Amazon Web Services 한국 블로그
AWS Batch – 배치(Batch) 컴퓨팅 관리 서비스 출시
제가 대학에 들어갔던 1978년에 Montgomery College 전산학과에는 IBM 370/168라는 메임 프레임이 있었고, 저는 카드 천공기를 통해 Job Control Language (JCL) 문법을 작성하는 것을 배웠습니다. (그 뒤로 FORTRAN, COBOL, PL/I 컴파일러가 나왔죠.) 작업한 카드 덱을 제출하기 위해 각 작업 식별자와 교환하여, IT 부서 운영자에게 건네 주면 인쇄된 결과와 카드 덱을 받으러 몇 시간 후에 다시 와야 했습니다. 결과물을 공부하고, 앞의 작업을 다시 하고 몇 시간 후에 오던 것을 반복하곤 했는데, 나중에 우리 작업의 실행 시간은 불과 몇 초 밖에 걸리지 않았다는 것을 알고 충격을 받았습니다. 학교 IT 부서에서 수행할 작업이 네 번째 우선 순위에 배정되었다면, 학생들이 준 것은 여덟번째로 매우 낮은 것이었습니다. 과거 우선 순위 선정 매커니즘의 목표는 중요한 업무에 우선해서 값비싼 하드웨어를 전부 사용하는 것이었습니다. 학교에서 학생들의 생산성은 자원을 효율적으로 사용하는 데 있어 후순위였던 것이죠.
현대적인 배치(Batch) 컴퓨팅
오늘날 배치(Batch) 컴퓨팅은 매우 중요합니다! 영화 스튜디오, 과학자, 연구원, 수치 분석가 및 기타 사람들이 쉽게 대용량 컴퓨팅 성능에 접근할 수 있게 되어, 컴퓨팅 사이클에 대해 활용하고자 하는 열의를 갖게 되었습니다. 많은 기업 조직에서는 오픈 소스 또는 상용 작업 스케줄러로 사내 컴퓨팅 클러스터를 직접 구축하여, 이러한 요구 사항을 충족시키기 위해 노력해 왔습니다. 그런데, 여전히 과거와 같이 우선 순위를 적용할 수 밖에 없는 충분한 양의 컴퓨팅 용량은 아닌 것 같습니다. 이들 기존 사내 클러스터는 구축 및 유지 보수에 비용이 많이 들고, 동일한 서버에 동일한 사양의 대형 프로세서로 구성되는 경우가 많습니다.
우리는 클라우드 컴퓨팅을 통해 다양한 타입의 EC2 인스턴스를 신속히 제공할 수 있고, 변화하는 요구 사항에 따라 확장 및 축소 할 수 있는 확장성과 사용한 만큼 지불하거나 경매를 통한 가격 책정 모델을 통해 배치 컴퓨팅 모델을 보다 효과적으로 변경할 수 있다고 생각했습니다. 과거에는 AWS 고객 역시 EC2 인스턴스, 콘테이너, 알림, CloudWatch 모니터링 등을 사용하여 자체 배치 처리 시스템을 구축했습니다. 이런 것들이 매우 일반적인 AWS 사용 사례 였기 때문에 이를 위한 관리형 서비스가 필요하다는 결론을 얻었습니다.
AWS Batch 서비스 출시
배치 컴퓨팅에 대한 전체 관리형 서비스인 AWS Batch를 오늘 출시합니다. 이를 통해 배치 관리자, 개발자 및 사용자들은 배치용 클러스터를 따로 구축, 관리 및 모니터링 할 필요 없이 대용량 클라우드 컴퓨팅 자원을 활용할 수 있게 되었습니다. 소프트웨어 구매나 설치도 필요도 업습니다.
AWS Batch에서는 관리 상 불필요한 부담을 덜면서 동적으로 확장되는 EC2 인스턴스 세트에 여러분의 콘테이너 이미지와 애플리케이션을 통해 배치 작업을 할 수 있습니다. 클라우드를 통한 효율적이고 사용하기 쉬운 서비스로서 Amazon EC2 및 EC2 스팟 인스턴스가 제공하는 탄력성을 통한 대용량 병렬 작업을 할 수 있게 되었고, Amazon S3, DynamoDB 및 SNS 같은 기존 서비스와도 안전하고 쉽게 연동할 수 있습니다.
우선 AWS Batch에서 사용되는 몇 가지 중요한 용어와 개념을 살펴 보겠습니다. (배치 작업을 많이 하시는 경우 이미 익숙하실 수 있습니다.)
