Amazon Web Services ブログ
自動コピーを利用した Amazon S3 から Amazon Redshift への 簡易化されたデータ取り込み (プレビュー)
本記事は、「Simplify data ingestion from Amazon S3 to Amazon Redshift using auto-copy (preview)」を翻訳したものです。
Amazon Redshift は、標準 SQL と既存のビジネスインテリジェンス (BI) ツールを使用して、すべてのデータを分析することを簡単かつ費用効果の高いものにする、高速なペタバイトスケールのクラウドデータウェアハウスです。数万の顧客が、エクサバイトのデータを分析し、数万の顧客が Amazon Redshift を活用して、エクサバイトのデータを分析したり複雑な分析クエリを実行したりすることで、最高の価格性能を享受しています。
データ取り込みは、ソースシステムからデータを Amazon Redshift に取得するプロセスです。これには、AWS Glue、Amazon EMR、または AWS Step Functions などの多くの AWS クラウドベースの ETL ツールを使用するか、単純に COPY コマンドを使用して Amazon Simple Storage Service (Amazon S3) からデータを Amazon Redshift にロードすることができます。COPY コマンドは、Amazon Redshift の大規模並列処理 (MPP) アーキテクチャを使用して、S3 バケットの1つもしくは複数のファイルからデータを並列に読み込みロードするため、テーブルをロードする最も効率的な方法です。
今、Amazon Redshift の自動コピー (プレビュー版) 機能を使用して、SQL ユーザーはAmazon S3 からのデータ取り込みを簡単な SQL コマンドで自動化することができます。Amazon Redshift の自動コピーが指定された Amazon S3 パスで新しいファイルを検出すると、COPY ステートメントがトリガーされ、データの読み込みを開始します。これにより、ソースデータが利用可能になった直後に、エンドユーザーが Amazon Redshift でも最新のデータを利用できること保証されます。
