Amazon Web Services ブログ
Amazon Athena を使った Amazon S3 分析データへのクエリ
最近、あるお客様からの問い合わせに答えました。その方々は、S3 Standard、S3 Infrequent-Access、そして S3 One-Zone Infrequent-Access など、複数ある Amazon S3 ストレージクラスに価値を感じているものの、そのストレージを最適化するのに、どの階層とライフサイクルルールを適用してよいか迷っているということでした。このお客様を含め、同様な状況にある他の方々も、複数のバケットと、各種のデータアクセスパターンを使用されています。結局、当社とお客様で協力しあい、S3 Analytics レポートが利用できるようにし、最適なライフサイクルが容易に決定できるようになりました。今回のブログ記事では、この過程で我々が学んだことや、多くの分析レポートを一度に簡単に調べるためのテクニックなどについて、概要をご説明していきます。
2016 年 11 月にリリースされた Amazon S3 分析 では、ストレージへのアクセスパターンの分析や、適切なデータを適切なストレージクラスへ移動させる機能などが提供されました。また、分析を行うためのデータを S3 バケットへ手動でエクスポートすることも可能になりました。これで、好みのビジネスインテリジェンスツールが使用でき、利用率や増加パターンについてより深い洞察を集めることができます。この機能は、利用パターンに基づきパフォーマンスを最適化しながら、ストレージのコストを削減するために役立ちます。
また、Amazon QuickSight の更新が 2017 年の 11 月に行われました。S3 コンソールでの数回のクリックにより、この QuickSight が、特定の S3 バケットに関する S3 分析を視覚化できるようにします。この処理は、手動でのエクスポートやデータに関する余計な準備作業も必要なく自動で完了します。
本記事では、こういったアナリティクスレポートのレビューをするための、代替的な方法をご紹介していきます。今回の手法では、サーバーレスで双方向性のクエリサービスである Amazon Athena、そして、完全マネージド型の ETL (エクストラクト、トランスフォーム、ロード) とデータカタログのサービスを提供する AWS Glue を使います。これらのサービスを併用することで、S3 Analytics レポートに対し直接 SQL クエリできます。QuickSight やその他のデータベースエンジンにロードする必要はありません。
この手法により、ストレージクラスのコスト削減方法が、一度にすべてのバケットに関して素早く簡単に特定できるようになります。Amazon S3 内で個別のレポートを調査したり、そのレポートを QuickSight のレポートとそれぞれリンクするより、効率的に作業できます。
アーキテクチャ
次に示した図が、今回構築したアーキテクチャの概要です。

まず最初に、ソースとなる Amazon S3 バケットの定義を行います。このバケットは分析を行い、その結果を CSV ファイルの S3 分析レポート [1] として、中心に置かれた Amazon S3 レポーティングバケット [2] に送ります。
分析レポートがレポーティングバケットに届くと、S3 Event Notification が AWS Glue Crawler [3] をトリガーします。これにより、各分析レポートは、AWS Glue Catalog [4] 内にある単一の論理分析テーブルで、新しいパーティションとしてマッピングされます。
次に、ユーザーもしくはアプリケーションから Amazon Athena [5] に対し、SQL クエリを送信します。Amazon Athena では、AWS Glue Catalog [6] を使い、Amazon S3 から読み込む必要があるファイルを決定し、このクエリを実行します [7]。
前出の情報の一部は、この後に示すガイドに従うことで、手動で作成することができます。それ以外のコンポーネント、たとえばデータベースや AWS Glue カタログ内のテーブル定義などは、コードサービスの自動インフラストラクチャである AWS CloudFormation を使って作成します。
前提条件
このガイドでは、S3 分析レポートを生成するよう定義するためのソースバケットが、1 つ以上は Amazon S3 内に存在することを前提とします。加えて、このレポートの送り先となるレポーティングバケットが、S3 の中に 1 つ必要です。ソースバケットの 1 つをレポーティングバケットに設定してもかまいません。また、分析レポートを受け取るためには、レポートバケットはソースバケットと同じリージョンに置かれる必要があります。
