O blog da AWS
Transformando o TR-069 bulk data em insights com o AWS IoT Core e os serviços de análise na AWS
Introdução
Os provedores de serviços de comunicação (CSPs) geralmente gerenciam milhões de dispositivos (CPEs) de seus clientes para fornecer diversos serviços. Existem diversos tipos de dispositivos, dependendo das tecnologias de comunicação utilizadas. Modems via cabo e xDSL, decodificadores e roteadores sem fio são alguns exemplos de tipos de equipamentos que vemos nos ambientes dos clientes.
Para gerenciar esses dispositivos, muitos CSPs usam o protocolo TR-069 do Broadband Forum (também conhecido como CPE WAN Management Protocol ou CWMP). Esse protocolo permite uma maneira padronizada de gerenciar diferentes tipos de CPEs, permitindo que os CSPs reutilizem a camada de gerenciamento em diferentes tipos de dispositivos por meio de um software de gerenciamento chamado Auto Configuration Server (ACS). Existem vários fornecedores de ACS que implementaram com sucesso o protocolo e prestam serviços aos CSPs para gerenciar suas frotas de dispositivos de forma eficaz.
As primeiras versões do protocolo TR-069 não definiram uma forma dedicada de coletar informações de telemetria do dispositivo. Inicialmente, operações definidas por protocolo, como getParameterValues ou informações periódicas, eram usadas pelos ACSs para coletar alguns dados de telemetria dos dispositivo em intervalos determinados. Essa forma de coleta de dados, no entanto, trouxe problemas de escalabilidade, especialmente para as frotas de que tinham milhões de dispositivos. Vendo esse problema, o Broadband Forum introduziu uma nova forma de coletar informações de telemetria de dispositivos chamada bulk data collection (coleta de dados em massa) e a incluiu nas versões mais recentes do TR-069.
O recurso bulk data collection cria um canal de coleta de dados separado, com objetivo de enviar informações de telemetria para outro destino diferente do ACS. Essa abordagem cria uma segregação separando o gerenciamento de configuração do gerenciamento de desempenho, permitindo que essas funções sejam escaladas de forma independente.
No ano passado, a AWS publicou um diagrama de arquitetura de referência para TR-069 na AWS, mostrando como os serviços da AWS podem ser usados para coletar dados de telemetria de dispositivos para gerar insights.
Neste blog post, explicarei casos de uso que vemos no setor para o uso dos dados de telemetria de CPEs e mostrarei uma implementação do TR-069 utilizando a arquitetura de referência da AWS.
Abordagem
Há alguns casos de uso comuns onde os dados de telemetria do CPE podem ser usados pelos CSPs. Neste blog, explicarei cinco desses casos de uso e como eles podem ser tratados na AWS através do processamento dos dados obtidos via TR-069 bulk data (dados em massa):
- Dashboards (Painéis em tempo real)
- Heartbeat (Detecção de batimentos)
- Closed-loop (Detecção de anomalias e automação em circuito fechado)
- Manutenção preditiva
- Análise e relatórios de dados históricos
Nas seções a seguir, descrevo esses casos de uso e apresento uma proposta de arquitetura para endereça-los na AWS.
Dashboards em tempo real
Os dashboards em tempo real geralmente são o primeiro requisito para projetos de coleta de bulk data. Esses dashboards permitem exibir os dados brutos (raw) ou processados (processed) o mais rápido possível após a ingestão. Os dashboards em tempo real permitem que a equipe de operação visualize as métricas brutas em tempo real, bem como as métricas derivadas para apoiar as operações e a solução de problemas.
Detecção de heartbeat
A detecção de heartbeat permite que os CSPs detectem os dispositivos que estão offline. Essa detecção pode ser implementada de várias maneiras. Com a coleta de bulk data via HTTPS, um aplicativo de análise de streaming dinâmico é normalmente usado para rastrear se um determinado dispositivo enviou dados dentro de um período de tempo definido. Em algumas implementações, o software de dashboard em tempo real também pode ser usado para detectar os heartbeats ausentes nos dispositivos. Se a coleta de bulk data for implementada pelo MQTT, as desconexões do dispositivo poderão ser detectadas imediatamente, pois existe a conexão persistente entre o dispositivo e o MQTT broker.