- 작업(Job) – AWS Batch에 제공되는 하나의 작업 단위 (쉘 스크립트, 리눅스 실행 파일 또는 콘테이너 이미지)입니다. 작업 정의(Job Definition)에 의해 정의한 파라미터 값을 통해 EC2에서 콘테이너화 되어 실행 합니다. Job에서 다른 작업을 ID로 참조할 수 있습니다. AWS Batch에서는 각 작업을 독립적으로 실행하고, (파라메트릭 스윕 및 몬테카를로 시뮬레이션에 적합한) 어레이 작업(Array Jobs) 역시 지원합니다. 어레이 작업은 병렬적으로 작업이 되고, 동시에 가용 컴퓨팅 자원을 관리하면서 실행합니다.
- 작업 정의(Job Definition) – 작업을 어떻게 실행할지 정합니다. AWS Identity and Access Management (IAM) 역할을 포함한 AWS 자원 접근 제어, CPU와 메모리와 요구 사항 등의 값을 설정합니다. 이러한 정보를 통해 개별 콘테이너 설정 값, 환경 변수, 마운트 지점 등을 정하게 됩니다. 개별 작업을 시작 될 때, 이들 값들이 재정의 됩니다.
- 작업 큐(Job Queue) – 컴퓨팅 환경이 예약 될 때까지 작업이 있는 곳으로, 우선 순위 값은 각 대기열와 연결됩니다.
- 스케줄러(Scheduler) –작업 큐와 함께 작업을 언제 어디서 어떻게 실행할지 결정합니다. AWS Batch 스케줄러는 FIFO(First-in, first-out) 기반이며 작업 사이의 의존성을 인지합니다. 우선 순위를 지정하고, 같은 컴퓨팅 환경 내에서 높은 우선 순위의 큐에 있는 작업부터 낮은 순서로 실행하게 됩니다. 스케줄러는 작업을 위한 적정한 크기의 컴퓨팅 환경을 설정하기도 합니다.
- 컴퓨팅 환경(Compute Environment) – 작업을 실행하기 위한 관리 혹은 비관리 컴퓨팅 자원으로서, 관리 환경에서는 세부적인 수준에서 인스턴스 타입을 정의할 수 있습니다. c4.2xlarge나m4.10xlarge 같은 특정한 인스턴스 타입을 지정하거나, 여러분이 원하는 신규 인스턴스 타입을 간단히 지정해도 됩니다. 또한, Spot Market의 경매에 따른 백분율 값에 따라 최소, 희망 혹은 최대 vCPU 숫자를 지정하거나, VPC 서브넷을 지정할 수 있습니다. 이러한 지정 파라미터와 제약 사항을 기반으로 AWS Batch가 원하는 EC2 인스턴스를 효과적으로 켜고 관리하고 종료하게 됩니다. 또한, 직접 컴퓨팅 환경을 구성할 수도 있는데, 이 때 AWS Batch가 사용할 Amazon ECS 클러스터를 직접 설정하고 확장성을 관리하셔야 합니다.
AWS Batch 살펴 보기
AWS 관리 콘솔에서 AWS Batch를 사용할 수 있으며, , AWS Command Line Interface (CLI)나 AWS Batch API를 사용할 수 있습니다.
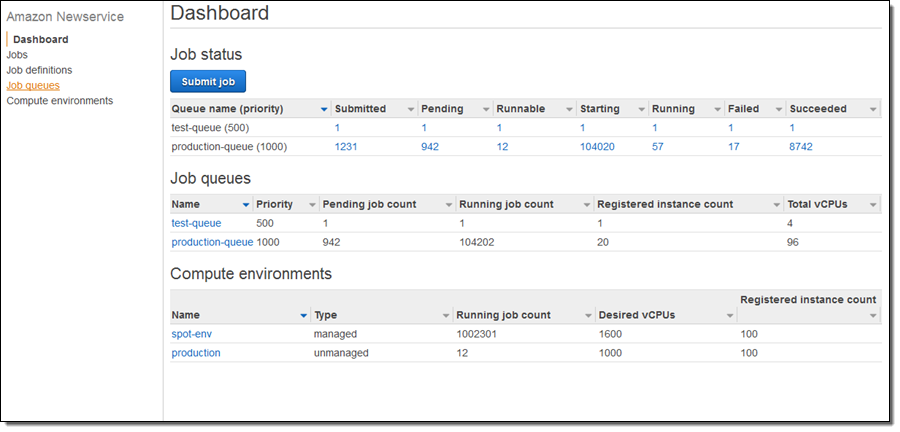
잠깐 살펴보면 상태 대시보드에 작업, 작업 큐 및 컴퓨팅 환경을 보실 수 있습니다.
