Amazon Web Services 한국 블로그
Amazon Aurora, DB 질의를 통한 기계 학습 결과 통합 기능 출시
인공 지능 및 기계 학습을 통해 우리는 데이터에서 더 나은 통찰력을 얻을 수 있습니다. 하지만, 구조화된 데이터의 대부분이 저장되는 위치는 어디일까요? 바로 데이터베이스입니다. 오늘날 관계형 데이터베이스의 데이터에 기계 학습을 사용하려면 데이터베이스에서 데이터를 읽은 후 기계 학습 모델을 적용하는 사용자 지정 애플리케이션을 개발해야 합니다. 이러한 애플리케이션을 개발하기 위해서는 데이터베이스와의 상호 작용 및 기계 학습 사용을 위해 다양한 기술이 필요합니다. 이는 새로운 애플리케이션이므로 애플리케이션의 성능, 가용성 및 보안을 관리해야 합니다.
관계형 데이터베이스의 데이터에 기계 학습을 적용하는 작업을 더 용이하게 만들 수 있을까요? 기존 애플리케이션의 경우에도 말입니다.
오늘부터 Amazon Aurora는 다음 두 개의 AWS 기계 학습 서비스와 기본적으로 통합됩니다.
- Amazon SageMaker는 사용자 지정 기계 학습 모델을 신속하게 구축, 학습 및 배포할 수 있는 기능을 제공하는 서비스입니다.
- Amazon Comprehend는 기계 학습을 사용하여 텍스트에서 통찰력을 찾는 자연어 처리(NLP) 서비스입니다.
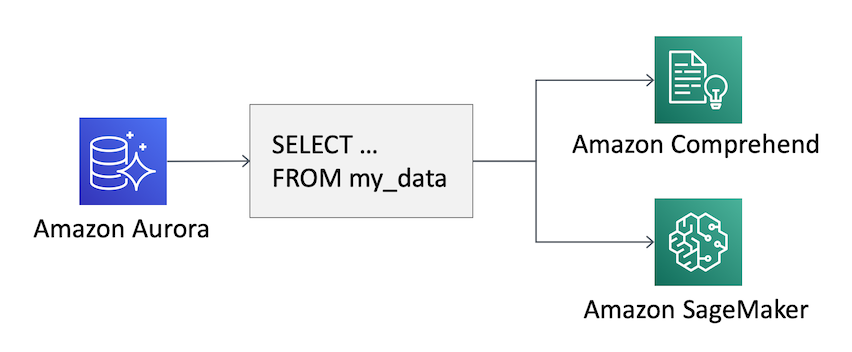
이 새로운 기능을 사용하면 쿼리에 SQL 함수를 사용하여 관계형 데이터베이스의 데이터에 기계 학습 모델을 적용할 수 있습니다. 예를 들어 Comprehend를 사용하여 사용자 댓글의 감정을 감지하거나 SageMaker로 구축된 사용자 지정 기계 학습 모델을 적용하여 고객의 “churn(이탈)” 위험을 예측할 수 있습니다. 이탈은 “change(변심)”와 “turn(돌아서기)”을 조합한 단어로, 서비스 사용을 중지하는 고객을 설명하는 데 사용됩니다.
기계 학습 서비스의 추가 정보를 포함하여 대용량 쿼리의 출력을 새 테이블에 저장할 수 있습니다. 또는 기계 학습 경험이 없어도 클라이언트가 실행한 SQL 코드를 변경하여 애플리케이션에서 이 기능을 대화형으로 사용할 수 있습니다.
Aurora 데이터베이스에서 수행할 수 있는 작업의 몇 가지 예를 살펴보겠습니다. 먼저 Comprehend를 사용한 다음, SageMaker를 사용하겠습니다.
데이터베이스 권한 구성
첫 번째 단계는 사용할 서비스, 즉 Comprehend, SageMaker 또는 둘 다에 액세스할 수 있는 권한을 데이터베이스에 제공하는 것입니다. RDS 콘솔에서 새 Aurora MySQL 5.7 데이터베이스를 만듭니다. 이 데이터베이스가 사용 가능한 상태가 되면 리전별 엔드포인트의 연결 및 보안 탭에서 IAM 역할 관리 섹션을 찾습니다.
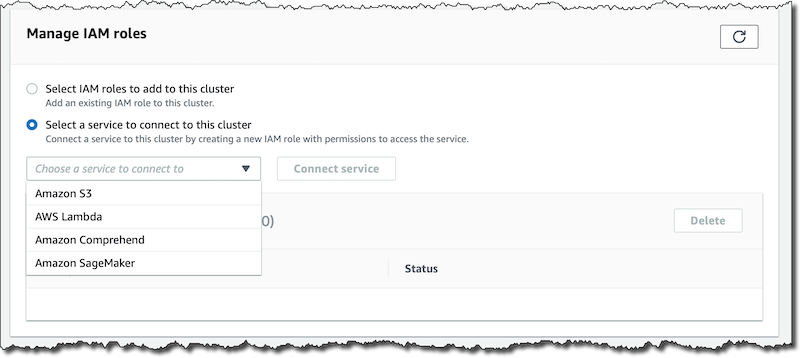
그런 다음, Comprehend와 SageMaker를 이 데이터베이스 클러스터에 연결합니다. SageMaker의 경우, 배포한 기계 학습 모델의 엔드포인트 Amazon 리소스 이름(ARN)을 제공해야 합니다. 엔드포인트를 여러 개 사용하려는 경우 이 단계를 반복해야 합니다. 새로운 기계 학습 통합 작동을 위해 Aurora 데이터베이스가 해당 서비스에 액세스할 수 있도록 서비스 역할을 생성하는 작업은 콘솔이 수행합니다.

