亚马逊AWS官方博客
新增功能 – 使用 Step Functions 协调 Amazon EMR 工作负载
使用 AWS Step Functions,您可以为应用程序添加无服务器工作流自动化。您的工作流的步骤可以在任何位置运行,包括在 AWS Lambda 函数中、在 Amazon Elastic Compute Cloud (EC2) 上或在本地运行。为简化构建工作流,Step Functions 直接与多项 AWS 服务集成:Amazon ECS、AWS Fargate、Amazon DynamoDB、Amazon Simple Notification Service (SNS)、Amazon Simple Queue Service (SQS)、AWS Batch、AWS Glue、Amazon SageMaker 以及(为运行嵌套工作流)Step Functions 本身。
从今天开始,Step Functions 将连接到 Amazon EMR,使您能够以最少的代码创建数据处理和分析工作流,节省时间,并优化集群利用率。例如,为机器学习构建数据处理管道不仅耗时,而且棘手。借助这一全新集成功能,您可以轻松协调工作流功能,包括上一步结果中的并行执行和依赖关系,并在运行数据处理作业时处理故障和异常情况。
具体来说,Step Functions 状态机现在可以:
- 创建或终止 EMR 集群,包括可更改集群终止保护。这样,您可将现有 EMR 集群重复用于工作流,也可在执行工作流期间按需创建一个集群。
- 为您的集群添加或取消 EMR 步骤。 每个 EMR 步骤都是一个作业单位,其中包含数据操作说明,以便通过安装在集群上的软件进行处理,例如 Apache Spark、Hive 或 Presto。
- 修改 EMR 集群实例队列或组的大小,使您可以根据工作流每个步骤的要求以编程方式管理扩展。例如,您可以在添加计算密集型步骤之前增大实例组的大小,并在完成后立即减小其大小。
在您创建或终止集群或向集群添加 EMR 步骤时,仅当相应的活动已在 EMR 集群上完成时,您才能使用同步集成移至工作流的下一个步骤。
读取您的 EMR 集群的配置或状态不属于 Step Functions 服务集成。如果您需要,可以使用 Lambda 函数作为任务访问 EMR List* 和 Describe* API。
使用 EMR 和 Step Functions 构建工作流
我将在 Step Functions 控制台上创建一个新的状态机。控制台可非常直观地呈现创建步骤,以便易于理解:

为创建状态机,我通过 Amazon States Language (ASL) 使用以下定义:
{
"StartAt": "Should_Create_Cluster",
"States": {
"Should_Create_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.CreateCluster",
"BooleanEquals": true,
"Next": "Create_A_Cluster"
},
{
"Variable": "$.CreateCluster",
"BooleanEquals": false,
"Next": "Enable_Termination_Protection"
}
],
"Default": "Create_A_Cluster"
},
"Create_A_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:createCluster.sync",
"Parameters": {
"Name": "WorkflowCluster",
"VisibleToAllUsers": true,
"ReleaseLabel": "emr-5.28.0",
"Applications": [{ "Name": "Hive" }],
"ServiceRole": "EMR_DefaultRole",
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "s3://aws-logs-123412341234-eu-west-1/elasticmapreduce/",
"Instances": {
"KeepJobFlowAliveWhenNoSteps": true,
"InstanceFleets": [
{
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
},
{
"InstanceFleetType": "CORE",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
}
]
}
},
"ResultPath": "$.CreateClusterResult",
"Next": "Merge_Results"
},
"Merge_Results": {
"Type": "Pass",
"Parameters": {
"CreateCluster.$": "$.CreateCluster",
"TerminateCluster.$": "$.TerminateCluster",
"ClusterId.$": "$.CreateClusterResult.ClusterId"
},
"Next": "Enable_Termination_Protection"
},
"Enable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": true
},
"ResultPath": null,
"Next": "Add_Steps_Parallel"
},
"Add_Steps_Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Step_One",
"States": {
"Step_One": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The first step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"End": true
}
}
},
{
"StartAt": "Wait_10_Seconds",
"States": {
"Wait_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Step_Two (async)"
},
"Step_Two (async)": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The second step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": "$.AddStepsResult",
"Next": "Wait_Another_10_Seconds"
},
"Wait_Another_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Cancel_Step_Two"
},
"Cancel_Step_Two": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:cancelStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"StepId.$": "$.AddStepsResult.StepId"
},
"End": true
}
}
}
],
"ResultPath": null,
"Next": "Step_Three"
},
"Step_Three": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The third step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": null,
"Next": "Disable_Termination_Protection"
},
"Disable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": false
},
"ResultPath": null,
"Next": "Should_Terminate_Cluster"
},
"Should_Terminate_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.TerminateCluster",
"BooleanEquals": true,
"Next": "Terminate_Cluster"
},
{
"Variable": "$.TerminateCluster",
"BooleanEquals": false,
"Next": "Wrapping_Up"
}
],
"Default": "Wrapping_Up"
},
"Terminate_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"Next": "Wrapping_Up"
},
"Wrapping_Up": {
"Type": "Pass",
"End": true
}
}
}
我让 Step Functions 控制台为执行此状态机创建一个新的 AWS Identity and Access Management (IAM) 角色。该角色自动包含访问 EMR 所需的所有权限。
此状态机可以使用现有的 EMR 集群,也可创建一个新集群。我可以使用以下输入创建在工作流结束时终止的新集群:
{
"CreateCluster": true,
"TerminateCluster": true
}
要使用现有集群,我需要使用以下句法在集群 ID 中提供输入:
{
"CreateCluster": false,
"TerminateCluster": false,
"ClusterId": "j-..."