この記事ではソースファイルがAmazon S3にある場合に、Amazon Redshiftで自動コピーを使用して、継続的なファイル取り込みパイプラインを簡単なSQLコマンドで構築する方法をご紹介しています。さらに、コピージョブを使用して自動コピーを有効にする方法、ジョブを監視する方法、考慮事項、およびベストプラクティスを紹介します。
Amazon Redshift の自動コピー機能の概要
Amazon Redshift の自動コピー機能は、簡単な SQL コマンドを使用して Amazon S3 からのデータの自動ロードを簡素化します。Amazon Redshiftの自動コピーを有効にするには、コピージョブを作成する必要があります。コピージョブは、S3 フォルダに新しく作成されたファイルのために COPY ステートメントを保存し、自動化し、再利用するデータベースオブジェクトです。
次の図は、このプロセスを示しています。
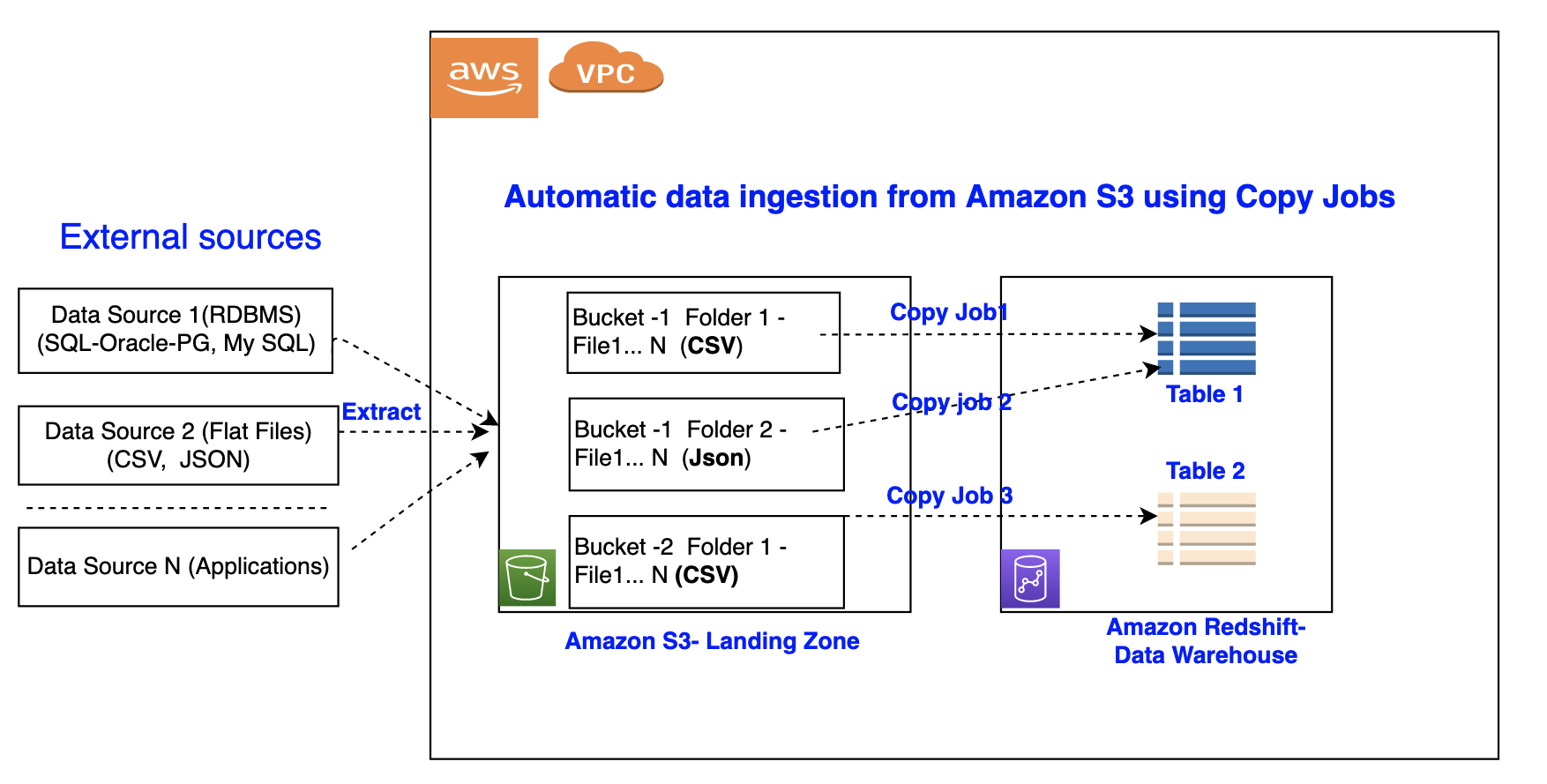
コピージョブには、以下の利点があります:
- データアナリストなどの SQL ユーザーは、パイプラインの構築をしたり外部フレームワークを使用することなく、Amazon S3 からデータを自動的にロードできます。
- コピージョブは、カスタムソリューションを実装する必要なく、Amazon S3 ロケーションからの継続的かつ増分データを取り込む機能を提供します。
- この機能は追加費用なしで利用できます。
- 既存の COPY ステートメントは、
JOB CREATE<job_name> パラメータを追加することで、コピージョブに変換することができます。 - すべてのロードされたファイルを追跡し、データの重複を防止します。
- シンプルな SQL ステートメントと任意の JDBC または ODBC クライアントを使用して簡単に設定できます。
前提条件
Amazon Redshift の自動コピー (プレビュー版) を利用するには、次の前提条件を満たす必要があります:
- AWS アカウント
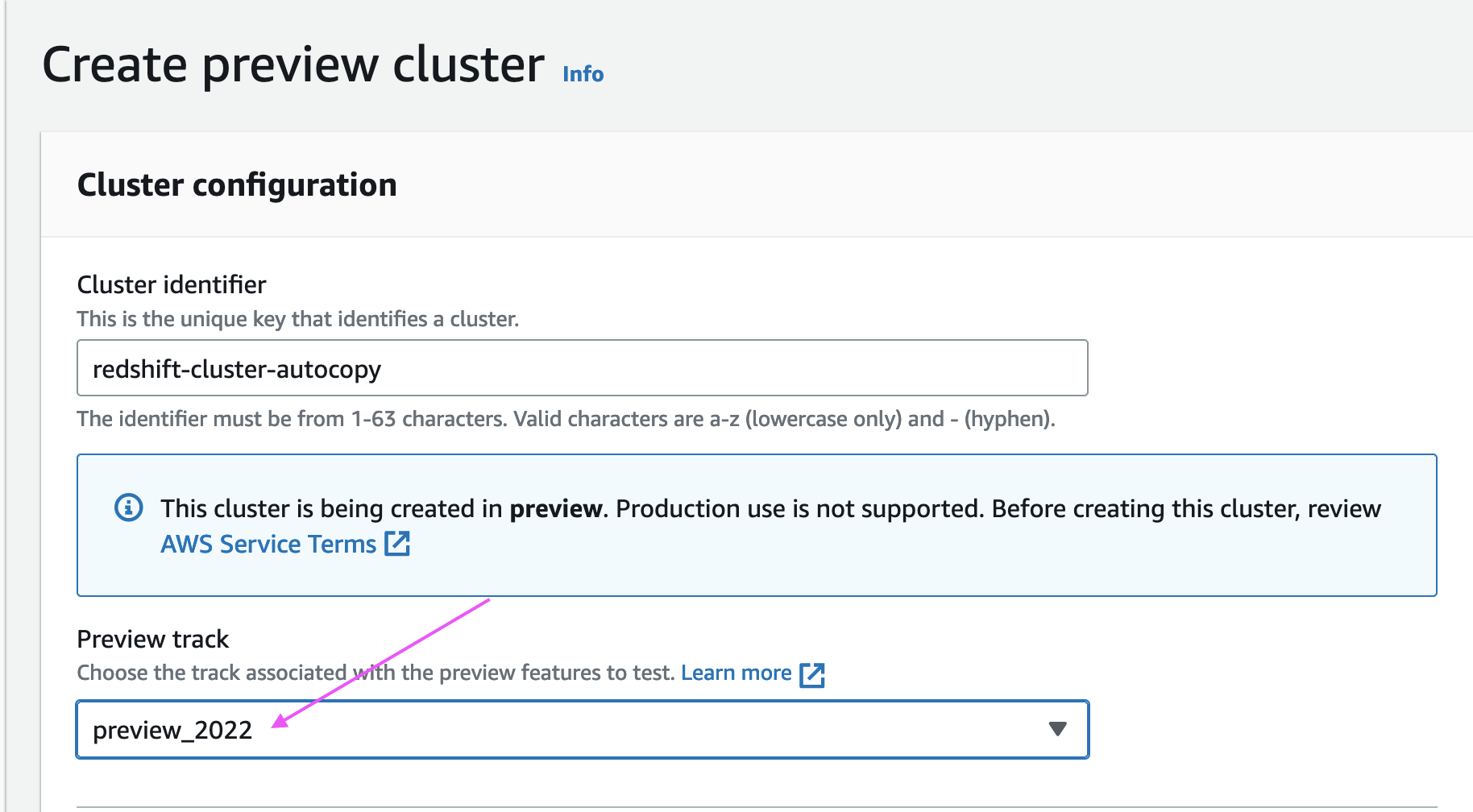
PREVIEW_2022のメンテナンストラックを持つ Amazon Redshift クラスター

Amazon S3 からの Amazon Redshift 自動コピーのサポートは、以下の AWS リージョンのプロビジョニングされたクラスター向けにプレビューとして提供されています:米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジア太平洋 (東京)、ヨーロッパ (アイルランド)、およびヨーロッパ (ストックホルム)。なお、プレビュートラックではスナップショットからのリストアはサポートされていません。