ステップ 1: S3 分析の有効化
まず始めに、ソースバケットにおいて S3 分析を有効化します。そして、各分析レポートが同じレポーティングバケットとプレフィックスに送られるように定義します。これは、AWS Glue クローラーがスキーマが合致する同じロケーションにあるオブジェクトを扱う際、Glue Data Catalog 内の単一の論理テーブルとみなすように定義されている場合があるからです。
分析の対象とする各ソースバケットに関しては、次にあげる要件を遵守すると同時に、「ストレージクラス分析を設定する方法」にあるガイドにも従ってください。
- 結果の出力先として、[Destination bucket] には、レポーティングバケットを設定します。
- [Destination prefix] には、
s3_analytics/bucket=SOURCE_BUCKETと設定します。
[Destination prefix] にある s3_analytics/ の部分は、最低 1 つが実在するのであれば、必要に応じて任意のフォルダーや連なったフォルダーに設定しても問題ありません。bucket=SOURCE_BUCKET の部分は、後に AWS Glue がレポートを適切にクロールするために、必ず記述する必要があります。たとえば、werberm-application-data という名前のバケットに関する S3 分析を有効化していて、レポートは werberm-reports というバケットに送りたい場合、分析の定義は次のようになります。

S3 ウェブコンソールから S3 分析を定義している場合は、ソースバケットにレポート送信を許可するバケットポリシーにより、レポートを受信するデスティネーションバケットも自動的に設定されます。CloudFormation や CLI、あるいは SDK などのプログラム的な手法を使っている場合は、それに合ったバケットポリシーを定義する必要があります。ポリシーの例については、こちらをクリックしてください。
最初の S3 分析レポートは 24 時間以内に開始され、1 日に一回配信されるようになります。これが配信されると、次に示すような内容が s3://your_report_bucket/s3_analytics/ に格納されます。

これらの各フォルダーには、対象バケットの Amazon S3 分析レポートが記述された CSV ファイルが 1 つ置かれています。
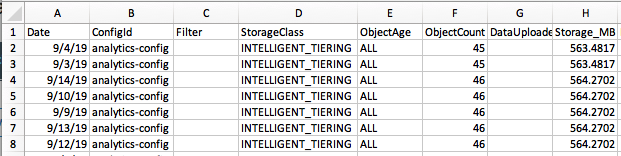
この中の 1 つをダウンロードして開くと、分析レポートを確認できます。次に示すのは、その一例です (簡潔にするため列を省略しています) 。
ステップ 2: AWS Glue によるクロールとカタログ化
AWS Glue では、完全マネージド型でサーバーレスの Apache Spark ETL ジョブに加え、Apache Hive Metastore に互換のデータカタログが利用できます。S3 のデータをこのカタログに追加しておけば、Amazon Athena (および、Amazon EMR や Amazon Redshift Spectrum を含む、複数の AWS のサービス) を使ったクエリがすぐに行えるようになります。
このリンクをクリックすると、us-east-1 にある CloudFormation スタックが起動されます。これには、Glue データベースと S3 分析レポート用のテーブルが定義済みです。また、このスタックには、新しく作られた各 S3 分析レポートを自動的にカタログ化し、カタログテーブルのパーティションとして追加するクローラーも含まれています。
AWS Lake Formationは、データレークのセットアップ、セキュリティ確保、そして管理を簡単にできるサービスですが、それを使用している場合、先の要領で起動した CloudFormation スタックが失敗する場合があります。このエラーが発生するかどうかは、データレークのアクセス許可の定義内容によります。具体的には、S3AnalyticsDatabase のスタックリソースを作成しようとして、 Insufficient Lake Formation Permissions: Required Create Database on Catalog というエラーが発生した場合は、AWS Lake Formation カタログ内でデータベースを作成するための権限を、Lake Formation の管理者から付与される必要があります。その後で、CloudFormation スタックをデプロイすることが可能になります。こちらのリンクから、 AWS Lake Formation と AWS Glue のアクセス許可モデルの詳細をご覧になれます。
