Amazon Web Services 한국 블로그
Amazon Comprehend – 딥러닝 기반 실시간 자연어 인식 서비스 출시
몇년 전 메릴랜드 대학교 CS 도서관을 돌아다니다가 컴퓨터가 할 수 없는 일(What Computers Can’t Do)과 그 후속작인 컴퓨터가 여전히 할 수 없는 일(What Computers Still Can’t Do)이라는 오래된 책을 발견했습니다. 이것은 컴퓨터 공학이 관심을 가지고 연구할 만한 분야라는 사실을 깨달았습니다. 이 게시물을 준비하는 동안 저는 첫 번째 책의 복사본을 찾았고, 아래와 같은 흥미로운 의견을 발견했습니다.
자연 언어의 문장을 사용하고 이해하는 인간에게는 문장의 맥락 의존성의 사용에 대한 암시적 지식이 필요합니다. 이는 Turing의 의문대로 컴퓨터가 자연 언어를 이해하고 번역할 수 있는 컴퓨터를 만드는 유일한 방법이자 세상을 학습하도록 프로그래밍하는 유일한 방법일 것입니다.
이는 통찰력 있는 의견이었고, 텍스트로 부터 새로운 의미와 가치를 발견할 수 있는 신규 서비스인 Amazon Comprehend 소개합니다.
Amazon Comprehend 소개
![]() Amazon Comprehend는 영어 또는 스페인어 텍스트에서 다양한 유형의 엔터티(사람, 장소, 브랜드, 제품 등), 핵심 구절, 감정(긍정, 부정, 혼재 또는 중립)을 식별하고, 핵심 구절을 추출합니다. Comprehend의 주제 모델링 서비스는 분석 및 주제 기반 그룹화용 대량의 문서로부터 주제를 추출합니다.
Amazon Comprehend는 영어 또는 스페인어 텍스트에서 다양한 유형의 엔터티(사람, 장소, 브랜드, 제품 등), 핵심 구절, 감정(긍정, 부정, 혼재 또는 중립)을 식별하고, 핵심 구절을 추출합니다. Comprehend의 주제 모델링 서비스는 분석 및 주제 기반 그룹화용 대량의 문서로부터 주제를 추출합니다.
이상 4개의 기능(언어 감지, 엔터티 범주화, 감정 분석 및 핵심 구절 추출)은 수백 밀리초 내에 응답이 가능한 대화식 사용을 위해 설계되었습니다. 주제 추출은 작업 기반 모델에서 작동하며, 응답은 컬렉션의 크기와 비례합니다.
Comprehend는 지속적으로 데이터 훈련을 하는 자연 언어 처리(NLP) 서비스입니다. AWS 엔지니어 및 데이터 과학자 팀이 계속해서 훈련 데이터를 확장 및 정제합니다. 시간이 흐름에 따라 서비스가 더욱 정확해지고 더욱 폭넓게 적용 가능하도록 하는 것이 목표입니다.
Amazon Comprehend 둘러보기
AWS 관리 콘솔을 사용하여 Amazon Comprehend를 둘러보고 Comprehend API를 사용하는 애플리케이션을 빌드할 수 있습니다. Direct Connect에 관한 제 최신 게시물의 첫 문단을 사용하여 Amazon Comprehend API 탐색기를 연습해 보겠습니다. 상자에 텍스트를 붙여넣고 [Analyze]를 클릭합니다.
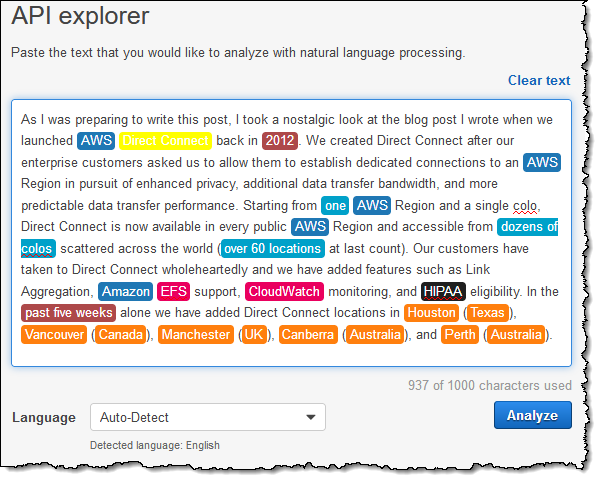
Comprehend가 빠르게 텍스트를 처리하고, 식별한 엔터티(위에 나와 있습니다)를 강조 표시한 다음 모든 기타 정보를 클릭 한 번으로 사용할 수 있습니다.
