亚马逊AWS官方博客
Amazon Redshift ML 现已正式推出 – 使用 SQL 创建机器学习模型并通过您的数据进行预测
借助 Amazon Redshift,您可以使用 SQL 在您的数据仓库、操作数据库和数据湖中查询和合并数 EB 的结构化和半结构化数据。现在,AQUA(高级查询加速器)已全面推出,您可以将您的查询性能最高提高 10 倍,而无需额外的费用和代码更改。事实上,Amazon Redshift 提供比其他云数据仓库高出三倍的性价比。
但是,如果您想更进一步,处理这些数据以训练机器学习 (ML) 模型并使用这些模型从仓库中的数据生成见解,该怎么办? 例如,要实施预测收入、预测客户流失和检测异常等使用案例? 过去,您需要将训练数据从 Amazon Redshift 导出到 Amazon Simple Storage Service (Amazon S3) 存储桶,然后配置并开始机器学习训练过程(例如,使用 Amazon SageMaker)。这个过程需要许多不同的技能,通常需要多个人才能完成。我们能将这个过程简化吗?
今天,Amazon Redshift ML已正式推出,可帮助您直接从 Amazon Redshift 集群创建、训练和部署机器学习模型。要创建机器学习模型,您可以使用简单的 SQL 查询来指定要用于训练模型的数据以及要预测的输出值。例如,要创建预测市场营销活动成功率的模型,您可以通过选择包含客户配置文件和以前营销活动结果的列(在一个或多个表格中)来定义输入,以及您想预测的输出列。在此示例中,输出列可以是显示客户是否对活动表现出兴趣的列。
运行 SQL 命令创建模型后,Redshift ML 会将指定的数据从 Amazon Redshift 中安全地导出到 S3 存储桶,并调用 Amazon SageMaker Autopilot 来准备数据(预处理和特征工程),然后选择适当的预构建算法,并将该算法应用于模型训练。您可以选择性地指定要使用的算法,例如 XGBoost。

Redshift ML 处理 Amazon Redshift、S3 与 SageMaker 之间的所有交互,包括训练和编译中涉及的所有步骤。模型训练完成后,Redshift ML 使用 Amazon SageMaker Neo 来优化模型以进行部署,并将其作为 SQL 函数提供。您可以使用 SQL 函数将机器学习模型应用于查询、报告和控制面板中的数据。
Redshift ML 现在包括许多在预览期间未提供的新功能,包括 Amazon Virtual Private Cloud (VPC) 支持。例如:
- 现在,您可以将 SageMaker 模型导入您的 Amazon Redshift 集群中(本地推理)。
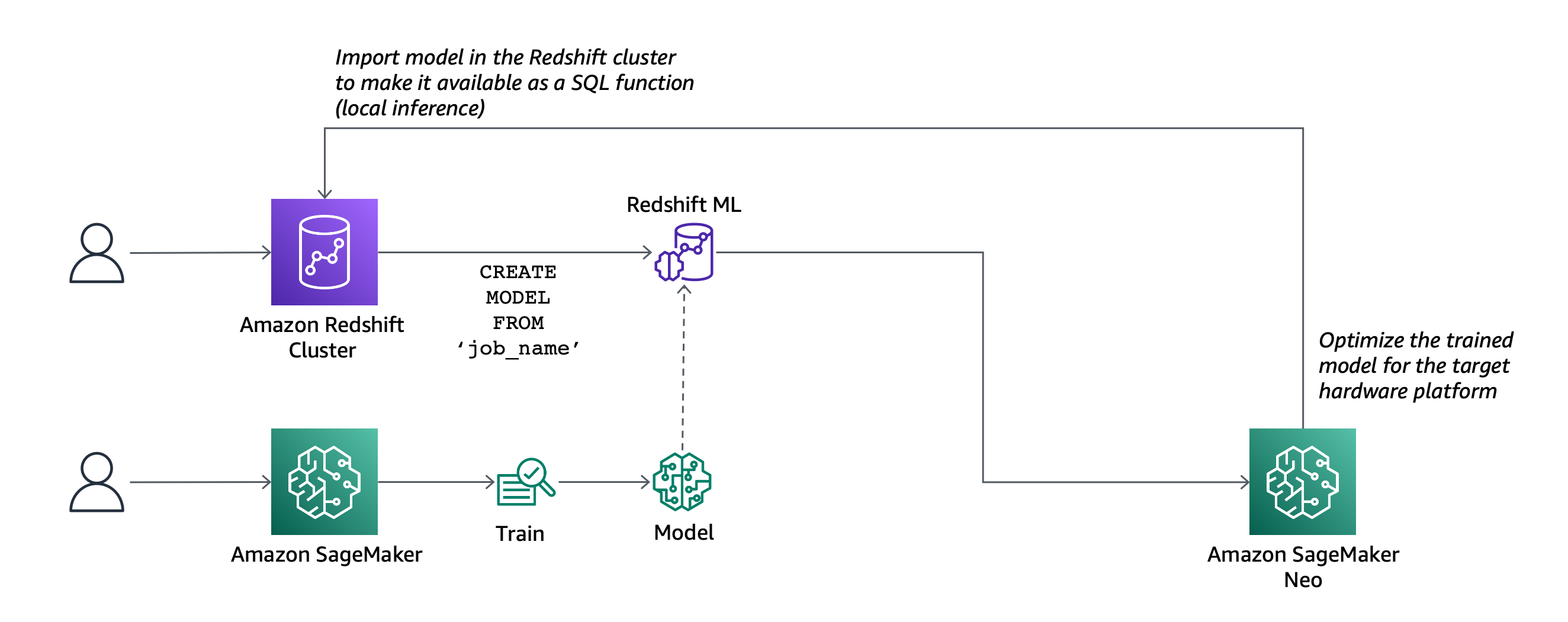
- 您还可以创建使用现有 SageMaker 终端节点进行预测 SQL 函数(远程推理)。在这种情况下,Redshift ML 正在批处理对终端节点的调用以加快处理速度。

