Amazon Web Services ブログ
Amazon SageMaker Canvas を発表 – ビジネスアナリスト向けの視覚的でノーコードの機械学習機能
ビジネス上の問題に直面し、日常的にデータを扱う組織として、ビジネスの成果を予測できるシステムを構築する能力が非常に重要になります。この能力があると、低速なプロセスを自動化し、IT システムにインテリジェンスを組み込むことで、問題の解決と迅速な対応が可能になります。
しかし、組織内のすべてのチームと個々の意思決定者が、他のデータサイエンスチームやデータエンジニアリングチームに依存することなく、このような機械学習 (ML) システムを大規模に作成できるようにするにはどうすればよいでしょうか? ビジネスユーザーまたはデータアナリストは、何百ものアルゴリズム、トレーニングパラメータ、評価メトリクス、デプロイのベストプラクティスについて学ぶことなく、毎日分析および処理するデータに基づいて予測システムを構築して使用したいと考えています。
2021 年 11 月 30 日(米国時間)、 Amazon SageMaker Canvas が一般提供されたことをお知らせします。これは、ビジネスアナリストがコードを書いたり、MLの専門知識なしに、ML モデルを構築して正確な予測を生成できる、新しいビジュアルでコードを使用しない機能です。直感的なユーザーインターフェイスにより、クラウドまたはオンプレミスのさまざまなデータソースを参照してアクセスしたり、ボタンをクリックするだけでデータセットを結合したり、正確なモデルをトレーニングしたり、新しいデータが利用可能になったら新しい予測を生成したりできます。
SageMaker Canvas は Amazon SageMaker と同じテクノロジーを活用して、データのクリーニングと結合、内部での数百のモデルの作成、最もパフォーマンスの高いモデルの選択、新しい個別予測またはバッチ予測の生成を自動的に行います。バイナリ分類、複数クラス分類、数値回帰、時系列予測など、複数の問題タイプをサポートしています。これらの問題タイプにより、コードを 1 行も記述しなくても、不正検出、チャーン削減、インベントリの最適化など、ビジネスクリティカルなユースケースに対処できます。
SageMaker Canvas の動作
e コマースのマネージャーで、製品が予定どおりに出荷されるかどうかを予測する必要があるとします。自由に使えるデータセットは、製品カタログと出荷履歴データセットで構成され、どちらも CSV 形式です。
まず、SageMaker Canvas アプリケーションに入ります。そこですべてのモデルとデータセットが作成され、検査されます。
![]()
[インポート] を選択し、ProductData.csv とShippingData.csv の 2 つの CSV ファイルをアップロードします。120 個の製品と 10,000 件の出荷記録があります。