Detecção de anomalias e automação em closed-loop
A detecção de anomalias é outro caso de uso comum para o processamento de dados de telemetria. Certas métricas, como utilização da CPU, utilização da memória ou taxa de transferência, podem ser usadas para criar linhas de base, e o sistema pode criar alertas para situações em que as leituras atuais se desviam dessas linhas. Para detectar anomalias pontuais, que não exigem uma abordagem baseada em ML (Machine Learning), verificações simples baseadas em limites são eficazes. A detecção de uma taxa de erro crescente em uma interface é um exemplo desses tipos de anomalias.
Depois que a anomalia for detectada, uma ação deve ser tomada para corrigi-la. Se a anomalia exigir ação manual, ela normalmente é convertida em um alerta ou um chamado de problema nos sistemas de suporte de operações (OSS) do CSP para ser rastreada e gerenciada. Se a anomalia puder ser resolvida por uma ação automatizada (como a reinicialização do dispositivo ou a alteração do canal Wi-Fi), pode-se tentar corrigi-la em um circuito fechado (closed-loop). Nessa configuração, o sistema de coleta de dados normalmente aciona o ACS para iniciar uma ação corretiva no dispositivo problemático. As automações de circuito fechado funcionam quase em tempo real.
Manutenção preditiva
A manutenção preditiva visa resolver problemas antes que eles aconteçam. Por exemplo, monitorar continuamente os níveis de voltagem da bateria de um dispositivo pode identificar problemas na bateria antes que eles causem indisponibiidade. A análise de manutenção preditiva geralmente requer dados históricos, não acontece em tempo real e pode ser executada em lotes. Evitar o envio desnecessário de equipes de manutenção pode trazer muita economia de custo para os CSPs e, ao mesmo tempo, melhorar a experiência do cliente.
Análise e relatórios de dados históricos
Os relatórios históricos são outro caso de uso comum. Os dados históricos do dispositivo podem ser usados para treinar modelos de ML para casos de uso baseados em ML que mencionei acima. Outro uso disso é solucionar problemas do cliente. Por exemplo, um cliente pode ligar para a central de atendimento e reclamar de um problema de desempenho recorrente que está ocorrendo em determinados momentos da semana. A identificação da causa raiz do problema do cliente pode não ser possível sem analisar os dados históricos. A análise de dados históricos também é utilizada para fins de análise exploratória de dados. Os dispositivos geralmente emitem centenas de métricas. É necessário explorar os dados brutos disponíveis para identificar quais podem ser usados para resolver os casos de uso mencionados acima ou para criar novos casos de uso.
Solução
A arquitetura da solução a seguir será usada para coletar dados de CPE e analisá-los para endereçar os casos de uso acima. Como mencionei anteriormente, essa arquitetura é uma implementação a partir da arquitetura de referência. Dependendo dos casos de uso que você deseja abordar, sua implementação pode ser mais simples, mais complexa ou pode usar outros serviços da AWS.

Diagrama de arquitetura mostrando como a telemetria e os metadados do CPE podem ser enviados para a AWS para gerar insights
Nas seções a seguir, vou dividir a arquitetura proposta em seções e organizar as seções por casos de uso, depois vou explicar as etapas comuns de configuração do dispositivo, ingestão e filtragem de dados, normalização e enriquecimento de dados.
Configuração do dispositivo
A primeira etapa na coleta de bulk data baseada em TR-069 é configurar o bulk data profile (perfil de coleta) em um dispositivo. O bulk data profile faz parte dos modelos de dados TR-098 ou TR-181 e precisa ser configurado via ACS. O bulk data profile inclui parâmetros de conexão, tais como URL do receptor de bulk data, protocolo, porta, informações de autenticação e assim por diante. O bulk data profile também inclui quais métricas do modelo de dados serão coletadas e enviadas para um receptor.
