Amazon Web Services ブログ
Amazon Kinesis Analytics - SQL を使用してリアルタイムにストリーミングデータを処理
ご存知の通り、Amazon Kinesis では、AWS Cloud でリアルタイムにストリーミングデータを操作するプロセスが大幅に簡素化されています。独自のプロセスおよび短期のストレージインフラストラクチャを設定および実行する代わりに、ただ Kinesis ストリームまたは Kinesis Firehose を作成し、そこにデータを流し込むように設定してから、それを処理または分析するアプリケーションを構築するのみです。Kinesis ストリームと Kinesis Firehose を使用してストリーミングデータソリューションを構築するのは比較的簡単なのですが、さらに簡素化したいと考えました。作業開発者、データサイエンティスト、または SQL 開発者であるかどうかにかかわらず、お客様がウェブアプリケーション、テレメトリ、およびセンサーレポートの大量のクリックストリームを、接続されたデバイス、サーバーログなどからすべてリアルタイムに標準クエリ言語を使用して処理できるようにしたいと考えました。
Amazon Kinesis Analytics
 本日より、Amazon Kinesis Analytics がご利用いただけるようになりました。ストリーミングデータに対して SQL クエリを継続的に実行し、データが届くと同時にフィルタリング、変換、および集約できるようになりました。インフラストラクチャで時間を無駄にするのではなく、データの処理とそこからのビジネス価値の抽出に注力できます。強力なエンドツーエンドのストリームプロセスパイプラインを 5 分で構築できます。SQL クエリより複雑なものを作成する必要はありません。