また、Amazon Simple Storage Service (Amazon S3) からデータを取得したり、Amazon Redshift や Snowflake などの他のクラウドまたはオンプレミスのデータソースに接続したりすることもできます。このユースケースでは、1.6 MB のデータを自分のコンピューターから直接アップロードすることにします。
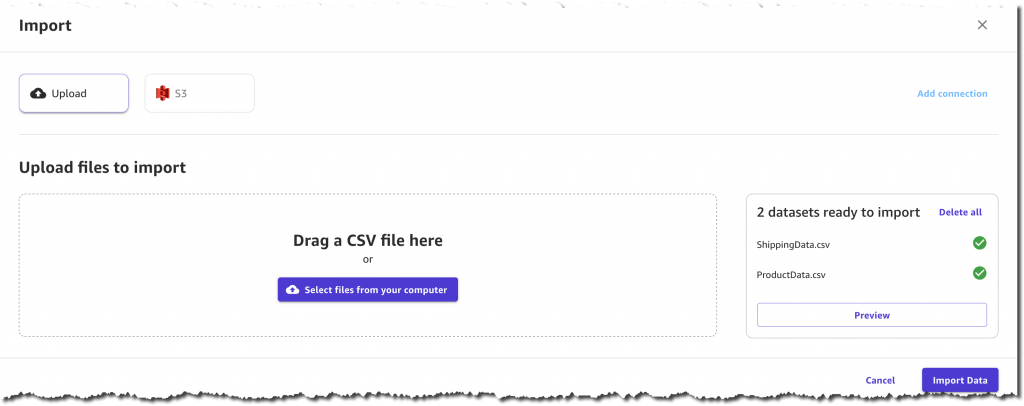
インポートを確定する前に、2 つのデータセット、列、およびそれぞれの値をプレビューする機械があります。例えば、各製品には ComputerBrand、ScreenSize、PackageWeight があります。出荷データセットの各レコードには、ShippingOrigin、OrderDate、ShippingPriority などの便利な列に加えて、On Time または Late いずれかの OnTimeDelivery (オンタイムデリバリー) も含まれています。この列は、SageMaker Canvas が履歴データに基づいて予測モデルを生成するために使用します。
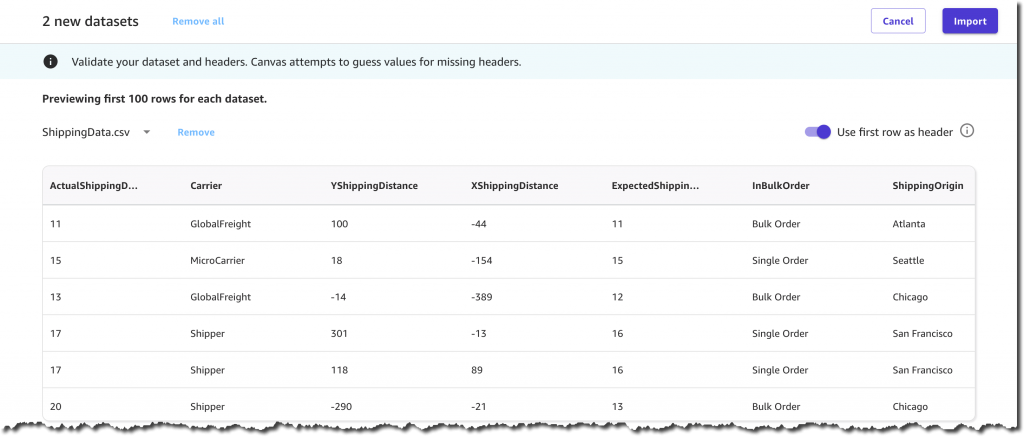
数秒の処理の後、データセットは準備完了です。データセットを結合して、製品情報と出荷情報の両方を含む単一のデータセットを作成することにしました。これはオプションのステップで、多くの場合、予測モデルの精度を上げることができます。
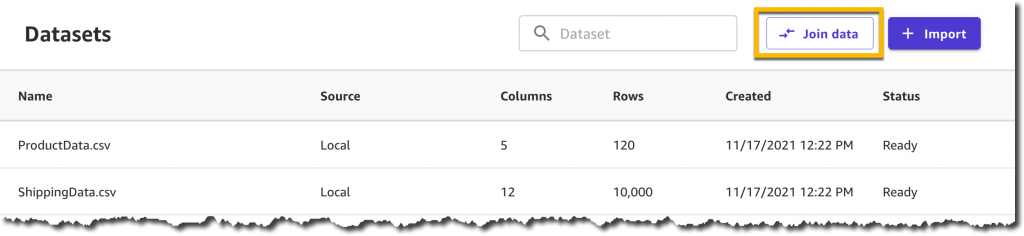
これで、2 つのデータセットをドラッグアンドドロップするだけで済みます。SageMaker Canvas は共有 ProductId 列を自動的に識別し、内部結合変換を適用します。
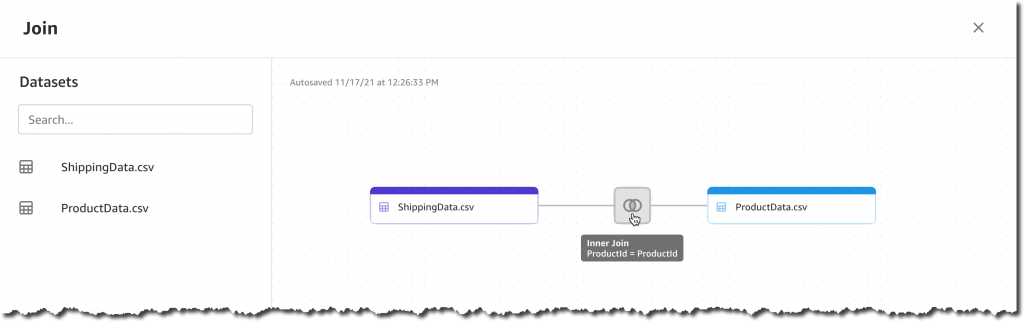
結合プレビューでは、結果の列を視覚化し、欠落している値や無効な値を特定し、オプションで不要な列の選択を解除できます。

