Amazon Web Services ブログ
Amazon DataZone の一般提供を開始 – 組織の境界を越えたデータプロジェクトでの共同作業
10月4日、組織内のデータプロデューサーとコンシューマーの間でデータをカタログ化、検出、分析、共有、管理するための新しいデータ管理サービスである Amazon DataZone の一般提供の開始を発表しました。
 AWS re:Invent 2022 では Amazon DataZone についての事前発表を行い、2023 年 3 月にはパブリックプレビューをリリースしました。
AWS re:Invent 2022 では Amazon DataZone についての事前発表を行い、2023 年 3 月にはパブリックプレビューをリリースしました。
前回の re:Invent の基調講演で、AWS の Databases, Analytics, and Machine Learning 担当バイスプレジデントである Swami Sivasubramanian は次のように述べました。「幸いなことに、私は DataZone の初期ユーザーとして、AWS の週次のビジネスレビューミーティングを開催してきました。このミーティングでは、ビジネス戦略の参考とするために、販売パイプラインと収益予測からのデータを集めています」。
基調講演中、Amazon DataZone の製品責任者である Shikha Verma が主導したデモでは、組織がこの製品を利用してより効果的な広告キャンペーンを作成し、データを最大限に活用する方法を示すためにデモンストレーションが行われました。
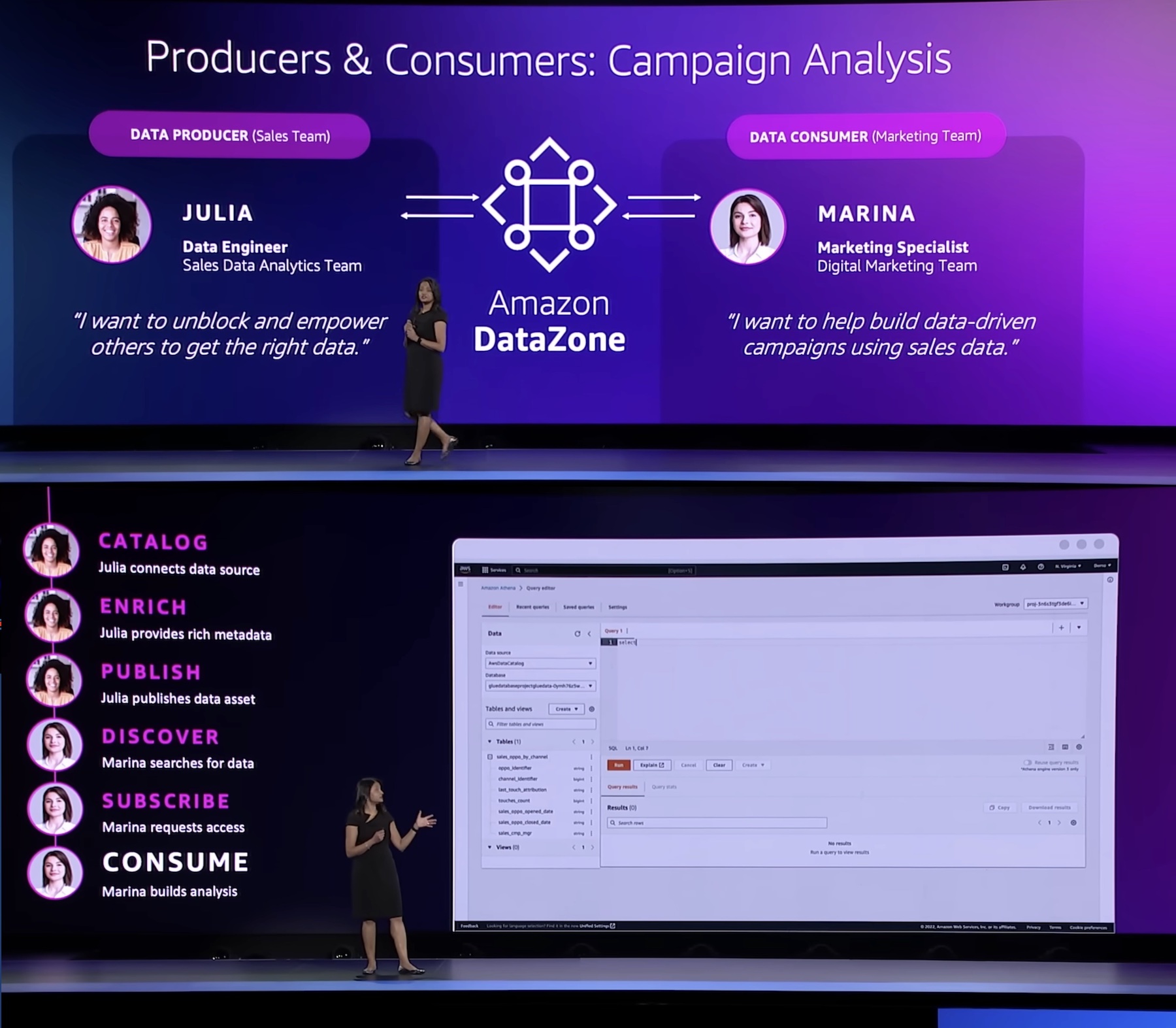
「すべての企業は、さまざまなデータストアに存在するデータを所有および利用する複数のチームで構成されています。データ担当者はこのデータをまとめなければなりませんが、このデータにアクセスしたり、データを把握したりするための簡単な方法を持っていません。DataZone は、データプロデューサーからコンシューマーまで、組織内の誰もが統制された方法でデータにアクセスしたり、データを共有したりできる統合環境を提供します」
データプロデューサーは Amazon DataZone を利用して、AWS Glue データカタログおよび Amazon Redshift テーブルからの構造化データアセットをビジネスデータカタログに追加します。データコンシューマーは、データカタログ内のデータアセットを検索およびサブスクライブし、他のビジネスユースケースの協力者と共有します。コンシューマーは、Amazon DataZone ポータルから直接アクセスできるツール (Amazon Redshift や Amazon Athena クエリエディタなど) を使用して、サブスクライブしたデータアセットを分析できます。統合されたパブリッシュ-サブスクライブワークフローは、プロジェクト全体でのアクセス監査機能を提供します。