この投稿で使用される SQL ステートメントについては、SQL ノートブック「redshift-auto-copy-preview-demo-sql-notebook.ipynb」 を参照してください。
コピージョブの設定
このセクションでは、Amazon S3 から Amazon Redshift へのファイルのデータロードを自動化する方法を説明します。既存の COPY 構文を使用し、JOB CREATE パラメータを追加して自動ファイル取り込みのための初期設定を行います。以下のコードを参照してください:
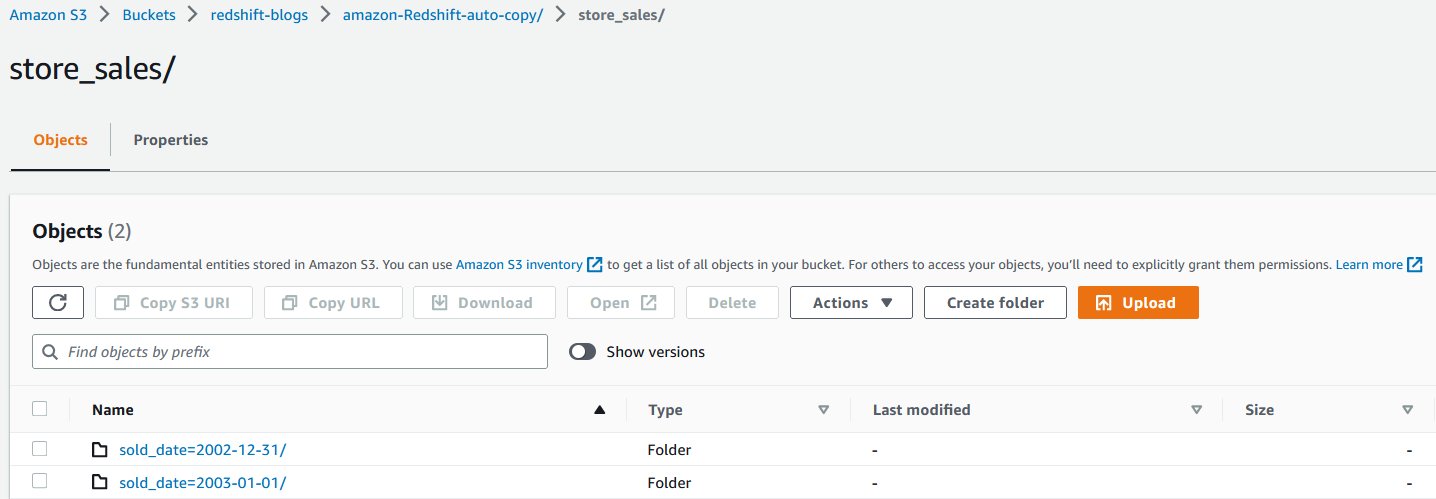
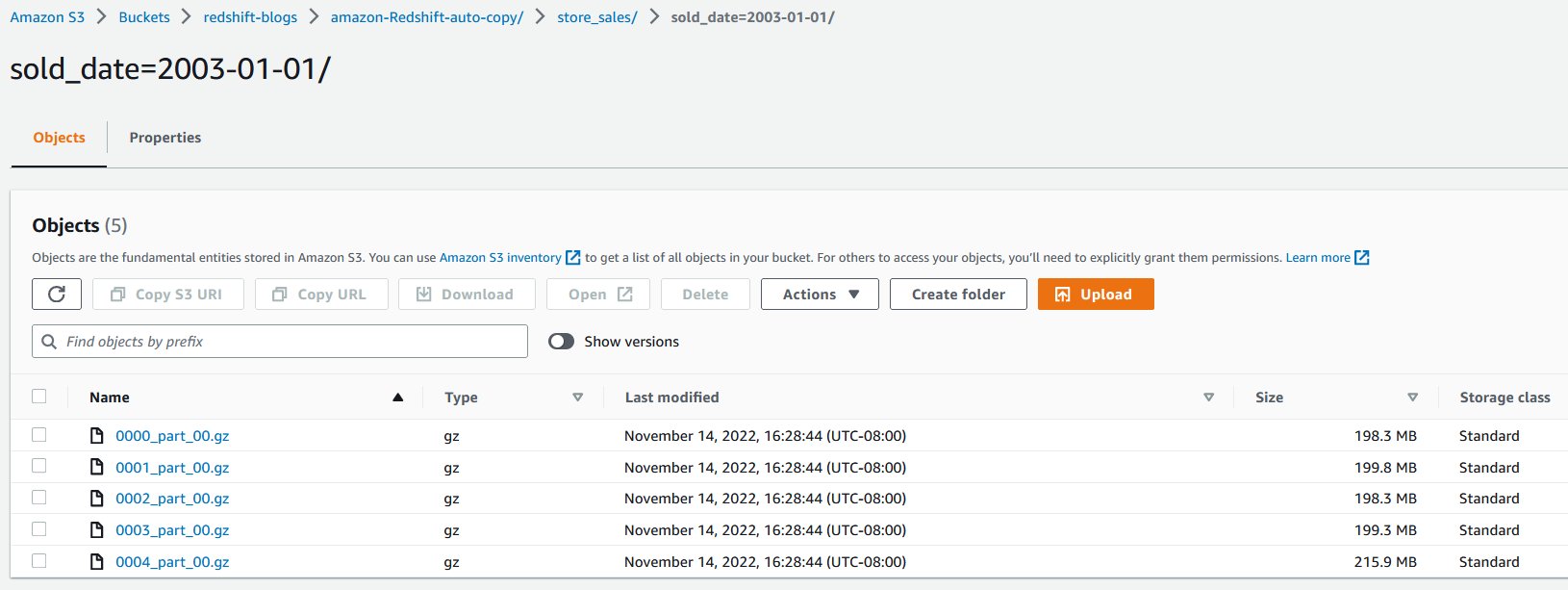
表示された出力は、それぞれ 2002-12-31 と 2003-1-1 に売り上げた取引から得られたものです。
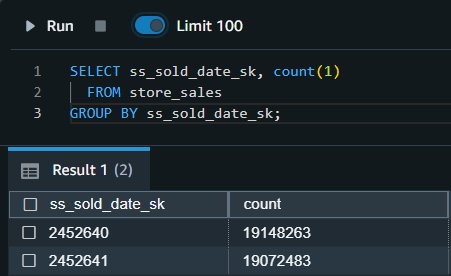
翌日、増分の売上トランザクションデータが同じ S3 オブジェクトパス内の新しいフォルダにロードされます。
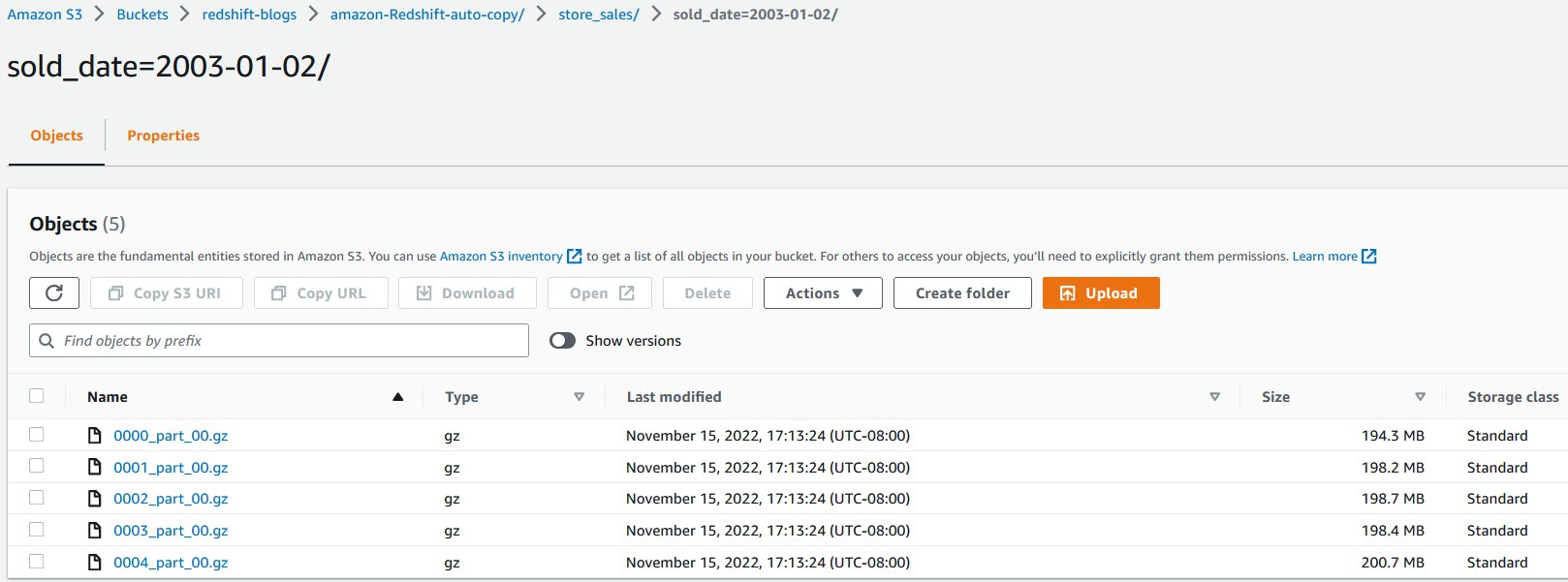
新しいファイルが同じ S3 オブジェクトパスに到着すると、コピージョブは自動的に未処理のファイルのみを store_sales テーブルに増分ロードします
2003-1-2 のすべての新しい売上トランザクションが自動的に取り込まれます。これを確認するために、次のクエリを実行します:

複数のデータソースからのデータの取り込みの自動化
複数のデータソースからAmazon Redshift テーブルにデータをロードすることもできます。複数の S3 バケットからデータを Amazon Redshift テーブルにロードする pub/sub パターンを使用する場合、各ソース/ターゲットの組み合わせごとに複数のデータパイプラインを維持する必要があります。COPY コマンドの新しいパラメータを使用することで、データのロードを自動化して効率的に処理することができます。
次の例では、Customer_1 フォルダには Green Cab Company の売上データがあり、Customer_2 フォルダには Red Cab Company の売上データがあります。COPY コマンドに JOB パラメータを使用して、このデータ取り込みプロセスを自動化することができます。
