亚马逊AWS官方博客
使用多区域 Amazon EKS 和 Amazon Aurora Global Database 扩展应用程序:第 1 部分
AWS 提供广泛而深入的服务,帮助您在 AWS 遍布全球的多个区域运行和扩展关键工作负载。无论您是需要多区域架构来支持灾难恢复,还是需要将应用程序和后端数据库放在靠近客户的地理位置以减少延迟,AWS 都能为您提供构建块来改善应用程序的可用性、可靠性和延迟。本系列包括两个部分,向您展示如何使用 Amazon Elastic Kubernetes Service(Amazon EKS)在多个区域中运行应用程序。我们使用跨越多个区域的 Amazon Aurora Global Database 作为持久性事务数据存储,并使用 AWS Global Accelerator 在区域之间分配流量。
Kubernetes 声明式系统使其成为编排和操作容器化应用程序的理想平台。在声明式系统中,您声明所需的状态,然后系统观察当前状态和所需状态,确定从当前状态达到所需状态需要的操作。利用 Kubernetes 声明式系统,您可以更轻松地设置应用程序,并让 Kubernetes 管理系统状态。它提供进一步延伸的部署和扩展功能,并自动管理容器化应用程序。Amazon EKS 集群按区域预置的方式可帮助您跨区域部署和管理容器化应用程序,以实现高可用性(HA)、灾难恢复(DR)和缩短延迟。要了解更多信息,请访问使用 Amazon EKS 操作多区域无状态应用程序。
多区域事务性应用程序通常依赖于跨区域低延迟的关系数据库。典型关系数据库的跨区域故障转移通常需要明确的策略、资源以及与应用程序重新配置相关的手动操作。对于整个灾难恢复解决方案而言,管理如此复杂的任务颇具挑战性。
Aurora Global Database 专为全球分布式应用程序设计,允许单个 Amazon Aurora 数据库跨越多个区域。它可以在不影响数据库性能的情况下复制数据,在各个区域实现低延迟的快速本地读取,并针对区域范围的停机提供灾难恢复。
在这篇文章中,您将学习多区域应用程序的架构模式和设计属性。
在下一篇文章中,我们将使用在多区域 Amazon EKS 集群上运行的微服务,以及用于实现事务数据持久性和低延迟本地读取的 Aurora Global Database(PostgreSQL 兼容版),为零售网站实施解决方案。我们还将研究这些微服务如何随着需求的增长而扩展,以及它们如何透明地自动处理所计划的跨区域 Aurora Global Database 故障转移。
设计模式
在本节中,我们将概述两种不同的设计模式:
- 本地读取,全局写入 – 通过这种设计模式,每个区域中的用户和应用程序在各自的区域中执行读取。这些应用程序对最终一致性具有容错能力。但是,此设计仅包含一个写入器,而在两个区域上运行的应用程序都会向该写入器节点发送写入操作。
- 本地读取,本地写入 – 通过这种设计模式,每个区域中的用户和应用程序在各自的区域中执行读取和写入。采用这种模式的数据库会双向复制更改。
在这篇文章中,我们将重点介绍使用本地读取、全局写入设计模式来实施解决方案。
多区域应用程序设计
在本节中,我们将讨论多区域应用程序的各种设计属性。
高可用性
