リレーショナルデータベースと非リレーショナルデータベースの違いとは?
リレーショナルデータベースと非リレーショナルデータベースの違いは何ですか?
リレーショナルデータベースと非リレーショナルデータベースは、アプリケーションのデータストレージの 2 つの方法です。リレーショナルデータベース (または SQL データベース) は、行と列の表形式でデータを格納します。列にはデータ属性が含まれ、行にはデータ値が含まれます。リレーショナルデータベース内のテーブルをリンクして、さまざまなデータポイント間の相互接続についてより深いインサイトを得ることができます。一方、非リレーショナルデータベース (または NoSQL データベース) は、データへのアクセスと管理にさまざまなデータモデルを使用します。このデータベースは、大容量のデータボリューム、および低レイテンシーを必要とするアプリケーション向けに最適化されています。これは他のデータベースのデータ整合性の制限の一部を緩和することによって達成されます。
リレーショナルデータベースはデータをどのように保存しますか?
リレーショナルデータベースは、列と行を含むテーブルにデータを格納します。各列は特定のデータ属性を表し、各行はそのデータのインスタンスを表します。
各テーブルにプライマリキー、つまりテーブルを一意に識別する識別子列を指定します。プライマリキーを使用してテーブル間のリレーションシップを確立します。これを使用して、テーブル間の行を別のテーブルの外部キーとして関連付けることができます。
2 つのテーブルを接続すると、1 つのクエリで両方のテーブルからデータを取得できます。リレーショナルデータベースを操作する SQL クエリを記述します。
保存データの例
たとえば、ある小売業者がすべての製品のテーブルを作成したとします。このテーブルには、製品名、説明、価格の列を表示できます。別のテーブルには、顧客、顧客名、購入内容に関するデータが含まれています。
次のテーブルは、このアプローチを示しています。
|
Product_id (プライマリキー) |
Product_name |
Product_cost |
|
P1 |
Product_A |
100 USD |
|
P2 |
Product_B |
50 USD |
|
P3 |
Product_C |
80 USD |
|
Customer_id |
customer-name |
Item_purchased (外部キー) |
|
C1 |
Customer_A |
P2 |
|
C2 |
Customer_B |
P1 |
|
C3 |
Customer_C |
P3 |
非リレーショナルデータベースはデータをどのように保存しますか?
スキーマレスデータを管理、保存する方法の違いから、いくつかの異なる非リレーショナルデータベースシステムが存在します。スキーマレスデータとは、リレーショナルデータベースが要求する制約を受けずに保存されるデータのことです。
次に、一般的なタイプの非リレーショナルデータベースについて説明します。
Key-Value データベース
Key-Value データベースは、データをキーと値のペアの収集として保存します。ペアでは、キーが一意の識別子の役割を果たします。キーと値のどちらも、単純なオブジェクトから複雑な複合オブジェクトまで、何であってもかまいません。
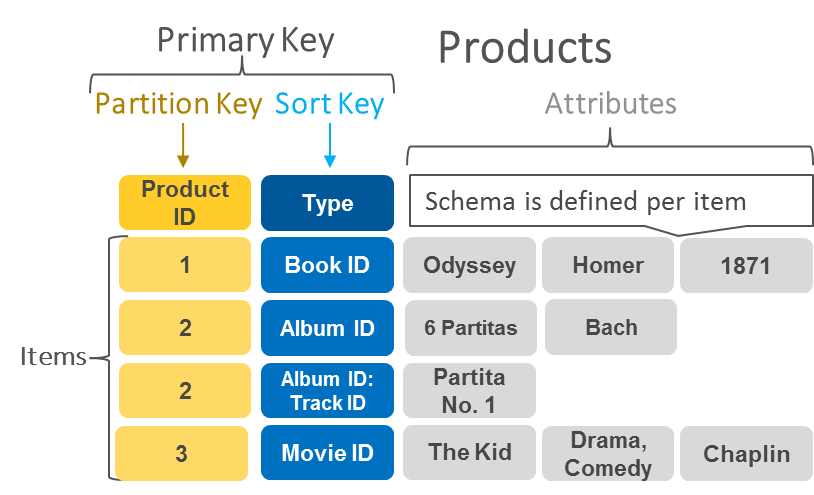
ドキュメントデータベース
ドキュメント指向データベースは、開発者がアプリケーションコードで使用するのと同じドキュメントモデル形式です。データを JSON オブジェクトとして格納します。これらのオブジェクトは、柔軟性があり、半構造化され、階層化されています。
次の例は、ドキュメントデータベースに保存されているデータがどのように見えるかを示しています。
|
{ company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
グラフデータベース
グラフデータベースは、リレーションシップの格納とナビゲートを目的として構築されたデータベースです。ノードを使用してデータエンティティを格納し、エッジを使用してエンティティ間のリレーションシップを格納します。
エッジには常に開始ノード、終了ノード、タイプおよび方向があります。たとえば、親子関係、アクション、所有権を記述できます。

