AWS 기술 블로그

롯데쇼핑의 Amazon Bedrock 기반 AI운영 어시스턴트 구축 사례
본 글은 지난 2월 AWS 기술블로그(https://aws.amazon.com/ko/blogs/tech/generative-ai-incident-response-knowledge-base/)의 아키텍처를 기반으로 롯데쇼핑의 운영 환경에 맞춰 고도화한 프로젝트 사례를 소개합니다. 도입배경 롯데쇼핑은 롯데온을 중심으로 다양한 온라인 쇼핑 플랫폼을 운영하며, 3,900만 명의 롯데멤버스 회원 기반과 연간 8조원 이상의 거래액을 기록하는 국내 대표 이커머스 기업입니다. 특히 블랙프라이데이나 뷰세라(뷰티 세일 라인업) 같은 대규모 프로모션 기간에는 평소 대비 수배에 달하는 트래픽이 집중되며, 이를 […]

AWS Fault Injection Service와Amazon ARC Region Switch로 복원력 향상하기
“이 게시글은 AWS Cloud Operations Blog의 ‘Improve the resiliency with AWS Fault Injection service and Amazon ARC Region switch by Rajakumar Sampathkumar‘를 번역 및 편집하였습니다” 분산 클라우드 환경에서는 시스템 장애가 자주 발생하기 때문에 애플리케이션 복원력이 고객에게 매우 중요합니다. 기존의 재해 복구 테스트 방식은 대부분 수동적이고 시간이 많이 소요되지만, 현대적인 카오스 엔지니어링 방식은 애플리케이션이 자동으로 장애를 […]

AWS Managed Microsoft AD(하이브리드 에디션)으로 Active Directory 도메인을 AWS로 확장하기
AWS는 2025년 8월 1일 Microsoft Active Directory용 AWS Directory Service(AWS Managed Microsoft AD)의 하이브리드 에디션 정식 출시를 발표하였습니다. 이 새로운 에디션을 통해 기존의 자체 관리형 Active Directory(AD) 도메인을 현재 ID 및 액세스 인프라로 유지하면서 AWS Managed Microsoft AD로 확장할 수 있습니다. AWS Managed Microsoft AD(하이브리드 에디션)는 Active Directory 종속 워크로드의 AWS 마이그레이션을 용이하게 하고 AWS […]

Amazon Bedrock AgentCore Identity로 안전한 기업형 에이전트 구현하기
“자율 AI”의 등장으로 인한 새로운 보안 과제 AI 에이전트는 단순한 대화형 챗봇을 넘어 실제 업무를 수행하는 단계로 진화하고 있습니다. 에이전트들은 API 호출, 코드 실행, 외부 시스템 제어 등 실제 행동(action)을 수행하며, 다수의 전문화된 에이전트가 협업하는 멀티 에이전트 패턴의 경우 에이전트-도구(tool) 연계를 넘어 에이전트 간 협업까지도 가능하게 하고 있습니다. 그러나 에이전트의 자율성이 높아질수록 새로운 보안 위협의 […]

AWS Backup를 활용하여 백업 데이터 복원 테스트를 구현하기
미션 크리티컬 애플리케이션은 전자상거래부터 의료에 이르기까지 다양한 분야를 지원하므로, 견고한 백업 전략은 단순한 모범 사례가 아닌 필수 요소입니다. 랜섬웨어와 같은 위협이 점점 더 정교해지는 상황에서 AWS 사용자에게는 백업 보유만으로는 충분하지 않습니다. 조직들은 재해가 발생했을 때 이러한 안전장치가 제대로 작동할 것이라는 확신이 필요합니다. 수동 테스트는 필수적이지만 IT 리소스를 소모합니다. 정기적인 자동화된 복원 테스트를 통해 조직은 효율성 향상뿐만 아니라 백업 무결성 검증, […]