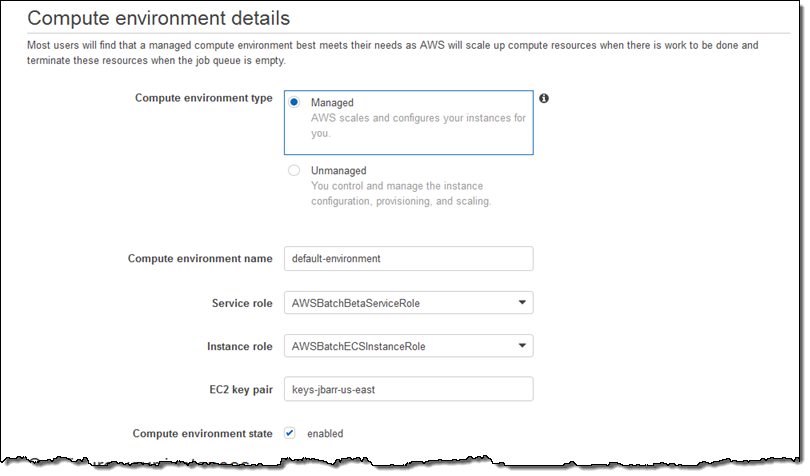
Compute environments을 선택하고 Create environment를 통해 작업을 시작할 수 있습니다. 우선 관리형 환경(Managed environment)으로 작업 이름과 IAM 역할(자동으로 생성)을 선택합니다.
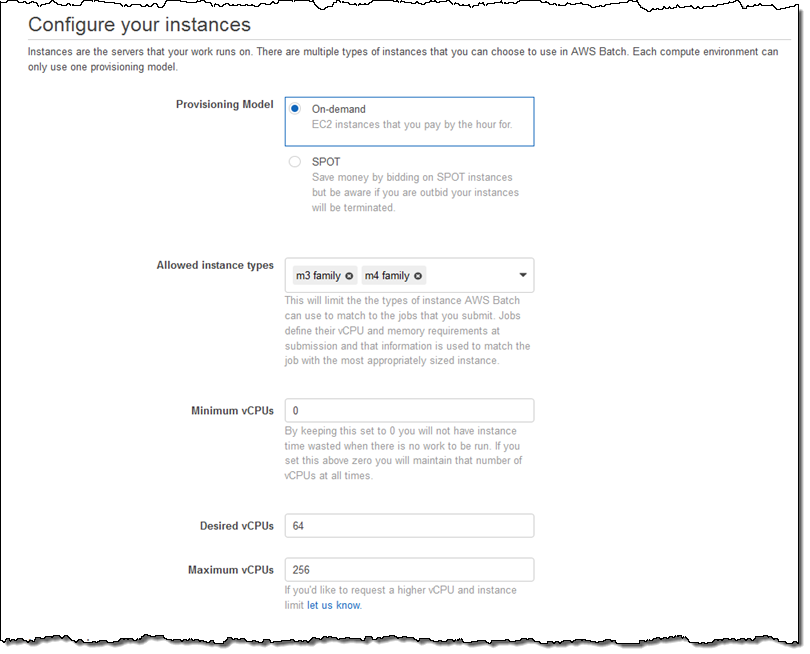
그리고 프로비저닝 모델(온디멘드 혹은 스팟)을 설정하고, 원하는 인스턴스 타입(또는 특정 타입) 및 컴퓨팅 환경(vCPU로 측정되는) 크기를 설정합니다.
컴퓨팅 자원과 보안 그룹 등에 필요한 VPC 서브넷를 선택함으로서 설정을 완료합니다.
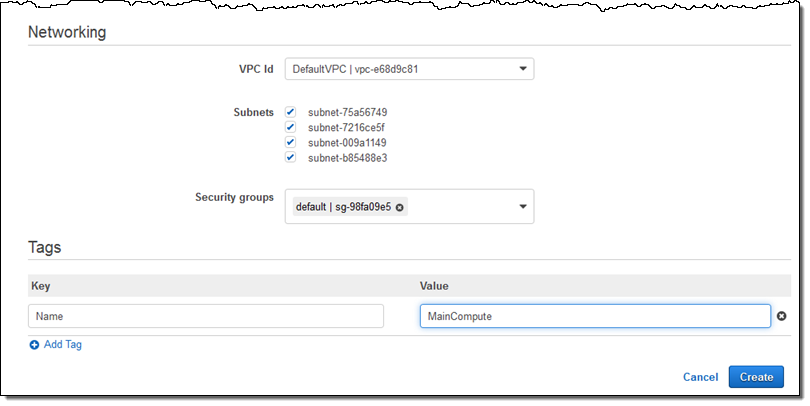
이제 Create를 누르면, 배치 작업을 위한 컴퓨팅 환경이 (MainCompute) 몇 초내에 생성됩니다.