Amazon Aurora에서 Comprehend 사용
MySQL 클라이언트를 사용하여 데이터베이스에 연결합니다. 테스트를 실행하기 위해, 블로깅 플랫폼의 댓글이 저장되는 테이블을 생성하고 샘플 레코드 몇 개를 삽입하겠습니다.
CREATE TABLE IF NOT EXISTS comments (
comment_id INT AUTO_INCREMENT PRIMARY KEY,
comment_text VARCHAR(255) NOT NULL
);
INSERT INTO comments (comment_text)
VALUES ("This is very useful, thank you for writing it!");
INSERT INTO comments (comment_text)
VALUES ("Awesome, I was waiting for this feature.");
INSERT INTO comments (comment_text)
VALUES ("An interesting write up, please add more details.");
INSERT INTO comments (comment_text)
VALUES ("I don’t like how this was implemented.");제 테이블에 있는 댓글의 감정을 감지하기 위해 aws_comprehend_detect_sentiment 및 aws_comprehend_detect_sentiment_confidence SQL 함수를 사용하겠습니다.
SELECT comment_text,
aws_comprehend_detect_sentiment(comment_text, 'en') AS sentiment,
aws_comprehend_detect_sentiment_confidence(comment_text, 'en') AS confidence
FROM comments;
aws_comprehend_detect_sentiment 함수는 입력 텍스트에 대해 가장 가능성 있는 감정인 POSITIVE, NEGATIVE 또는 NEUTRAL을 반환합니다. aws_comprehend_detect_sentiment_confidence 함수는 감정 감지의 신뢰도를 반환하며, 이때 신뢰도는 0(전혀 신뢰하지 않음)에서 1(완전히 신뢰함) 사이입니다.
Amazon Aurora에서 SageMaker 엔드포인트 사용
Comprehend로 수행한 작업과 마찬가지로, SageMaker 엔드포인트에 액세스하여 제 데이터베이스에 저장되는 정보를 보강할 수 있습니다. 실용적인 사용 사례를 보여주기 위해 이 게시물의 시작 부분에서 언급한 고객 이탈의 예를 구현해보겠습니다.
휴대전화 사업자들은 어떤 고객이 결국 이탈하고 어떤 고객이 서비스를 계속 사용하는지에 대한 기록을 가지고 있습니다. 이 기록 정보를 사용하여 기계 학습 모델을 구성할 수 있습니다. 모델에 대한 입력으로 고객의 현재 구독 플랜, 하루 중 시간대별 통화량, 고객 서비스 센터에 전화를 건 빈도를 사용하겠습니다.
다음은 제 고객 테이블의 구조입니다.
SHOW COLUMNS FROM customers;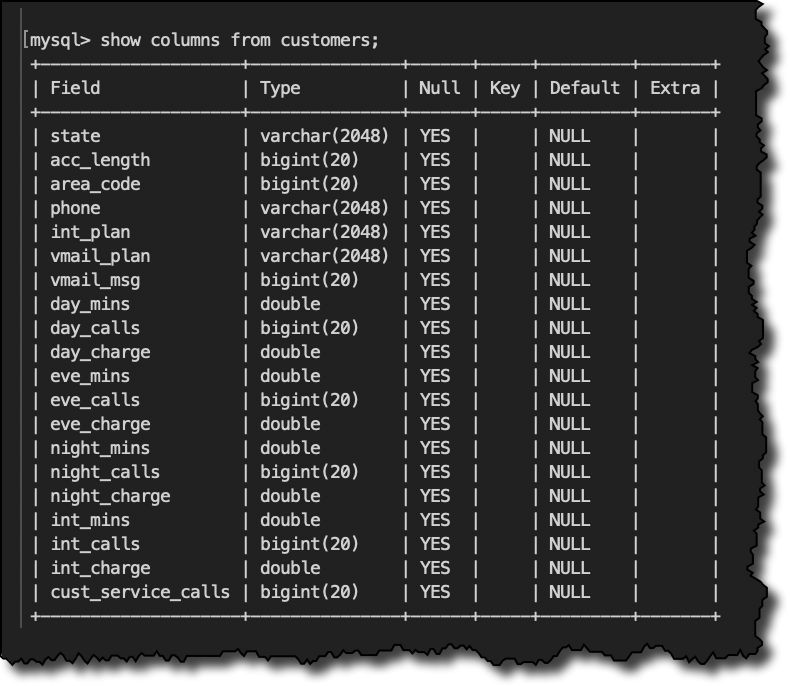
이탈 위험이 있는 고객을 식별할 수 있도록 XGBoost 알고리즘을 사용하는 이 샘플 SageMaker 노트북에 따라 모델을 학습시킵니다. 모델이 생성되면 호스팅된 엔드포인트에 배포됩니다.