Amazon Bedrock AgentCore Gateway: AI 에이전트의 MCP 도구 통합 관리하기
1. 도입 생성형 AI 기술의 발전과 함께 AI 에이전트는 단순한 질의응답을 넘어 실제 업무를 수행하는 핵심 시스템으로 자리잡고 있습니다. 많은 기업들이 AI 에이전트를 활용하여 고객 서비스를 자동화하고, 내부 업무 프로세스를 개선하며, 직원들의 생산성을 높이고 있습니다. 하지만 AI 에이전트가 실제 업무를 수행하려면 외부 시스템과 연결되어야 합니다. 캘린더를 조회하고, 데이터베이스를 검색하며, API를 호출하고, 이메일을 발송하는 등의 작업을 […]
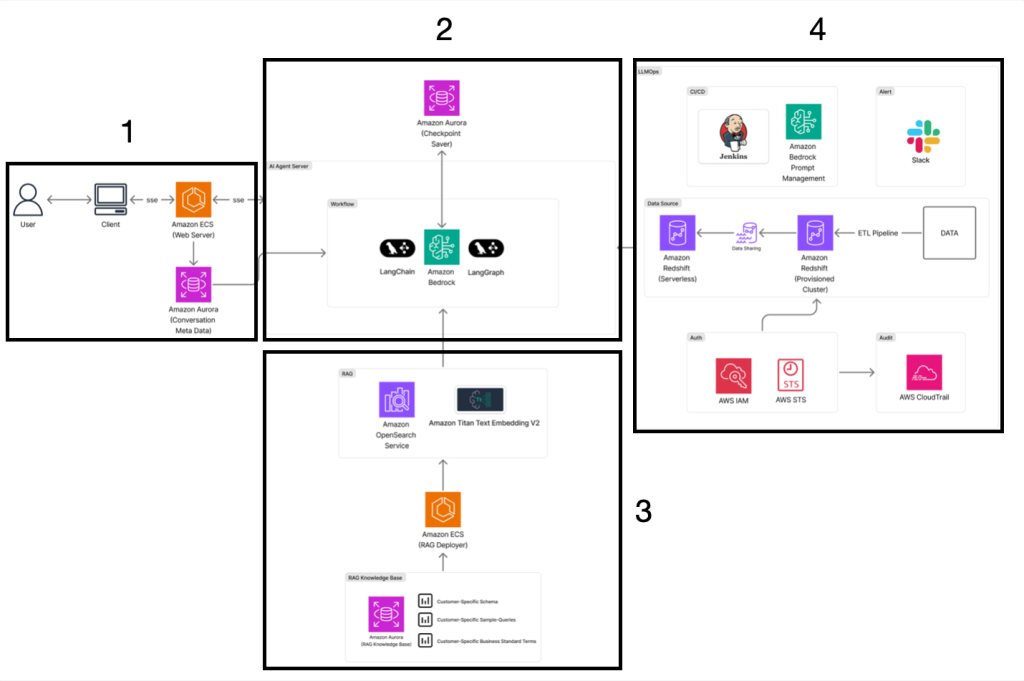
아이지에이웍스 AI 에이전트 클레어: Amazon Bedrock 기반 Text-to-SQL/Chart 에이전트로 이룬 데이터 분석 혁신
이 블로그는 2025 AI x Industry Week 에서 “Text2SQL로 완성한 IGAWorks 디파이너리의 데이터 분석 에이전트”의 주제로도 발표되었으며, 세션에서 다루지 못했던 세부 내용에 대해서도 추가로 소개합니다. 블로그는 아이지에이웍스가 AI 에이전트 ‘클레어(Claire)’를 개발하여 SQL 지식이 없는 마케터도 복잡한 데이터 분석을 수행할 수 있도록 한 혁신 사례를 총 2부에 걸쳐 소개하고자 합니다. 이를 통해 데이터 분석의 민주화가 어떻게 […]