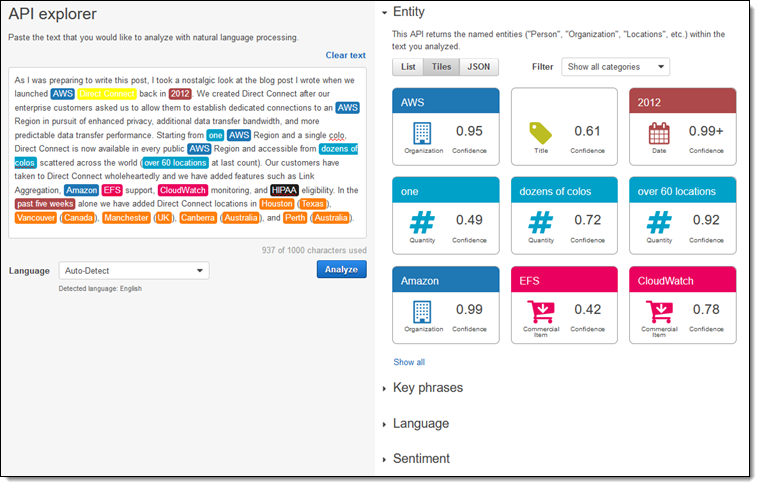
결과의 각 부분을 살펴보겠습니다. Comprehend가 제가 입력한 텍스트의 엔터티의 여러 범주를 감지할 수 있습니다.
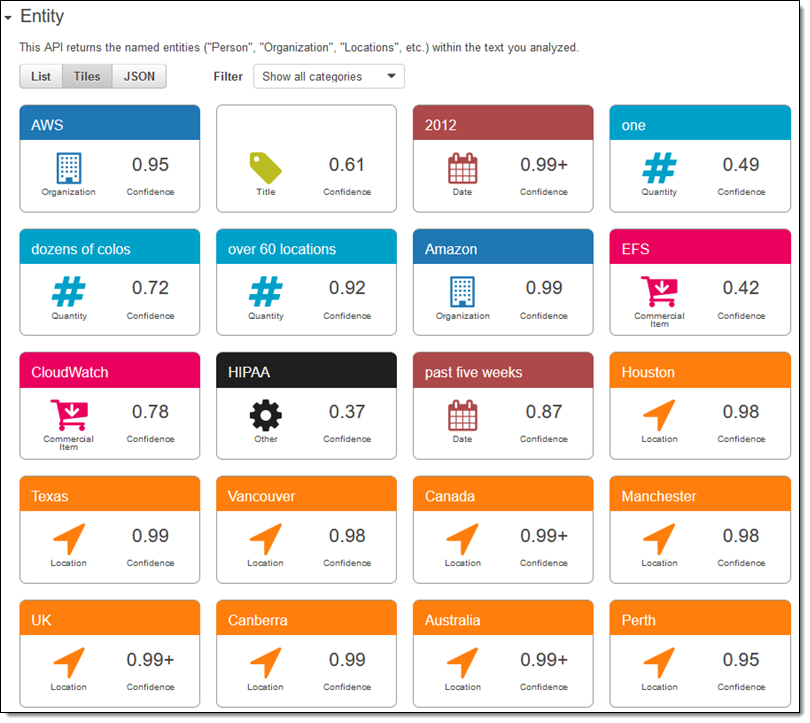
텍스트에서 발견된 모든 엔터티입니다(목록으로 또는 원시 JSON 형식으로도 표시될 수 있습니다).
첫 핵심 구절입니다(나머지는 [Show all]을 클릭하면 확인할 수 있습니다).