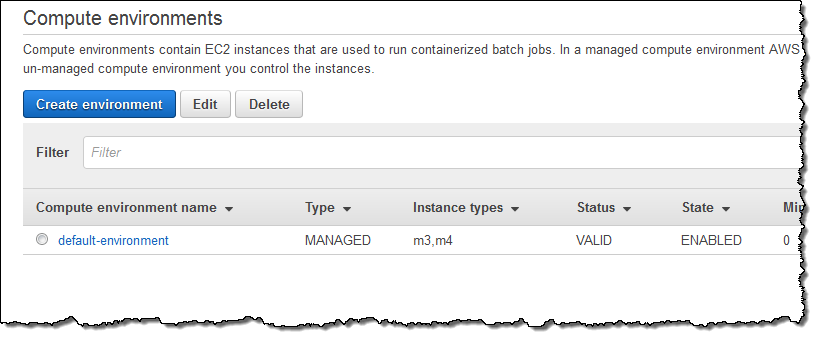
다음으로, 컴퓨팅 환경에 보낼 작업 큐가 필요합니다. Queues를 선택한 후 Create Queue를 클릭해서 설정을 진행합니다. 모든 값을 기본값으로 선택 한 뒤, 작업 큐를 내 컴퓨팅 환경에 연결하고 Create queue를 누릅니다.
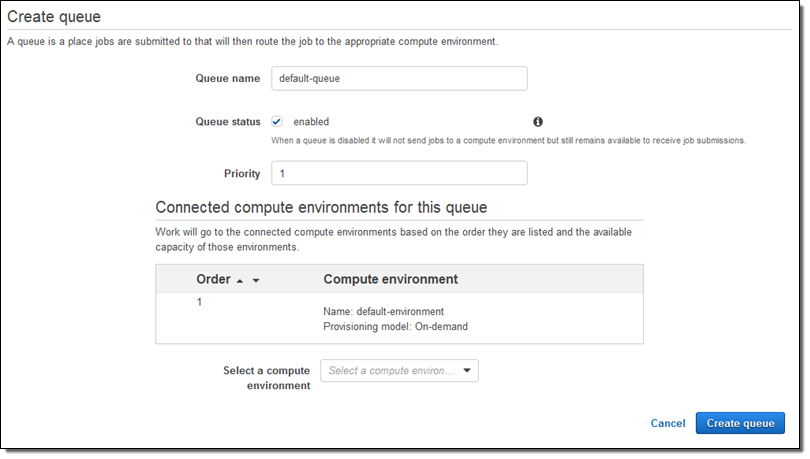
이 역시 몇 초안에 진행 됩니다.
이제 작업 정의를 할 차례입니다. Job definitions를 선택하고, Create를 눌러 작업에 대해 정의합니다. (아래는 아주 간단한 작업으로 아마 여러분은 더 잘하실 수 있을 겁니다.) 제가 만든 작업은 sleep 명령어로 128MB 메모리와 1 vCPU에서 진행됩니다.