对于企业而言,寻求多区域部署的一个关键原因是暂时性故障和灾难恢复导致的服务和应用程序连续性问题。
Amazon EKS 会自动检测并替换运行状况不佳的控制面板实例。Kubernetes 声明式 DevOps 范例会根据清单中定义的资源所需状态,与其当前状态进行对比,动态地对应用程序采取纠正措施。这就使得应用程序自然而然地具备了抵御组件级故障的能力。
Aurora 设计用于提供 99.99% 的可用性,在一个区域内复制 6 个数据副本,并将数据连续备份到 Amazon Simple Storage Service(Amazon S3)。它可以透明地从物理存储故障中恢复;区域内实例故障转移通常用时不超过 30 秒。
Amazon Aurora Global Database 在区域之间使用异步存储复制,以此来支持跨区域灾难恢复(DR)方案。这样可以实现极低的复制延迟,从而最大限度地减少数据丢失的可能性,以及将数据库故障转移到新的主区域所需的时间。这种数据丢失称为恢复点目标(RPO),它是企业可以容忍的数据丢失量;恢复时间目标(RTO)是指系统重新开始接受来自应用程序的正常请求所需的时间。要了解有关 Aurora Global Database 的更多信息,请参阅使用 Amazon Aurora Global Database。
跨区域故障转移到 Aurora Global Database 中的某个辅助数据库通常用时不到一分钟。使用 Aurora 全球数据库,您可以选择两种不同的故障转移途径:
- 托管的计划故障转移 – 使用托管的计划故障转移,您可以故障转移到辅助 AWS 区域同时维护复制拓扑,而无需重新创建任何辅助集群。其 RPO 为 0(无数据丢失),因为它会将辅助数据库集群与主数据库集群同步,然后再执行其他任何更改。故障转移的持续时间(RTO)取决于主 AWS 区域与辅助 AWS 区域之间的复制滞后量。
- 手动的计划外故障转移 – 对于计划外故障转移,在极少数情况下出现主区域停机时,您需要手动分离并提升辅助区域中的一个 Aurora 集群。然后,您将重新创建 Aurora Global Database 并恢复复制拓扑。数据库的 RTO 通常少于 1 分钟。RPO 取决于发生故障时,网络上 Aurora 存储的复制滞后。您可以监控 Amazon CloudWatch
AuroraGlobalDBReplicationLag指标,以此来监控辅助区域中的 Aurora 集群落后于主区域中集群的程度。
数据复制
复制延迟会影响发生故障时跨区域恢复服务的速度。同样重要的是,数据复制速度要足够快,以满足应用程序的本地读取 SLA 要求。Aurora 副本与同一区域中的主实例共用相同的数据卷;该区域内几乎没有复制延迟。我们通常观察到的延迟处于几十毫秒量级。Aurora Global Database 辅助区域中 Aurora 副本的延迟通常不到一秒。
联网
您可以使用 AWS Transit Gateway 实现区域内 VPC 对等连接,通过专用网络,连接托管在多个 AWS 区域中 Amazon EKS 集群上的应用程序。
可扩展性
您的应用程序和数据库服务应具有内在的弹性,以便随着需求的增加自动扩展,并在负载减少时缩减。