ステップ 3: S3 分析レポートをクエリする
Amazon Athena コンソールを開き、左にあるドロップダウンメニューから、[s3_analytics] データベースを選択します。
次のようなコマンドを実行し、AWS Glue クローラーが Amazon S3 分析レポートを検知しており、Glue カタログを更新済みであることを確認します。
>>> Show partitions s3_analytics_report;
次の例のように、テーブルのパーティションとしてソースバケット名が表示されていれば、分析レポートのカタログ化は成功しています。
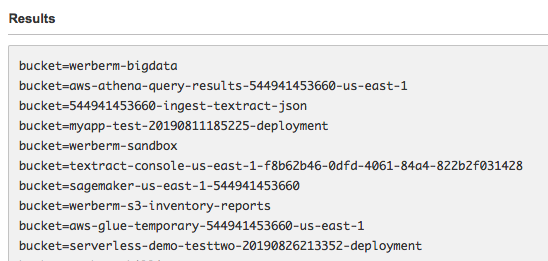
この段階で、標準 SQL を使い分析レポートをクエリできます。その例を次に示します。
SELECT bucket, *
FROM s3_analytics
WHERE object_count IS NOT NULL
ORDER BY storage_mb DESCこれに対し Amazon Athena が返す結果は次のようになります。

Amazon S3 分析の自動的な評価
ここまでで、Athena ウェブコンソールにある S3 分析データに対する、簡素な Amazon Athena SQL クエリの実行方法をご紹介してきました。しかしながら、新しい S3 ストレージ階層で推奨事項があるときにインフラストラクチャ担当チームに知らせ、さらなるストレージコストの低減に役立てたい場合などは、S3 分析のレビューや応答を自動的に行いたくなると思います。これは、本ブログ記事の範囲外になりますが、次のステップでこれを実現するためには、Amazon Athena での AWS CLI と SDK クエリに関する機能を参考にされると良いでしょう。
Amazon S3 Intelligent Tiering
このブログでは Amazon S3 分析について注目していますが、S3 が (2018 年 11 月に立ち上げた) S3 Intelligent-Tiering というものをご提供していることにも、ここで触れておくと良いと思います。Amazon S3 Intelligent-Tiering とは、ストレージコストを自動的に最適化させたいお客様向けに作られた S3 のストレージクラスです。これにより、データアクセスのパターンが変化したときでも、パフォーマンスへの影響や運用上のオーバーヘッドなしで最適化が行えます。S3 Intelligent-Tiering では、オブジェクトを 2 つの階層に保存します。その 1 つは高頻度のアクセスに最適化されており、また他方は、低コストで使え、低頻度アクセス向けに最適化された階層になっています。S3 Intelligent-Tiering では、アクセスパターンを監視し、連続 30 日間アクセスされていないデータを低頻度アクセス向けの階層に移動することで、毎月のモニタリング回数と自動化の料金を低減します。S3 Intelligent-Tiering では検索料金は発生しません。低頻度向け階層に移動されたオブジェクトに対し後にアクセスが発生した場合は、高頻度アクセス階層に自動的に戻されます。S3 Intelligent-Tiering の詳細についてはこちらをご参照ください。
コストとクリーンアップ
このブログ記事で示したデモ用アーキテクチャを作成すると、使用したサービスに関する少額の料金が発生します。たとえば、この執筆時点において、毎月 100 万オブジェクトをモニタリングするごとに 0.10 USD の料金が、Amazon S3 分析により課金されます。最新の料金については、Amazon S3、Amazon Athena、AWS Glue での各料金ページをご参照ください。
リソースをクリーンアップして料金の発生を止めるには、次のことを行います。
- ここで有効化したすべてのバケット向けの Amazon S3 分析レポートを無効化します。
- アルゴリズムの中心にある Amazon S3 レポーティングバケットに配信されたレポートを削除します。
- AWS CloudFormation スタックを削除することで AWS Glue リソースを削除します。
まとめ
今回の記事では、S3 分析レポートを単一の論理テーブルとしてカタログ化するための、AWS Glue の使用方法について解説しました。加えて、この記事の中では、それらのテーブルに対する SQL クエリを Amazon Athena を使って簡単に実行する方法も示しています。これらのレポートを活用すると、利用パターンに合わせパフォーマンスの最適化をしながら、ストレージコストを削減する手段が簡単に見つかります。
ご質問またはご提案については、以下でコメントを残してください。