本日より、Amazon Kinesis Analytics がご利用いただけるようになりました。ストリーミングデータに対して SQL クエリを継続的に実行し、データが届くと同時にフィルタリング、変換、および集約できるようになりました。インフラストラクチャで時間を無駄にするのではなく、データの処理とそこからのビジネス価値の抽出に注力できます。強力なエンドツーエンドのストリームプロセスパイプラインを 5 分で構築できます。SQL クエリより複雑なものを作成する必要はありません。
データベーステーブルに対する一連の SQL クエリの実行を考慮する場合、クエリは通常、非常に素早く追加および削除されるのに対して、データはほぼ静的なままです。常に行が追加、変更および削除されますが、これは特定の時点で実行する単一のクエリを考慮する際、一般的には関係ありません。Kinesis Analytics のクエリをストリーミングデータに対して実行すると、このモデルと正反対のことが生じます。クエリは長時間実行され、新しいレコード、監視、またはログエントリが届くと同時に、データは毎秒何度も変化します。一度この仕組みを把握すると、クエリプロセスモデルが非常に理解しやすいことが分かります。レコードが届くと同時に処理する、持続的なクエリを構築するのです。所定のクエリで処理されるレコードのセットを制御するには、プロセス「ウィンドウ」を使用します。Kinesis Analytics では、3 つの異なるタイプのウィンドウがサポートされています。
タンブリングウィンドウは定期的なレポートに使用されます。タンブリングウィンドウを使用して、時間の経過と共にデータをまとめることができます。おそらく毎秒数千~数百万ものリクエストを受信するので、1 分ごとの受信数を知りたいと思うでしょう。現在のタンブリングウィンドウが閉じると、その後に次のウィンドウが開始します。ウィンドウがいっぱいになるたびに、新しい結果が生成されます。
スライディングウィンドウは、モニタリングとその他のタイプのトレンド検出に使用されます。例えば、スライディングウィンドウを使用してリアルタイムで動くエラー率の平均をコンピューティングできます。レコードがウィンドウに入り、レコードがその中にあるかぎり結果に反映され、ウィンドウは進行します。新しいレコードがウィンドウに入るたびに、新しい結果が生成されます。ウィンドウのサイズを調整して、結果の精度を制御できます。