Amazon DataZone のご紹介
Amazon DataZone についてまだなじみがないお客様のために、その主要な概念と機能をご紹介します。
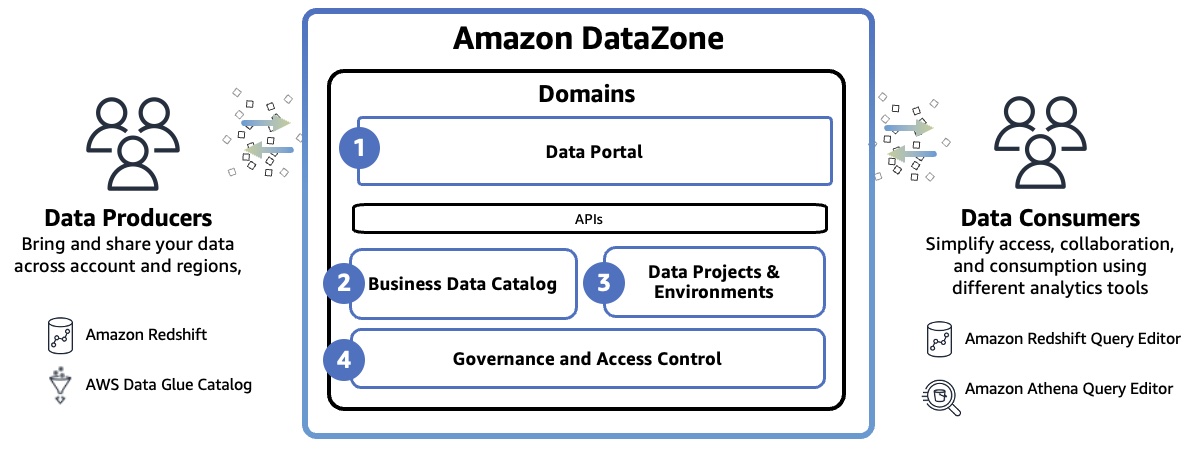
Amazon DataZone ドメインは、独自のデータ (独自のデータアセットや、データまたはビジネス用語の独自の定義を含む) を管理でき、独自の管理基準を設けている場合がある、組織内の事業部門 (LOB) やビジネス領域の明確な境界を表します。ドメインには、データポータル、ビジネスデータカタログ、プロジェクトや環境、組み込みワークフローなどのすべてのコアコンポーネントが含まれます。
- データポータル (AWS マネジメントコンソールの外部) – これは、さまざまなユーザーがセルフサービスの形式でデータのカタログ化、検出、管理、共有、分析を行うことができるウェブアプリケーションです。データポータルは、AWS IAM アイデンティティセンターを介して、AWS Identity and Access Manager (IAM) 認証情報、または ID プロバイダーから提供される既存の認証情報を使用してユーザーを認証します。
- ビジネスデータカタログ – カタログでは、分類法またはビジネス用語集を定義できます。このコンポーネントを使用すると、ビジネスコンテキストを含めて組織全体のデータをカタログ化し、組織内の全員がデータを迅速に検索および理解できるようにすることができます。
- データプロジェクトと環境 – プロジェクトを使用して、ユーザー、データアセット、分析ツールのビジネスユースケースベースのグループを作成することで、AWS 分析へのアクセスを簡素化できます。Amazon DataZone のプロジェクトは、プロジェクトメンバーが共同作業、データ交換、データアセットの共有を行うことができるスペースを提供します。プロジェクト内では、分析ツールやストレージなどの必要なインフラストラクチャをプロジェクトメンバーに提供する環境を作成して、プロジェクトメンバーが新しいデータを簡単に生成したり、アクセス権のあるデータを利用したりできるようにすることができます。
- ガバナンスとアクセスコントロール – 組織全体のユーザーがカタログ内のデータへのアクセスをリクエストし、データの所有者がそれらのサブスクリプションリクエストを確認して承認することを可能にする、組み込みワークフローを使用できます。サブスクリプションリクエストが承認されると、Amazon DataZone は、AWS Lake Formation や Amazon Redshift などの基盤となるデータストアで許可を管理することで、自動的にアクセスを付与できます。