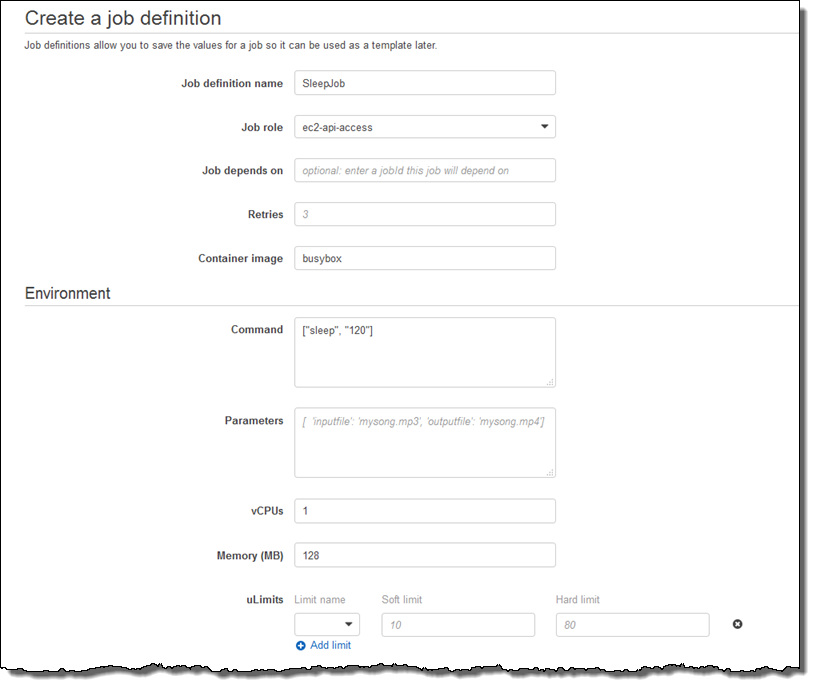
환경 변수를 전달하고 접근 권한을 비활성화한 뒤, 프로세스 사용자 이름을 지정하고 콘테이너 내에서 파일 시스템을 사용할 수 있도록 할 수 있습니다.
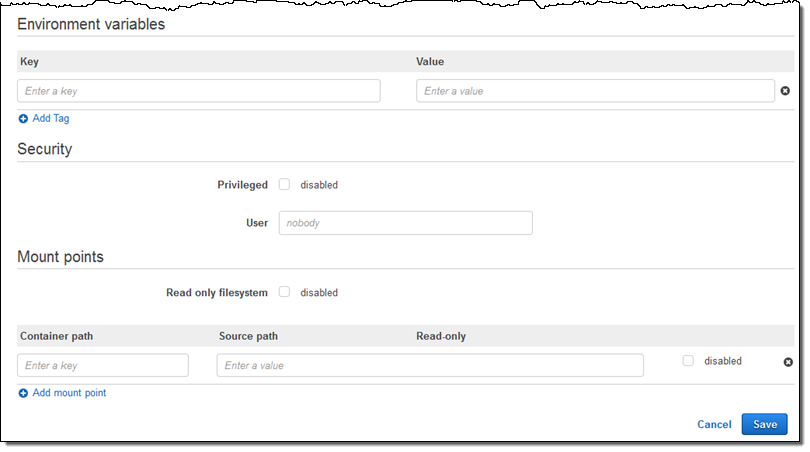
Save를 눌러 작업 정의를 완료합니다.
이제 작업을 돌려볼 차례입니다. Jobs을 선택한 후 Submit job를 누릅니다.
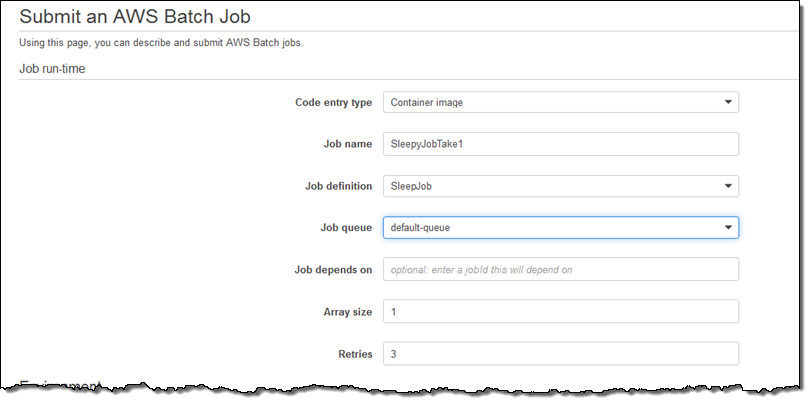
다양한 측면의 작업의 재정의, 부가적인 태그 추가 등의 기능을 활용할 수 있으며, 이제 Submit을 누릅니다.