매경AX의 생성형 AI 기반 오디오 팟캐스트 자동 생성 시스템 도입 여정
개요 매경AX는 매일경제신문사의 자회사로, 매경미디어그룹의 디지털 부문을 총괄하는 핵심 조직입니다. 2025년 디지털 전환(DX)을 넘어 ‘AI 전환(AI Transformation, AX)‘을 지향하며 사명을 ‘매경닷컴’에서 ‘매경AX’로 변경했습니다. 매경 AX는 단순한 뉴스 웹사이트를 넘어, AI 기술을 통해 콘텐츠의 가치를 극대화하고 개인 맞춤형 정보를 제공하는 ‘AI 지식 플랫폼’으로 발전 중입니다. 현재 매경AX는 독자가 질문을 입력하면 AI가 매경 콘텐츠를 기반으로 답변, 참고 […]
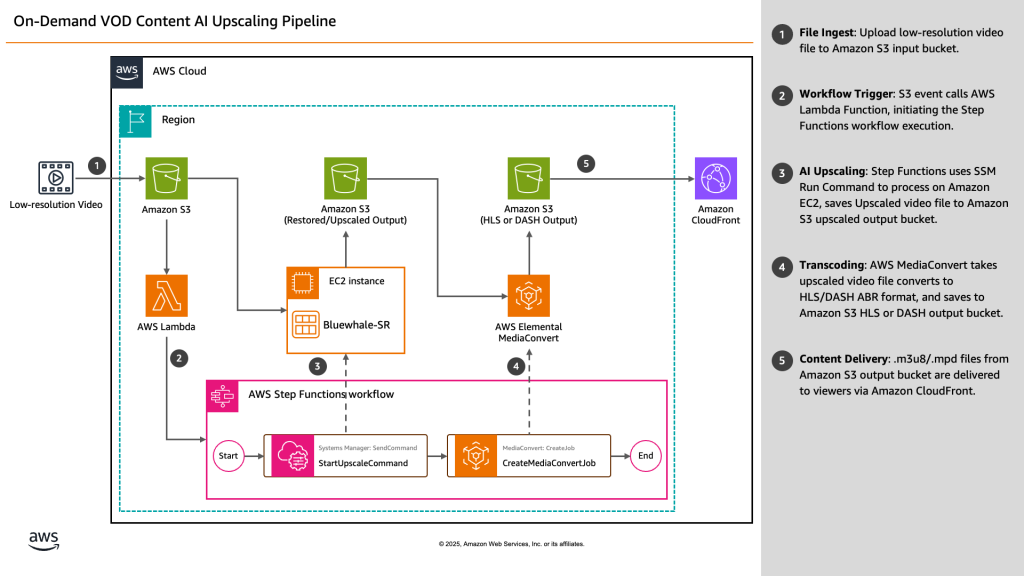
블루닷(BLUEDOT)의 AWS Elemental과 EC2 GPU AMI를 이용한 실시간 4K AI 비디오 업스케일링 아키텍처
블루닷 (BLUEDOT)은 미디어 AI 혁신을 선도하는 기술 기업으로, 영상 품질 개선 및 인코딩 최적화 솔루션을 전문적으로 제공하고 있습니다. 블루닷은 콘텐츠 업스케일링, 초고해상도 영상 변환, 실시간 스트리밍 최적화 등 광범위한 영역에서 차별화된 기술을 제공해 왔으며, 글로벌 미디어 기업, 방송사, OTT 플랫폼을 주요 고객으로 확보하고 있습니다. 특히, 블루닷의 핵심 기술인 AI 기반 업스케일링 솔루션은 기존 저해상도 영상의 […]

Amazon Aurora를 위한 Advanced JDBC Wrapper Driver 소개
이 글은 AWS Database Blog에 게시된 Introducing the Advanced JDBC Wrapper Driver for Amazon Aurora by Dave Cramer을 한국어 번역 및 편집하였습니다. 현대의 애플리케이션은 확장성과 복원력을 필수적으로 갖추어야 합니다. 특히 확장성이 가장 중요한데, 이는 애플리케이션이 워크로드 규모에 따라 수백만 사용자의 요청을 즉시 처리할 수 있는 능력을 의미합니다. 전자상거래, 금융 서비스, 게임과 같이 상태를 유지해야 하는(Stateful) […]