SageMaker 엔드포인트가 서비스 중일 때 콘솔의 IAM 역할 관리 섹션으로 돌아가 Aurora 데이터베이스에 엔드포인트 ARN에 액세스할 수 있는 권한을 제공하겠습니다.
이제 엔드포인트에 입력(모델에 필요한 매개 변수)을 제공하는 새로운 will_churn SQL 함수를 생성하겠습니다.
CREATE FUNCTION will_churn (
state varchar(2048), acc_length bigint(20),
area_code bigint(20), int_plan varchar(2048),
vmail_plan varchar(2048), vmail_msg bigint(20),
day_mins double, day_calls bigint(20),
eve_mins double, eve_calls bigint(20),
night_mins double, night_calls bigint(20),
int_mins double, int_calls bigint(20),
cust_service_calls bigint(20))
RETURNS varchar(2048) CHARSET latin1
alias aws_sagemaker_invoke_endpoint
endpoint name 'estimate_customer_churn_endpoint_version_123';모델이 고객의 휴대전화 구독 세부 정보 및 서비스 사용 패턴을 보고 이탈 위험을 식별합니다. will_churn SQL 함수를 사용하여 제 customers 테이블에 대해 쿼리를 실행해 기계 학습 모델을 기반으로 고객에게 플래그를 지정하겠습니다. 쿼리 결과를 저장하기 위해 새로운 customers_churn 테이블을 생성하겠습니다.
CREATE TABLE customers_churn AS
SELECT *, will_churn(state, acc_length, area_code, int_plan,
vmail_plan, vmail_msg, day_mins, day_calls,
eve_mins, eve_calls, night_mins, night_calls,
int_mins, int_calls, cust_service_calls) will_churn
FROM customers;customers_churn 테이블의 레코드 몇 개를 살펴보겠습니다.
SELECT * FROM customers_churn LIMIT 7;
운 좋게도 처음 7명의 고객은 분명히 이탈하지 않을 것 같습니다. 하지만 전체적으로는 어떨까요? will_churn 함수의 결과를 저장했으므로 customers_churn 테이블에 대해 SELECT GROUP BY 문을 실행할 수 있습니다.
SELECT will_churn, COUNT(*) FROM customers_churn GROUP BY will_churn;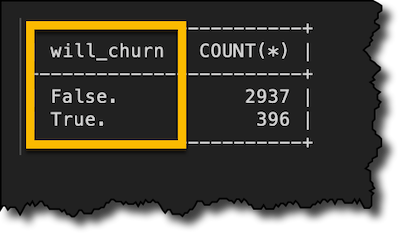
이제 쿼리 실행 결과를 자세히 살펴보고 무엇이 고객의 이탈을 야기하는지 이해할 수 있습니다.
새 엔드포인트 ARN을 사용하여 기계 학습 모델의 새 버전을 생성한 경우 SQL 문을 변경하지 않고 will_churn 함수를 다시 생성할 수 있습니다.
지금 이용 가능
현재 Aurora MySQL 5.7에서 새로운 기계 학습 통합을 사용할 수 있으며, SageMaker 통합은 정식 버전으로 제공되고 Comprehend 통합은 미리 보기로 제공됩니다. 자세한 내용은 설명서를 참조하십시오. AWS는 다른 엔진 및 버전을 준비 중입니다. Aurora MySQL 5.6과 Aurora PostgreSQL 10 및 11이 곧 출시될 예정입니다.
Aurora 기계 학습 통합은 기본 서비스가 제공되는 모든 리전에서 사용할 수 있습니다. 예를 들어 Aurora MySQL 5.7과 SageMaker를 둘 다 사용할 수 있는 리전에서는 SageMaker 통합을 사용할 수 있습니다. 서비스가 제공되는 리전의 전체 목록은 AWS 리전 표를 참조하십시오.
통합을 사용하는 데 대한 추가 비용은 없으며, 기본 서비스를 정상 요금으로 지불하기만 하면 됩니다. Comprehend를 사용할 때는 쿼리 크기에 주의하시기 바랍니다. 예를 들어 특별히 긍정적이거나 부정적인 댓글을 단 고객에게 연락하기 위해 고객 서비스 웹 페이지에서 사용자 피드백에 대한 감정 분석을 수행하며 사람들이 하루에 다는 댓글의 수가 10,000개일 경우, 하루에 3 USD를 지불하게 됩니다. 비용을 최적화하려면 결과를 저장해야 한다는 점을 기억하시기 바랍니다.
이제 어느 때보다 쉽게 관계형 데이터베이스에 저장된 데이터에 기계 학습 모델을 적용할 수 있습니다. 앞으로 이 기능을 통해 무엇을 구축할지에 대한 계획을 공유해주세요!
— Danilo