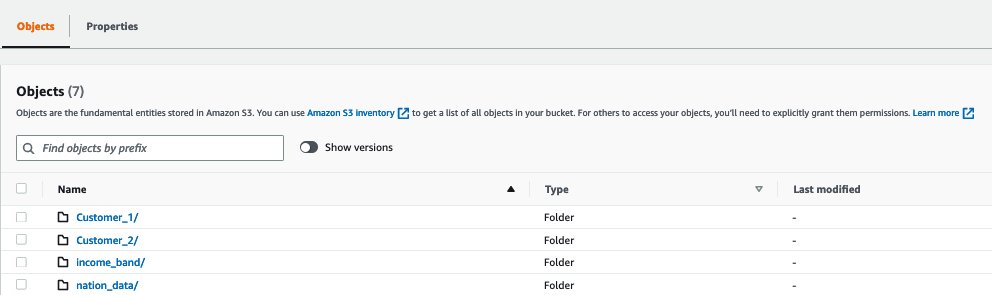
以下のスクリーンショットは、ファイルに保存されたサンプルデータを示しています。各フォルダには似たデータが含まれていますが、異なる顧客のデータが含まれています。

この例では、これらのファイルのターゲットは Amazon Redshift のテーブル cab_sales_data です。
ターゲットテーブルである cab_sales_data テーブルを定義します。
次のコードに示すように、異なる顧客 (ここでは Customer_1 と Customer_2) に属する売上データの取り込みを監視および処理する2つのコピージョブを定義することができます。これらのジョブは Customer_1 および Customer_2 フォルダを監視し、ここに追加された新しいファイルをロードします。
各顧客には、次の出力に示すように、独自の vendorid が割り当てられます:

手動でコピージョブを実行する
コピージョブを一時停止して新しいファイルのロードを停止する必要があるシナリオがあるかもしれません。例えば、データソースにおいて破損したデータパイプラインを修正するシナリオです。
その場合、COPY JOB ALTER コマンドを使用して AUTO OFF に設定するか、AUTO OFF の新規 COPY JOB を作成します。この設定を行うと、自動コピーは新しいファイルを探さなくなります。
必要であれば、ユーザーは手動で COPY JOB を起動し、新しいファイルが見つかれば取り込むようにします。
COPY JOB RUN <Copy Job Name>
既成のコピージョブで「AUTO ON」を無効にするには、次のコマンドを使用します:
COPY JOB ALTER <Copy Job Name> AUTO OFF
次の表は、通常のコピーと新しい自動コピージョブの構文とデータの重複を比較したものです。
| . | コピー | 自動コピージョブ (プレビュー) |
| 構文 | COPY <table-name>
|
COPY <table-name>
|
| データ重複 | 同じ S3 フォルダに対して複数回実行すると、再度データを読み込むことになり、データの重複が発生します。 | 同じファイルを 2 度読み込まないため、データの重複を防ぐことができます。 |
コピージョブのプレビューの中で、他のデータフォーマットへの対応が進められる予定です。
コピージョブのエラーハンドリングと監視