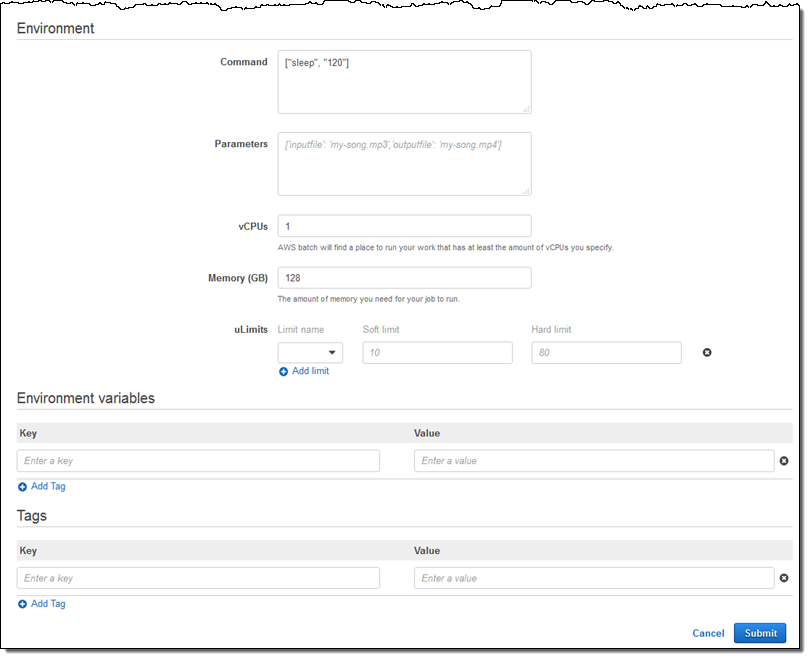
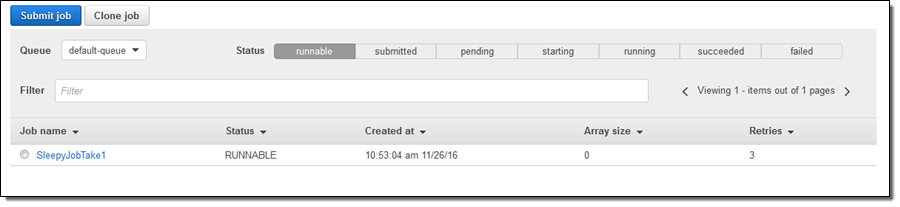
그 뒤에 결과가 나옵니다.
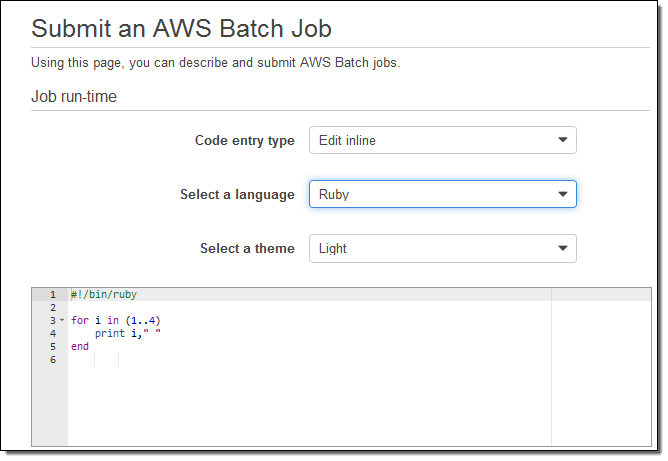
Ruby, Python, Node, 또는 Bash 스크립트를 통해서도 작업을 정의할 수 있습니다. 예를 들어, 아래는 루비 코드로 만든 작업입니다.
콘솔에서 작업한 것과 같이 커맨드 라인에서도 create-compute-environment, describe-compute-environments, create-job-queue, describe-job-queues, register-job-definition, submit-job, list-jobs, describe-jobs 명령어로 같은 작업을 수행할 수 있습니다.
AWS Batch API를 사용하여 좀 더 흥미로운 방식으로 배치 작업을 할 수 있습니다. 예를 들어, 새로운 개체(예를 들어, 엑스레이 사진, 지진파 데이터 영상, 3D 이미지 정보)가 Amazon S3 버킷에 업로드 되었을 때 AWS Lambda 함수를 통해 개체를 조사하고, 이를 분석하여 메타 데이터를 뽑아 내거나 하는 작업을 수행할 수 있을 것입니다. SubmitJob 함수는 그렇게 얻어진 데이터를 Amazon DynamoDB에 저장하고 Amazon Simple Notification Service (SNS)로 알림을 보낼 수도 있을 것입니다.
정식 출시 및 가격
AWS Batch는 오늘 부터 US East (Northern Virginia) 리전에서 사용 가능하며, 곧 지원 리전을 계속 확대할 예정입니다. 추가적인 리전 확대와 아울러 AWS Lambda 함수 기반 작업 등 다양한 추가 기능도 선보일 예정입니다.
AWS Batch에는 추가 비용은 없으며, 여러분이 사용하는 AWS 컴퓨팅 리소스 비용만 지불하시면 됩니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Batch – Run Batch Computing Jobs on AWS의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.