Neste exemplo, o mecanismo de envio de dados é baseado em POST via HTTPS. Nesse cenário acima, a frota de CPEs é configurada para enviar métricas do bulk data para um endpoint HTTPS do AWS IoT Core em intervalos específicos configurado no bulk data profile.
Ingestão de dados
Para a ingestão de dados utilizamos o AWS IoT Core. No AWS IoT Core existe a opção de configurar uma função AWS Lambda como um autorizador personalizado para endpoint HTTP. A função AWS Lambda, em conjunto com uma tabela no Amazon DynamoDB, são usadas para coletar e validar informações de nome de usuário e senha dos cabeçalhos HTTP.
Como a ingestão de dados é feita somente por HTTP, a funcionalidade Basic Ingest do AWS IoT Core também é usada. Essa funcionalidade nos permite fazer um “by-pass” do message broker no caminho de ingestão, o que permite um fluxo de dados mais econômico.
Uma regra de roteamento dados no mecanisco de regras do AWS IoT entrega as mensagens recebidas para o Amazon Kinesis Data Streams. Esse raw stream (canal de dados bruto) é usado para coletar e reter essas mensagens.
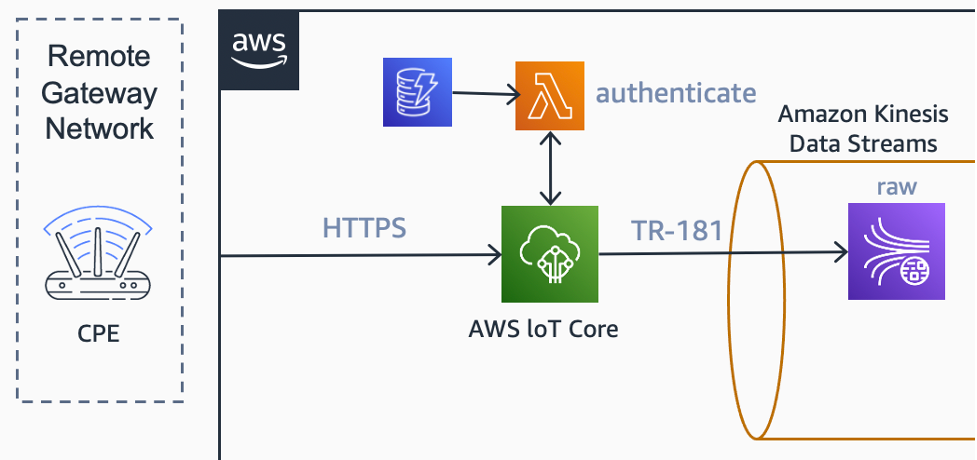
Diagrama de arquitetura mostrando como os dados de telemetria do CPE podem ser ingeridos pelo AWS IoT Core
Filtragem, normalização e enriquecimento de dados
Uma aplicação de análise de streams, baseada no Apache Flink e executada no Amazon Kinesis Data Analytics, busca continuamente novas mensagens no raw stream. Essa aplicação filtra, normaliza e converte o documento JSON, recebido dos CPEs, no modelo de dados interno, que será usado posteriormente no processamento dos casos de uso.
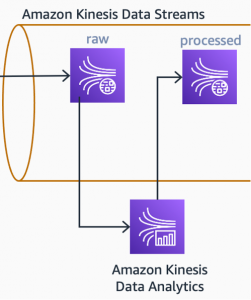
Diagrama de arquitetura mostrando como os dados brutos são processados pelo Amazon Kinesis Data Analytics e gravados em outro stream
A aplicação executando no Kinesis Data Analytics também enriquece os dados. Frequentemente, encontraremos métricas que são contadores dentro dos dados brutos (raw data). Métricas como BytesSent e BytesReceived são contadores que aumentam continuamente no dispositivo. Para usar esses tipos de métricas em análises, precisamos processá-las e criar métricas derivadas. A taxa de transferência de entrada, por exemplo, pode ser calculada a partir de dois pontos de dados consecutivos de bytesReceived e do intervalo de tempo entre eles.