カスタムウィンドウは、適切なグループが厳密に時間に基づいていない場合に使用されます。クリックストリームデータまたはサーバーログを処理している場合、カスタムウィンドウを使用してセッション化として知られるアクションを実行できます。つまり、各ユーザーが実行する最初と最後のアクション (受信データ内のセッション ID により識別される) によって、各クエリをバインドできます。各ユーザーが閲覧したページ数またはサイトで費やした時間をコンピューティングするクエリを作成できます。
これらすべてはいくらか複雑に聞こえるかもしれませんが、実装するのは非常に簡単です。Kinesis Analytics では、受信レコードのサンプルを分析し、最適なスキーマを提案します。それをそのまま使用することも、微調整して実際のデータモデルをさらに反映することもできます。スキーマが定義されると、組み込み SQL エディターを使用できます (ライブデータに対する構文チェックと簡単なテストを含む)。クエリの結果を Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、または Amazon Kinesis Stream を含む最大 4 つの送信先にルーティングするように、Kinesis Analytics を設定できます。初めての Amazon Kinesis Analytics アプリケーションを構築する場合、SQL ステートメントのペアを作成する必要があります (より複雑なアプリケーションには多くを使用する場合がありますが、必要なのは起動と実行の 2 つのみです)。
これは、中間 SQL 結果を保存するアプリケーション内のストリームを作成するためのステートメントです (ストリームは、選択および挿入でき、継続的にアップデートされる SQL テーブルのようなものです)。
1 つのアプリケーション内のストリームから SQL クエリを選択し、別のアプリケーション内のストリームに挿入します。