在研究如何在实践中使用这些新功能之前,让我们先看看 Redshift ML 与 AWS 数据库和分析服务中的类似功能之间的区别。
| ML 功能 | 数据 | 从 SQL
进行训练 |
使用 SQL 函数
进行预测 |
| Amazon Redshift ML |
数据仓库 S3 数据湖(带有 Redshift Spectrum) |
是的,使用
Amazon SageMaker Autopilot |
是的,模型可以在 Amazon Redshift 集群内导入和执行,也可以使用 SageMaker 终端节点调用模型。 |
| Amazon Aurora ML | 关系数据库
(与 MySQL 或 PostgreSQL 兼容) |
否 |
是的,使用 SageMaker 终端节点。 还可以与 Amazon Comprehend 本机集成,以进行情绪分析。 |
| Amazon Athena ML |
S3 数据湖 其他数据源可以通过 Athena 联合查询使用。 |
否 | 是的,使用 SageMaker 终端节点。 |
使用 Redshift ML 构建机器学习模型
我们来构建一个模型,预测客户是接受还是拒绝营销优惠。
要管理与 S3 和 SageMaker 之间的交互,Redshift ML 需要访问这些资源的权限。我创建了一个 AWS Identity and Access Management (IAM) 角色,如文档中所述。我将 RedshiftML 用于角色名称。请注意,该角色的信任策略同时允许 Amazon Redshift 和 SageMaker 代入角色,以与其他 AWS 服务交互。
我从 Amazon Redshift 控制台中创建一个集群。在集群权限中,我关联 RedshiftML IAM 角色。当集群可用时,我将加载我的同事 Julien 在 SageMaker Autopilot 宣布推出时撰写的这篇超级有趣的博客文章中使用的数据集。
我正在使用的文件 (bank-additional-full.csv) 为 CSV 格式。每一行都描述了与客户进行的直接营销活动。最后一列 (y) 描述活动的结果(客户是否订阅了向他们营销的服务)。
下面的该文件的前几行。第一行包含标题。
我将文件存储在我的其中一个 S3 存储桶中。S3 存储桶用于卸载数据和存储 SageMaker 训练构件。
然后,我使用控制台中的 Amazon Redshift 查询编辑器创建表格来加载数据。
CREATE TABLE direct_marketing (
age DECIMAL NOT NULL,
job VARCHAR NOT NULL,
marital VARCHAR NOT NULL,
education VARCHAR NOT NULL,
credit_default VARCHAR NOT NULL,
housing VARCHAR NOT NULL,
loan VARCHAR NOT NULL,
contact VARCHAR NOT NULL,
month VARCHAR NOT NULL,
day_of_week VARCHAR NOT NULL,
duration DECIMAL NOT NULL,
campaign DECIMAL NOT NULL,
pdays DECIMAL NOT NULL,
previous DECIMAL NOT NULL,
poutcome VARCHAR NOT NULL,
emp_var_rate DECIMAL NOT NULL,
cons_price_idx DECIMAL NOT NULL,
cons_conf_idx DECIMAL NOT NULL,
euribor3m DECIMAL NOT NULL,
nr_employed DECIMAL NOT NULL,
y BOOLEAN NOT NULL
);我使用 COPY 命令将数据加载到表格中。我可以使用之前创建的相同 IAM 角色 (RedshiftML),因为我使用相同的 S3 存储桶来导入和导出数据。
现在,我使用新的 CREATE MODEL 语句从 SQL 界面中直接创建模型:
CREATE MODEL direct_marketing
FROM direct_marketing
TARGET y
FUNCTION predict_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);在此 SQL 命令中,我指定创建模型所需的参数:
FROM– 我选择direct_marketing表格中的所有行,但我可以将表格的名称替换为嵌套查询(请参见下面的示例)。TARGET– 这是我想预测的列(在此案例中为y)。FUNCTION– 要进行预测的 SQL 函数的名称。IAM_ROLE– Amazon Redshift 和 SageMaker 代入的 IAM 角色,用于创建、训练和部署模型。S3_BUCKET– 临时存储训练数据的 S3 存储桶,以及您选择保留模型构件的副本时存储模型构件的位置。
在这里,我将简单语法用于 CREATE MODEL 语句。对于更高级的用户,还可以使用其他选项,例如:
MODEL_TYPE– 使用指定模型类型进行训练,例如 XGBoost 或多层感知器 (MLP)。如果我没有指定此参数,SageMaker Autopilot 会选择适当模型类来使用。PROBLEM_TYPE– 定义要解决的问题类型: 回归、二进制分类或多级分类。如果我不指定此参数,则会根据我的数据在训练期间发现问题类型。OBJECTIVE– 用于测量模型质量的目标指标。此指标在训练期间进行了优化,以便根据数据提供最佳估计。如果我不指定指标,则默认行为为使用均方误差 (MSE) 进行回归,使用 F1 评分进行二进制分类,以及使用准确性进行多类分类。其他可用选项包括 F1Macro(用于将 F1 评分应用于多类分类)和曲线下面积 (AUC)。有关目标指标的更多信息,请参阅 SageMaker 文档。
根据模型的复杂性和数据量,模型可能需要一些时间才能使用。我使用 SHOW MODEL 命令查看模型何时可用:
当我使用控制台中的查询编辑器执行此命令时,我获得以下输出:

正如预期的那样,模型目前处于 TRAINING 状态。
当我创建此模型时,我将表格中的所有列选为输入参数。我想知道如果我创建一个使用较少输入参数的模型会发生什么? 我处于云中,并没有因为有限的资源被拖慢速度,所以我使用表格中的列子集创建另一个模型:
CREATE MODEL simple_direct_marketing
FROM (
SELECT age, job, marital, education, housing, contact, month, day_of_week, y
FROM direct_marketing
)
TARGET y
FUNCTION predict_simple_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);一段时间后,我的第一个模型准备就绪,我从 SHOW MODEL 获得了此输出。控制台中的实际输出处于多个页面中,我将结果合并到此处,以便更容易遵循它们:

从输出中,我看到模型已被正确识别为 BinaryClassification,且 F1 被选为目标。F1 评分是同时考虑精度和召回的指标。它返回介于 1(完美精度和召回)和 0(最低评分)之间的值。模型的最终评分 (validation:f1) 为 0.79。在此表格中,我还找到了为模型创建的 SQL 函数的名称 (predict_direct_marketing),它的参数及其类型和训练成本的评估。
第二个模型准备就绪时,我比较了 F1 评分。第二个模型的 F1 得分低于第一个模型 (0.66)。但是,由于参数较少,SQL 函数更容易应用于新数据。与机器学习经常存在的情况一样,我必须在复杂性和可用性之间找到适当的平衡。
使用 Redshift ML 进行预测
既然这两个模型已准备就绪,我可以使用 SQL 函数进行预测。使用第一个模型,我检查在将模型应用于训练的相同数据时,我得到了多少误报(错误的阳性预测)和漏报(错误的阴性预测):
SELECT predict_direct_marketing, y, COUNT(*)
FROM (SELECT predict_direct_marketing(
age, job, marital, education, credit_default, housing,
loan, contact, month, day_of_week, duration, campaign,
pdays, previous, poutcome, emp_var_rate, cons_price_idx,
cons_conf_idx, euribor3m, nr_employed), y
FROM direct_marketing)
GROUP BY predict_direct_marketing, y;查询的结果表明,该模型更善于预测阴性结果,而不是阳性结果。事实上,即使真正的阴性结果数量远远大于真正的阳性结果,但误报比漏报还是要多得多。我在下面的屏幕截图中添加了一些绿色和红色的评论,以澄清结果的含义。

使用第二种模式,我看到多少客户可能对营销活动感兴趣。理想情况下,我应该针对新客户数据运行此查询,而不是我用于训练的数据。
SELECT COUNT(*)
FROM direct_marketing
WHERE predict_simple_direct_marketing(
age, job, marital, education, housing,
contact, month, day_of_week) = true;哇,看看结果,有 7000 多个潜在客户!

可用性和定价
Redshift ML 现已在以下 AWS 区域推出:美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、美国西部(旧金山)、加拿大(中部)、欧洲(法兰克福)、欧洲(爱尔兰)、欧洲(巴黎)、欧洲(斯德哥尔摩)、亚太地区(香港)、亚太地区(东京)、亚太地区(新加坡)、亚太地区(悉尼)和南美洲(圣保罗)。有关更多信息,请参阅 AWS 区域服务列表。
使用 Redshift ML,您只需为使用量付费。训练新模型时,您需要为 Amazon SageMaker Autopilot 和 Redshift ML 使用的 S3 资源付费。进行预测时,如我在本博文中使用的示例所示,导入到 Amazon Redshift 集群中的模型不会产生额外费用。
Redshift ML 还允许您使用现有的 Amazon SageMaker 终端节点进行推理。在此案例中,适用用于实时推理的通常 SageMaker 定价。在此,您可以找到有关使用 Redshift ML 控制成本的几点提示。
要了解更多信息,您可以参阅 Redshift ML 预览版发布时撰写的此博客文章和文档。
使用 Redshift ML 开始从您的数据中获得更好的见解。
– Danilo