主な違い: リレーショナルデータベースと非リレーショナルデータベース
リレーショナルデータベースと非リレーショナルデータベースでは、データの保存と管理方法が大きく異なります。次のセクションでは、具体的な違いについて説明します。
構造
リレーショナルデータベースは、データを表形式で保存し、データのバリエーションとテーブルのリレーションシップに関する厳格なルールに従います。これにより、データの整合性と一貫性を維持しながら、構造化データに対する複雑なクエリを処理できます。
非リレーショナルデータベースは、要件が変化するデータに対してより柔軟で有用です。これらを使用して、画像、動画、ドキュメント、その他の半構造化および非構造化コンテンツを保存できます。
データの完全性メカニズム
アトミック性、一貫性、分離性、耐久性 (ACID) とは、データ処理のエラーや中断にもかかわらず、データの完全性を維持するデータベースの能力のことです。
リレーショナルデータベースモデルは厳密な ACID 特性に従います。これは、結果が伴う一連のオペレーションは、必ず一緒に完了することを意味します。1 つのオペレーションが失敗すると、一連のオペレーションがすべて失敗します。これにより、常にデータの正確性が保証されます。
これに対して、非リレーショナルデータベースは、基本的に可用性があり、ソフトステートで、最終的に一貫性がある (BASE) という、より柔軟なモデルを提供しています。
非リレーショナルデータベースは可用性を保証しますが、即時の一貫性は保証しません。データベースの状態は時間の経過とともに変化することがあり、最終的には一貫性が保たれます。非リレーショナルデータベースの中には、ACID 準拠のパフォーマンスや他のトレードオフを提供するものもあります。
パフォーマンス
リレーショナルデータベースのパフォーマンスは、そのディスクサブシステムに左右されます。データベースのパフォーマンスを向上させるには、SSD を使用し、独立ディスクの冗長アレイ (RAID) で構成することでディスクを最適化できます。パフォーマンスを最大限引き出すには、インデックス、テーブル構造、クエリを最適化する必要もあります。
これに対して、NoSQL データベースのパフォーマンスは、ネットワークレイテンシー、ハードウェアクラスターサイズ、およびコールアプリケーションに左右されます。非リレーショナルデータベースのパフォーマンスを向上させる方法はいくつかあります。
- クラスターサイズを大きくする
- ネットワークレイテンシーを最小化する
- インデックスとキャッシュ
NoSQL データベースは、リレーショナルデータベースと比較して、特定のユースケースでより高いパフォーマンスとスケーラビリティを提供します。
スケール
リレーショナルデータベースシステムの厳格なスキーマは、規模が大きくなると課題となる場合があります。通常、サーバーに CPU または RAM リソースを追加することで垂直方向にスケールします。読み取り専用のワークロード用にサーバー間でデータを複製することで、水平方向にスケールすることもできます。ただし、読み取り/書き込みワークロードの水平スケーリングには、パーティショニングやシャーディングなどの特別な戦略が必要です。
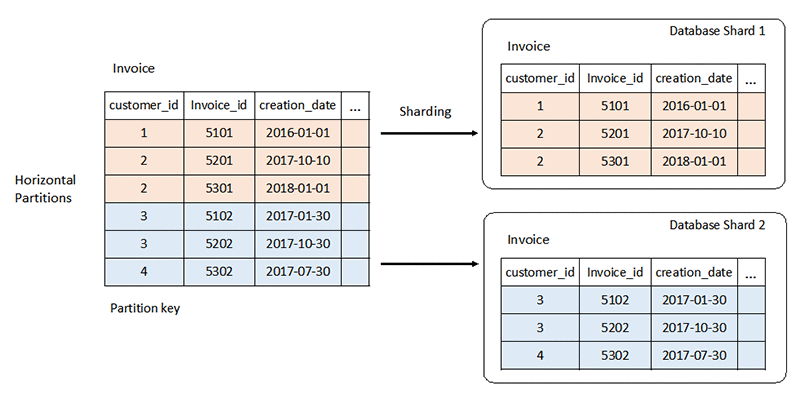
これに対して、NoSQL データベースは非常にスケーラブルです。ワークロードをより簡単に多くのノードに分散することができます。これらのデータベースは、小さなセットにパーティショニングし、そのセットを複数のノードに分散することで、大量のデータを処理することができます。

リレーショナルデータベースと非リレーショナルデータベースの使用タイミング
データのサイズ、構造、アクセス頻度が予測可能な場合には、リレーショナルデータベースが最適です。エンティティ間のリレーションシップが重要な場合は、リレーショナルデータベース管理システムを使用することをお勧めします。たとえば、構造や関係が複雑な大規模なデータセットがある場合、分析や使いやすさのためにそのリレーションシップを際立たせたいと思うでしょう。
これに対して、形状やサイズが柔軟であったり、将来的に変化する可能性のあるデータを保存する場合には、非リレーショナルモデルが効果的です。