在主区域内,Aurora 支持三个可用区中最多 15 个低延迟只读副本。我们可以使用 Aurora Global Database,配置多达 5 个辅助区域以及每个辅助区域中最多 16 个只读副本。借助 Aurora Global Database,您可以跨区域扩展数据库读取,并将应用程序放在靠近用户的位置。
Amazon EKS 支持 Horizontal Pod Autoscaler,可在 CPU 达到阈值时扩展容器化应用程序。
流量路由
出现灾难情况时的自动流量路由和服务恢复是企业面临的另一项挑战。
Aurora Global Database 托管的计划内和计划外故障转移需要重新配置应用程序,以便将所有写入操作发送到新主区域中的 Aurora 数据库集群终端节点。您可以将应用程序配置为使用 Amazon Route 53 DNS 别名记录,并将其更新为指向新的写入器终端节点,从而尽可能减少应用程序的重新配置。但是,DNS 别名记录更改传播通常会因生存时间(TTL, Time To Live)而延迟,并影响整体故障转移时间。此外,故障转移期间会断开数据库连接,应用程序应重新建立连接。您可以在此 GitHub 存储库中找到示例解决方案。
在这篇文章中,我们使用 PgBouncer 数据库连接入池程序,在计划内 Aurora Global Database(PostgreSQL 兼容版)故障转移期间透明地处理上述限制。它可帮助在故障转移期间保持数据库连接。我们使用 Amazon EventBridge 和 AWS Lambda 在故障转移期间自动处理 PgBouncer 重新配置。您可以使用开源解决方案,例如适用于 Aurora 集群 MySQL 兼容版的 ProxySQL。要了解更多信息,请参阅 使用 Amazon Aurora PostgreSQL 读取器设置高可用的 PgBouncer 和 HAProxy。
您可以使用 AWS Global Accelerator 或 Amazon CloudFront 将连接路由到在不同区域中提供的应用程序。
解决方案概览
以下架构图概述了本文中的解决方案:
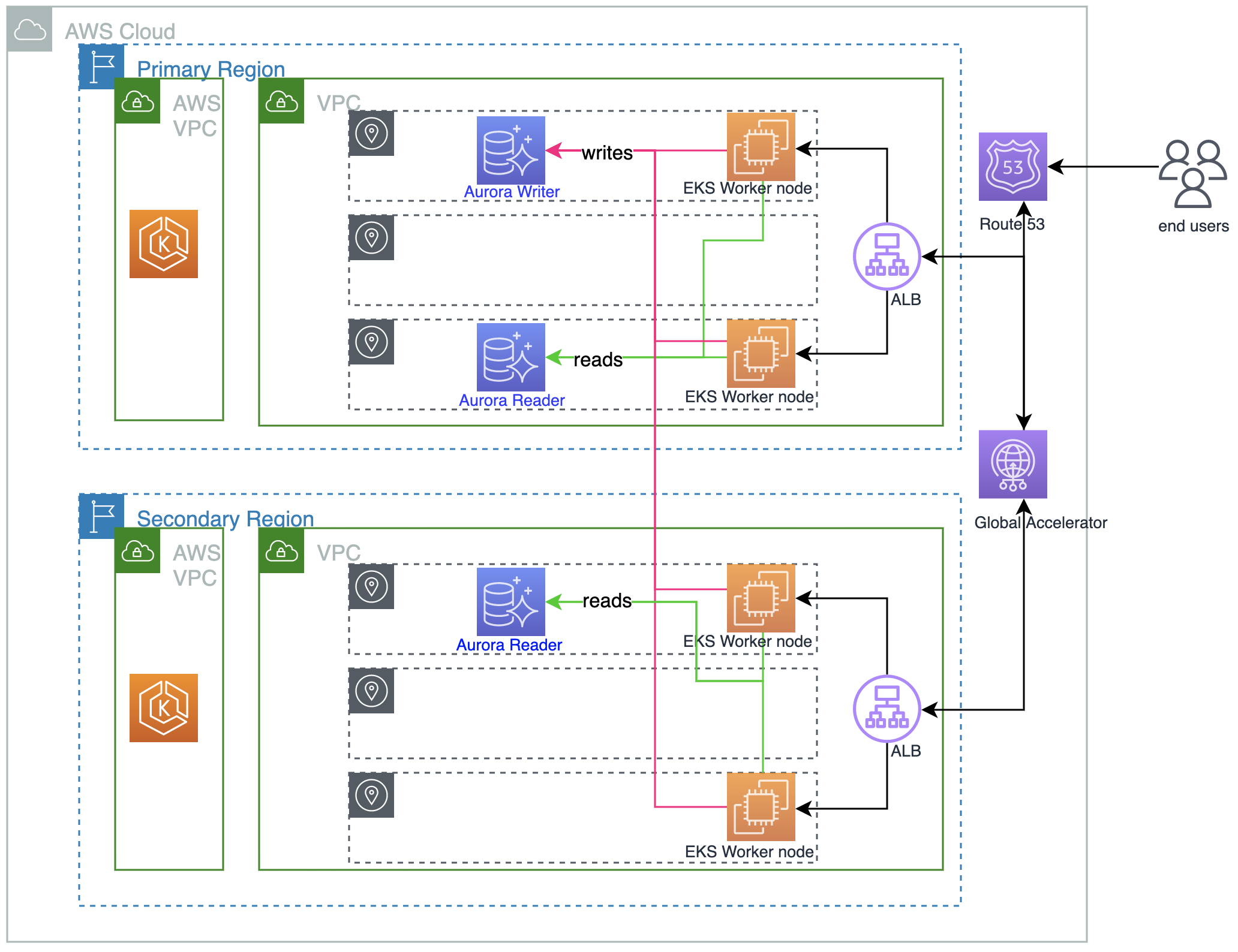
我们使用本地读取和全局写入设计模式,将两个区域配置为双活。首先,我们在区域 us-east-2 和 us-west-2 中,创建兼容 PostgreSQL 的 Amazon EKS 集群和 Aurora Global Database。我们使用 PgBouncer 进行连接入池。我们还为 PgBouncer 实施了一个工作流,以处理计划内的 Aurora Global Database 故障转移。然后,我们将应用程序堆栈(包括有状态和无状态容器化应用程序)部署到两个区域中的 Amazon EKS 集群,并使用 Application Load Balancer 在相应区域中公开应用程序终端节点。最后,我们将负载均衡器的 Global Accelerator 配置为终端节点。
小结
在这篇文章中,您学习了架构模式和多区域应用程序设计。
在本系列的第 2 部分中,我们将讨论如何使用 Amazon EKS、Global Accelerator 和 Aurora Global Database,为多区域应用程序扩展和构建弹性及自动故障转移。
我们欢迎您的反馈,请在评论部分提出您的意见或问题。