Depois que os dados são enriquecidos com métricas derivadas, eles podem ser gravados em outro fluxo: fluxo processado (processed stream). Esse fluxo será uma entrada para o primeiro caso de uso posterior: painel em tempo real.
Caso de uso 1: painéis em tempo real
O primeiro caso de uso que expliquei foi a respeito dos dashboards ou painéis em tempo real. Na arquitetura proposta, estou usando o Amazon Managed Grafana para criar os dashboards. Além disso também estou usando uma função AWS Lambda para ler os dados recebidos do stream processado e gravá-los no Amazon Timestream. O Amazon Timestream contém as informações da série temporal, que podem ser visualizadas nos painéis do Amazon Managed Grafana por meio de seu plug-in.

Diagrama de arquitetura mostrando como os dados processados podem ser exibidos nos painéis do Amazon Managed Service for Grafana.
Um painel do Amazon Managed Grafana pode exibir muitos detalhes, dependendo dos requisitos do cliente. Agregações como MIN, MAX e AVG podem ser feitas dentro do painel em intervalos amplos de tempo. Os painéis do Amazon Managed Grafana também permitirão que você defina limites em relação às métricas e exiba alarmes quando esses limites forem excedidos.
Caso de uso 2: detecção de heardbeat
Na arquitetura proposta, a mesma aplicação, executando no Kinesis Data Analytics também é usado para detectar heardbeat ausentes no stream de entrada, pois ele não terá requisitos de escalabilidade separados, e presumi que uma única equipe será responsável pelo Kinesis Data Analytics. Se esse não for o caso, ele deve ser projetado como uma leitura separada a partir do raw stream ou do processed stream. Isso também se aplica a casos de uso futuros que serão definidos neste blog.
Como o Apache Flink é uma plataforma de processamento de streams com controle de estado, ele pode ser usado para manter o estado para um dispositivo específico. Nesse objeto de estado, pode ser salva a última data e hora que o dispositivo enviou o bulk data collection e usar temporizadores para detectar quando um dispositivo perde um número configurável de intervalos de tempo. Quando uma condição de falta de heartbeat é detectada, o aplicativo gera um evento de alarme no fluxo de alarmes de heartbeat.
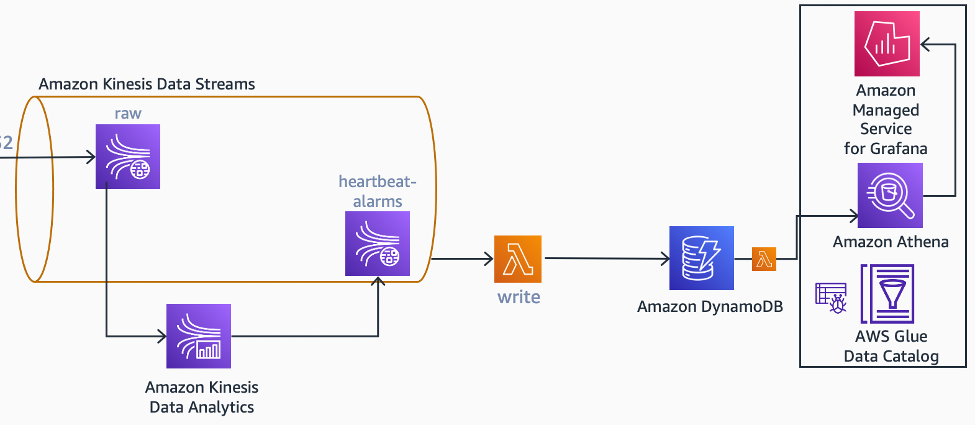
Diagrama de arquitetura mostrando como os alarmes de heartbeat podem ser gerados a partir dos dados brutos.