詳細については、「Amazon DataZone の用語と概念」をご覧ください。
Amazon DataZone の開始方法
まず、製品マーケティングチームが製品の導入を促進するキャンペーンを実行したいというシナリオを考えてみましょう。これを行うには、営業チームが所有する製品販売データを分析する必要があります。このチュートリアルでは、データプロデューサーとして機能する営業チームが Amazon DataZone で販売データを公開します。その後、データコンシューマーとして機能するマーケティングチームが販売データをサブスクライブし、キャンペーン戦略を構築するためにそのデータを分析します。
DataZone の仕組みを理解するために、Amazon DataZone の開始方法ガイドを要約したものを見てみましょう。
1.ドメインを作成する
DataZone の利用を初めて開始する際には、まずドメインと、ビジネスデータカタログ、プロジェクト、環境などのすべてのコアコンポーネントをデータポータルに作成して、それらのコンポーネントがそのドメイン内に存在するようにします。Amazon DataZone コンソールに移動し、[ドメインを作成] を選択します。
[ドメイン名] と説明を入力し、他の値はすべてデフォルトのままにします。
例えば、[サービスアクセス] セクションで、デフォルトで [新しいロールを作成して使用] を選択すると、Amazon DataZone は、DataZone がドメイン内のユーザーに代わって API 呼び出しを実行することを認可するために必要な許可を持つ新しいロールを自動的に作成します。DataZone がすべての設定ステップを実行できる Quick Setup オプションのチェックをオンにします。
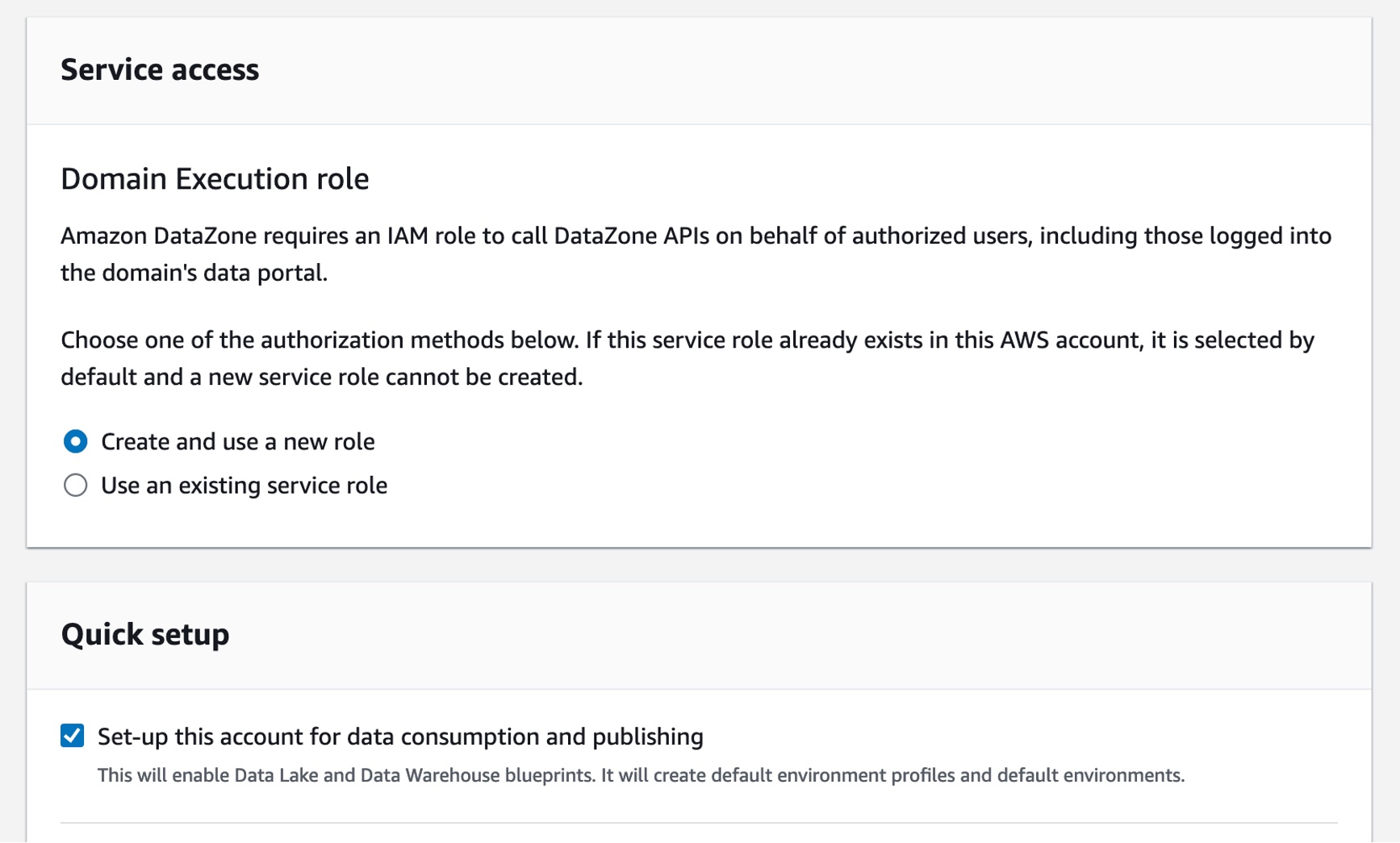
最後に、[ドメインを作成] を選択します。Amazon DataZone は必要な IAM ロールを作成し、このドメインが AWS Glue データカタログ、Amazon Redshift、Amazon Athena などのアカウント内のリソースを使用できるようにします。ドメインの作成が完了するまでに数分かかる場合があります。ドメインのステータスが [使用可能] になるまで待ちます。
2.データポータルでプロジェクトと環境を作成する
ドメインが正常に作成されたらそのドメインを選択し、ドメインの概要ページでルートドメインのデータポータル URL を確認して書き留めます。この URL を使用して、Amazon DataZone データポータルにアクセスできます。[データポータルを開く] を選択します。
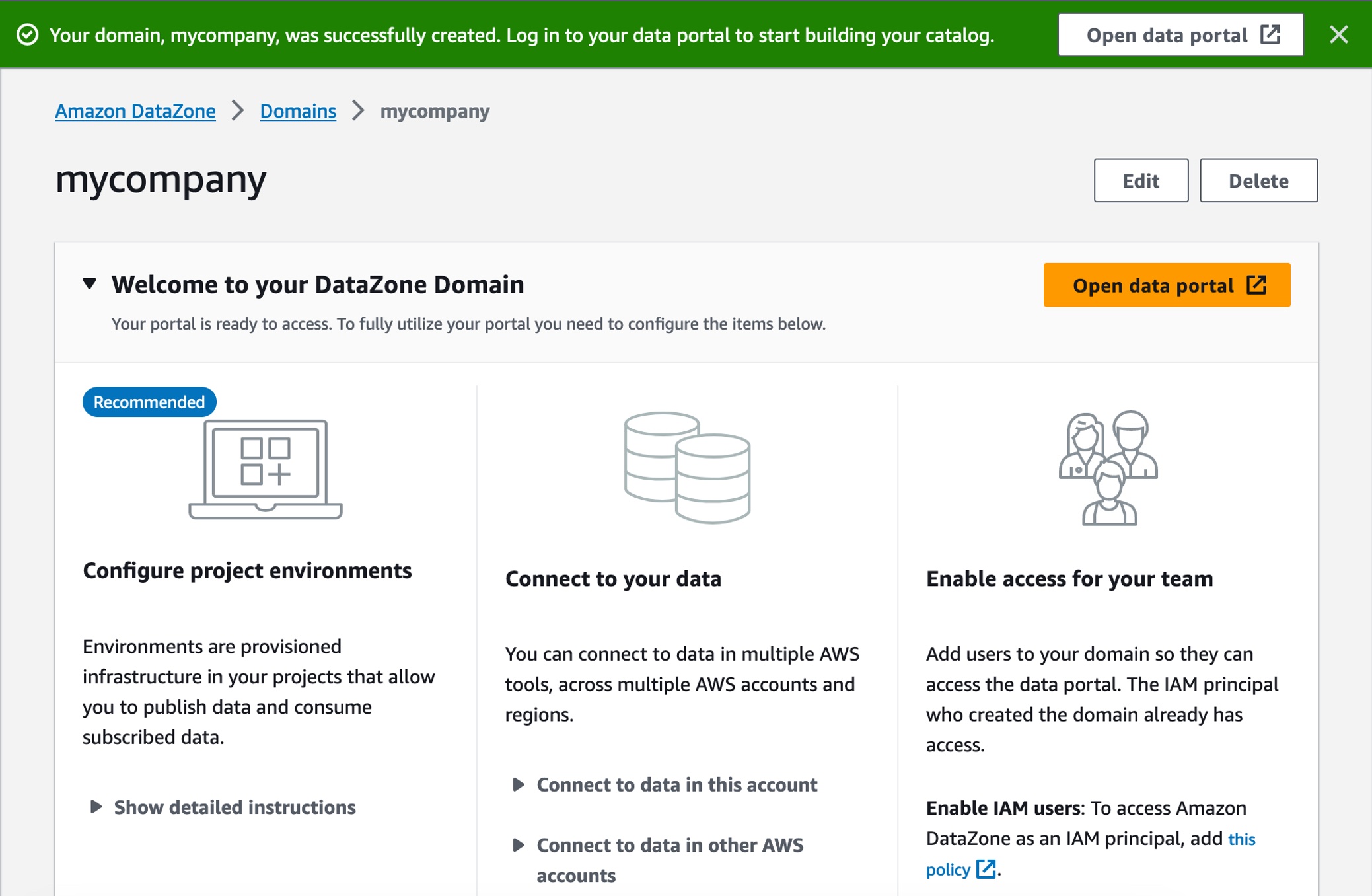
営業チームとして新しいデータプロジェクトを作成して販売データを公開するには、[プロジェクトを作成] を選択します。

ダイアログボックスで、[名前] として「Sales producer project」と入力し、このプロジェクトの [説明] を入力して、[作成] を選択します。

プロジェクトを作成したら、このプロジェクトでデータおよび分析ツール (Amazon Athena や Amazon Redshift など) を使用するための環境を作成する必要があります。概要ページで、または [環境] タブをクリックした後、[環境を作成] を選択します。

[名前] として「publish-environment」と入力し、この環境の [説明] を入力して、[環境プロファイル] を選択します。環境プロファイルは、プロジェクトに追加される AWS アカウント、リージョン、VPC の詳細、リソースやツールなど、環境を作成するために必要となる技術的な詳細が含まれる事前定義済みのテンプレートです。
いくつかのデフォルトの環境プロファイルを選択できます。DataLakeProfile を選択すると、Amazon S3 および AWS Glue ベースのデータレイクからデータを公開できるようになります。また、Amazon Athena を利用してアクセスできる AWS Glue テーブルに対するクエリも簡素化されます。

次に、オプションのパラメータをすべて無視して、[環境を作成] を選択します。環境が IAM ロール、Amazon S3 サフィックス、AWS Glue データベース、Athena ワークグループなどの特定のリソースを AWS アカウントに作成するのに約 1 分かかります。これにより、プロジェクトのメンバーがデータレイクでデータを生成および利用することがより容易になります。
3.データポータルでデータを公開する
AWS Glue テーブルでデータを公開する環境を作成できました。Amazon Athena でこのテーブルを作成するには、[環境] ページの右側にある [データのクエリ] (Athena のリンクが設定されています) を選択します。
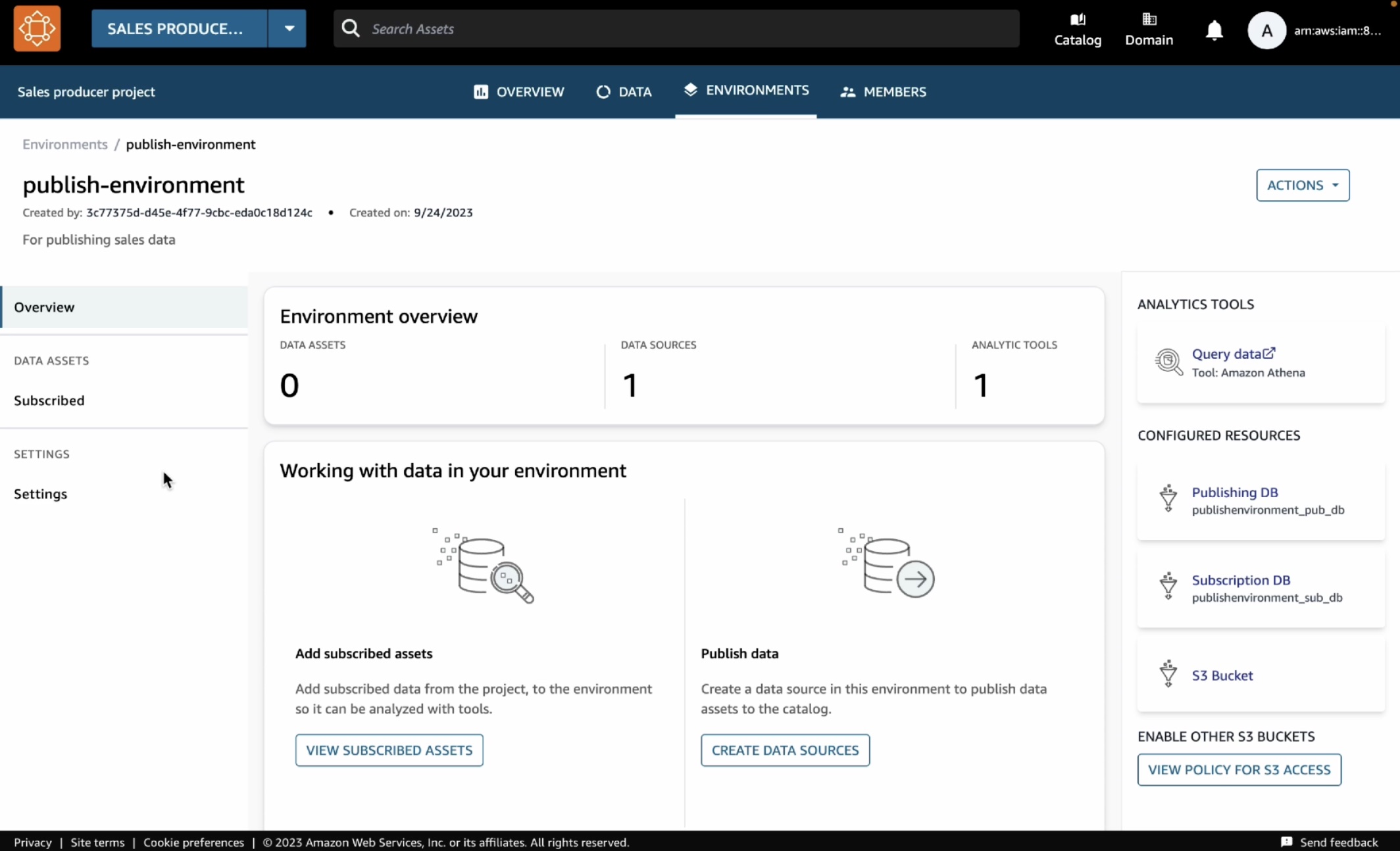
これにより、Athena クエリエディタが新しいタブで開きます。データベースのドロップダウンから publishenvironment_pub_db を選択し、次のクエリをクエリエディタに貼り付けます。これにより、環境の AWS Glue データベースに catalog_sales というテーブルが作成されます。
CREATE TABLE catalog_sales AS
SELECT 146776932 AS order_number, 23 AS quantity, 23.4 AS wholesale_cost, 45.0 as list_price, 43.0 as sales_price, 2.0 as discount, 12 as ship_mode_sk,13 as warehouse_sk, 23 as item_sk, 34 as catalog_page_sk, 232 as ship_customer_sk, 4556 as bill_customer_sk
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561ドロップダウンメニューに 2 つのデータベースが表示されます。publishenvironment_pub_db は、新しいデータを生成し、それを DataZone カタログに公開することを選択するためのスペースを提供します。もう 1 つの publishenvironment_sub_db は、プロジェクトメンバーがプロジェクト内のカタログのデータをサブスクライブまたはアクセスする場合に使用します。
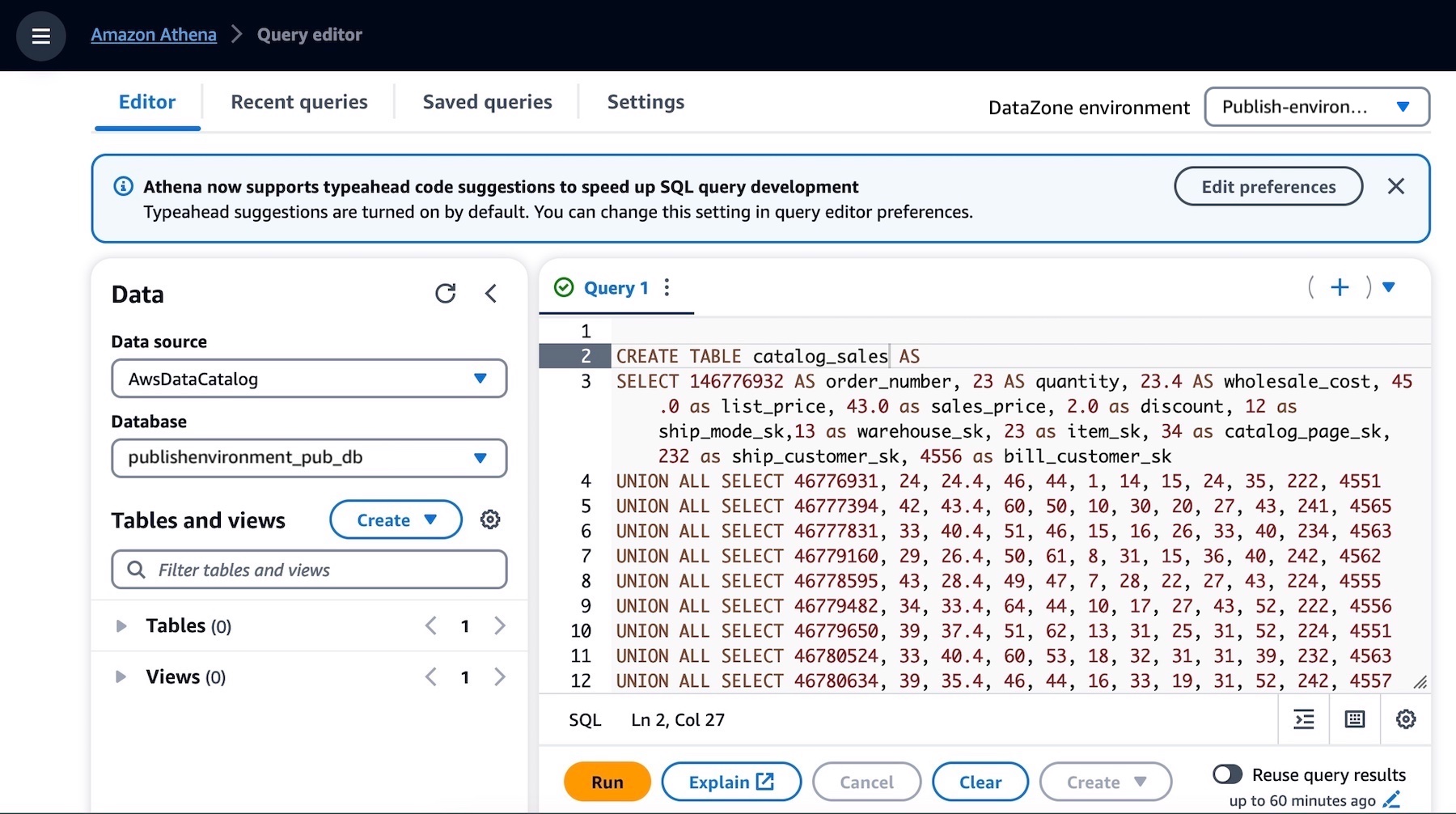
catalog_sales テーブルが正常に作成されたことを確認してください。これで、Amazon DataZone カタログに公開できるデータアセットが完成しました。
データプロデューサーは、データポータルに戻って、このテーブルを DataZone カタログに公開できます。上部のメニューで [データ] タブを選択し、左側のナビゲーションペインで [データソース] を選択します。
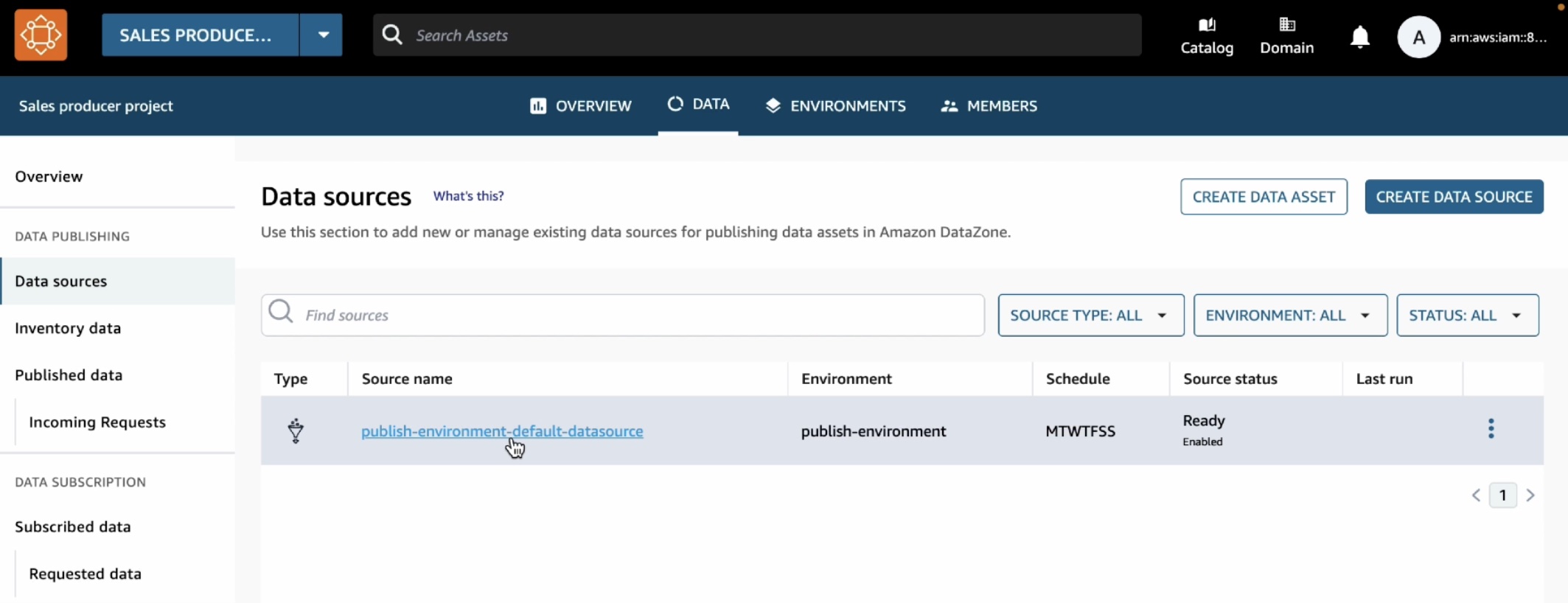
環境内には、自動的に作成されたデフォルトのデータソースがあります。このデータソースを開くと、catalog_sales テーブルを作成したばかりの環境の公開データベースが表示されます。
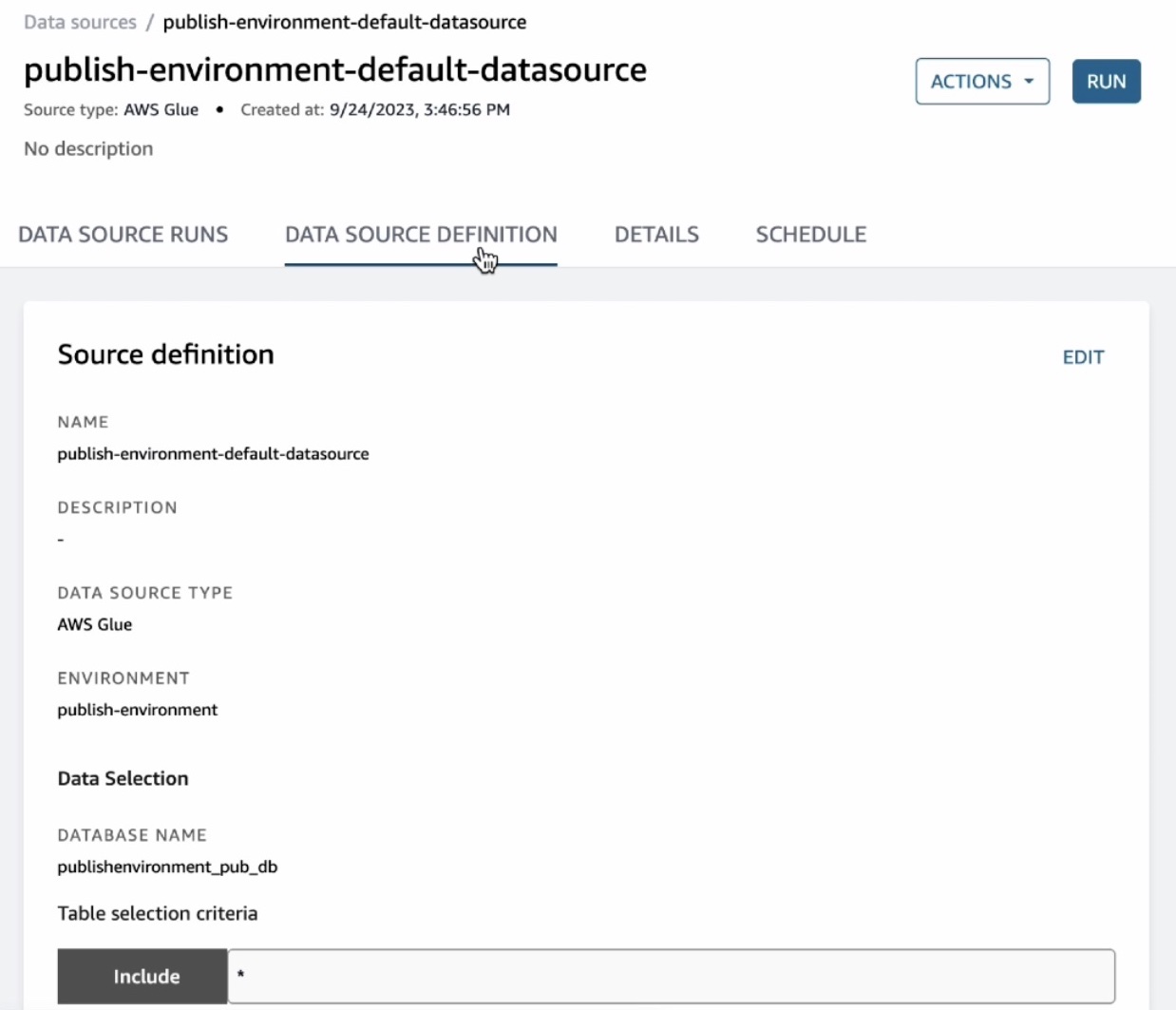
このデータソースは、公開データベース内で見つかったすべてのテーブルを DataZone に取り込みます。デフォルトでは、自動メタデータ生成が有効になっています。これは、データソースが DataZone に取り込むアセットが、そのアセットのテーブルと列のビジネス名を自動的に生成することを意味します。このデータソースで [実行] を選択します。
データソースの実行が完了すると、[データソースの実行] に catalog sales テーブルが表示されます。
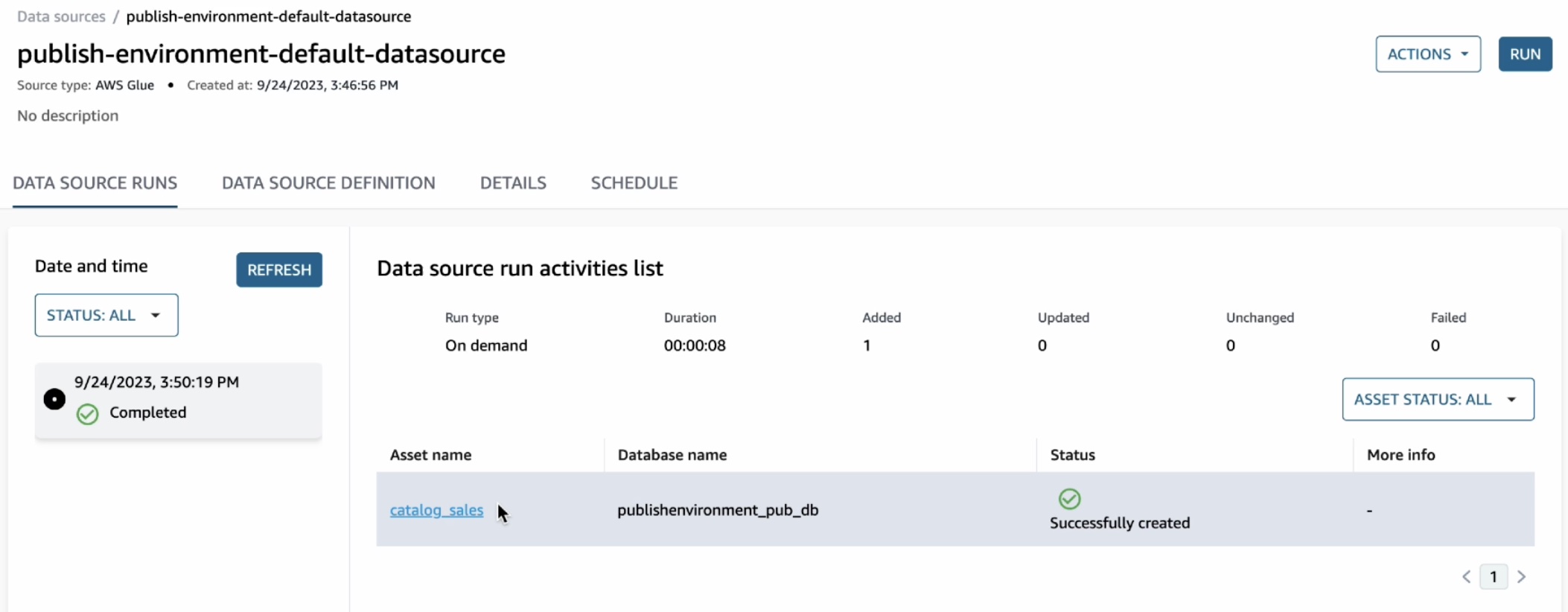
このアセットを開くと、テーブルのスキーマや、他のいくつかの技術的な詳細 (AWS アカウント、リージョン、データの物理的な場所など) を含む技術メタデータを、公開ジョブが自動的に抽出しているのを確認できます。
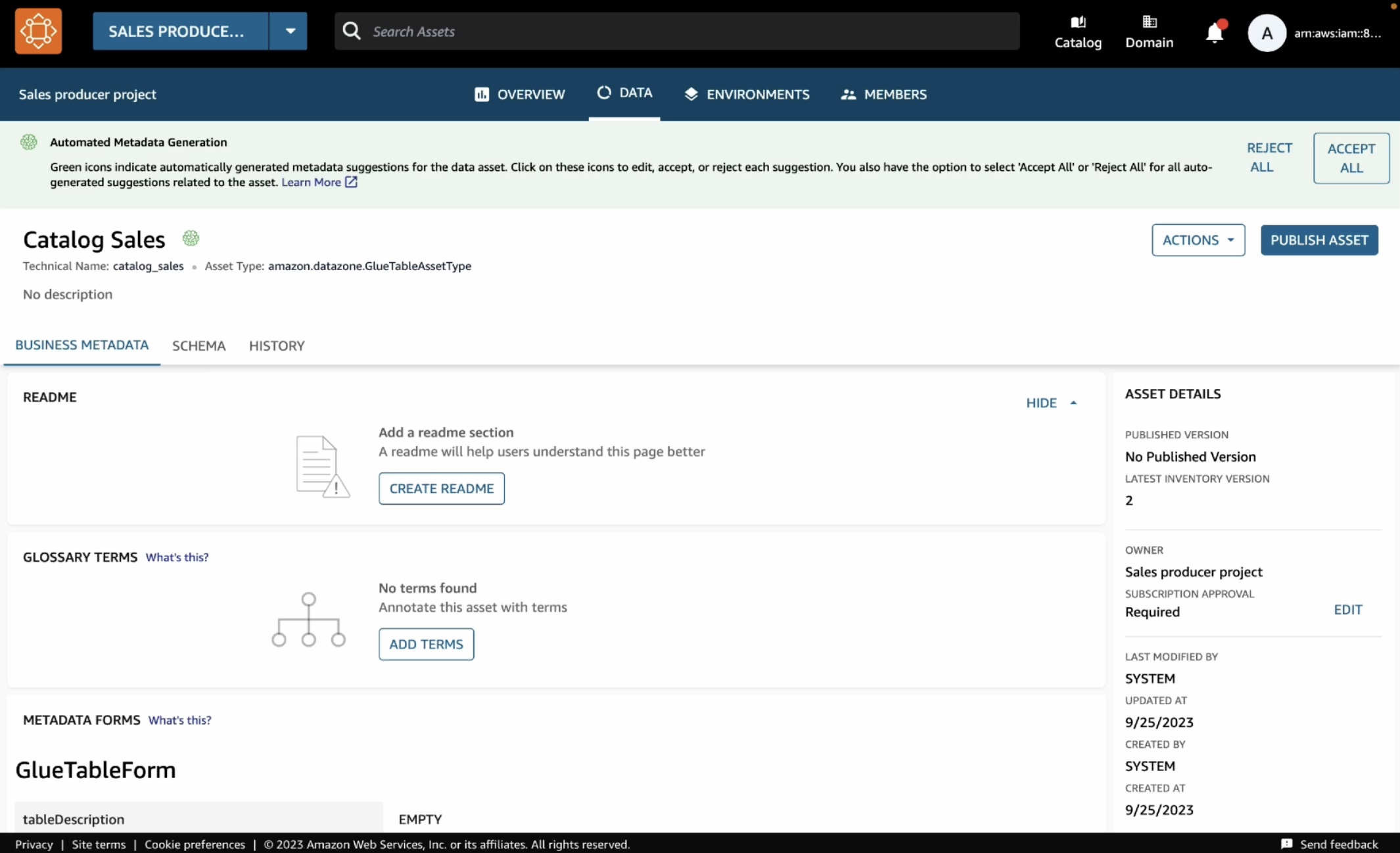
これらのメタデータが正しいと思われる場合は、各推奨項目の脳のアイコンをクリックするか、またはすべての推奨項目について [すべて承認] ボタンをクリックするだけで、これらの推奨項目を承諾できます。公開する準備ができたら、[アセットを公開] を選択し、ダイアログボックスで再確認します。
4.データコンシューマーとしてデータをサブスクライブする
次に、役割をマーケティングチームに切り替えて、このテーブルのサブスクリプションまたはアクセスをリクエストする方法を見てみましょう。データコンシューマーとして、前と同じステップを繰り返して「Marketing consumer project」という新しいプロジェクトと「subscriber-environment」という新しい環境を作成します。
新しく作成したプロジェクトで、検索バーに「catalog sales」と入力すると、公開されたテーブルが検索結果に表示されます。[カタログ販売データ] を選択します。
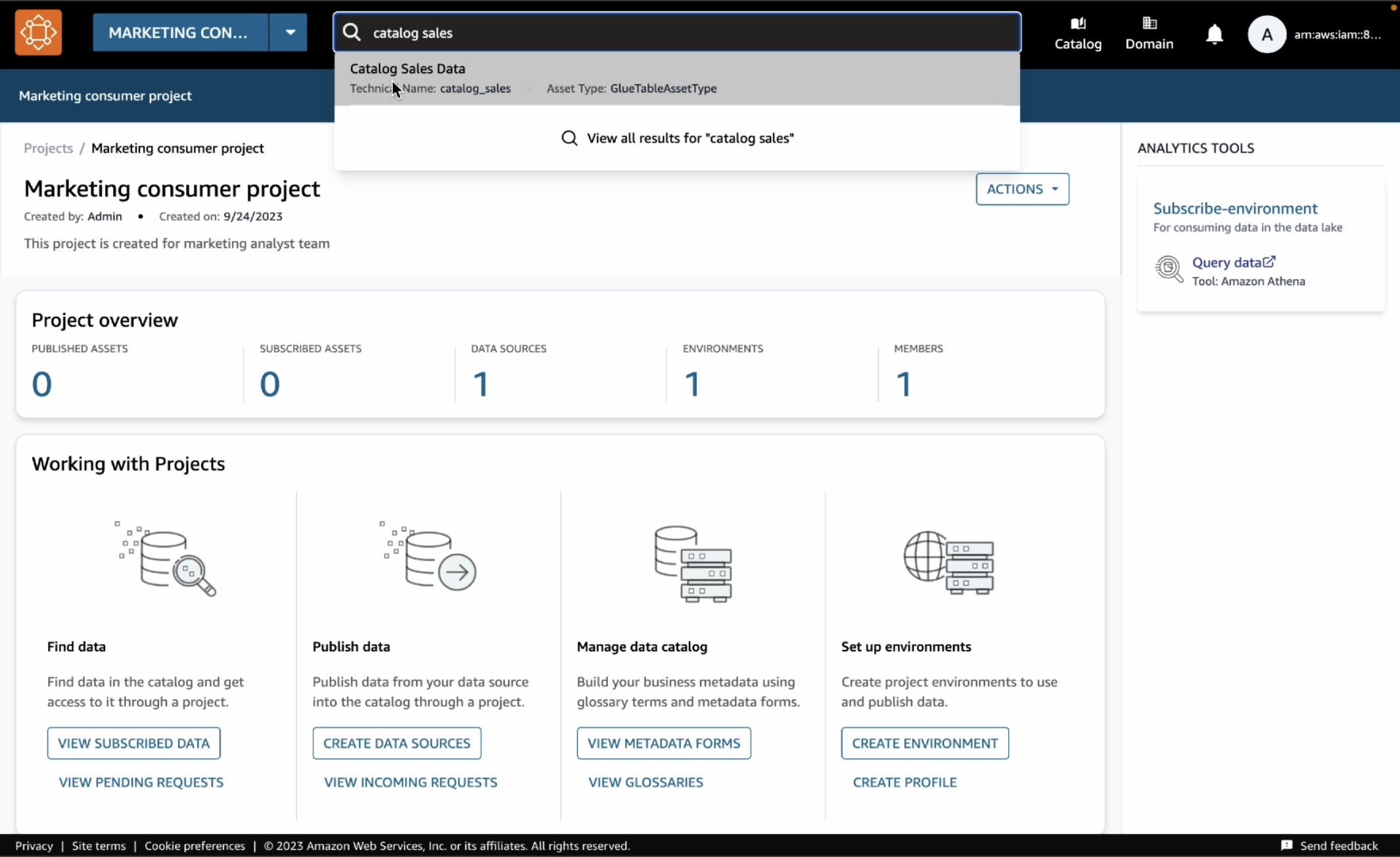
カタログで、[サブスクライブ] を選択します。
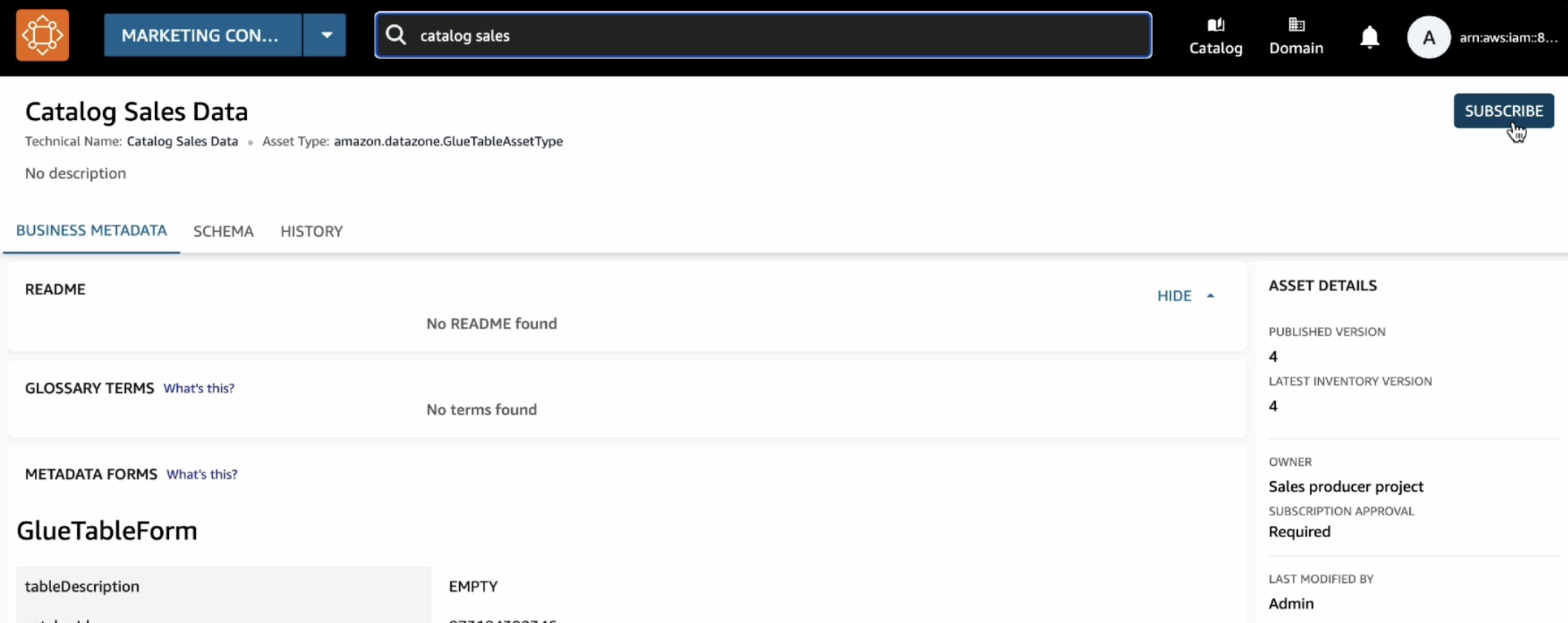
[カタログ販売データをサブスクライブ] ウィンドウで、マーケティングコンシューマープロジェクトを選択し、サブスクリプションリクエストの理由を入力して、[サブスクライブ] を選択します。
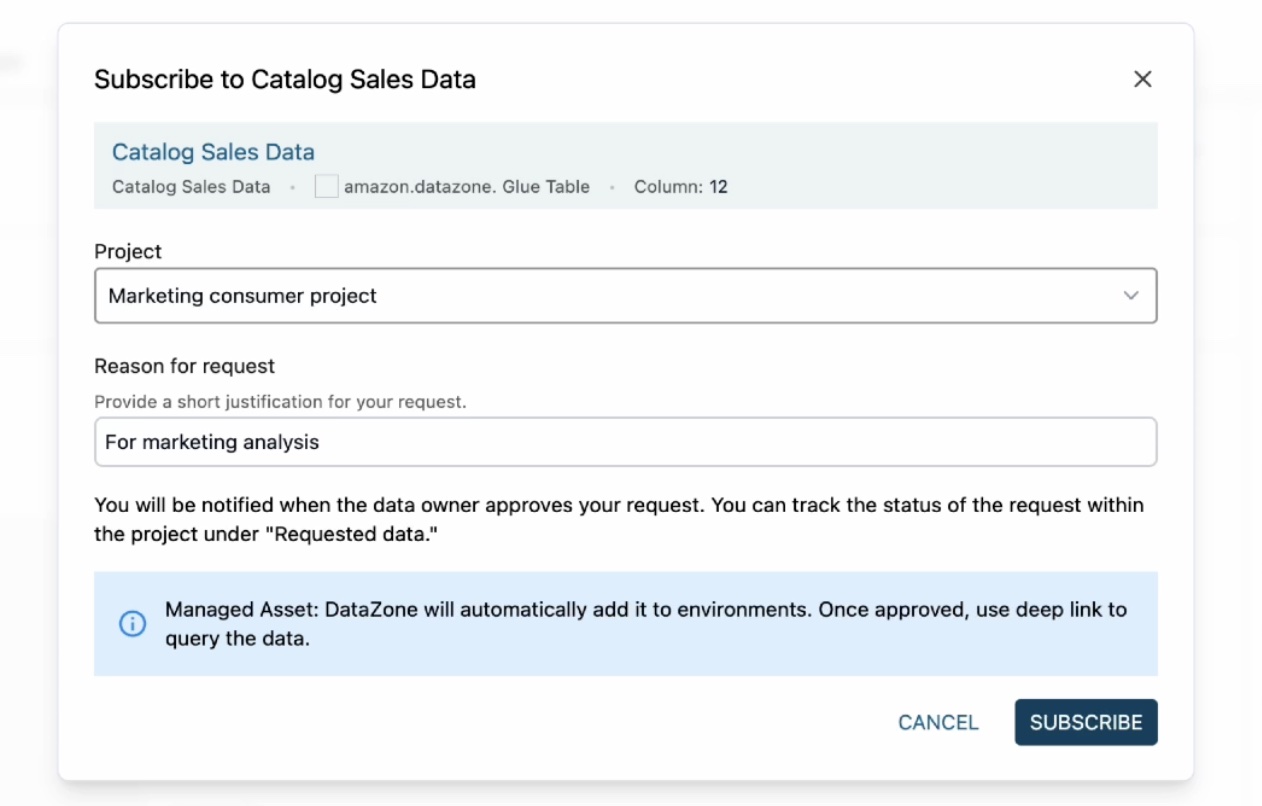
データプロデューサーとしてサブスクリプションリクエストを受け取ると、セールスプロデューサープロジェクトのタスクを通じて通知されます。ここではサブスクライバーとパブリッシャーの両方の役割を担っているため、通知が表示されます。
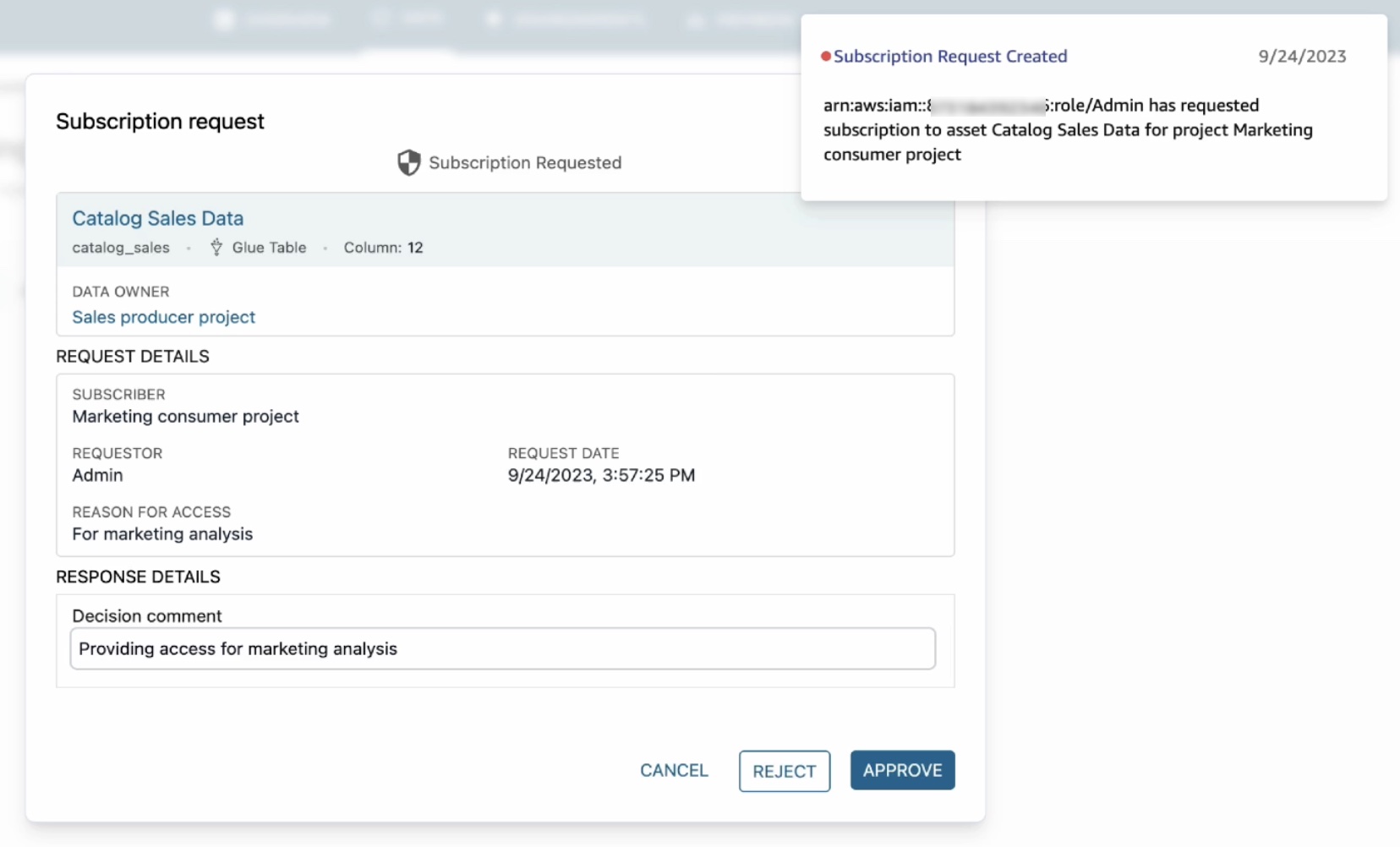
この通知をクリックすると、アクセスをリクエストしたプロジェクト、リクエストを実行したユーザー、およびアクセスが必要な理由を含むサブスクリプションリクエストが開きます。[承認] を選択し、承認の理由を入力します。
サブスクリプションが承認されたので、マーケティングコンシューマープロジェクトでカタログ販売データを表示できるようになりました。これを確認するには、トップメニューの [データ] タブを選択し、左側のナビゲーションペインで [データソース] を選択します。
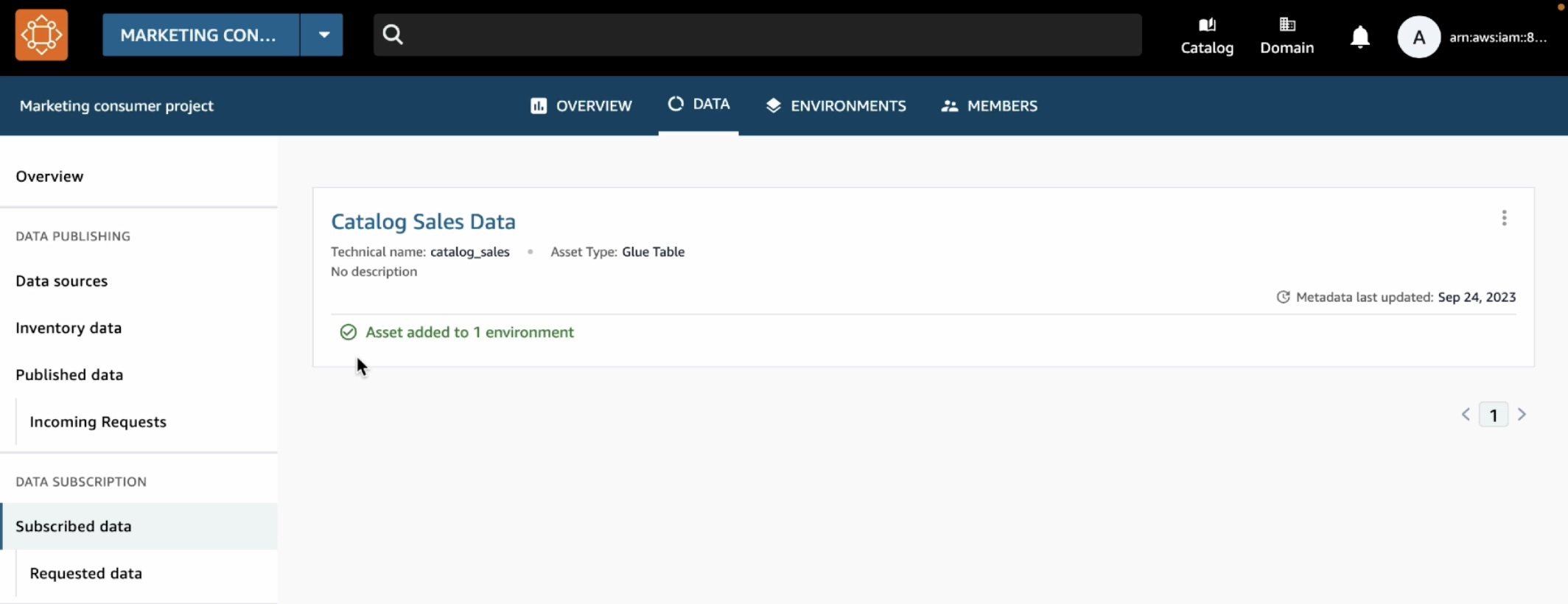
サブスクライブデータを分析するには、トップメニューの [環境] タブを選択し、マーケティングコンシューマープロジェクトで作成した Subscribe-environment を選択します。右側のペインに新しい [データのクエリ] リンクが表示されます。
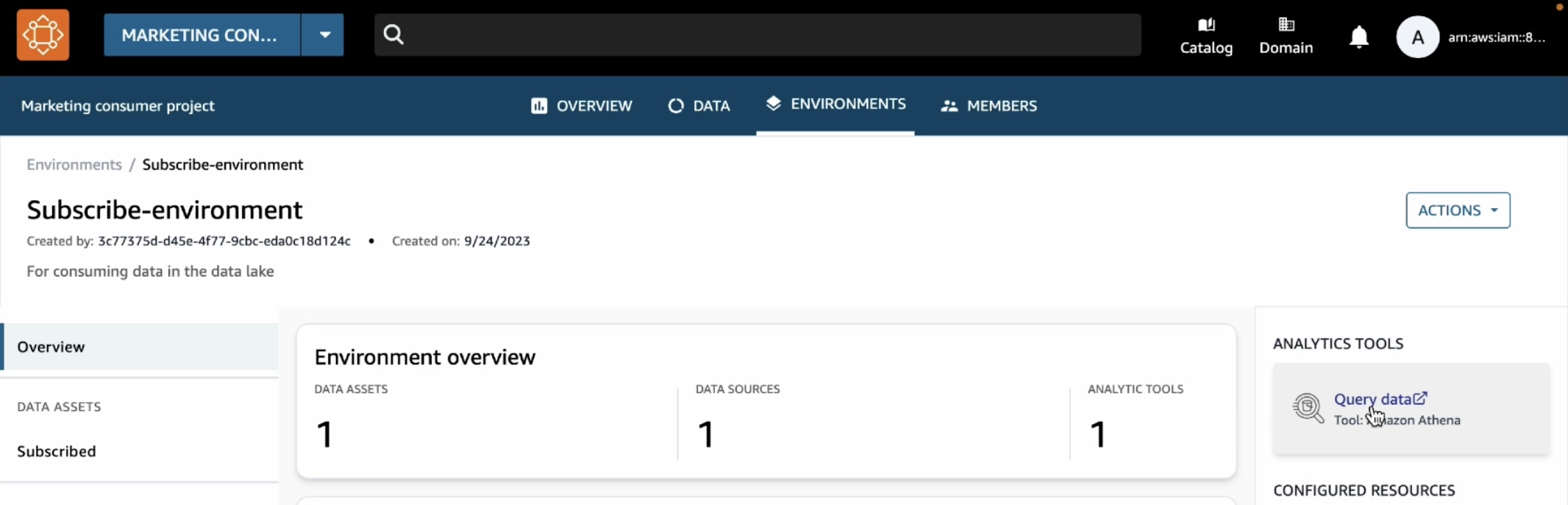
カタログ販売テーブルがサブスクリプションデータベースの下に表示されていることがわかります。
このテーブルにアクセスできることを確認するには、テーブルをプレビューして、クエリが正常に実行されることを確認します。
これにより、Athena クエリエディタが新しいタブで開きます。データベースのドロップダウンから subscribeenvironment_sub_db を選択し、クエリエディタにクエリを入力します。
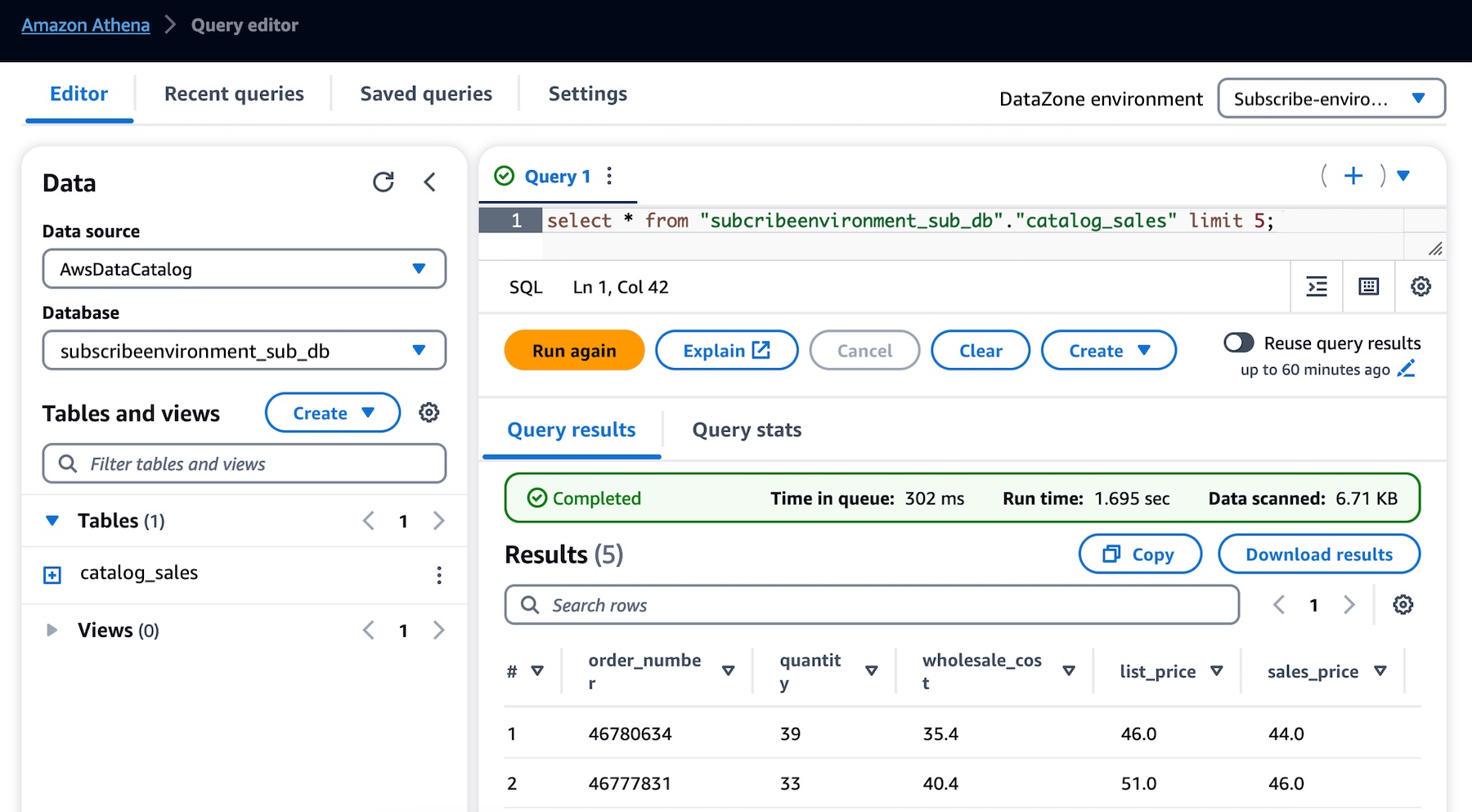
これで、コンシューマー (マーケティングチーム) としてサブスクライブし、プロデューサー (営業チーム) によってビジネスデータカタログに公開された販売データテーブルに対してクエリを実行できるようになりました。
AWS Glue テーブルや Amazon Redshift テーブルおよびビューの公開などの詳細なデモについては、YouTube のプレイリストをご覧ください。
GA での新機能
プレビュー中、お客様から多くの関心とすばらしいフィードバックをお寄せいただきました。少し時間を割いてそれらの機能を確認し、いくつかの改善点をご紹介します。
エンタープライズ対応ビジネスカタログ – ビジネスコンテキストを追加し、組織内の全員がデータを検出できるようにするために、自動メタデータ生成を使用してカタログをカスタマイズできます。自動メタデータ生成では、機械学習を使用して、データアセットと、それらのアセット内の列のビジネス名を自動的に生成します。また、メタデータのキュレーション機能も改善しました。GA では、複数のビジネス用語集の用語をアセットにアタッチしたり、用語集の用語をアセット内の個別の列にアタッチしたりできます。
データユーザー向けのセルフサービス – データの自律性を提供して、ユーザーがデータを公開および利用できるようにするために、API を使用してあらゆるタイプのアセットをカスタマイズし、カタログに取り込むことができます。データパブリッシャーは、取り込みジョブを通じてメタデータの検出を自動化することも、Amazon Simple Storage Service (Amazon S3) からファイルを手動で公開することもできます。データコンシューマーは、ファセット検索を使用して、データを迅速に検索および理解できます。ユーザーは、システムの更新や実行すべきアクションについて通知を受けることができます。これらのイベントは、アクションをカスタマイズするために Amazon EventBridge を利用してお客様のイベントバスに出力されます。