[Save joined data] を選択し、この結合データセットに新しい名前を指定します。このデータセットには、16 列と 10,000 レコードが含まれます。
次に、モデルを作成し、左側のメニューの [Models] セクションで [New model] を選択します。それをオンタイム予測モデルと呼びます。
最初のステップは、データセットの選択です。
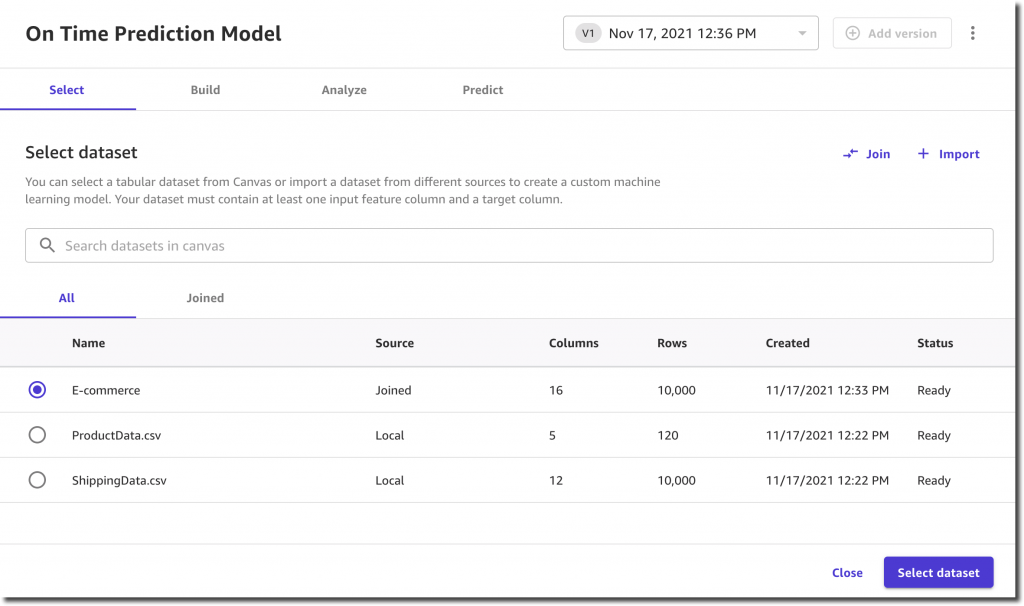
モデルが予測するターゲット列、OnTimeDelivery を選択します。
SageMaker Canvas は値の分布を表示し、すでに最も適切なモデルタイプである 2 つのカテゴリ分類を推奨しています。

モデルトレーニングを進める前に、分析レポートを生成するオプションがあります。この分析により、推定精度と各列の影響という 2 つの非常に重要な情報が得られます。

99.9% という推定精度で自信が得られますが、 ActualShippingDays 列が最も大きな影響を与えていることに気付きました。残念ながら、このコラムは事前に利用できず、この予測には使用できません。そこで、選択を解除して分析を再実行します。