Quando o dispositivo volta a ficar on-line, o mesmo aplicativo Kinesis Data Analytics gera outro evento, dessa vez, eliminando o alarme, para o mesmo stream. Uma função do AWS Lambda coleta processa os eventos de alarme e eliminação de alarmes e mantém uma tabela (heartbeat-missing-devices) de dispositivos com alarme de heartbeat no Amazon DynamoDB.
Se for necessário, é possível exibir essas informações em um painel. Na arquitetura proposta, um painel é criado no Amazon Managed Grafana, que usa o Amazon Athena para extrair informações da tabela heartbeat-missing-devices.
Caso de uso 3: detecção de anomalias e automação de circuito fechado
Conforme mencionado anteriormente, existem várias maneiras de detectar anomalias com métricas. A detecção de anomalias com base em limites pode ser usada em elementos de dados individuais ou agregados baseados em intervalos de tempo. Um aplicativo Kinesis Data Analytics também pode fazer a detecção de anomalias em tempo real baseada em aprendizado de máquina (ML) por meio de um algoritimo RCF (Random Cut Forest) ou chamando um endpoint de inferência pré-treinado do Amazon SageMaker.
Independentemente do mecanismo usado, as anomalias detectadas podem ser usadas para acionar automações de self-healing (autorrecuperação) com ou sem aprovação humana.
Na arquitetura proposta, uma anomalia pontual, detectada por um limite simples em uma métrica de erro, aciona um mecanismo de self-healing com a aprovação do usuário.
Nessa subarquitetura, o fluxo de eventos começa com o aplicativo Kinesis Data Analytics publicando um evento de detecção de anomalias em um tópico do Amazon SNS. Esse evento inclui a ID do dispositivo associado a anomalia. Quando o evento é recebido pelo Amazon SNS, ele invoca uma função do Lambda. A função Lambda consulta uma tabela do DynamoDB as informações do responsável dispositivo, utilizando o ID do dispositivo. Depois que as informações do responsável são localizadas, a função Lambda busca o número de telefone e envia ao responsável um SMS utilizando o Amazon Pinpoint e solicita sua autorização para reinicializar o dispositivo.

Diagrama de arquitetura que mostra como os alarmes de anomalias podem acionar uma ação corretiva.
O Amazon Pinpoint usa sua funcionalidade de SMS bidirecional para coletar a resposta do usuário e entregá-la a um tópico do Amazon SNS. Este tópico passa as informações para uma fila FIFO do Amazon SQS, que é consultada por outra função Lambda. A função Lambda grava a resposta do proprietário em uma tabela do DynamoDB e, se a resposta for positiva, invoca outra função Lambda. Em seguida, a função Lambda vai interagir com a interface northbound (NBI) do ACS para reinicializar o dispositivo.
Anomalias diferentes vão necessitar mecanismos diferentes de self-healing. Uma analise dos mecanismos atuais, para solução de problemas e seus gatilhos, vão ajudar a encontrar os possíveis candidatos para cenários de self-healing.
Casos de uso 4 e 5: análise de dados históricos, relatórios e manutenção preditiva
Os dados históricos do dispositivo podem desempenhar um papel importante, nos casos de uso de análise de dados históricos e geração de relatórios. Esses dados também podem ser usados para treinar algoritmos de ML para detectar anomalias e indicar atividades de manutenção preditiva.
A ingestão de dados de telemetria de milhões de dispositivos com intervalos de minutos traz desafios de escalabilidade, especialmente no que diz respeito ao armazenamento. O Amazon S3 foi escolhido para a arquitetura propostas, pois conta com escalabilidade praticamente ilimitada e ótima relação custo beneficio, portanto é adequado para o armazenamento dos dados de telemetria.