}
我们来看看它的工作原理。工作流开始时,Should_Create_Cluster Choice 状态将查看输入以确定它是否应进入 Create_A_Cluster 状态。此时,我使用同步调用 (elasticmapreduce:createCluster.sync) 等待新的 EMR 集群到达 WAITING 状态,然后再继续进入下一个工作流状态。AWS Step Functions 控制台会显示使用到 EMR 控制台的链接创建的资源:

之后,Merge_Results Pass 状态将输入状态与新创建集群的集群 ID 合并,以将其传递至工作流中的下一个步骤。
在开始处理任何数据之前,我使用 Enable_Termination_Protection 状态 (elasticmapreduce:setClusterTerminationProtection) 帮助确保我的 EMR 集群中的 EC2 实例不会因出现意外或错误而关闭。
现在,我已准备好使用 EMR 集群执行某些操作。我的工作流中有三个 EMR 步骤。为简单起见,这些步骤都基于此 Hive 教程。对于每个步骤,我使用 Hive 的类似于 SQL 的界面对一些示例 CloudFront 日志运行查询,并将结果写入 Amazon Simple Storage Service (S3)。在生产使用案例中,您可能有多个 EMR 工具并行处理和分析您的数据(两个或多个步骤同时运行)或具有某些依赖关系(一个步骤的输出是另一个步骤的必要因素)。我们来尝试执行一些类似的操作。
首先我在并行状态下执行 Step_One 和 Step_Two:
- Step_One 作为作业 (
elasticmapreduce:addStep.sync) 同步运行 EMR 步骤。这意味着在继续执行工作流中的下一个步骤之前,执行会等待 EMR 步骤完成(或取消)。您可以有选择地添加超时,以监控 EMR 步骤的执行是否在预期时间范围内。 - Step_Two 正在异步添加 EMR 步骤 (
elasticmapreduce:addStep)。在这种情况下,只要 EMR 回复请求已收到,工作流就会移至下一个步骤。几秒钟后,为了尝试其他集成,我取消了 Step_Two (elasticmapreduce:cancelStep)。这种集成在生产使用案例中可能会非常有用。例如,如果您从并行运行的另一个步骤中收到错误消息,使得继续执行某个 EMR 步骤变得毫无用处,则可取消该步骤。
在这两个步骤都已完成并生成结果之后,我将以作业形式执行 Step_Three,与我为 Step_One 执行的操作类似。当 Step_Three 完成后,我将进入 Disable_Termination_Protection 步骤,因为我已使用集群完成此工作流。
根据输入状态,Should_Terminate_Cluster Choice 状态将进入 Terminate_Cluster 状态 (elasticmapreduce:terminateCluster.sync) 并等待 EMR 集群终止,或直接进入 Wrapping_Up 状态并离开正在运行的集群。
最后,我还要处理 Wrapping_Up 状态。实际上,我在此最终状态下所做工作不多,但我不能从 Choice 状态结束工作流。
在 EMR 控制台中,我看到我的集群和 EMR 步骤的状态:
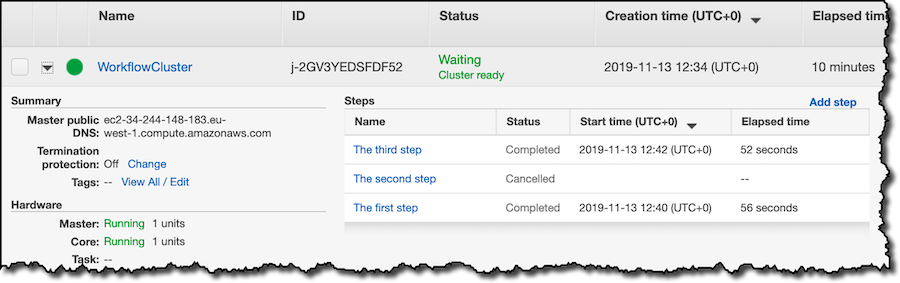
使用 AWS 命令行界面 (CLI),我可以在配置为 EMR 步骤输出的 S3 存储桶中找到我的查询结果:
aws s3 ls s3://MY-BUCKET/MyHiveQueryResults/
...
根据我的输入,EMR 集群在此工作流执行结束时仍在运行。我单击 Create_A_Cluster 步骤中的资源链接转至 EMR 控制台并将其终止。如果您也同时打开此演示,请注意不要让 EMR 集群在您不需要时运行。
现已推出
Step Functions 与 EMR 的集成已在所有区域全面推出。除常规 Step Functions 和 EMR 定价之外,使用此功能不会产生额外费用。
现在,您可以使用 Step Functions 来快速构建复杂的工作流,以便执行 EMR 作业。工作流可以包括并行执行、依赖关系和异常处理。 Step Functions 可以在作业失败后轻松重试,并在出现严重错误后终止工作流,因为您可以指明出错时所发生的情况。欢迎与我分享您将如何使用此功能!
– Danilo