分析へのアクセスの簡素化 – GA では、プロジェクトはビジネスユースケースベースの論理コンテナとして機能します。プロジェクトを作成し、特定のビジネスユースケースに基づいてユーザー、データ、分析ツールをグループ化して共同作業できます。プロジェクト内では、分析ツールやストレージなどの必要なインフラストラクチャをプロジェクトメンバーに提供する環境を作成して、プロジェクトメンバーが新しいデータを簡単に生成したり、アクセス権のあるデータを利用したりできるようにすることができます。これにより、ユーザーは、ニーズに応じて複数の機能や分析ツールを同じプロジェクトに追加できます。
統制されたデータ共有 – データプロデューサーは、コンシューマーがアクセスをリクエストし、データ所有者が承認することを可能にするサブスクリプション承認ワークフローを使用して、データへのアクセスを所有および管理します。公開時にアセットにアタッチされるサブスクリプション条件を設定したり、AWS マネージドのデータレイクと Amazon Redshift のサブスクリプション付与のフルフィルメントを自動化したりできるようになりました (他のソースのために EventBridge イベントを利用してカスタマイズすることもできます)。
今すぐご利用いただけます
Amazon DataZone は現在、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、カナダ (中部)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (ストックホルム)、南米 (サンパウロ) の 11 の AWS リージョンで一般提供されています。
Amazon DataZone の無料トライアルをご利用いただけます。これには、利用開始後の最初の 3 暦月間にわたって、50 名のユーザーによる追加料金なしでの利用が含まれています。無料トライアルは、AWS アカウントに初めて Amazon DataZone ドメインを作成したときに開始されます。試用期間中に月間ユーザー数を超過した場合は、標準料金に基づいて課金されます。
詳細については、製品ページおよびユーザーガイドをご覧ください。フィードバックは、AWS re:Post for Amazon DataZone 宛てに、または通常の AWS サポートの連絡先を通じてお寄せいただけます。
– Channy
原文はこちらです。