Os dados brutos e processados no Amazon Kinesis Data Streams são copiados para os buckets brutos (raw) e processados (processed), respectivamente. A operação de cópia é feita pelo Amazon Kinesis Data Firehose. O Kinesis Data Firehose organiza os dados em uma estrutura de pastas YYYY/MM/DD/HH (Ano/Mês/Dia/Hora), adicionando prefixos automaticamente no S3. Como os dados processados serão consultados diretamente no Amazon Athena, o Amazon Kinesis Data Firehose também converte os dados no formato Parquet para otimizar custos e a leitura. Políticas de ciclo de vida (lifecycle) no Amazon S3 são configuradas nos buckets brutos e processados, para mover objetos da classe de armazenamento Amazon S3 Standard para classes de armazenamento mais frias após um período de retenção especificado.
Nossos clientes e parceiros normalemente precisam utilizar os dados existentes no ACS em conjuntio com os dados de telemetria. Geralmente, os dados do TR-069 bulk data não incluem metadados do dispositivo, informações como localização, recursos do dispositivo e outras informações de inventário.
Os dados do ACS também podem ser importados para o Amazon S3 e podem ser correlacionados com os dados de telemetria no Amazon Athena através de consultas SQL. Os dados do ACS também podem ser usados para enriquecer o fluxo de dados no aplicativo Kinesis Data Analytics. Na arquitetura proposta, usei o AWS Database Migration Service (AWS DMS) para capturar metadados de bancos de dados ACS. O AWS DMS oferece suporte a vários mecanismos de banco de dados SQL e NoSQL, como Oracle, MS SQL Server e MongoDB. Com seus recursos de migração contínua e captura de dados de alteração (CDC), ele pode capturar alterações do banco de dados do ACS e inseri-las no Amazon S3 quase em tempo real. Quando os dados chegam ao Amazon S3, um trabalho do AWS Glue os transforma ainda mais do formato de saída do Amazon DMS em um formato comum, otimizado para leitura.

Diagrama de arquitetura mostrando como os metadados do ACS podem ser extraídos do banco de dados ACS via AWS DMS.
Conclusão
Neste blog, defini alguns dos casos de uso comuns de dados de telemetria de CPE. Mostrei como a coleta do TR-069 bulk data pode ser usada em conjunto com diferentes serviços da AWS para ingestão e análise com uma arquitetura de exemplo da AWS.
O uso de serviços serverless da AWS permite escalabilidade transparente à medida que sua frota de CPE cresce, além de reduzir seus custos de gerenciamento.
Você pode explorar o TR-069 e a arquitetura de referência da AWS e implementá-la para resolver seus desafios de coleta de bulk data do CPE.
Você também pode visitar Telecomunicações na AWS para saber como os CSPs reinventam a comunicação com a AWS.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre o autor
 Murat Balkan é Specialist Solutions Architect (OSS/BSS) em Toronto.
Murat Balkan é Specialist Solutions Architect (OSS/BSS) em Toronto.
Revisor
 Luciano Coelho é Arquiteto de Soluções que trabalha há mais de 20 anos com clientes Enterprise e Telecom. Ampla experiência em Sistemas de Armazenamento e rede, atualmente dedica seu tempo a ajudar clientes a inovarem e economizar através do uso dos serviços na nuvem AWS. Ama mergulhar sempre que pode e é apaixonado por construir coisas, marcenaria, serralheria, impressão 3d, eletrônica e tudo que associado a tecnologia.
Luciano Coelho é Arquiteto de Soluções que trabalha há mais de 20 anos com clientes Enterprise e Telecom. Ampla experiência em Sistemas de Armazenamento e rede, atualmente dedica seu tempo a ajudar clientes a inovarem e economizar através do uso dos serviços na nuvem AWS. Ama mergulhar sempre que pode e é apaixonado por construir coisas, marcenaria, serralheria, impressão 3d, eletrônica e tudo que associado a tecnologia.