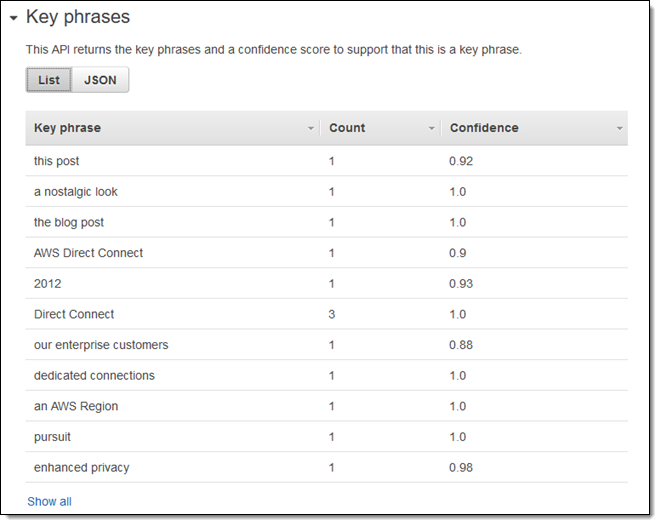
언어와 감정도 간단하게 파악할 수 있습니다.
그렇습니다. 이것은 대화형 함수입니다. 그럼 배치를 살펴보겠습니다. 이미 하나의 S3 버킷에는 수천 개의 제 이전 블로그 게시물이 포함되어 있고, 결과를 위해 마련한 빈 버킷, 그리고 Comprehend가 두 버킷 모두에 액세스할 수 있도록 하는 IAM 역할이 있습니다. 입력을 한 다음 [Create job]을 클릭하여 시작합니다.
콘솔에서 제 최근 작업을 볼 수 있습니다.
작업이 완료되면 버킷에 결과가 표시됩니다.
시연을 목적으로 저는 데이터를 다운로드하고 내부를 들여다 볼 수 있습니다(대부분의 경우 이를 시각화 또는 분석 도구에 저장합니다).
공통 주제 번호(첫 번째 열) 내에 있는 용어와 관련이 있는 topic-terms.csv 파일 클러스터입니다. 처음 25개의 행입니다.
doc-topics.csv 파일은 어떤 파일이 최초 파일의 주제를 참조하는지 나타냅니다. 이번에도 처음 25개의 행입니다.
애플리케이션 구축하기
대부분의 경우 Amazon Comprehend API를 사용하여 자연 언어 처리를 자체 애플리케이션에 추가할 것입니다. 주요 대화형 함수는 다음과 같습니다.
DetectDominantLanguage– 텍스트의 중심 언어를 감지합니다. 다른 함수들 가운데 이 정보를 입력해야 하는 경우도 있으니 이 함수를 먼저 호출해야 합니다.DetectEntities– 텍스트의 엔터티를 감지하고 JSON 형식으로 이를 반환합니다.DetectKeyPhrases– 텍스트의 핵심 구절을 감지하고 JSON 형식으로 이를 반환합니다.DetectSentiment– 텍스트의 감정을 감지하고 POSITIVE, NEGATIVE, NEUTRAL 또는 MIXED로 반환합니다.
또한 이러한 함수에 4개의 변수가 있습니다(각각 다음 접두사가 포함됩니다). Batch따라서 최대 25개의 문서를 동시에 처리할 수 있습니다. 이들을 사용하여 처리량이 높은 데이터 처리 파이프라인을 빌드할 수 있습니다.
- 주제 감지 작업을 생성 및 관리하는 데 사용할 수 있는 함수는 다음과 같습니다.
StartTopicsDetectionJob– 작업을 생성하고 실행을 시작합니다.ListTopicsDetectionJobs– 현재 및 최근 작업의 목록을 가져옵니다.DescribeTopicsDetectionJob– 단일 작업에 관한 세부 정보를 가져옵니다.
정식 출시
Amazon Comprehend는 현재 사용 가능하며, 오늘부터 이를 사용하여 애플리케이션에 적용할 수 있습니다! 자세한 사항은 요금 페이지 및 고객 사례, 기술 문서를 참고하세요.
– Jeff;
이 글은 AWS re:Invent 2017 신규 서비스 소식으로 Amazon Comprehend – Continuously Trained Natural Language Processing의 한국어 번역입니다.