また、場合によっては、データリレーションシップが表形式のプライマリキーと外部キーの形式にうまく収まらないこともあります。たとえば、ソーシャルメディアネットワーク内の友人や人間関係をモデル化するには、リレーショナルデータベースでは何百行ものテーブルが必要になります。
これに対して、非リレーショナルデータベースではこれを 1 行で表すことができます。次の例は、非リレーショナルデータベースに 4 人の友人がいるメンバーのデータエントリを示しています。
|
Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{メンバー名:「メンバー 1」 メンバーの友人:「メンバー 2、メンバー 3、メンバー 4、メンバー 5」} |
違いのまとめ: リレーショナルデータベースと非リレーショナルデータベース
|
カテゴリ |
リレーショナルデータベース |
非リレーショナルデータベース |
|
データモデル |
表形式。 |
Key-value、ドキュメント、またはグラフ。 |
|
データタイプ |
構造化データ。 |
構造化データ、半構造化データ、非構造化データ。 |
|
データの完全性 |
ACID に完全準拠で高品質。 |
最終的な整合性モデル。 |
|
パフォーマンス |
サーバーにリソースを追加することで改善されました。 |
サーバーノードを追加することで改善されました。 |
|
スケーリング |
水平スケーリングには追加のデータ管理戦略が必要です。 |
水平スケーリングの使用は簡単です。 |
AWS はリレーショナルデータベースと非リレーショナルデータベースの要件をどのようにサポートできますか?
Amazon Web Services (AWS) は、リレーショナルおよび非リレーショナルデータベースの要件に対応する多くのサービスを提供しています。
リレーショナルデータベース向け AWS サービス
Amazon Relational Database Service (Amazon RDS) はマネージドサービスを集めたものであり、クラウド内でリレーショナルデータベースを簡単にセットアップ、運用、およびスケールできるようにします。クラウドデータベースには、パフォーマンス、スケール、コスト効率といった、多くの利点があります。次のようなリレーショナルデータベースエンジンを使用できます。
- SQL Server 用 Amazon RDS で複数のエディションの SQL Server (2014、2016、2017、2019) をデプロイできます
- MySQL コミュニティエディションバージョン 5.7 と 8.0 をサポートする Amazon RDS for MySQL
- Amazon RDS for MariaDB が MariaDB サーバーバージョン 10.3、10.4、10.5、10.6 をサポートする
さらに、 Amazon RDS for Oracle には 2 つの異なるライセンスモデルがあります。つまり、オラクルのライセンスをお持ちでない場合は、別途購入する必要はありません。
非リレーショナルデータベース向け AWS サービス
また、AWS は複数の NoSQL データベースサービスを備えており、あらゆる NoSQL の要件に対応することができます。次に例を示します。
- Amazon DynamoDB は、あらゆる規模のワークロードに対して一貫した 1 桁ミリ秒単位のレイテンシーを提供するキーバリュー型データベースサービスです。
- Amazon DocumentDB (MondoDB との互換性あり) は、柔軟で反復的な開発を可能にする強力で直感的な API を備えた、人気の高いドキュメント指向データベースです。
- Amazon MemoryDB は、耐久性に優れたインメモリデータベースサービスです。マイクロ秒の読み取り/書き込みレイテンシーを実現し、超高速のパフォーマンスを実現します。
- Amazon Neptune は、高性能グラフアプリケーションを構築して実行するためのフルマネージド型のグラフデータベースサービスです。
- Amazon OpenSearch Service は、機械で生成されたデータをほぼリアルタイムで視覚化および分析することを目的として構築されています。
今すぐアカウントを作成して、AWS のリレーショナルデータベースと非リレーショナルデータベースを使い始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages