Amazon Web Services 한국 블로그
Amazon Comprehend IDP – PDF, 워드 문서 및 이미지를 처리 기능 출시
오늘 지능형 문서 처리(IDP)를 위한 새로운 Amazon Comprehend 기능을 발표합니다. 이 기능을 사용하면 텍스트를 먼저 추출하지 않고도 Amazon Comprehend에서 직접 PDF 문서, Microsoft Word 파일 및 이미지에서 엔터티를 분류하고 추출할 수 있습니다.
많은 고객은 스캔한 영수증 이미지나 PDF 형식의 세금 내역서와 같이 반구조화된 형식의 문서를 처리해야 합니다. 오늘날까지 이러한 고객은 우선 광학 문자 인식(OCR) 도구를 사용하여 해당 문서를 사전 처리하고 텍스트를 추출해야 했습니다. 그런 다음 Amazon Comprehend를 사용하여 사전 처리된 파일에서 항목을 분류하고 추출할 수 있었습니다.
이제 IDP용 Amazon Comprehend를 통해 고객은 단일 API 호출로 일반 텍스트 문서뿐만 아니라 PDF, docx, PNG, JPG 또는 TIFF 이미지와 같은 반구조화된 문서를 처리할 수 있습니다. 이 새로운 기능은 OCR과 Amazon Comprehend의 기존 자연어 처리(NLP) 기능을 결합하여 문서에서 항목을 분류하고 추출합니다. 사용자 지정 문서 분류 API를 사용하면 문서를 범주 또는 클래스로 구성할 수 있으며, 사용자 지정 개체 인식 API를 사용하면 제품 코드나 비즈니스 관련 항목과 같은 문서에서 항목을 추출할 수 있습니다. 예를 들어, 보험 회사는 이제 더 적은 수의 API 호출로 스캔한 고객의 청구 사항을 처리할 수 있습니다. Amazon Comprehend 엔터티 인식 API를 사용하면 청구 사항에서 고객 번호를 추출하고 사용자 지정 분류기 API를 사용하여 주택, 자동차 또는 개인 보험 등 다양한 보험 카테고리로 청구 사항을 정렬할 수 있습니다.
오늘부터 IDP용 Amazon Comprehend API를 사용하여 파일을 실시간으로 추론하고 일련의 대규모 문서에 대한 비동기 배치 처리를 수행할 수 있습니다. 이 기능은 문서 처리 파이프라인을 간소화하고 개발에 들어가는 노력을 덜어줍니다.
시작하기
AWS Management Console, AWS SDK 또는 AWS Command Line Interface(AWS CLI)에서 IDP용 Amazon Comprehend를 사용할 수 있습니다.
이 데모에서는 사용자 지정 분류자를 사용하여 반구조화된 파일을 비동기적으로 처리하는 방법을 살펴봅니다. 엔터티 추출의 경우 단계가 다르며 설명서를 확인하여 수행 방법을 배울 수 있습니다.
분류기로 파일을 처리하려면 먼저 사용자 지정 분류기를 학습시켜야 합니다. Amazon Comprehend 개발자 안내서의 단계를 따를 수 있습니다. 일반 텍스트 데이터로 이 분류기를 훈련시켜야 합니다.
사용자 지정 분류기를 훈련시킨 후 비동기 또는 동기 작업을 사용하여 문서를 분류할 수 있습니다. 동기 작업을 사용하여 단일 문서를 분석하려면 사용자 지정 모델을 사용하여 실시간 분석을 실행할 엔드포인트를 만들어야 합니다. 설명서에서 실시간 분석에 대한 자세한 정보를 찾을 수 있습니다. 이 데모에서는 비동기 작업을 사용하여 분류할 문서를 Amazon Simple Storage Service(S3) 버킷에 배치하고 분석 배치 작업을 실행합니다.
콘솔에서 문서 일괄 분류를 시작하려면 Amazon Comprehend 페이지에서 분석 작업으로 이동한 다음 작업 생성으로 이동하세요.
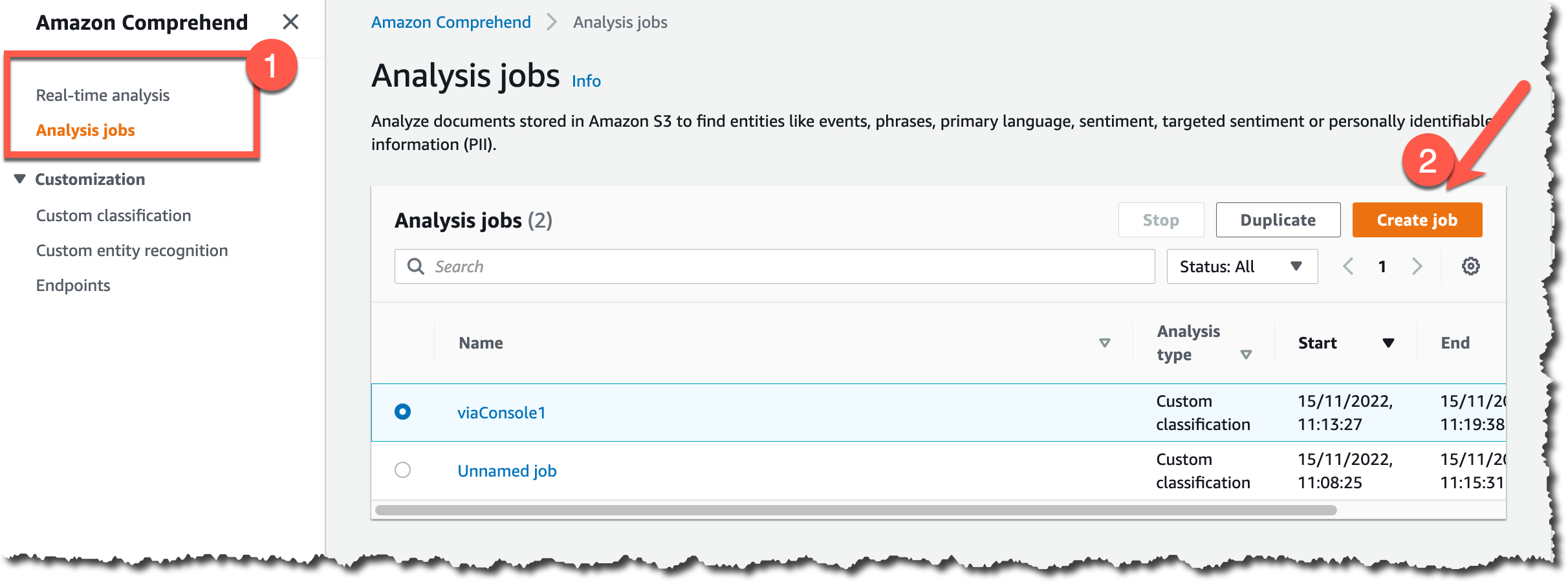
그런 다음 새 분석 작업을 구성할 수 있습니다. 먼저 이름을 입력하고 사용자 지정 분류 및 이전에 만든 사용자 지정 분류기를 선택합니다.
그런 다음 입력 데이터를 구성할 수 있습니다. 먼저 해당 데이터의 S3 위치를 선택합니다. 해당 위치에 PDF, 이미지 및 Word 문서를 배치할 수 있습니다. 반구조화된 문서를 처리하기 때문에 파일당 하나의 문서를 선택해야 합니다. 문서 추출 및 구문 분석에 대한 Amazon Comprehend 설정을 재정의하려는 경우 고급 문서 입력 옵션을 구성할 수 있습니다.
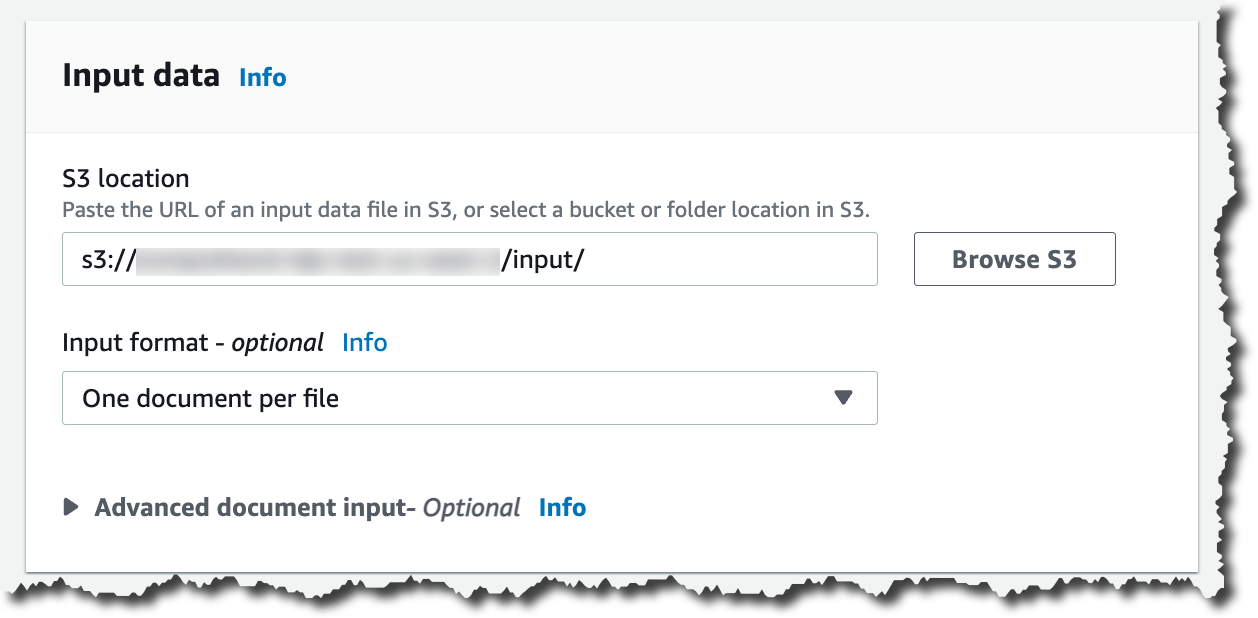
입력 데이터를 구성한 후 이 분석 결과를 저장할 위치를 선택할 수 있습니다. 또한 지정된 Amazon S3 위치에서 읽고 쓸 수 있는 액세스 권한을 이 분석 작업에 부여해야 작업을 생성할 수 있습니다.
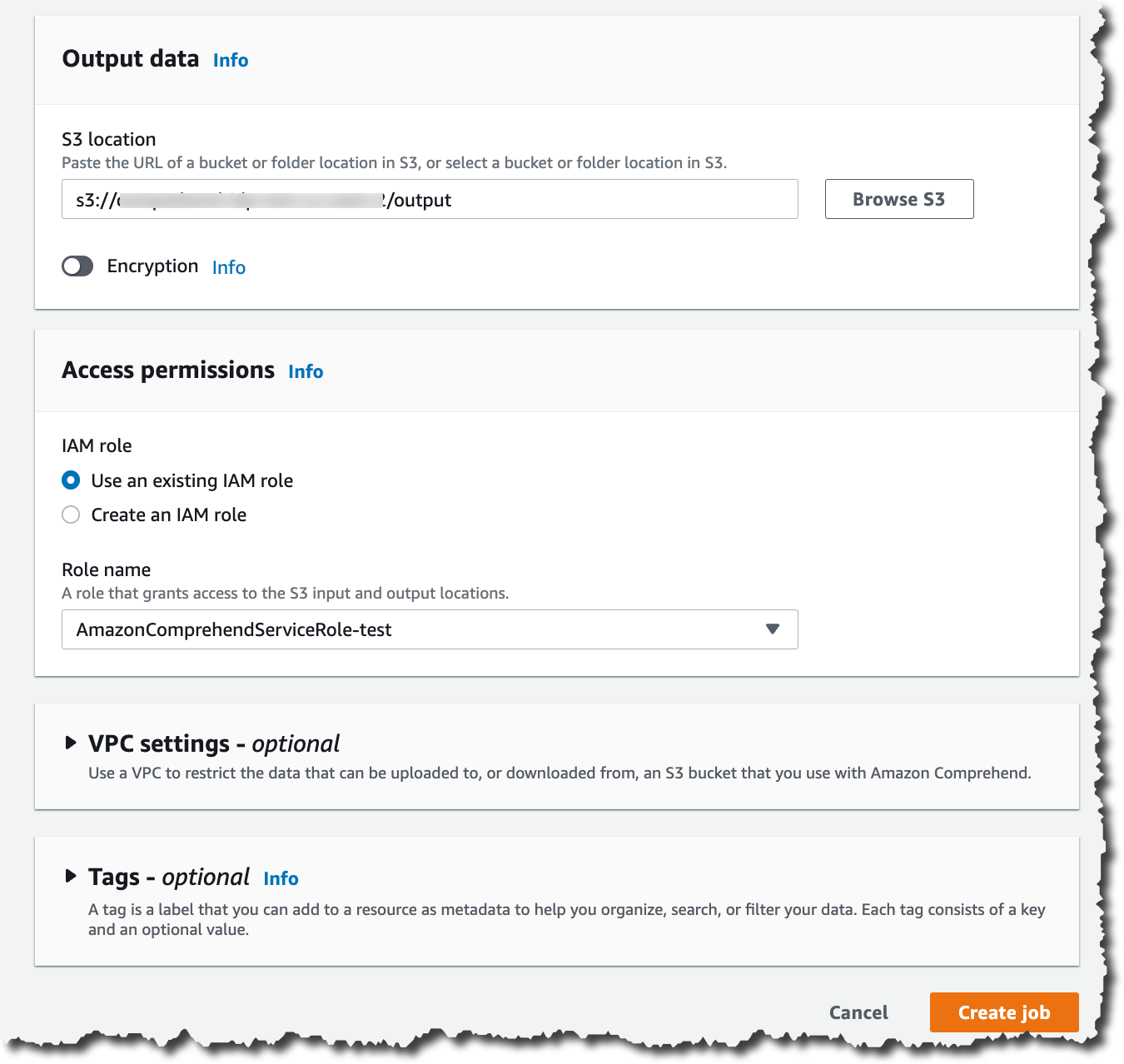
입력 크기에 따라 작업을 실행하는 데 몇 분 정도 걸립니다. 작업이 준비되면 출력 결과를 확인할 수 있습니다. 작업을 생성할 때 지정한 Amazon S3 위치에서 결과를 찾을 수 있습니다.
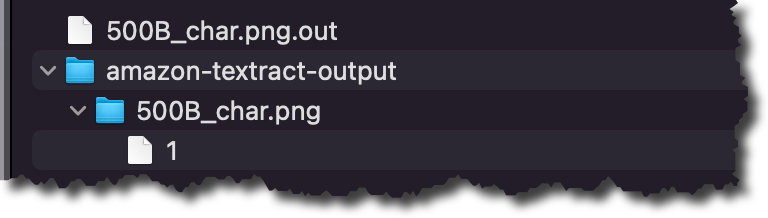
결과 폴더에는 Amazon Comprehend가 분류한 각 반정형 파일에 대한 .out 파일이 있습니다. .out 파일은 JSON으로, 각 줄은 문서의 페이지를 나타냅니다. amazon-textract-output 디렉터리에는 분류된 각 파일의 폴더가 있으며, 해당 폴더 안에는 원본 파일의 페이지당 파일이 하나씩 있습니다. 이러한 페이지 파일에는 분류 결과가 들어 있습니다. 분류 결과에 대해 자세히 알아보려면 설명서 페이지를 확인하세요.
정식 출시
Amazon Comprehend를 사용할 수 있는 모든 리전의 Amazon Comprehend에서 지금 바로 PDF, 이미지 및 워드 문서와 같은 반정형 파일의 엔터티를 비동기식 및 동기식으로 분류하고 추출할 수 있습니다. Amazon Comprehend 개발자 안내서에서 새로운 출시 내용에 대해 자세히 알아보세요.
— Marcia