新しい推定精度は 94.2% で、まだかなり高い精度です。最も影響力のある列は、ShippingPriority、YShippingDistance、XShippingDistance、Carrier です。これらの情報はすべて事前に入手可能であり、予測に使用できるので、これは素晴らしいことです。一方、PackageWeight や ScreenSize などの製品関連の列は、予測に与える影響はごくわずかです。これは、将来的には、出荷情報のみをトレーニングと予測のフェーズに入力することで、プロセス全体を簡素化できることを意味します。
分析のインサイトには満足しています。そこで、標準的な構築オプションを選択して予測モデルを構築することにしました。
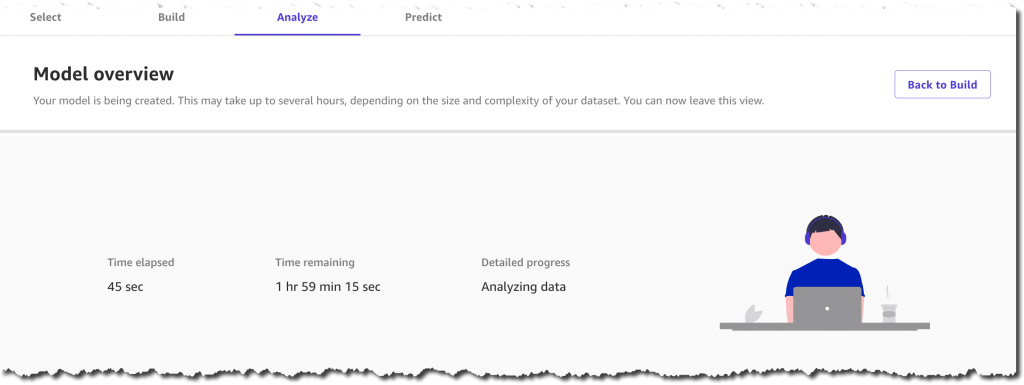
ここで、私は散歩に出かけたり、いくつかの生産的な会議に出席したり、単に家族と時間を過ごしたりすることができます。SageMaker Canvas は私のためにすべての作業を行い、バックグラウンドで何百ものモデルをトレーニングしています。最高のパフォーマンスを発揮するものを選択するので、数時間で正確な予測の生成を開始できます。もちろん、トレーニング期間はデータセットのサイズと問題の種類によって異なります。
約 1 時間半後、モデルの準備が整い、コンソールでその精度と柱の影響を視覚的に分析できます。また、モデルが 95.8% の確率で正しい値を予測し、推定精度よりもさらに高いことに満足しています。
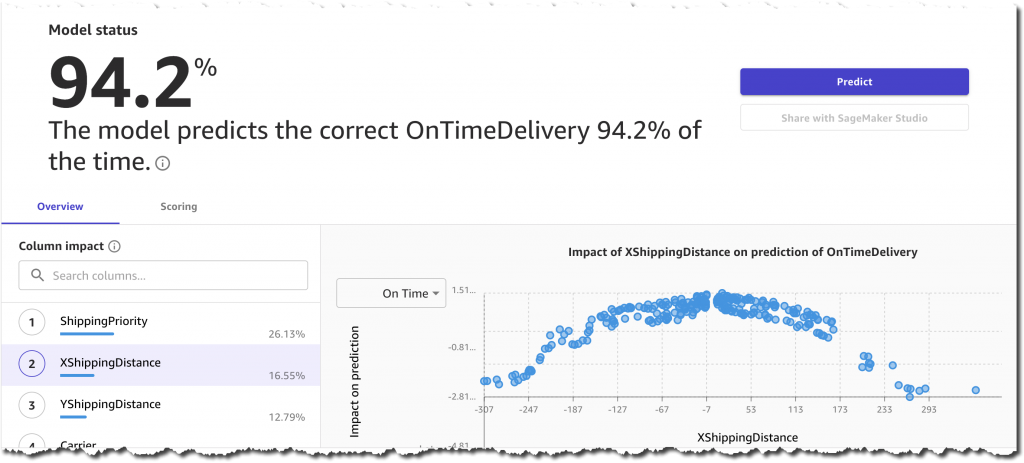
オプションで、Precision、Recall、F1 Score などの高度なメトリクスを検査することもできます。これらのメトリクスは、モデルのパフォーマンスと、このモデルからどのような偽陽性と偽陰性が期待できるかを理解するのに役立ちます。

ここから、モデルを Amazon SageMaker Studio で共有したり、Canvas UI を引き続き使用して新しい予測を生成したりできます。
直感的な UI を続行して [Predict] を選択することにしました。これで、バッチ予測のために個々のレコードまたはデータセットを操作できるようになりました。
[Single prediction] を選択すると、SageMaker Canvas により作業が省略でき、既存のレコードから始めることができます。列の値を変更して、予測とそれに対応する特徴の重要性について即座にフィードバックを得ます。

この迅速なフィードバックループと直感的な UI により、カスタムコードを記述しなくても ML モデルを使用できます。モデルを自動化された本番システムに統合する場合、Amazon SageMaker Studio の統合により、チームの他のデータサイエンティストとモデルを簡単に共有できます。
本日より一般的にご利用いただけます
SageMaker Canvas は、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (フランクフルト)、および欧州 (アイルランド) で一般的にご利用いただけます。Amazon S3、Amazon Redshift、または Snowflake に既に保存されているデータだけでなく、ローカルデータセットでも使用を開始できます。数回クリックするだけで、データセットの準備と結合、推定精度の分析、影響力のある列の検証、最もパフォーマンスの高いモデルのトレーニング、新しい個別予測またはバッチ予測の生成を行うことができます。ご意見をお寄せいただき、機械学習でさらに多くのビジネス上の問題を解決するためにお手伝いできることを楽しみにしています。
– Alex
原文はこちらです。