コピージョブは、ジョブ作成時に指定したS3フォルダーを継続的に監視し、新しいファイルが作成されるたびに取り込みを実行します。S3フォルダーの下に作成された新しいファイルは、データの重複を避けるために正確に一度だけロードされます。
デフォルトでは、特定のファイルにデータまたはフォーマットの問題がある場合、コピージョブはロードエラーでファイルの取り込みに失敗し、システムテーブルに詳細が記録されます。コピージョブは新しいデータファイルに対しては引き続き AUTO ON のままとなり、以前に失敗したファイルは無視され続けます。
Amazon Redshiftは、必要に応じてコピージョブを監視またはトラブルシューティングするために、ユーザーのために以下のシステムテーブルを提供します:
- コピージョブの一覧 – SYS_COPY_JOB を使用して、データベースに格納されているすべてのコピージョブを一覧表示します:

- コピージョブの集計を取得する – SYS_LOAD_HISTORY ビューを使用して、
copy_job_idを指定して、コピージョブ操作の集計メトリクスを取得します。コピージョブによって処理されたすべてのファイルの集計メトリクスが表示されます。

- コピージョブの詳細を取得する – STL_LOAD_COMMITS を使用して、コピージョブによって処理された各ファイルのステータスと詳細を取得します:

- コピージョブのエラーの詳細を取得する – STL_LOAD_ERRORS を使用して、コピージョブから取り込みに失敗したファイルの詳細を取得します:

コピージョブのベストプラクティス
コピージョブでは、新しいファイルが検出され、(自動または手動で)取り込まれると、Amazon Redshift はファイル名を記録し、同じファイル名で新しいファイルが作成されたときにこの特定のジョブを実行しないようにします。
以下は、コピージョブを使用してファイルを操作する際に推奨されるベストプラクティスです:
- コピージョブの各ファイルには一意のファイル名を使用します (例:
2022-10-15-batch-1.csv)。 ただし、異なるコピージョブからのファイルであれば、同じファイル名を使用することができます:- job_customerA_sales –
s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv - job_customerB_sales –
s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv
- job_customerA_sales –
- ファイルの内容を更新しないでください。既存のファイルを上書きしないでください。既存のファイルの変更は、ターゲットテーブルに反映されません。コピージョブは更新されたファイルや上書きされたファイルを検知しないので、コピージョブが検知するために新しいファイル名としてリネームされていることを確認してください。
- コピージョブで処理済みのファイルを取り込む必要がある場合は、通常の COPY ステートメント (ジョブではない) を実行します。(コピージョブを伴わない COPY は、読み込まれたファイルを追跡しません。) たとえば、ファイル名を制御できない場合に、最初に受け取ったファイルのコピーが失敗したようなシナリオで役に立ちます。次の図は、この場合の典型的なワークフローを示したものです。
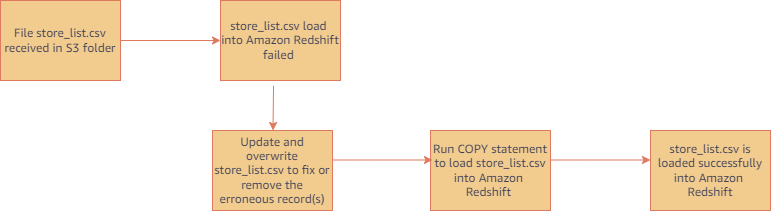
- ファイルの追跡履歴をリセットしてやり直す場合は、コピージョブを削除して再作成してください。
コピージョブの考慮点
プレビュー中、自動コピーを使用する際の主な注意点を以下に示します:
- コピージョブは、空の S3フォルダー (既存のファイルがない) を使用して作成する必要があります。
- 以下の機能はサポートされていません:
- MAXERROR パラメータ
- マニフェストファイル
- キーベースのアクセスコントロール
- 列データ形式 (Parquet、ORC、RCFile、SequenceFile)
- デフォルトの
IAM_ROLEの使用
自動コピープレビューのその他の考慮事項については、AWS のドキュメントを参照してください。
お客様の声
GE Aerospace は、民間機および軍用機用のジェットエンジン、コンポーネント、システムを提供するグローバル企業です。同社は第一次世界大戦以来、ジェットエンジンの設計、開発、製造を行っています。
“GE Aerospace は、AWS 分析サービスと Amazon Redshift を使用して、重要なビジネス上の意思決定を促進するクリティカルなビジネスインサイトを得ています。Amazon S3 からの自動コピーに対応したことで、Amazon S3 から Amazon Redshift へデータを取り込むための、よりシンプルなデータパイプラインを構築することができます。これにより、データプロダクトチームがデータにアクセスし、エンドユーザーにインサイトを提供する能力が加速されます。データを通じて価値の創造に多くの時間を費やし、統合に費やす時間を減らしています。”
– Alcuin Weidus GE エアロスペース社 シニアプリンシパルデータアーキテクト
まとめ
この記事では、自動コピープレビュー機能を使用して Amazon S3 から Amazon Redshift へのデータロードを自動化する方法をご紹介しました。この新機能は、Amazon Redshift のデータ取り込みをこれまで以上に簡単にするのに役立ち、SQL ユーザーがシンプルな SQL コマンドを使用して最新のデータにアクセスできるようにします。
アナリストやSQLユーザーであれば、簡単なSQLコマンドでAmazon S3からRedshiftへのデータ取り込みを開始でき、サードパーティーのツールやカスタム実装を必要とせず、最新のデータにアクセスすることができます。
執筆者について
 Jason Pedreza は AWS の Analytics Specialist Solutions Architect で、ペタバイトのデータを扱うデータウェアハウスの経験がある。AWS 入社以前は、Amazon.com でデータウェアハウスソリューションを構築。 Amazon Redshift に特化し、スケーラブルな分析ソリューションの構築を支援している。
Jason Pedreza は AWS の Analytics Specialist Solutions Architect で、ペタバイトのデータを扱うデータウェアハウスの経験がある。AWS 入社以前は、Amazon.com でデータウェアハウスソリューションを構築。 Amazon Redshift に特化し、スケーラブルな分析ソリューションの構築を支援している。
 Nita Shah はニューヨークを拠点とする AWS のアナリティクススペシャリストソリューションアーキテクトです。20年以上にわたりデータウェアハウスソリューションを構築しており、Amazon Redshift を専門としています。彼女は、エンタープライズスケールの well-architected な分析および意思決定支援プラットフォームの設計と構築を支援することに重点を置いています。
Nita Shah はニューヨークを拠点とする AWS のアナリティクススペシャリストソリューションアーキテクトです。20年以上にわたりデータウェアハウスソリューションを構築しており、Amazon Redshift を専門としています。彼女は、エンタープライズスケールの well-architected な分析および意思決定支援プラットフォームの設計と構築を支援することに重点を置いています。
 Eren Baydemir は AWS のテクニカルプロダクトマネージャーであり、顧客向け製品の構築に15年の経験を持ち、現在は Amazon Redshift チームでデータレイクとファイル取り込みのトピックに焦点を当てています。2020年に Amazon に買収された DataRow の CEO 兼共同創業者でもあります。
Eren Baydemir は AWS のテクニカルプロダクトマネージャーであり、顧客向け製品の構築に15年の経験を持ち、現在は Amazon Redshift チームでデータレイクとファイル取り込みのトピックに焦点を当てています。2020年に Amazon に買収された DataRow の CEO 兼共同創業者でもあります。
 Eesha Kumar は AWS のアナリティクスソリューションアーキテクトです。AWS のプラットフォームとツールを使ったソリューションの構築を支援することで、データのビジネス価値を実現するために顧客と協働しています。
Eesha Kumar は AWS のアナリティクスソリューションアーキテクトです。AWS のプラットフォームとツールを使ったソリューションの構築を支援することで、データのビジネス価値を実現するために顧客と協働しています。
 Satish Sathiya は Amazon Redshift のシニアプロダクトエンジニアです。彼は熱心なビッグデータ愛好家であり、世界中の顧客と協力して成功を収め、データウェアハウスとデータレイクアーキテクチャのニーズを満たしています。
Satish Sathiya は Amazon Redshift のシニアプロダクトエンジニアです。彼は熱心なビッグデータ愛好家であり、世界中の顧客と協力して成功を収め、データウェアハウスとデータレイクアーキテクチャのニーズを満たしています。
 Hangjian Yuan は Amazon Redshift のソフトウェア開発エンジニアです。分析データベースに情熱を注ぎ、お客様に最先端のストリーミング体験を提供することに力を注いでいます。
Hangjian Yuan は Amazon Redshift のソフトウェア開発エンジニアです。分析データベースに情熱を注ぎ、お客様に最先端のストリーミング体験を提供することに力を注いでいます。
翻訳はソリューションアーキテクトの小役丸が担当しました。原文はこちらです。