また、S3 を送信元とするデータを参照するよう、SQL ステートメントもレコードに追加できます。これはレコードを強化または変更し、追加のさらに詳細な情報を含める時に役立ちます。
動作中の Amazon Kinesis Analytics
動作中の Amazon Kinesis Analytics を数分見てみましょう。
Amazon Kinesis Analytics コンソールにログインし、Create new application をクリックします。名前とアプリケーションの説明を記入します。
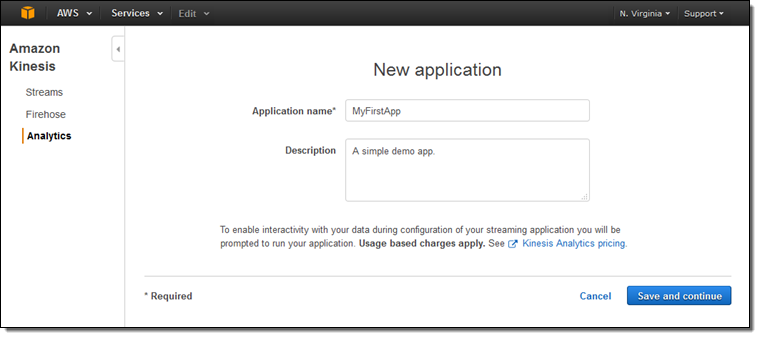
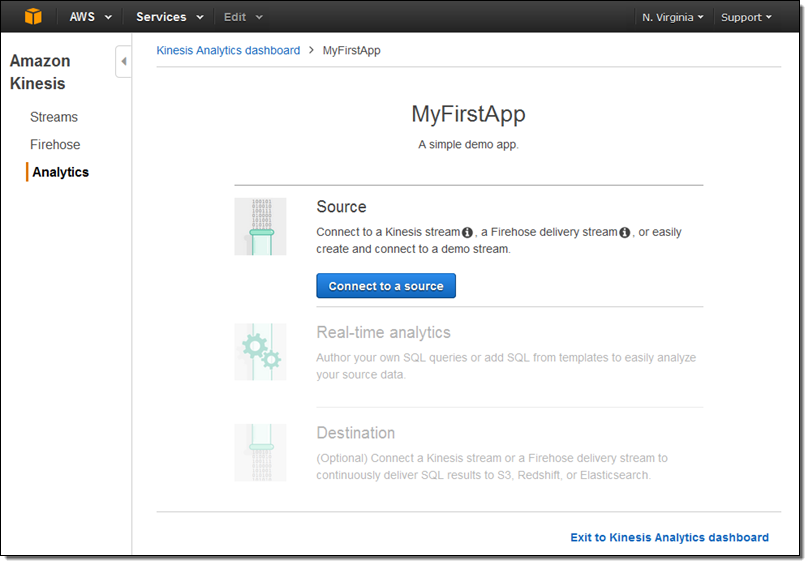
データソース、クエリ、および送信先を管理できるようになりました。
既存の入力ストリームの 1 つを選択できます。
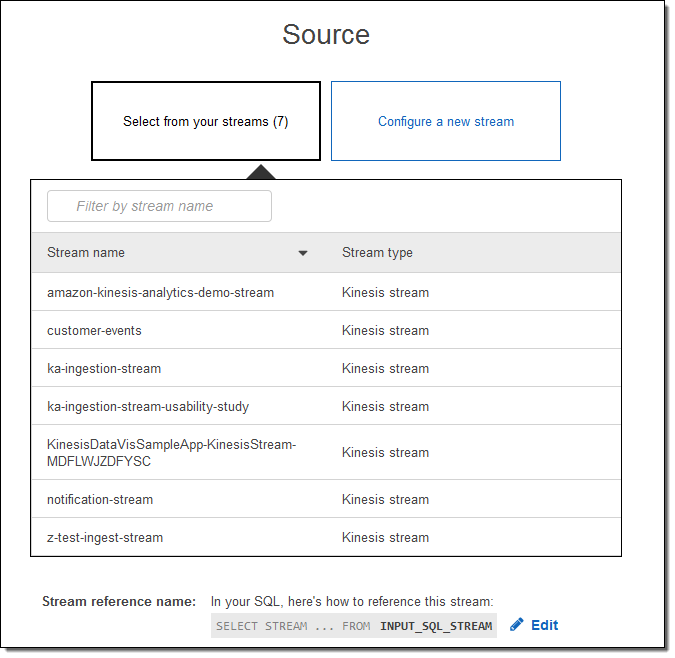
または、新しいストリームを設定できます (こちらを実行します)。
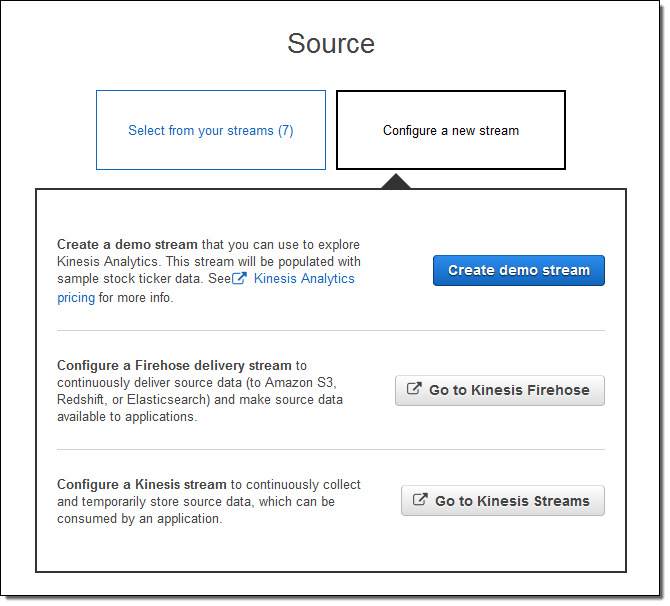
Create demo stream をクリックし、サンプルの株式相場表示機のデータが入力されるストリームを作成します。これには 30~40 秒かかります。Kinesis Analytics はストリームを参照し、スキーマを提案します。それをそのまま承認することも、微調整することもできます。
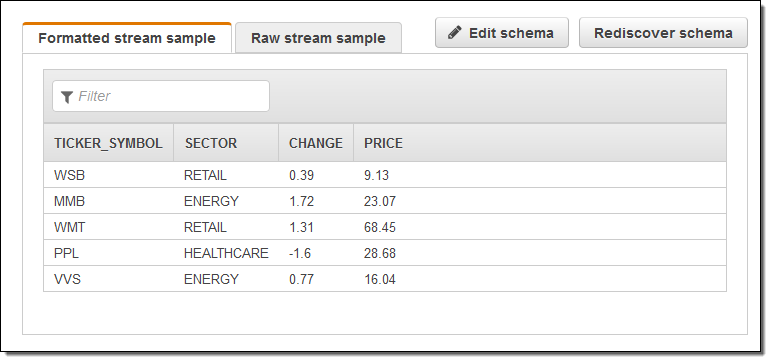
それから SQL エディターに移動します。アプリケーションの起動を提案しています。良いアイデアだと思うので、同意して Yes をクリックし、アプリケーションを起動します。
これが実際の SQL エディターです。
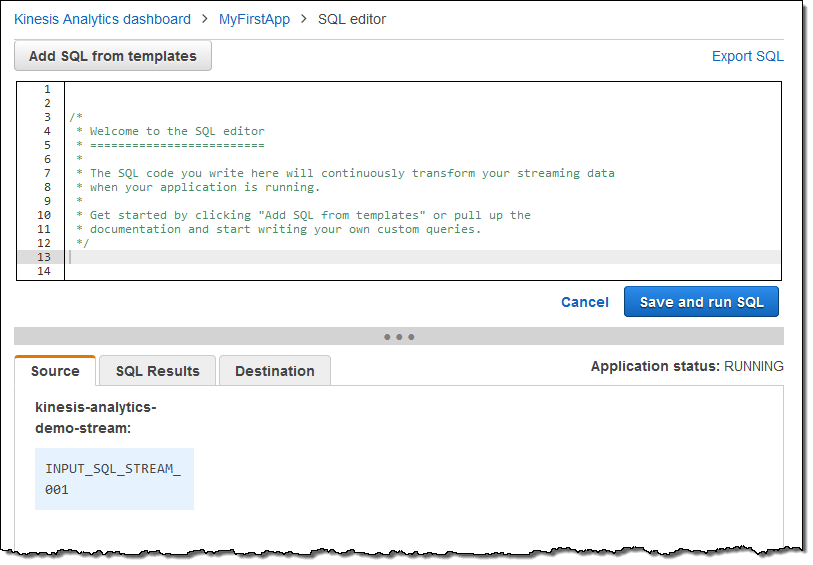
クエリをゼロから作成することも、テンプレートを使用することもできます。
継続的なフィルターを選びました。これが SQL です。
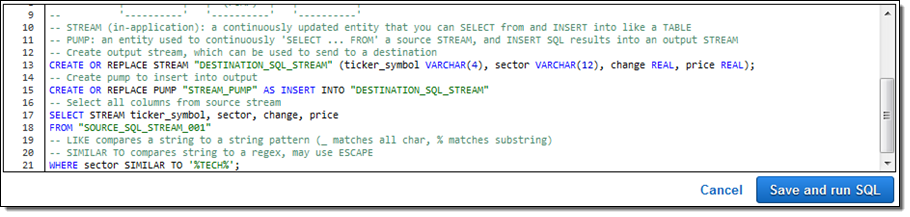
確認し、アグリーメントを承認し、Save and run SQL をクリックしました。数秒以内に結果が流れ始め、コンソールに表示されました。
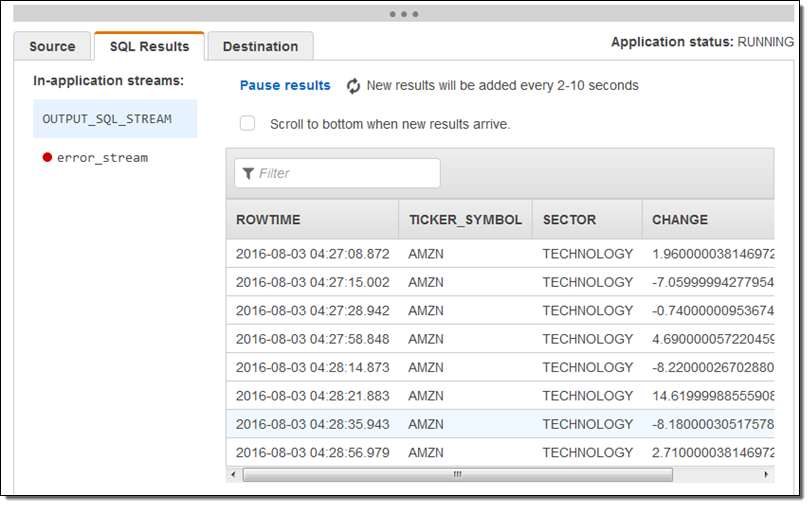
SQL エディターを使用して、部門と料金列を削除するようクエリを変更し、クエリを再度実行しました。この作業を行ってみて、CREATE STREAM ステートメントから列を削除する必要があることを学びました (振り返ってみると明白なのですが、これは長い 1 日の最後の作業でした)。こちらが修正した結果セットです。
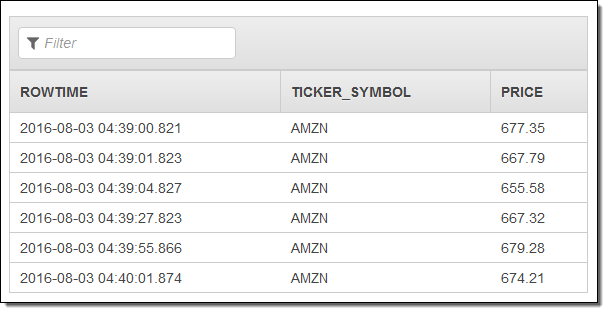
ほとんどの場合、次のステップでは結果を新規または既存のストリームにルーティングすることになるでしょう。これはコンソールから実行できます。
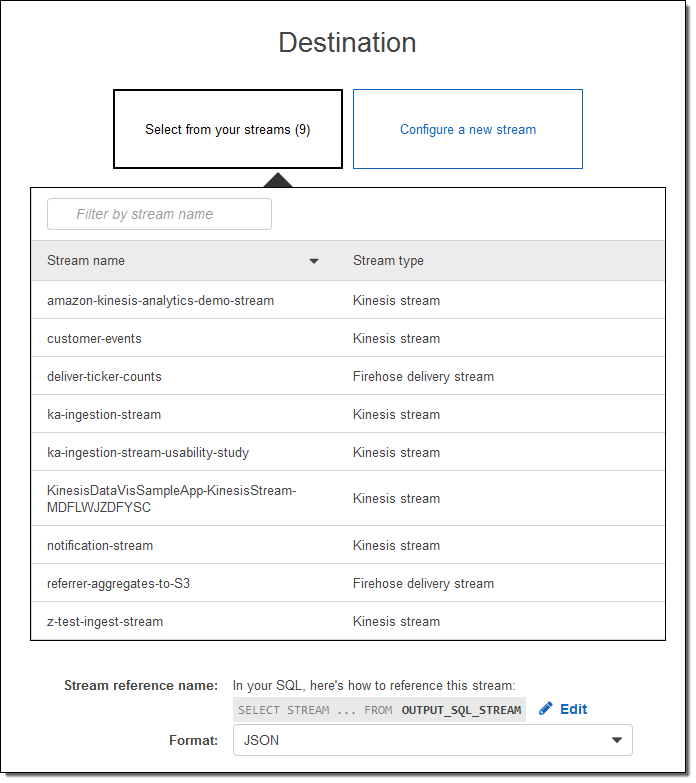
数回のクリックとほんの少しの入力のみで、本番環境規模の株式相場表示機のストリームを処理できる Amazon Kinesis Analytics アプリケーションを作成できました。本番環境で使用される前に、この「デモ」には何の変更も必要ありません。素晴らしいです。
詳細 & お試し
いつものように、このすばらしい新サービスについては、やっと分かり始めたばかりです。詳細については、新しい投稿をご覧ください。Writing SQL on Streaming Data with Amazon Kinesis Analytics上記のステップは 5 分またはそれ以下で再現できるはずです。ぜひお試しされるようにお勧めします。アプリケーションを作成し、SQL クエリをカスタマイズし、大規模なストリーミングデータの処理方法を学んでください。
今すぐご利用可能
今すぐ Amazon Kinesis Analytics をご利用いただけます。今日からストリーミングデータに対してクエリの実行を開始できます。
— Jeff