そして Jurassic Park にゲスト出演した) Thinking Machines CM-5 は、実際には単一の AWS コアよりも遅いと指摘しました!
6 月 4 日の午前 11 時 56 分 (太平洋標準時) に実行は終了しました。わずか 24 分後の午後 12 時 20 分までに、クラスターがダウンし、すべてのインスタンスが停止しました。これが、オンデマンドスーパーコンピューティングのパワーです!
Beowulf クラスターを想像する
スラッシュドット電子掲示板の初期の頃、当時印象的なハードウェアを参照していたすべての投稿には、「Beowulfクラスターを想像してみてください」というコメントが必ず含まれていました。 現在は、ほぼあらゆるサイズのクラスターを簡単に想像 (そてい起動) することができ、大規模な計算ニーズに対応できます。
AWS クラウドのスピードと柔軟性の恩恵を受けられる惑星規模の問題があるなら、想像力を働かせましょう! 以下は、始めるためのいくつかのリソースです。
- AWS ハイパフォーマンスコンピューティングのページ。
- AWS HPC リソース。
- AWS HPC ブログ。
- AWS HPC ワークショップ。
- AWS ParallelCluster。
- AWS ハイパフォーマンスコンピューティングコンピテンシーパートナー。
おめでとうございます
この素晴らしい成果について、Mike と Descartes 研究所の彼のチームにお祝いの言葉を贈りたいと思います。 Mike は何十年もの間、大量生産されたコモディティハードウェアとソフトウェアを使用してスーパーコンピューターを構築できることを世界に証明するために尽力し、その結果は明らかです。

この実行と Descartes 研究所の詳細については、Descartes 研究所が AWS を利用したクラウドベースのスーパーコンピューティングデモンストレーションで TOP500 の第 40 位を達成、大規模な地理空間データ分析の新時代の幕開けをご覧ください。
– Jeff